针对存储排序文件过程中合并和压缩的算法LSM-Tree
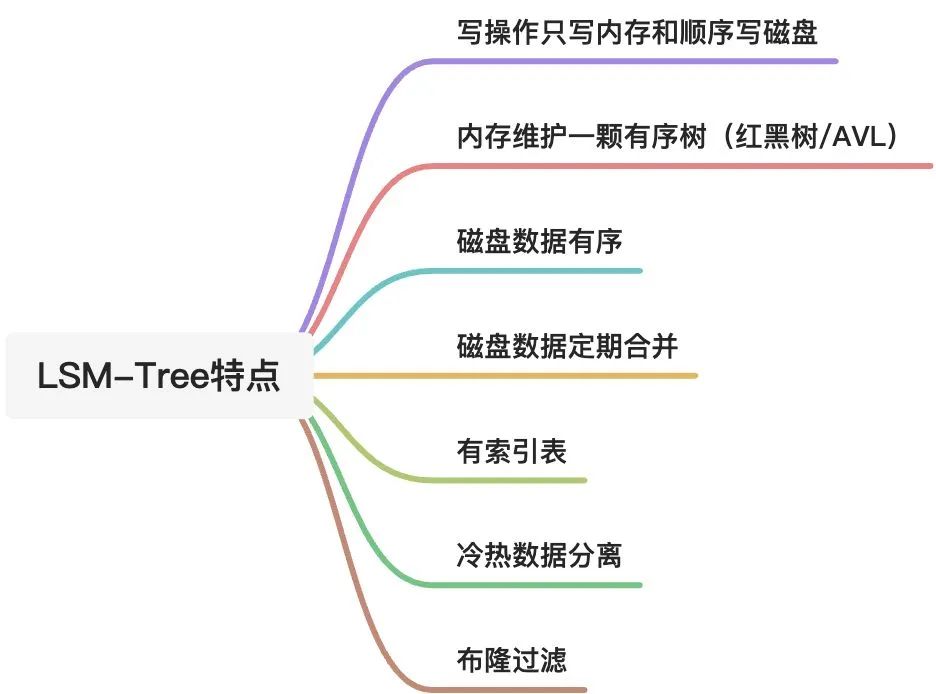
LSM-Tree全称为Log-Structured Merge-Tree,日志结构合并树,它的架构分为内存部分和有序的磁盘部分,内存部分实现高速写,有序的磁盘部分实现高效查。
LSM-Tree简介
LSM-Tree的概念出自1996年的一篇论文,它提出了针对存储排序文件过程中合并和压缩的算法。之后基于该原则的存储引擎通常被称为LSM存储引擎。
如果持久型数据库存入数据时,需要随机写入磁盘,需要寻找对应的磁盘位置,包括寻找磁道、扇区,转动磁头。转动磁头这一机械过程相对于数据写入的其他过程(CPU的计算和磁头电流改变磁盘单元格的磁场)是非常缓慢的,这是高速I/O的瓶颈所在。
LSM-Tree的思想是:借助于内存和日志文件将写入过程分为时间上不前后相连的两步,写入是只顺序写入磁盘的日志文件和内存,等系统空闲时再将内存中数据写入到磁盘。这样在处理写入请求时就省去了磁盘寻道、转动磁头的时间。
我认为可以先记住LSM-Tree的以下几个特点,再去深入了解它:
LSM-Tree架构
LSM-Tree全称为Log-Structured Merge-Tree,日志结构合并树,下文简称LSMT。LSMT的架构分为内存部分和有序的磁盘部分,内存部分实现高速写,有序的硬盘实现高效查,整体架构如下图所示。

