前端也要懂算法,不会算法也能微调一个 NLP 预训练模型
前言
学习nlp的过程,就像升级打怪,每一个阶段都是一个坎,要想出新手村,需要跨过这几个坎
- level 1、了解nlp的概念 和 能做的边界
- level 2、会用一个已有的模型
- level 3、学会微调一个自己业务专属的模型
- level 4、定义一个全新的模型
之前有分享过 [前端工程师如何快速使用一个NLP模型] ,本文是该文的一个小进阶
- 初探level3
本文预计需要30min,通过本文主要获得几个知识点:
- 回顾 NLP的一些概念
- 学会微调一个 中文bert模型 完形填空任务
nlp介绍
发展历史
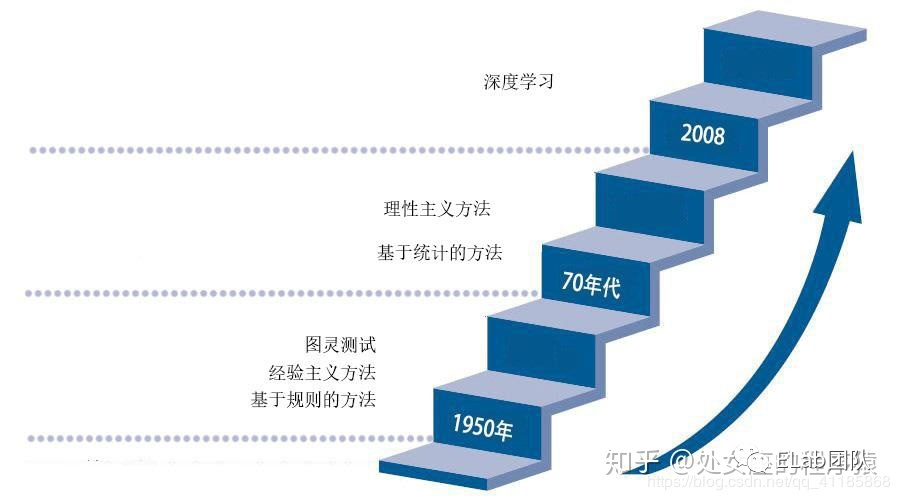
NLP任务的发展有两个明显的阶段,我们以bert模型为区分点,前半段是基础的神经网络阶段(bert模型之前的阶段),后半段是BertTology阶段(bert模型之后的阶段)
参考 https://zhuanlan.zhihu.com/p/148007742
-
1950-1970 - 采用基于规则的方法
