更快更小!ProtoBuf 入门详解
什么是 Proto Buffer
Proto Buffer 是一种语言中立的、平台中立的、可扩展的序列化结构数据的方法。
Protocol Buffers are a language-neutral, platform-neutral extensible mechanism for serializing structured data.
这是来自官网 Overview 页面对于 Protobuf 的简介,抛开繁杂的修饰词,Protobuf 的核心是序列化结构数据,为了更好地理解 Protobuf,我们首先需要知道序列化是什么?
序列化指的是将一个数据结构或者对象转换为某种能被跨平台识别的字节格式,以便进行跨平台存储或者网络传输。
例如前端和后端可能使用不同的编程语言,它们内部的数据表示方式可能不兼容。序列化提供了一种语言无关的格式来表示数据,这样不同的系统就可以理解和处理这些数据。在我们日常进行前后端开发时,后端通常会返回 JSON 格式的数据,前端拿到后再进行相关的渲染,JSON 其实就是序列化的一种表现形式。而我们这里提到的 Proto Buffer 就是序列化的其他表现形式。事实上除了 JSON 与 Protobuf 还有很多种形式,例如 XML、YAML。
回到正题,我们来看看 Protobuf 所具备的特性:
- 语言中立与平台中立: Protobuf 不依赖于某一种特殊的编程语言或者操作系统的机制,意味着我们可以在多种编程环境中直接使用。(大部分序列化机制其实都具有这个特性,但是某些编程语言提供了内置的序列化机制,这些机制可能只在该语言的生态系统内有效,例如 Python 的 pickle 模块)
- 可拓展:Protobuf 可以在不破坏现有代码的情况下,更新消息类型。具体表现为向后兼容与向前兼容,这一点将在后文做出更详细的解释。
- 更小更快:序列化的目的之一是进行网络传输,在传输过程中数据流越小传输速度自然越快,可以整体提升系统性能。Protobuf 利用字段编号与特殊的编码方法巧妙地减少了要传递的信息量,并且使用二进制格式,相比于 JSON 的文本格式,更节省空间。
工作流程
假设我想要将 Person 的信息在前后端之间进行传递,如果说采用传统 JSON 的形式,那我们可能会写出下面这样的代码:
// 要发送的数据对象
const data = {
username: 'exampleUser',
password: 'examplePassword'
};
// 将数据转换为 JSON 格式的字符串
const jsonData = JSON.stringify(data);
// 发送 POST 请求
fetch('https://your-api-endpoint.com/login', {
method: 'POST', // 请求方法
headers: {
'Content-Type': 'application/json' // 指定内容类型为 JSON
},
body: jsonData // 请求体
})
.then(response => {
if (!response.ok) {
throw new Error('Network response was not ok');
}
return response.json(); // 解析 JSON 响应
})
.then(data => {
console.log(data); // 处理响应数据
})
.catch(error => {
console.error('There has been a problem with your fetch operation:', error);
});上述代码做了下面这几件事:
1.利用工具函数 JSON.stringify 将要发送的数据对象序列化。(对于复杂的数据结构,如果不进行序列化,直接发送 text/plain 的数据,后端显然是无法准确理解目标数据的,所以序列化在传输结构化的数据时起到极其重要的作用)。 2.将序列化后的数据使用 fetch 进行网络传输。 3.利用工具函数 response.json 将返回的序列化数据反序列化得到目标数据,此时反序列化后的 data 就是一个正儿八经的 JavaScript 对象,我们可以直接拿来使用。
上述过程其实就是网络传输结构化数据的通用方法,而 JSON 只是实现这一目的的常用格式。想必此时你对序列化的概念已经有了足够的理解,序列化其实就像一个翻译官,将一种编程语言中的数据结构转换成一种通用的格式,以便其他编程语言或者其他系统能够理解和处理。下面我们来看看,如果说我们使用 Proto Buffer 来作为这个翻译官,我们的工作流程是怎样的?