内存中存在一个MemTable,MemTable内部维护一个高效读写的有序的数据结构,可以是红黑树、AVL树或者跳表等。写入数据时主要写入MemTable,当MemTable大小达到阈值时,会全部写入到磁盘中形成一个SSTable。当进行写操作时,只要写CommitLog,再写完MemTable就会返回写成功。
▐ LSTM的查找
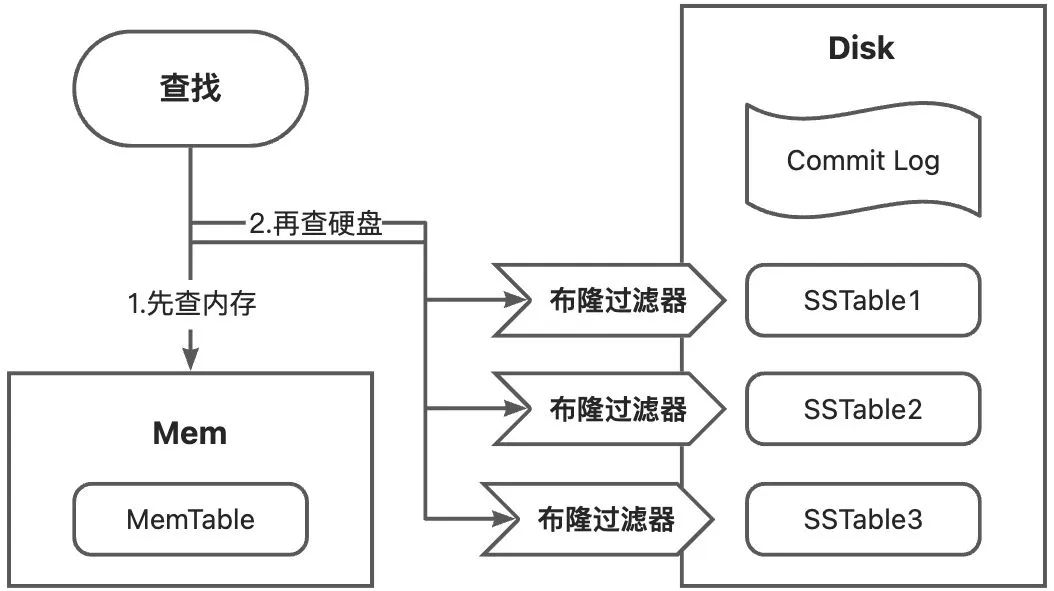
LSMT的查找分为两部,首先是查找内存,不中再查硬盘,具体步骤如下所示;
- 先查内存中的MemTable,如果命中则返回;
- 再查硬盘,先对每个SSTable对应的布隆过滤器进行过滤,如果判定为在该SSTable中,则查询该SSTable的索引表,索引表key有序,所以是二分查找。如果找到对应的key,则根据偏移值获取数据返回;如果未找到对应的key,则对下一个SSTable重复该过程。
▐ LSTM的写入
LSMT的写入包括对数据的增加、修改和删除。针对当前写请求的操作有两步:
- 先顺序写入磁盘的日志;
- 讲当前写请求的数据写入内存中的M嗯额Table;
- 回复当前写请求“写入成功”。
写请求回复之后的操作:
当MemTable到达阈值时,写入磁盘,形成一个SSTable;
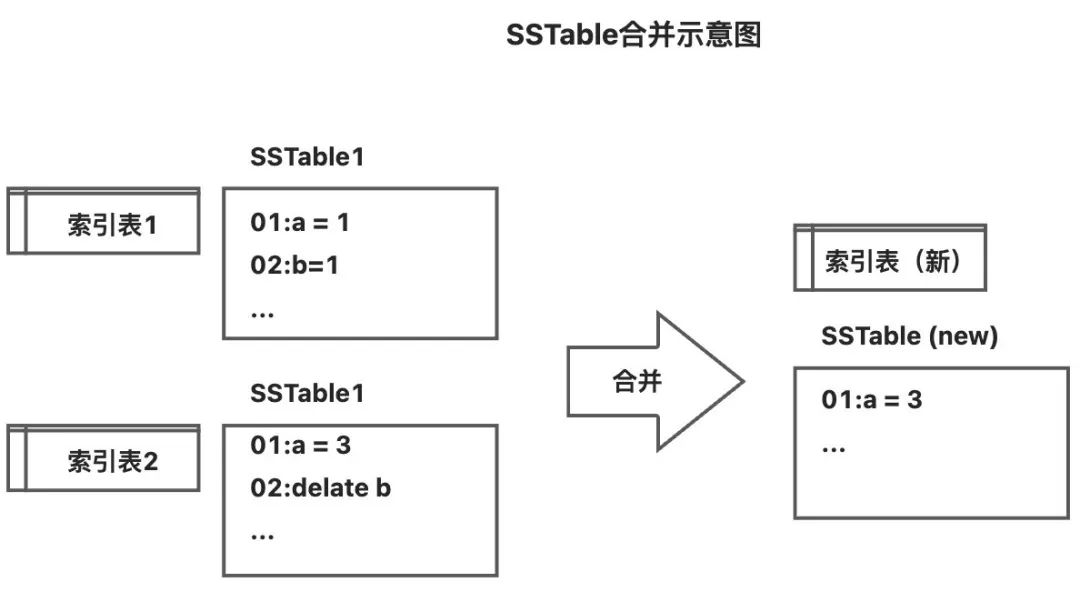
当SSTable数量到达阈值时,进行合并。合并时采用归并方式,将两个有序的SSTable合并为一个,并生成一张新的有序的索引表。

| 名词 | 解释 |
