【Web技术】1869- spa 如何达到 ssr 的秒开技术方案——预渲染
预渲染
SPA(单页应用)在初次加载时,由于需要加载所有必要的 JavaScript 和 CSS 文件,以及应用的主 HTML 文件,因此可能会产生白屏时间较长的问题,对用户体验而言是非常糟糕的。
其中白屏时间主要影响因素之一:SPA 应用在加载完成后,需要再进行一次 DOM 渲染才能显示页面内容。在渲染过程中,可能需要加载大量的 JavaScript 文件、CSS 文件或网络请求,这些操作都需要耗费时间,从而导致白屏时间变长。
对单页面应用进行预渲染,将页面在打包期间渲染成静态 HTML 文件,可以很好的解决白屏时间过长问题
预渲染的几个优势:
- 优化 SEO
由于单页面应用通常只有一个入口 HTML 文件,因此其页面内容无法被搜素引擎爬虫捕获到。而使用预渲染功能,可以让项目构建出包含所有动态内容的静态 HTML 页面,从而被搜索引擎爬虫作为内容来源,提高 SEO 优化效果。
- 更快的加载速度
使用预渲染功能,可以将动态生成的部分预先生成静态文件,无需等到页面加载完成后再生成,从而提高网站的加载速度。
- 更好的用户体验
预渲染后,用户进入网站时可以更快地获取到内容,可以提高用户的体验。
- 减轻服务端压力
使用静态资源替代计算资源,可以减轻服务端的压力。预渲染后的页面不需要借助服务器的计算资源,减轻了服务器的压力,提高了页面处理效率。
核心流程
社区也提供了prerender-spa-plugin 这类插件,可以直接集成到项目中使用,由于得物预发、正式环境静态资源都是应用cdn的,会导致预渲染异常。本地启动服务,cdn上无对应资源。最终由团队内手动实现一款具备相同功能的static-generator插件
核心流程
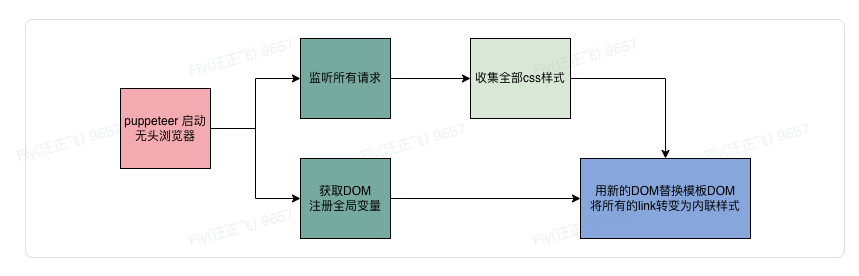
接下来通过代码简单的看一下其各个环节是如何做的
首先需要做的,定义一个gererate函数和一个Renderer类
const generate = () => {}
class Renderer {}gererate 主要是用于处理参数和流程处理
Renderer 主要是用于启动无头浏览器生成HTML
首先看一下Renderer是如何生产HTML的:
核心是使用puppeteer
Puppeteer 是一个由 Google 推出的 Node.js 库,它提供了一个高级 API ,可以使用 Headless Chrome 或 Chromium 来控制 Chrome 或 Chromium 的行为,用于测试、屏幕截图和数据爬取等。
Puppeteer 可以模拟人类的操作,比如点击、填充表单、下拉、切换页面、截图等,同时还可以拦截网络请求和处理 Cookies 等功能。由于其灵活性和易用性,许多开发者使用它进行爬虫、测试、数据分析等任务。
相关代码:利用puppeteer 启动一个无头浏览器获取页面的HTML
const getHtml = async ({ userAgent, onRequest, url }) => {
const browser = await puppeteer.launch({ headless: true, args: ['--no-sandbox', '--disable-setuid-sandbox'] }) // 启动无头浏览器
const page = await browser.newPage()
await page.setViewport({ width: 375, height: 812 })
if (userAgent) await page.setUserAgent(userAgent)
// 页面实例上下文中执行的方法
await page.evaluateOnNewDocument(() => (window['_prerender_'] = 'prerender'))
// 启用请求拦截器
await page.setRequestInterception(true)
// 监听请求
page.on('request', (request) => onRequest?.({ request, pageUrl: url, page }))
await page.goto(url)
// 页面实例上下文中执行的方法
await page.evaluate(observeRender) // 默认5000ms页面加载完成
const content = await page.content()
await page.close()
return content
}上述代码除了生成HTML外,还有一个十分重要的事情 page.on('request',(request) => onRequest),其拦截了页面的所有请求,将所有的CSS资源进行了缓存
onRequest实现
const cssContent = {}
const onRequest = asycn ({ request }) => {
const body = await read(url)
if (cssInline && filename.endsWith('.css')) {
const byteLength = body.byteLength
const { maxSize = Infinity, exclude, include } = cssInline