1.定义数据结构:首先,开发者使用.proto文件来定义数据结构。这个文件是一种领域特定语言(DSL),用来描述数据消息的结构,包括字段名称、类型(如整数、字符串、布尔值等)、字段标识号等等。
syntax = "proto3";
// 有点类似 TypeScript 的 interface
message Person {
string name = 1;
int32 id = 2;
string email = 3;
}为什么需要额外定义 proto 文件呢?Proto Buffer 能够利用该文件中的定义,去做很多方面的事情,例如生成多种编程语言的代码方便跨语言服务通信,例如借助字段编码与类型来压缩数据获得更小的字节流,再例如提供一个更加准确类型系统,为数据提供强类型保证。 听上去或许比较抽象,这里先用一个简单的例子来说明 proto 文件的好处之一:如果我们采用 JSON 进行序列化,由于 JSON 的类型比较宽松,比如数字类型不区分整数和浮点数,这可能会导致在不同的语言间交换数据时出现歧义,而 proto 中我们可以定义 float int32 等等更加具体的类型。至于其他好处,希望我能在后文中让大家逐步理解。
2.生成工具函数代码:接下来,我们需要使用 protobuf 编译器(protoc)处理.proto文件,生成对应目标语言(如C++、Java、Python等)的源代码。这些代码包含了数据结构的类定义(称为消息类)以及用于序列化和反序列化的函数。
3.使用生成的代码进行网络传输:当需要发送数据或者接收到消息对象时,我们就可以利用生成代码中所提供的序列化与反序列化函数对数据进行处理了,就像我们使用 JSON.stringify 那样。
值得注意的是,在利用 Protobuf 进行网络数据传输时,确保通信双方拥有一致的.proto 文件至关重要。缺少了相应的 .proto 文件,通信任何一方都无法生成必要的工具函数代码,进而无法解析接收到的消息数据。与 JSON 这种文本格式不同,后者即便在没有 JSON.parse 反序列化函数的情况下,人们仍能大致推断出消息内容。相比之下,Protobuf 序列化后的数据是二进制字节流,它并不适合人类阅读,且必须通过特定的反序列化函数才能正确解读数据。Protobuf 的这种设计在提高数据安全性方面具有优势,因为缺少 .proto 文件就无法解读数据内容。然而,这也意味着在通信双方之间需要维护一致的 .proto 文件,随着项目的扩展,这可能会带来额外的维护成本。
实际应用
由于笔者从事的是前端工作,所以此处将使用 Node.js 及其相关生态进行举例。由于 protobuf 官方提供的 protoc 并不直接支持由 proto 文件生成 js 代码,所以我们需要借助一些额外的工具。
仓库地址:protobuf.js | Github
- 安装所需依赖:
npm install protobufjs protobufjs-cli。 - 在 src 下新建一个 protos 目录用于存放
.proto文件,新建一个User.proto文件,添加以下内容:
syntax = "proto3";
message User {
uint32 id = 1;
string name = 2;
string email = 3;
string password = 4;
}- 在
package.json中添加一条脚本命令,该命令将会把所有的 proto 文件编译到一个 js 模块中并且生成相应的类型声明。该命令行指令的其他用法请参考上文仓库中的 README 文件。
"scripts": {
// ...