-
人们定义了大量语言规则,但因规则的局限性,只能解决一些简单问题
-
1970-20世纪初 - 采用基于统计的方法
-
随着技术发展 和 语料库丰富,基于统计的方案逐渐代替了基于规则的方法,开始走向实际应用
-
2008-2018 - 引入深度学习的RNN、LSTM、GRU
-
在图像识别和语音识别领域的成果激励下,人们也逐渐开始引入深度学习来做自然语言处理研究,由最初的词向量到2013年的word2vec,将深度学习与自然语言处理的结合推向了高潮,并在机器翻译、问答系统、阅读理解等领域取得了一定成功
-
现今
-
2017年谷歌提出了Transformer架构模型,2018年底,基于Transformer架构,谷歌推出了bert模型,bert模型一诞生,便在各大11项NLP基础任务中展现出了卓越的性能(https://gluebenchmark.com/leaderboard) ,现在很多模型都是基于或参考Bert模型进行改造
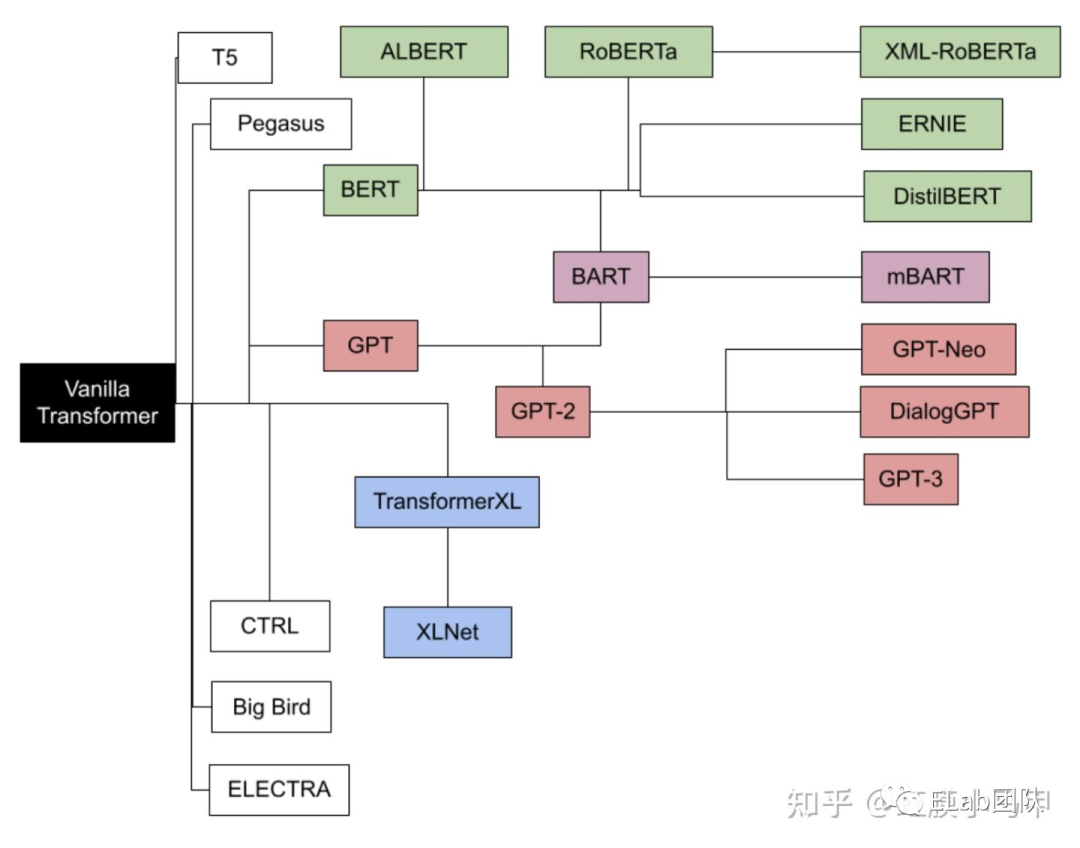
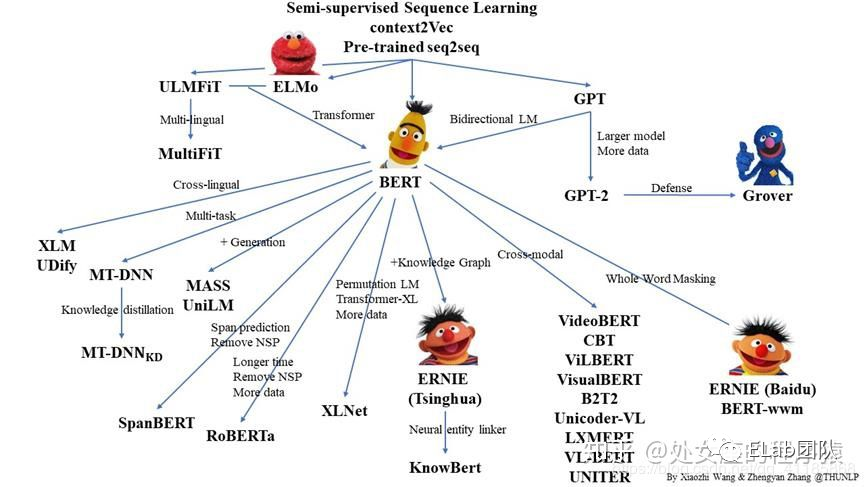