if (!(byteLength > maxSize || exclude?.test(filename)) && (!include || include.test(filename))) {
// 把css 先存起来
cssContent[filename] = body.toString()
}
}
return request.respond({
status: 200,
body,
})
}其核心就做了两个事情
- 获取css文件的内容
- 缓存到cssContent中,后面生成html时使用
至此已经可以获取到HTML和所有的CSS了,那么接下来要做的便是将新的HTML替换老的HTML,并将所有通过link标签引入的css资源移除,换成style标签包裹的内联CSS
再看一下gererate函数,内部首先是对参数进行格式化处理
const generate = async (config: GenerateConfigParams) => {
const generate = async (config: GenerateConfigParams) => {
const {
sourceDir, //源文件目录
staticDir = sourceDir, // 静态资源打包目录
pages, // 页面路由
baseUrl = 'https://m.dewu.com',
cdn = '',
userAgent = DWUA,
postProcess, // 处理生成后的html
inject,
} = config
const mutation = typeof config.mutation === 'string' ? [config.mutation] : config.mutation
const renderer = new Renderer()
renderer.pages = pages
renderer.baseUrl = baseUrl
renderer.userAgent = userAgent
const sourceHTMLPath = join(sourceDir, 'index.html')
renderer.postProcess = ({ html, page }) => {
if (mutation) {
const dom = new JSDOM(sourceHTML)
const newDom = new JSDOM(html)
// 将新的HTML替换老的HTML
mutation.forEach((mutation) => {
const oldNode = dom.window.document.querySelector(mutation) as HTMLElement
const newNode = newDom.window.document.querySelector(mutation) as HTMLElement
if (oldNode) {
oldNode.innerHTML = newNode?.innerHTML ?? ''
}
})
// 将所有通过link标签引入的css资源移除,换成style标签包裹的内联CSS
const links = newDom.window.document.querySelectorAll('link')
for (const link of links) {
const originHref = link.getAttribute('href') ?? ''
const content = cssContent[originHref.split('/').pop() ?? '']
if (content) {
const newStyle = dom.window.document.createElement('style')
newStyle.innerHTML = content
newStyle.setAttribute('data-href', originHref)
newStyle.setAttribute('data-css', 'inline')
dom.window.document.head.appendChild(newStyle)
const link = dom.window.document.querySelector(`link[href="${originHref}"]`)
if (link) {
link.parentElement?.removeChild(link)
}
}
}
html = dom.serialize()
}
return {
html,
page,
}
}
renderer.onRequest = () => {
// 上面的 onRequest 函数 ....
}
}
}预渲染核心的三部分便大致如上述代码,
需要注意的是:接入预渲染的时候,需要找运维同学配合修改一些Nginx的配置,
主要是对路由 进行 文件重定向
慎用三方库
业务中存在一些简单的校验、转换和动效并不需要引入三方库,尤其是因为一个较为简单的功能引入了一个较为大且冷门的库时,不仅会增加项目的打包体积,还会增加项目后续维护的沟通、学习成本。
例如下面一个简单切换动效


上述的切换动效CSS实现代码如下
@keyframes bigScale {
0% {
opacity: 0;