"proto": "pbjs -o ./src/protoRoot.js -w commonjs -t static-module ./src/protos/*.proto && pbts ./src/protoRoot.js -o ./src/protoRoot.d.ts",
"dev": "tsc ./src/index.ts && node ./src/index.js"
},c ./src/index.ts && node ./src/index.js"<br></br>},<br></br>尝试运行
npm run proto会得到
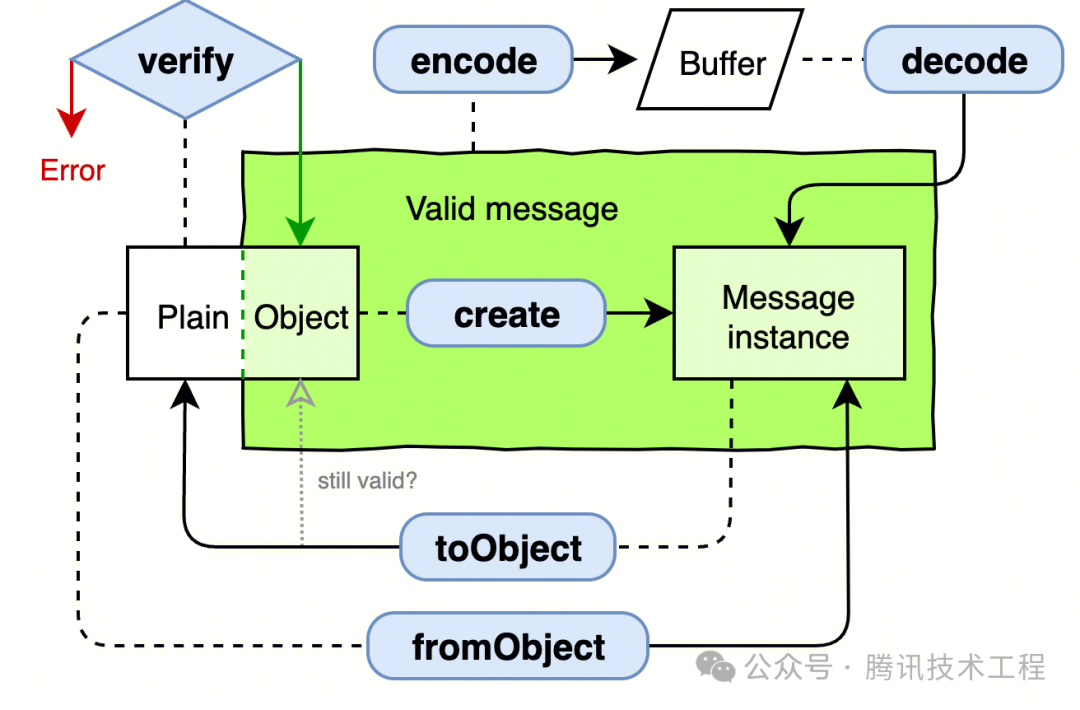
protoRoot.js简单观察,我们可以发现该文件中定义了 User 类以及一些其他的工具函数。这些工具函数的具体用法可以参考API 文档,基本的工作流程如下:
- 对原始的 JavaScript 对象使用
verify进行类型校验,随后使用create创建为消息实例,再利用encode将其编码为二进制串。 - 对于二进制串,使用
decode解码为消息实例,随后通过toObject转换为原始的 JavaScript 对象。
编写 index.ts 代码如下:该代码展示了将 JavaScript 对象序列化并进行网络传输的过程,也模拟了收到 protobuf 数据后将其反序列化的过程。
import axios from "axios";
import * as root from "./protoRoot";
const encodeMessage = ()=> {
const payload = {
id: 2333,
name: 'dora',
email: 'dora@mmm.com',
password: '123456',
deprecated: true,
}
// verify 只会校验数据的类型是否合法,并不会校验是否缺少或增加了数据项。
// 虽然上面的对象中多出了一个 deprecated 属性, 但是 verify 函数并不会报错。事实上多余的属性在 encode 时会被忽略
const invalid = root.User.verify(payload);
if( invalid) {
console.log(invalid);
throw Error(invalid);
}
const message = root.User.create(payload);
const buffer = root.User.encode(message).finish();
return buffer;
}
const buffer = encodeMessage();
axios.post('http://localhost:3000/',buffer,{
headers: {
'Content-Type': 'application/octet-stream',
responseType: 'arraybuffer',
},
}).then((res)=>{
const buffer = Buffer.from(res.data);
const message = root.User.decode(buffer);
const user = root.User.toObject(message);
console.log(user);
})
// 可以简单起一个 express 项目来模拟传输过程
const express = require("express");
const bodyParser = require("body-parser");
const app = express();
app.use(bodyParser.raw({ type: 'application/octet-stream', limit: '2mb' }));
const port = 3000;
app.post("/", (req, res) => {
const data = req.body;
console.log(data);
res.type('application/octet-stream')
res.send(data);
});
app.listen(port, () => {
console.log(`Server listening at http://localhost:${port}`);
});以上就是使用 protobuf 进行网络通信的简单 demo,事实上实际工作中可能还涉及更加复杂的过程,但由于笔者能力有限暂时无法给出比较合适的例子。在后文中我将尝试对 proto 的原理进行浅显的解释。
语法指南 v3
基本语法
让我们以上面定义的 proto 代码为例:
syntax = "proto3"; // 指定使用的语法版本, 默认情况下是 proto2
// 定义包含四个字段的消息 User
message User {
uint32 id = 1; // 字段 id 的类型为 uint32,编号 1
string name = 2; // 字段 name 的类型为 string,编号 2
string email = 3; // ...
