一图搞懂Kafka核心概念,值得收藏
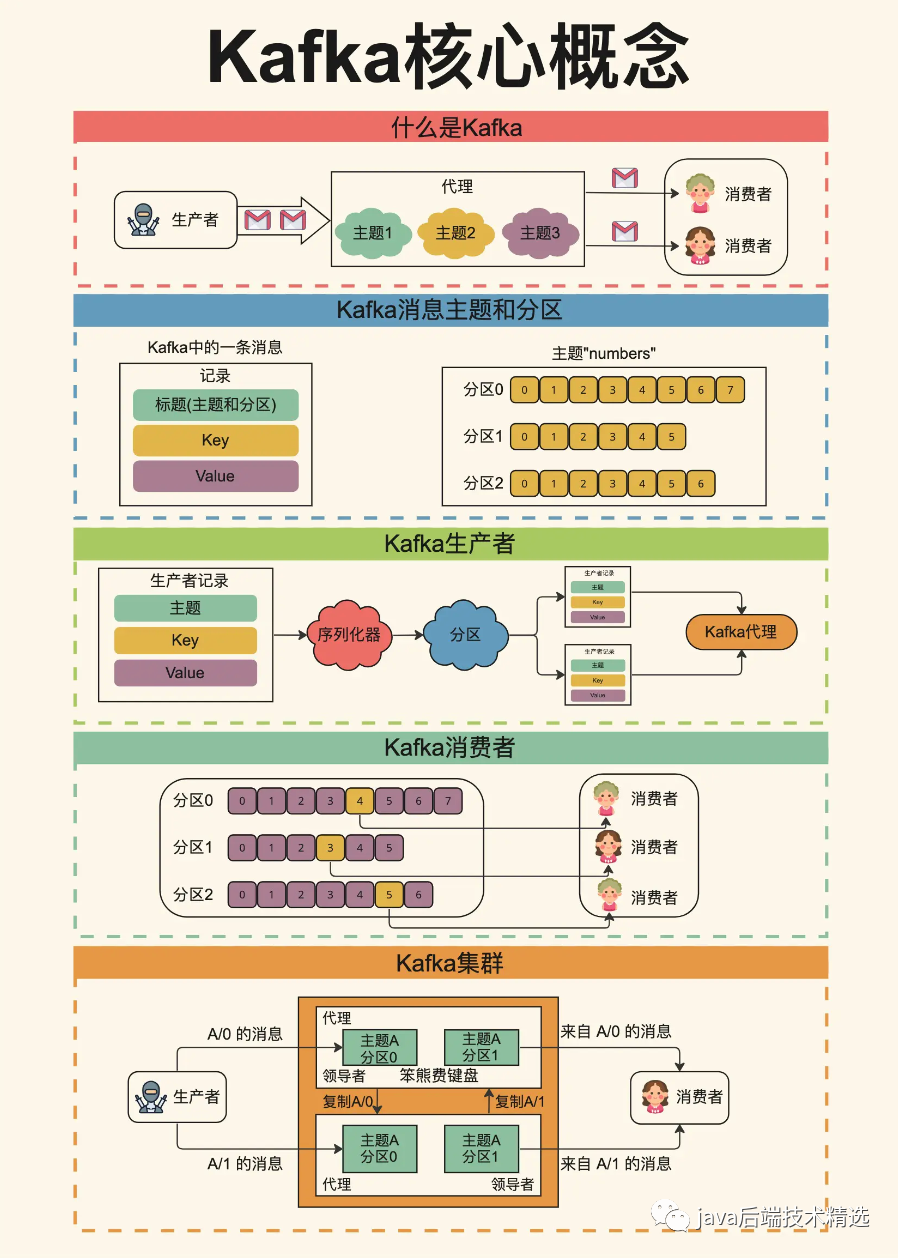
什么是kafka?Kafka是一种高性能、分布式的流数据平台,用于处理、存储和传输实时数据流。世界上一些最大的数据管道都在使用 Kafka。Netflix和Uber等的工作流程都依赖它。
Kafka 消息、主题和分区Kafka 中数据的基本单位是消息,可以将消息想象成数据库表中的记录。它以字节数组的形式传输。每条消息都会发送到一个特定的主题。您可以将 Kafka 主题与计算机上的数据库表或文件夹进行比较。主题也由多个分区组成。分区提高了冗余性并使主题可以水平扩展。
Kafka 生产者和 Kafka 消费者生产者是将消息发送到Kafka集群的应用程序或组件。它负责创建消息并将其发布到一个或多个指定的主题。生产者将消息发送到Kafka的一个分区,并负责选择要发送到的分区。生产者可以将消息发送为异步操作,也可以进行同步发送来等待消息的确认。
消费者是订阅和读取Kafka中消息的应用程序或组件。它订阅一个或多个主题,并从分区中拉取消息进行消费。消费者通过指定消费者组来进行协作,每个消费者组可以有多个消费者。每个分区只能由一个消费者组中的一个消费者进行消费,这样可以实现消息的负载均衡和并行处理
单个 Kafka 服务器称为代理。代理每秒可以处理数千个分区和数百万条消息。将代理人视为生产者和消费者之间的桥梁。它接收来自生产者的消息并处理来自消费者的获取请求。但代理人并不是孤立工作的。它作为 Kafka 集群的一部分工作Kafka 集群由多个代理组成。该集群提供复制等功能。每个分区都跨多个代理进行复制,确保高可用性和冗余。
Kafka特点
- 高吞吐量:能够处理每秒数百万条消息的高吞吐量,适用于大规模的数据流处理场景。
- 可扩展性:采用分布式架构,可以水平扩展到多个代理,实现数据的分布和负载均衡。
- 持久性:使用持久化存储引擎,将消息持久化到磁盘,确保数据的持久性和可靠性。
- 实时性:设计目标是提供低延迟的数据处理能力,使得实时数据能够及时被处理和传输。
- 可靠性:采用分布式复制机制,保证数据的冗余和容错性,确保数据不会丢失。