bert 大家族
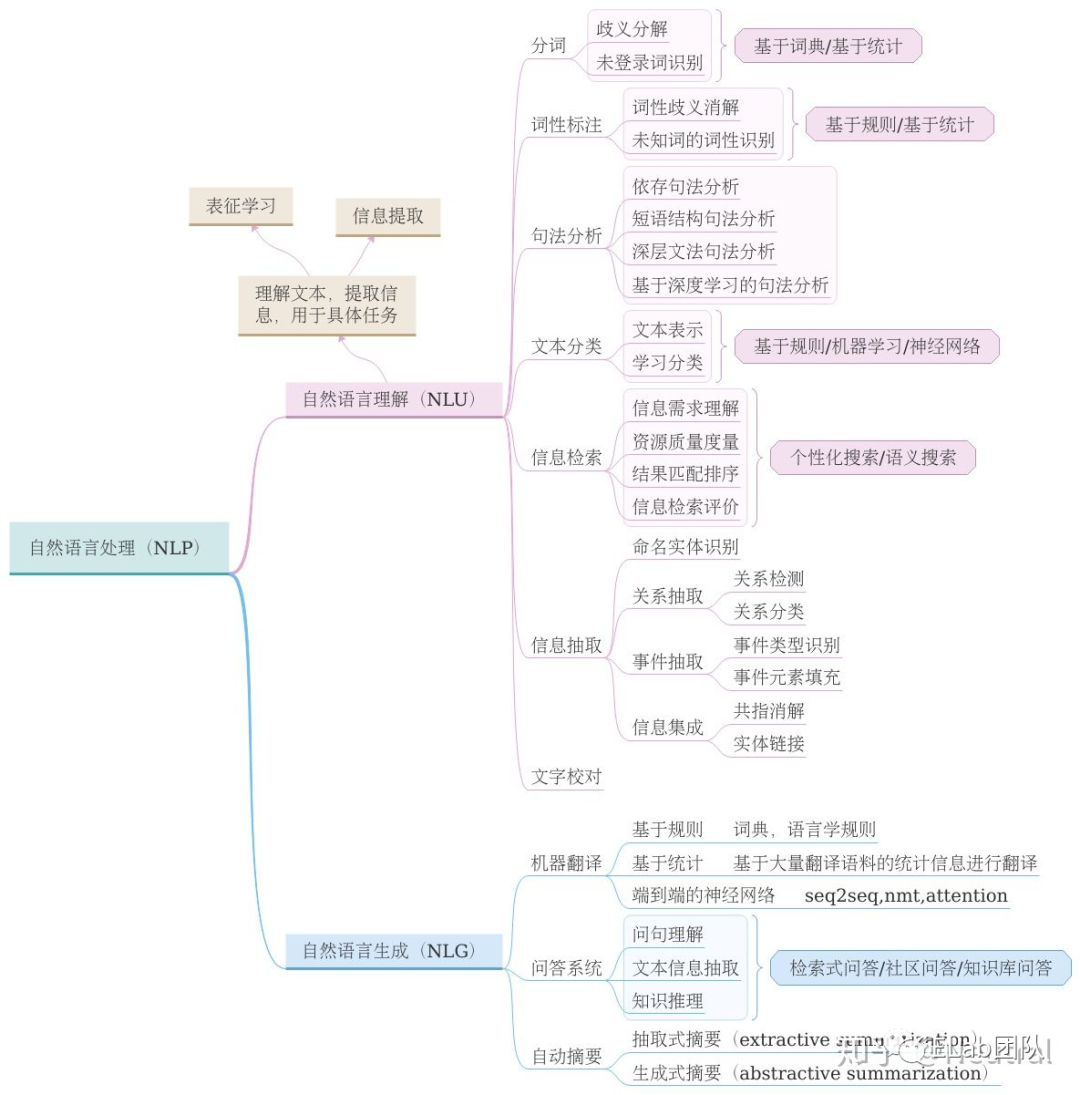
目前研究方向
方向分为两个方向
https://zhuanlan.zhihu.com/p/56802149
- 自然语言理解 NLU
- 自然语言生成 NLG

学习nlp绕不开的一个知识概念
神经网络基本原理
这是个有点大的概念,本文为了避免冗余繁琐,主要强调两个地方,方便有个大体认知
神经元
单个神经元是神经网络的基础,就像生物界的神经元(树突决定输入、输出;轴突完成信号传递)
数学表示如下:Output=f(∑n(x*w)+θ)
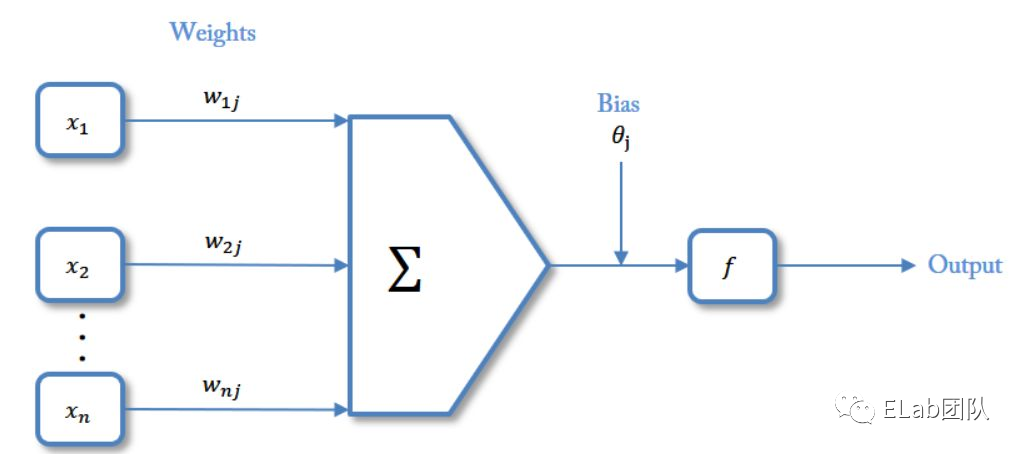
激活函数作用:加入非线性因素,解决线性模型表达能力的不足,拟合更多的情况
其中 w、θ 的值由 模型训练 得到,一个神经网络训练过程就是让每个神经元模型的权重值调整到最佳,以使整体的预测效果最好
神经网络工作基本流程
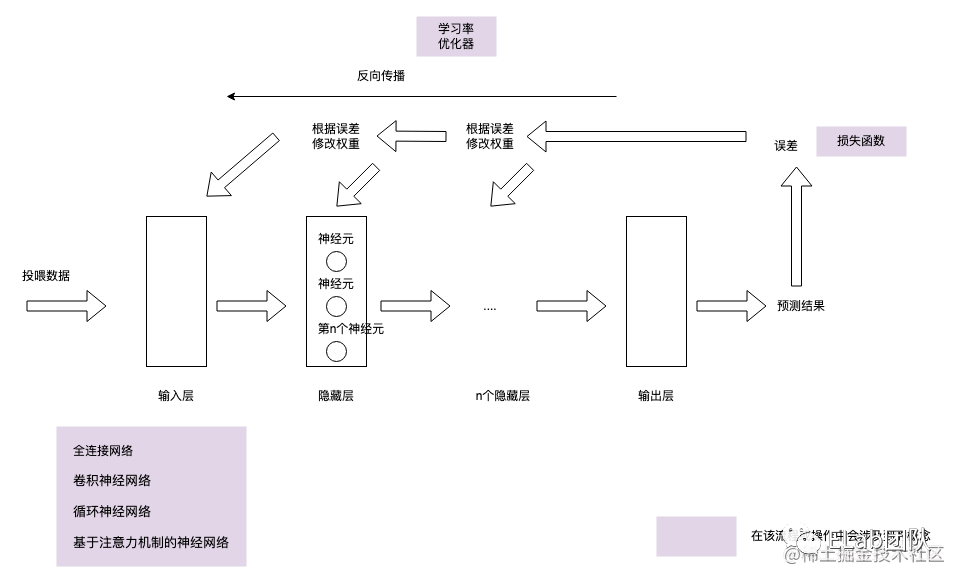
损失函数:计算 输出值、目标值 之间的误差