string password = 4;
}- 需要注意的是
syntax = "proto3";必须是文件的第一个非空的非注释行。
在声明 protobuf 文件的语法版本之后,我们就可以开始定义消息结构。这个过程在语法上有点类似于 TypeScript 中的 interface 。在定义字段时,必须指明字段的类型,名称以及一个唯一的字段编号。
-
类型:proto 提供了丰富的类型系统,包括无符号整数
uint32、有符号整数sint32、浮点数float、字符串、布尔等等,你可以在这个链接中查看完整的类型描述。当然,除了为字段指定基本的类型意外,你还可以为其指定enum或是自定义的消息类型。 -
字段编号:每个字段都需要一个唯一的数字标识符,也就是字段编号。这些编号在序列化和反序列化过程中至关重要,因为他们将替代字段名称出现在序列化后二进制数据流中。在使用 JSON 序列化数据时,其结果中往往包含人类刻度的字段名称,例如
{ "id": "123456" },但是在 protobuf 中,序列化后的结果中只会包含字段编号而非字段名称,例如在本例中,id的编号为 1,那我序列化后的结果只会包含 1 而非id。这种方法有点类似于 HTTP 的头部压缩,可以显著减少传输过程中的数据流大小。 事实上字段编号的使用是 proto 中非常重要的一环,在使用中务必遵循以下原则: -
字段编号一旦被分配后就不应更改,这是为了保持向后兼容性(咱们会在后文详细说明)。
-
编号在
[1,15]范围内的字段编号在序列化时只占用一个字节。因此,为了优化性能,对于频繁使用的字段,尽可能使用该范围内的数字。同时也要为未来可能添加的常用字段预留一些编号(不要一股脑把 15 之内的编号都用了!) -
字段编号从 1 开始,最大值是 29 位,字段号
19000,19999是为 Protocol Buffers 实现保留的。如果在消息定义中使用这些保留字段号之一,协议缓冲区编译器将报错提示。 -
(可选)字段标签:除了上述三个必须设置的元素外,你还可以选择性设置字段标签:
-
optional: 之后字段被显式指定时,才会参与序列化的过程,否则该字段将保持默认值,并且不会参与序列化。在 proto3 中所有字段默认都是可选的,并不需要使用这个关键字来声明字段,除非在某些情况下我们需要区分字段是否被设置过。在 proto3 中,如果字段未被设置,它将不会包含在序列化的消息之中。在 JavaScript 中,如果一个字段被指定为 optional 并且没有设置值,在解析后的对象将不会包含该字段(如果没有指定 optional 将会包含该字段的默认值)。 -
repeated:以重复任意次数(包括零次)的字段。它们本质上是对应数据类型列表的动态数组。 -
map:成对的键/值字段类型,语法类似 Typescript 中的Record。 -
保留字段:如果你通过完全删除字段或将其注释来更新消息类型,则未来其他开发者对类型进行自己的更新时就有可能重用字段编号。当旧版本的代码遇到新版本生成的消息时,由于字段编号的重新分配,可能会引发解析错误或不预期的行为。为了避免这种潜在的兼容性问题,protobuf 提供
reserved关键字来明确标记不再使用的字段编号或标识符,如果将来的开发者尝试使用这些标识符,proto 编译器将会报错提醒。
message Foo {
reserved 2, 15, 9 to 11, 40 to max;
// 9 to 11 表示区间 [9,11], 40 to max 表示区间 [40, 编号的最大值]
reserved "foo", "bar";
}默认值
在解析消息时,如果编码的消息中并不包含某个不具有字段标签的字段,那么解析后对象中的响应字段将设置为该字段的默认值。默认值的规则如下:
- 对于
string,默认值为空字符串 - 对于
byte, 默认值为空字节 - 对于
bool, 默认值为false - 对于数字类型,默认值为 0
- 对于
enum类型,默认值为第一个定义的枚举值(编号为 0)
假设某个字段具有 optional 字段标签(或是其他什么的标签),那么在解析后的对象中将不会存在这些字段。
兼容性
如果现有的消息类型不再满足您的需求,你可以对其进行一定程度的变更。
- 如果添加新字段,请勿更改任何现有字段的字段编号。旧的消息依然能被新生成的工具函数解析,新增的字段将会使用默认值;同样,新的消息也能被旧的工具函数所解析(新增的字段将会被忽略)。
- 如果删除字段,请记得保留字段编号,以免在未来重复使用导致预期之外的错误。
- 如果你想要进行字段类型的变更,一种方式是删除原有字段随后新建一个,另外一个方式就是直接修改某些可以无缝兼容的类型(例如
int32转变为int64,显然不会丢失信息),具体有哪些属性是兼容的,可以查阅字段更新说明
除了上述提到的语法之外,其实还有很多进阶的操作,例如:
- 声明 Package 关键字区分命名空间。
- 使用 oneof 类型表示特殊的消息(包含多个字段,但这些字段在任何给定时间只能有一个字段被设置)
- 使用 service 定义定义服务端接口的请求与响应格式。