|---|---|
| 落盘 | 当内存中的MemTable达到最大容量时,一次性写入硬盘,形成一个新SSTable |
| 定期合并 | 当SSTable数量多时会降低查询性能;而且存储了很多修改和删除的信息。为了提高查询性能并节省磁盘空间,定期将所有的SSTable合并,剔除被删除和已被修改的数据。所有对数据的操作在commit log中都会被记录,因此可以通过commit log回滚。 |
-
LSMT的修改操作
LSMT收到修改请求时,并不会真正去修改SSTable中的数据,而是将这个修改作为一条修改记录存上到MenTable中,当MemTable写入磁盘进行合并时,两条数据的key相同,合并时根据时间戳,新的数据将覆盖老的数据。
-
LSMT的删除操作
LSMT的删除操作分为两种情况:要删除的数据在内存中,在磁盘中。
LSMT收到删除请求时,首先会查看内存中是否存在该记录,如果存在则直接删除;如果不存在则会向内存中的有序数据结构中增加一个删除记录。并不会真正去删除SSTable中的数据,当MemTable写入磁盘进行合并时,两条数据的key相同,合并时根据时间戳,执行最终的删除操作。
▐ MemTable
LSMT的memTable维护一个有序数据结构,可以是红黑树或者跳表结构,插入时按照有序结构将数据插入到对应位置,插入后安装所选用的结构的平衡要求进行有序结构调整。
写入磁盘时,将此有序结构按序吐出数据写入到硬盘中。