反向传播:把误差传递给权重,让权重做适当的调整,最终让正向传播的输出结果与标签间误差最小
学习率:反向传播中步长大小,控制调节幅度,在精度和速度之间找到一个平衡
优化器:一般需要反复迭代才能找到适合的权重,比较耗时,所以我们通过 一套策略(优化器)利用算法从而更快、更好的将参数调整到位
but,在代码编写过程中,我们并不需要手写一个损失函数,手写一个优化器,Pytorch 会帮你封装成了一个个api;而在大部分场景甚至都不需要再去手写神经网络 或者 训练别人写好的神经网络,因为我们可以直接使用预训练模型,开箱即用

预训练模型
前面有提到 bert模型,bert模型就是一个预训练模型,下面简单说下预训练模型
具体可以回顾下:[前端工程师如何快速使用一个NLP模型]
概念:什么是预训练模型
第三方(主要是三方机构)用数据集已经训练好的模型,通常情况下,我们可以拿来即用
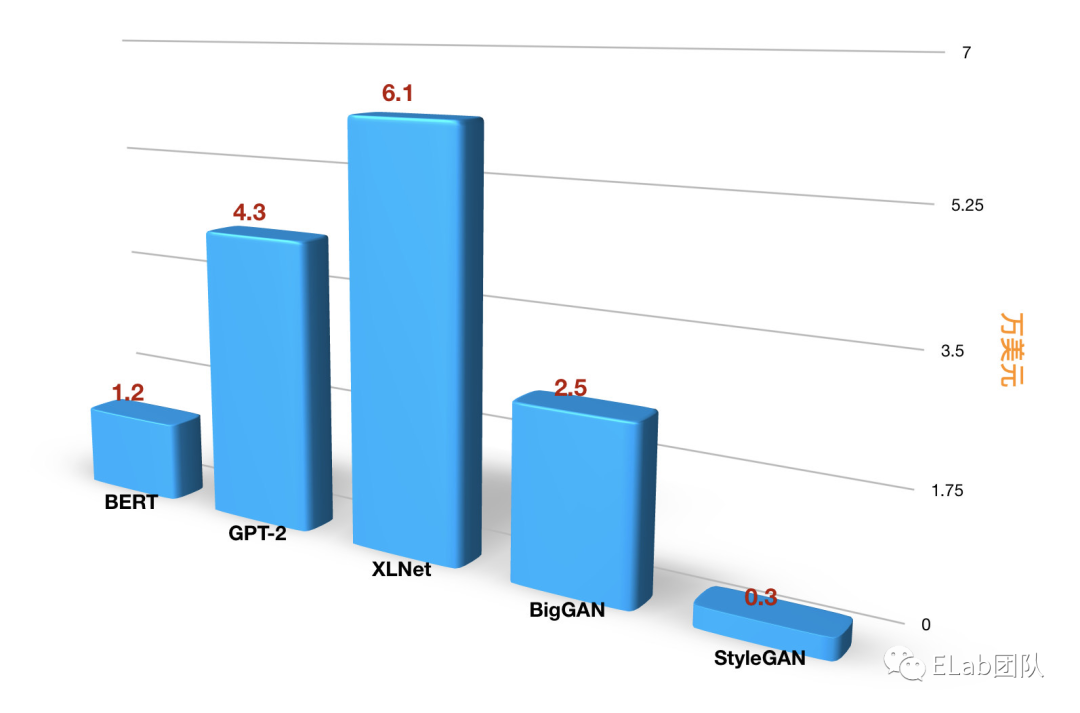
一些预训练模型的训练成本
如何使用预训练模型
很多开源的预训练模型大家会提交到 github 或者发布到 huggingface[1]中
国内也有类似 hugginface平台- 百度paddle[2],但还是 huggingface使用人最多
huggingface主要用两种方式:
方式1、借助 huggingface 封装好的 pipeline,一行代码调用
方式2、借助huggingface transformers提供的原子化 api (model、tokenizer)等完成
原子化 api使用三个步骤:
- 分词:句子拆成词,词映射为一个可用于数学计算的向量序号
- 预测:调用模型推理的过程
- 解词:推理得到的向量,反查映射表,转换为词,最后成句
预训练模型优缺点
优点:
1 . 工程角度:开箱即用;节约训练成本;减少训练时长,加速生产
2 . 模型泛化能力强:预训练模型经过海量数据训练,更好地学到了数据中的普遍特征,相比从头开始训练参数,预训练模型具有会有更好的泛化效果
存在的问题:
预训练模型就像一个 六边形战士,学到了海量数据中的特征,从而各项能力指标都不错,但在特定场景下,无法侧重学习特定业务的某些特征,从而不能像一把尖刀精准要害
那么该如何解决呢?