- 使用 import 导入其他文件中的消息定义。
请自行参考官方文档吧!一个包含了大部分语法特性的代码如下:
syntax = "proto3"; // 指定 protobuf 的版本
package example; // 定义包名
// 导入其他 protobuf 文件
import "google/protobuf/timestamp.proto";
import "other_package/other_file.proto";
// 定义一个枚举类型
enum State {
UNKNOWN = 0; // 枚举值必须从 0 开始
STARTED = 1;
RUNNING = 2;
STOPPED = 3;
}
// 定义一个消息类型
message Person {
// 定义一个字符串字段
string name = 1; // 字段编号必须是唯一的正整数
// 定义一个整型字段
int32 id = 2; // 这里的 2 是字段编号
// 定义一个布尔字段
bool has_pony = 3;
// 定义一个浮点字段
float salary = 4;
// 定义一个枚举字段
State state = 5;
// 定义一个重复字段(类似于列表)
repeated string emails = 6;
// 定义一个嵌套消息
message Address {
string line1 = 1;
string line2 = 2;
string city = 3;
string country = 4;
string postal_code = 5;
}
// 定义一个嵌套消息字段
Address address = 7;
// 定义一个 map 字段(类似于字典)
map<string, string> phone_numbers = 8;
// 定义一个任意类型字段
google.protobuf.Any any_field = 9;
// 定义一个时间戳字段
google.protobuf.Timestamp last_updated = 10;
// 定义一个从其他文件导入的消息类型字段
other_package.OtherMessage other_field = 11;
// 定义一个 oneof 字段,可以设置其中一个字段
oneof test_oneof {
string name = 12;
int32 id = 13;
bool is_test = 14;
}
}
// 定义一个服务
service ExampleService {
// 定义一个 RPC 方法,请求类型为 GetPersonRequest 响应类型为 Person
rpc GetPerson(GetPersonRequest) returns (Person);
}
// 定义 GetPerson RPC 方法的请求消息类型
message GetPersonRequest {
int32 person_id = 1;
}数据编码
该部分内容细节主要参考官方文档: protobuf.dev/program...
Protobuf 采用了一种称为 Tag-Length-Value(TLV)的编码方案,在开始之前,我们可以利用以下函数帮助我们打印出编码后的二进制序列方便观察:
function toBinaryString(uint8Array) {
return Array.from(uint8Array).map(byte => byte.toString(2).padStart(8, '0'));
}
/*
const payload = {
name: 'dora',
}
const message = root.User.create(payload);
const buffer = root.User.encode(message).finish();
console.log(toBinaryString(buffer));
*/现在让我们对一个 string 类型的数据 t 进行编码,可以得到序列: 00001010 00000001 01110100 。

这三个字节分别对应了 protobuf 编码的三个内容:(在 protobuf 中每个字节的首位都是控制位,用于表示随后的字节是否需要和自己属于同一个字段)
Tag
标签由字段编号与字段类型组成,其编码格式为:(field_number << 3) | wire_type
例如 0 | 0001 | 010 表示当前字段的类型是 3(010),字段编号是 1 (0001)。对于更大的字段编号例如 18,其 Tag 部分编码序列可能为: 10010010 00000001 ,第一个字节去除控制位与字段类型剩下 0010 与后续字节逆序(考虑到大端小端字节序)拼接形成 00000001 0010(2+16=18) 。这就是为什么对于频繁使用的字段最好将其字段编号设置在[1,15] 之间,因为这样编码后的 tag 部分只会占据一个字节,能有效利用空间。另外从编码后的结果来看,我们只保留了字段对应的编号,并没有把字段的名称也添加进来,这能够非常有效地减少字节流大小。
那么字段类型是什么呢?