transform: scale(0.95);
}
to {
transform: scale(1);
opacity: 1;
}
}
@keyframes smallScale {
0% {
transform: scale(1);
opacity: 1;
}
to {
transform: scale(0.95);
opacity: 0;
}
}
.squareInCenter {
animation: 0.3s linear 0s 1 normal forwards running bigScale;
}
.squareOutCenter {
animation: 0.3s linear 0s 1 normal forwards running smallScale;
}在业务开发的过程中,尤其是C端的页面,在实现功能时对于引入额外的库是一件需要十分谨慎的事情,在内部就看到不少项目在引入关于日期处理方面的库时,dayjs、momentJS同时都会引用到项目中,B端项目都不能忍,更何况C端项目
字体使用和优化
字体加载和优化是前端开发中的一个重要问题,特别是在移动端和低网络状况下。下面是一些字体加载和优化的技巧
FOUT问题
通过设置 font-display 属性可以控制字体加载时的显示效果,包括 auto、swap、block、fallback 和 optional 几种模式,可以减少字体加载时间和防止文本闪烁
设置属性为fallback时效果

可以看到日期存在明显的FOUT(无样式文本闪现)问题,设置swap也是类似效果,并不符合预期
设置属性为block时效果

最终选择了font-display: block;效果会更好一些
注意,并不是整个页面都使用block属性,对于一些非首屏关键渲染的样式,使用fallback更为合适一些,因为其会使用浏览器默认字体,所以还是需要结合业务、场景合理使用
字体****库大小,你得懂
先看一个gpt对于签到业务常用字体库打下的统计
DIN Condensed 字体库的大小在几百KB到几MB之间
Helvetica Neue 字体库的大小在几MB到十几MB之间
也就是这两种字体的大小,如果不加以处理,全部加载的大小在几MB到十几MB之间,对于前端项目而言,这是挺夸张的一件事
可以和设计人员沟通,将字体库中常用的字体导出,前端项目仅仅引入需要的字体就好,比如DIN Condensed字体都是使用在阿拉伯数字上,并不会在其他字上使用,那么只需要将阿拉伯数字导出即可。比如汉字,根据《现代汉语通用字表》(GB/T 13000-2018),常用汉字(包括简体字和繁体字)共计3500个,其中常用的一般是指前1000个左右的汉字,那么在使用字体库的时候,是不是可以默认只需要导出部分即可。
经过处理后的字体库大小如下图

字体****库数量,你得控制
上面说了一个字体库的大小是多大,就算是经过处理,最少也会有30KB大小,所以项目引入的字体种类是需要控制的,不能设计同学使用了多少种类字体设计,我们就要照单全收
当设计同学新增字体库时,如果字体使用在3次以内,是不是可以使用图片来代替文字,或者使用现有的字体库来平替
提高稳定性
在优化的过程中,移除了大量的废弃接口、ab和代码逻辑,这样做的代价必然是会造成一些问题,毕竟不管代码现状是怎样,只要线上能跑起来就是可以的,一般也不会大刀阔斧的去改造原有的代码,本着代码可维护性(避免日后接手代码的人内心)的原则,最终还是对其动了手
既然已经选择了动手,那么就要思考一下如何确保稳定性,毕竟生产还是需要敬畏的,否则造成什么比较阻塞性的bug,那可真的是好心办坏事了,关于如何保证稳定性,我是从下面这几方面入手
可行性和风险评估
每次改动和优化代码之前,我会先对功能进行整体的回归一下,再查看对应的代码,在查看代码的过程中,我会确定几个事情
- 页面的功能是否存在多种业务逻辑判断的情况,比如符合条件A,执行弹框的逻辑,符合添加B,执行接口调用逻辑。若是业务逻辑较为复杂,那么改造和优化的成本会很大,ROI会比较低
- 是否为阻塞性的功能,比如新人引导流程的功能,这个流程出现问题则是非常严重的,这类代码保持能不动则不动
- 该功能模块迭代的频率,比如像商品流这块功能,仅近半年就经历过3次大的功能改版,每一次改版都是基于老的业务进行修修补补,导致代码就很难维护且这个痛经常存在,这种改造一下的ROI就会高一些
- 功能模块的大小和耦合度,比如下文说的MallScrollShowMore组件,其就是一个单独且较小的功能模块,改动速度快,且改造过程中关注点更多的只需要放在组件内部就好,这种改动ROI也会较高
结合上面的几点,我会综合考虑我接下来要做的事情可行性是怎样的,这么做带来的风险有多大,个人是的风格是,例如MallScrollShowMore组件,其就是一个非常独立的、功能小且非阻塞性功能的组件,可行性高,并不具备太多的改造风险,那么我就会撸起袖子干
做好记录和改动点
由于是优化中携带的代码改动,需要自己做好改动点的沉淀,不仅方便测试回归对应的地方,也便于自测
当发现组件设计或者实现有问题时,我会作记录
严格执行自测
记录只是第一步,测试周开始前,需要针对本次的所有改动进行自测,因为很多改动在这个时候,作为研发的我才是最熟悉整个项目的了,这个时候其实个人才是测试主力,测试同学帮忙回归和验证核心流程。在改造过程中记录的改动点就是测试用例,需要严格执行和回归,毕竟功能优化、改造时,自己才是第一责任人