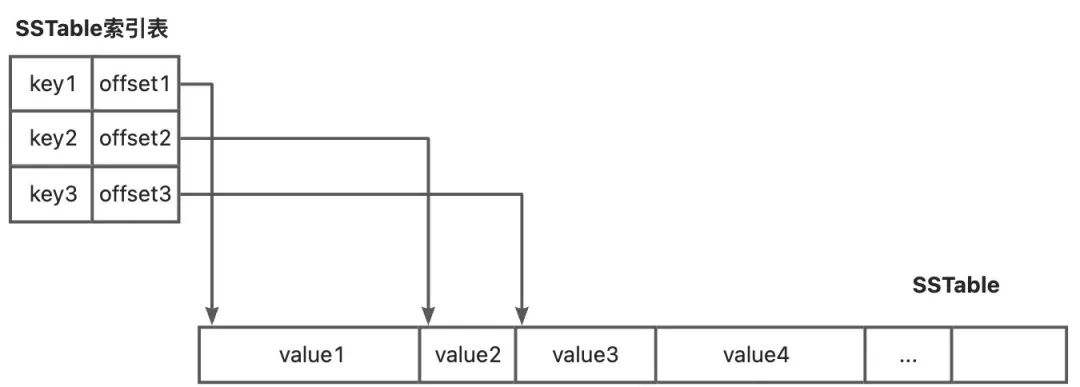
▐ SSTable结构
索引表在我们操作系统非常常见,像文件管理和存储中都用到了索引表。类似于我们操作系统中的索引表,SSTable也用一张存储表记录了SSTable存储的每个元素的位置。引入索引表后,当从SSTable中取数据的时候,不用把整个SSTable读进内存了,而是只需要读进非常小的索引表即可,极大减少了IO成本。同时索引的key是有序的,所以查找时二分查找方式也非常快。
▐ 布隆过滤器
为了进一步减少数据查询时的磁盘IO和提高查询速度,LSMT引入了布隆过滤器。上一小节中提到为了不把整个SSTable读入到内存中,引入了索引表,但是当SSTable数据量较大时,索引表也较大。因此引入布隆过滤器,将读入到内存的数据再减少一个数量级。
利用布隆过滤器,对所要查询的数据进行一个初步判读。每个SSTable都有个布隆过滤器,如果布隆过滤器判定为没有,则改SSTable中一定不存在改数据;如果布隆过滤器判定为有,则改数据很可能存在于该SSTable中,这是再将索引表加载进内存,进行进一步的查找确认。如果找到则返回;如果未找到,则再匹配下一个SSTable的布隆过滤器。
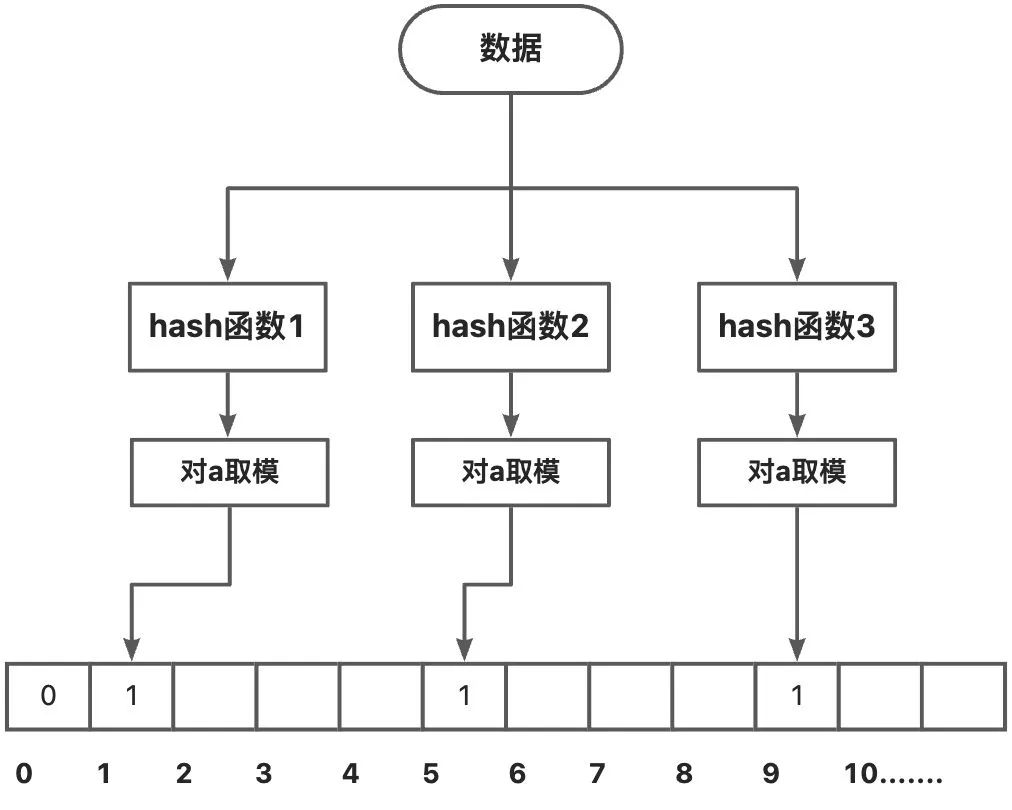
布隆过滤器的结构如下所示:
-
存储时
数据的key分别对多个hash函数运算,再对运算结果取模得到数值x1,x2...,再将数组中x1,x2..位置置为1。
-
查询时