微调 bert模型
在bert模型基础上,微调一个中文完形填空任务
之所以选择 这个任务,是因为微调中文模型的文章比较少,而微调完形填空的就基本没有找到..
什么是Bert模型
BERT是通过 预测屏蔽子词 来进行训练的模型,这种方式在语句级的语义分析中取得了极好的效果。
屏蔽子词:先将句子中的部分词语屏蔽,再令模型去预测被屏蔽的词语
掩码例子
原句: 我爱中国
掩码后: 我爱[MASK]国
Bert 将训练文本15%的词进行掩码操作的,其中对于15% 需要掩码的词 如何掩盖也有特殊规则:
- 有80%的概率用 [MASK] 标记来替换
- 有10%的概率用随机采样的一个单词来替换
- 有10%的概率不做替换
正常效果

微调目标
可以看到模型推理的结果还不错,能推理出来常见的人名
但我们的目标是: "魔改历史",让模型 预测出来 "三国人物诸葛涛" ,实现穿越,那么该如何做呢?
微调具体操作
在线操作地址:
https://colab.research.google.com/drive/12SCpFa4gtgufiJ4JepLMuItjkWb6yfck?usp=sharing
step1、准备自定义语料
train.json


step2、定义训练器
定义训练集和测试集


step3、模型训练
训练代码

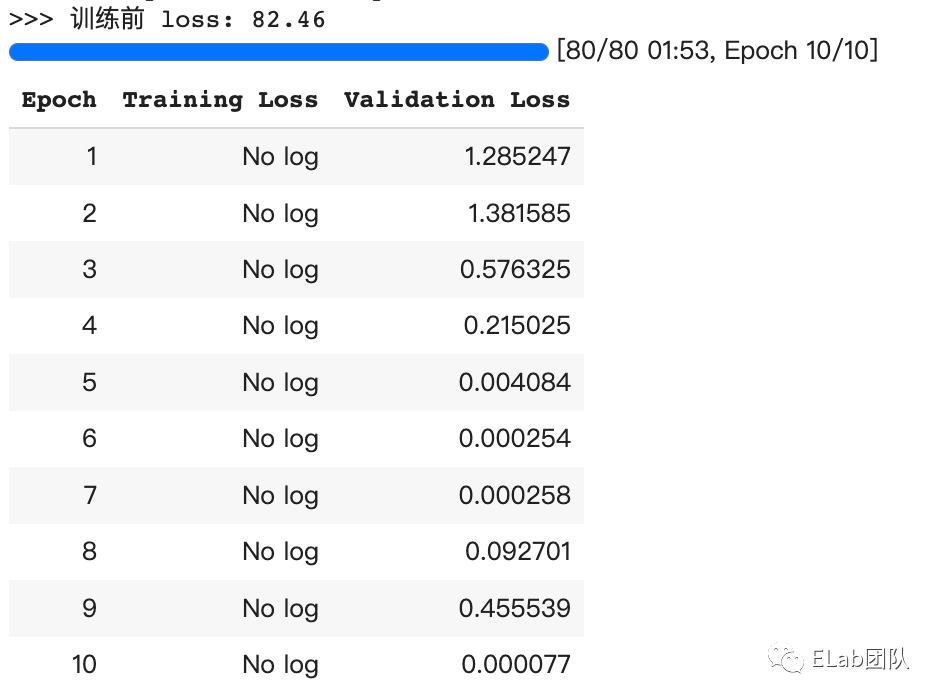

验证结果


总结
学完本篇课程,算是初探 level3 成功了!
两个flag完成了吗?
- 回顾 NLP的一些概念
- 学会微调一个 中文bert模型 完形填空任务
预训练模型是普通用户的福音,而通过微调预训练模型,每个人都可以收集构造自己的语料,打造一个自己专属的nlp模型,或许人人皆是调参工程师

参考学习
Huggingface course课程
- https://huggingface.co/course/chapter7/3?fw=pt
- https://huggingface.co/course/en/chapter5/5?fw=pt
《基于Bert模型的自然语言处理实战》
参考资料
[1]huggingface: https://huggingface.co/
[2]百度paddle: https://www.paddlepaddle.org.cn/hublist
-
END - ❤️ 谢谢支持