key分别对多个hash函数运算,再对运算结果取模得到数值x1,x2...,再查看数组中x1,x2..位置上的数。如果不是全为1,则说明该数据一定不在该SSTable中;如果全为1,则说明该数据有极大概率在该SSTable中,即认为该数据在该SSTable中。
-
布隆过滤器判定错误的概率
如果数组长度是m,有k个hash函数。每当插入一个元素时的hash值时,数组中某位置置为1的概率是1/m,不置为1的概率是1-1/m。插入一个元素时,一个位置不置为1的概率是(1-1/m)**k。
插入n个元素后,某个位置还是0的概率为(1-1/m)**nk
查找时,某个元素不在容器中,但是它的hash值对应的数组位置都被置为1的概率为(1-(1-1/m)**nk)**k,当n较大时公式变为,又等价无穷小的极限替换公式得到

由于n和m一般是无法调节的,将k看为变量,对上述函数求导,可得到k=ln2*m/n(约为0.7m/n)时判错率最低。
▐ LSM-Tree总结
-
优点
写入快(增、删、改速度非常快),写吞吐量极大:写入时仅写入内存和顺序写入磁盘上的日志,不用关心是否写入磁盘。
-
缺点
- 查询能力被弱化,虽然LSMT有布隆过滤器和SSTable的索引表,但是相比于B+树结构查询仍较慢。
- 范围查找能力差。
- 查询一个不存在的数据时会进行全表扫描,非常慢。
- 压缩过程有时会影响正在进行的读和写的性能,因为磁盘资源有限,当磁盘进行压缩操作时,正常的数据请求有可能需要等待;
LSMT应用
目前基于LSM实现的数据库有:LevelDB,RocksDB,Hbase,Cassandra,ClinkHouse等。
▐ Google levelDB
Leveldb是由Google的工程师Jeff Dean和Sanjay Ghemawat开发的一个可持久化存储的KV数据库。leveldB在普通的LSMT架构的基础上进行了扩展,使其性能更佳,具体有以下扩展:
- 内存中扩展了ImmuTable ,目的是防止MemTable写入磁盘时系统无法对外提供服务,引入ImmuTable后,MemTable数据满时变为ImmuTable,由新的内存区域充当MemTable,这样MemTable便可以不间断的对外提供服务了,ImmuTable在合适时机写入磁盘。
- 对磁盘中的SSTable采用冷热数据的思想进行了分级,等级越高的SSTable数据越新,查询时从等级高的数据开始查询,level0>level1>level2... 。
- 增加了manifest文件,manifest文件中记录了Level中SSTable的分布,单个SSTable的最大最小key,以及其他一些LevelDB需要的元数据,便于查找时进行过滤。
- 增加current文件,manifest随着不断合并可能会有多个,current文件的作用就是记录最新的那个manifest的文件的位置。

-
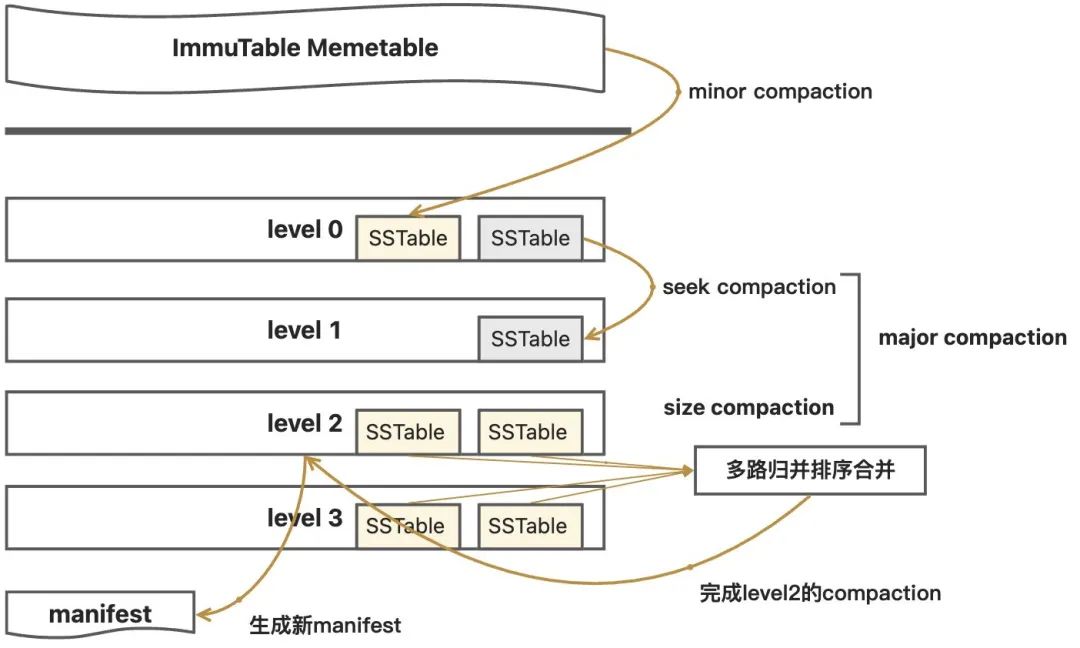
levelDB的压缩策略
levelDB扩展完善了LSMT的合并过程,采用多种压缩策略对不同场景下的SSTable进行合并。
三种压缩策略:
| 压缩策略 | 描述 |
|---|---|
| minor Compaction | 把MemTable中的数据导入到SSTable |
| major Compaction | 合并不同层级的SSTable文件,major Compaction会减少level的数量 |
| full Compaction | 将所有的SSTable文件合并 |
leveldb中实现了minor compaction和major compaction。其中major compaction由size compaction、manul compaction和seek compaction。
| size compaction | 平衡操作,当系统发现某一层的SSTable数量超过阈值的时候会触发compaction |
|---|---|
| manul compaction | 人工手动触发,通过接口调用人为地去触发它执行Compaction |
| seek compaction | 记录每一个SSTable文件的不命中率,当某个SSTable的不命中率达到阈值时,会将其合并到下一层的level中。 |
▐ HBase
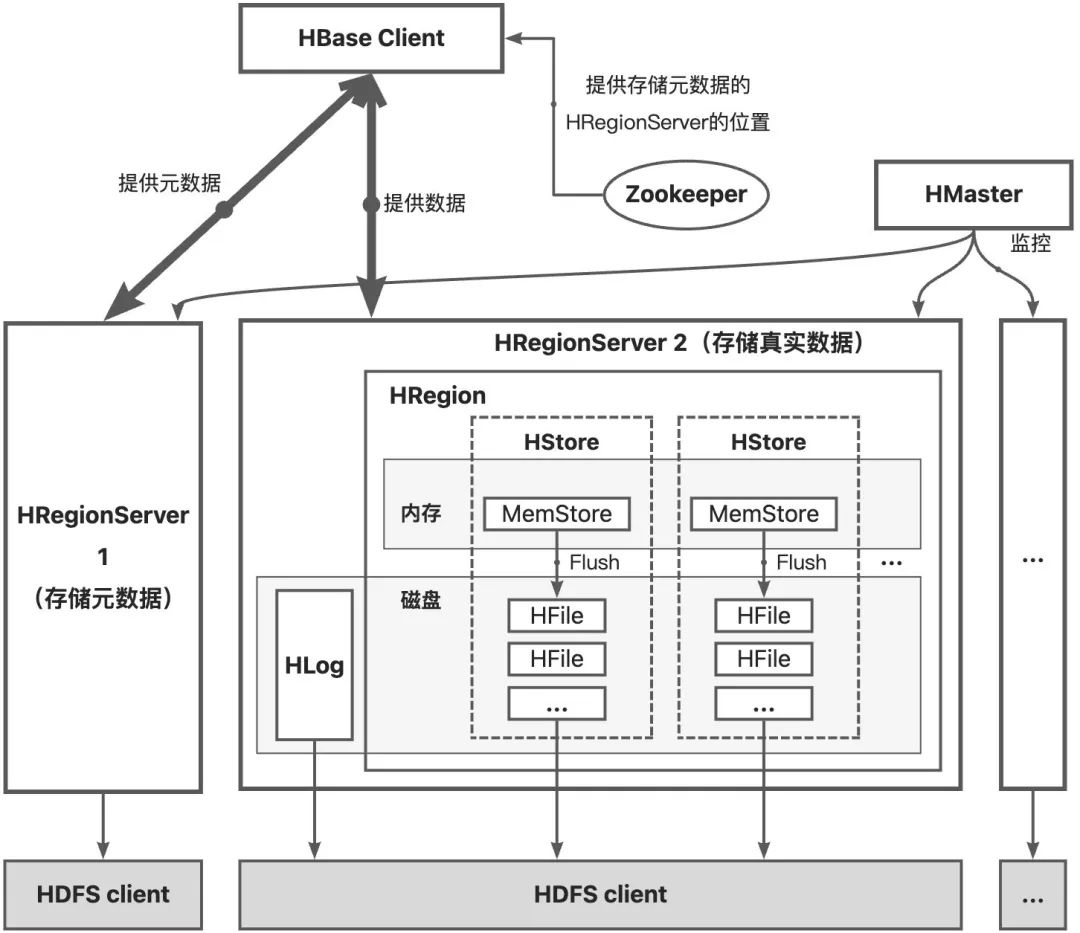
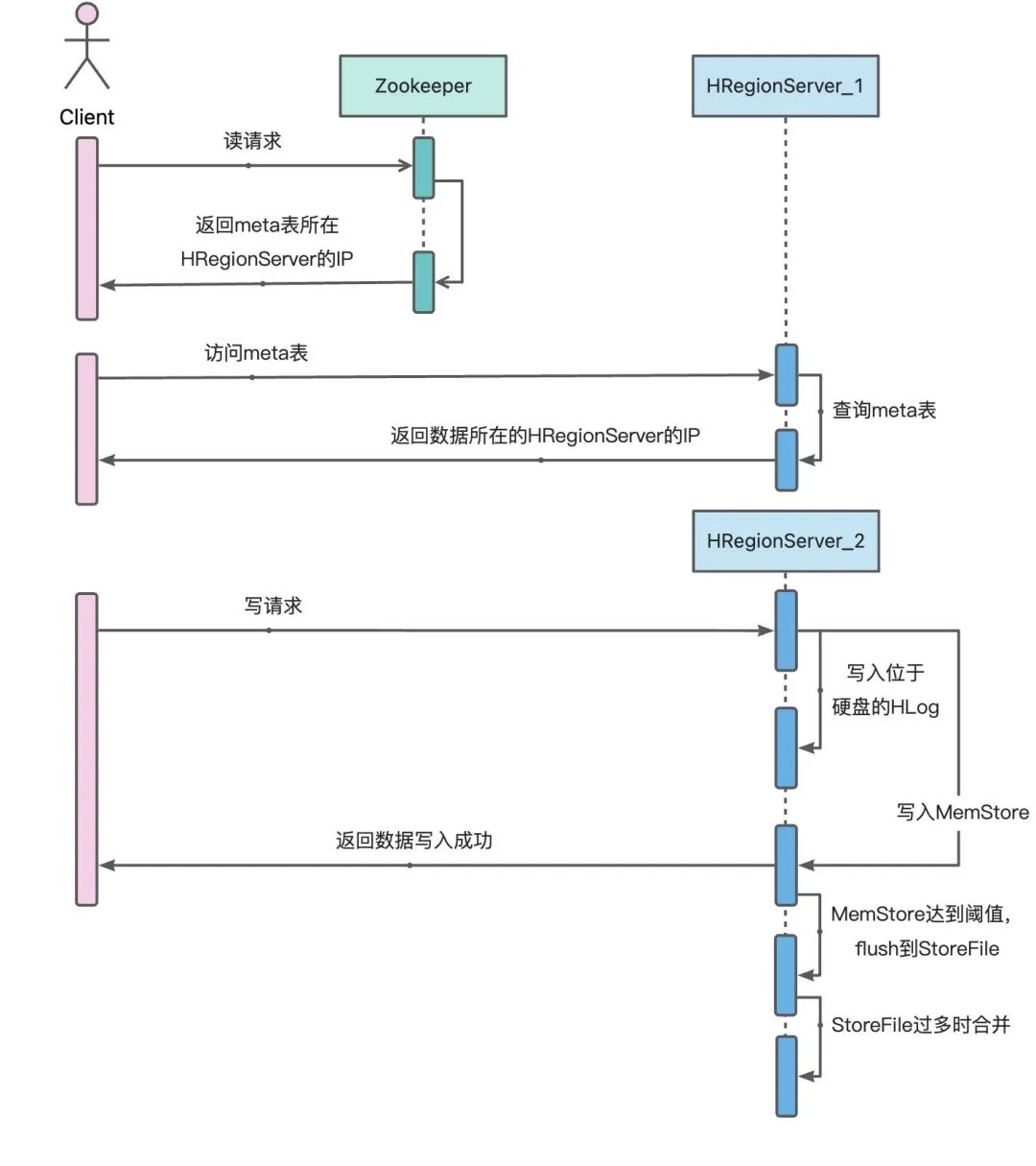
HBase的整体结构如图所示,HDFS的HStore采用LSMT思想结构,分为MemStore和HFile。
MemStore位于内存中,维护一颗有序数据结构。HFile位于磁盘中,是真正存储数据的结构。当MemStore数据达到阈值时会将数据刷入到磁盘中形成一个HFile,当HFile过多时会进行合并。
-
写入过程
▐ ClinkHouse
ClinkHouse的Merge引擎也是用的LSMT的思想,其在LSMT基础上更充分的实现了索引。
-
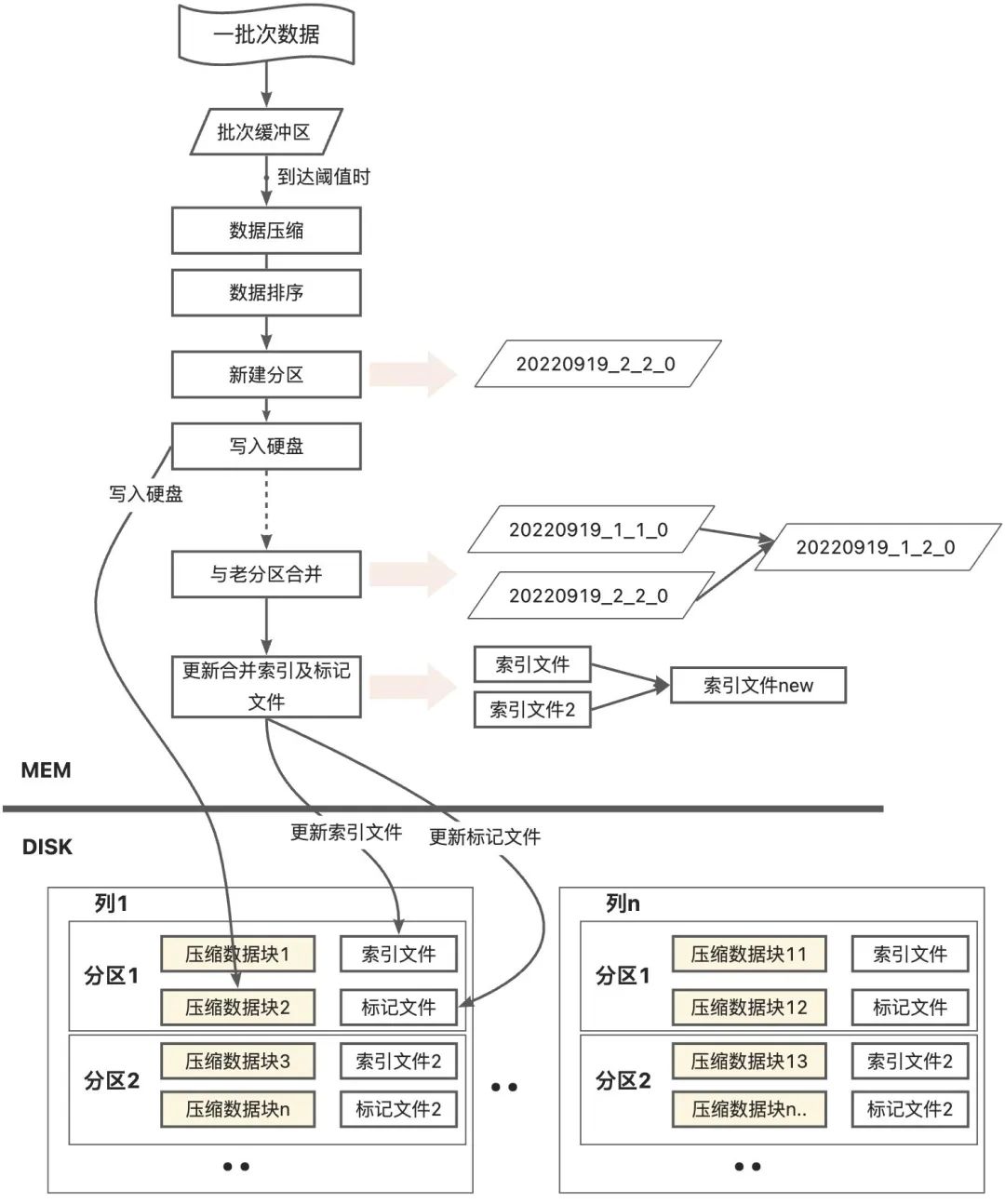
数据写入过程
数据先写入到内存的缓存区,等到达到缓冲区的阈值时(阈值可以自己配置,默认64KB到1MB),进行数据压缩排序写入硬盘。
每次写入磁盘形成一个新的分区,分区内容包括校验文件、索引文件、偏移文件、数据文件等。通过校验文件校验该分区内数据的完整性;通过索引文件找到要查询的数据;通过偏移文件找到所查找的数据在该分区中的偏移位置(分区内划分压缩块,偏移位置一般指压缩块的便宜位置);数据文件有多个压缩块组成,是存储数据的地方。
-
分区合并过程
ClinkHouse的分区合并即为LSMT的合并过程,每次写入后形成一个新的分区,clinkhouse会定期将partition值相同的分区进行合并。合并的时候会利用索引文件和偏移文件,按照归并思想进行数据合并,形成新的完成的分区,其中索引文件、便宜文件等都进行合并。
-
Merge引擎整体架构