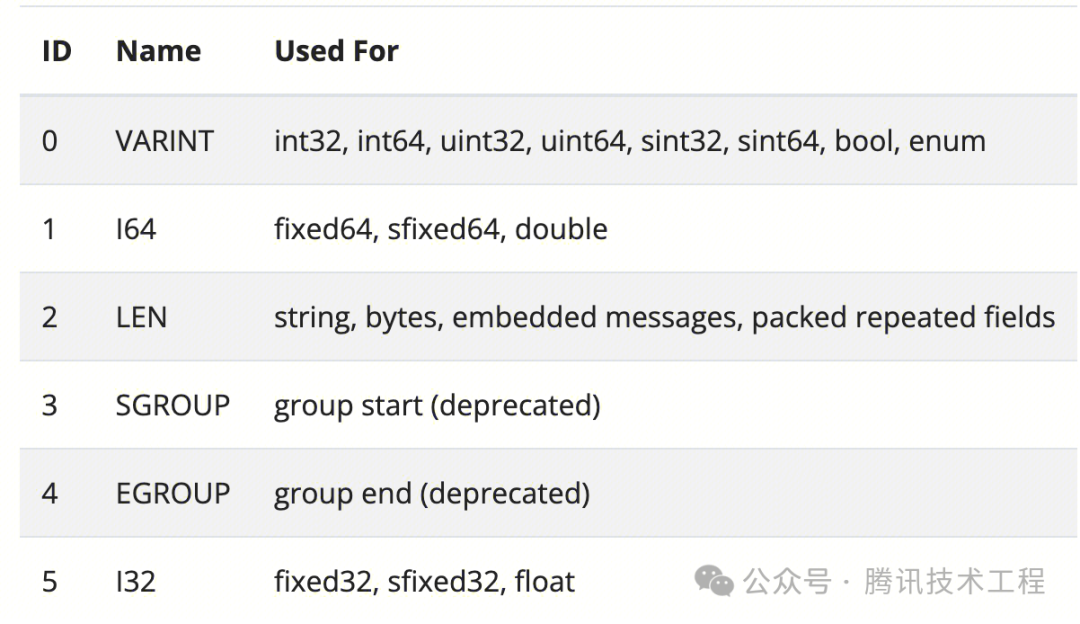
字段类型用于告诉解析器它后面的有效载荷有多大,从而允许旧的解析起跳过他们不理解的新字段。前面这句话其实是官方文档做出的解释,当个人认为理解起来较为困难。最好结合实际来看,例如对于 I32 类型 ,其有效载荷是固定 4 个字节的,也就是说 Tag 之后的 4 个字节是属于当前字段的;对于 LEN 类型,其有效载荷则需要通过后续 length 部分的编码才能确定;而对于 VARINT 类型,其有效载荷长度由编码后的数字长度决定(并不需要由 length 部分决定)。那么旧的解析器遇到未知的字段时,只需要根据不同字段类型的规则跳过特定长度的有效载荷就能够跳过那些无法理解的字段了。所有字段类型如下:
Length
对于具有长度的字段,例如字符串、列表等等,编码后的序列需要显式指定字段的长度。对于上面的例子,长度为 1 的字符串 t 编码后的第二个字节就是用来指定字符串长度的00000001,后续的字节则用来表示每个字符的 ASCII 值。
Varint 编码
Varint 编码是一种用于压缩数据的变长编码方法,特别适用于编码较小的正整数,但对于大整数和负数来说,反而会表现糟糕。 在传统的 int32 类型中,一个数字比如 150(128 + 16 + 4 + 2) 会占用四个字节: 00000000 00000000 00000000``10010110。可以发现前 3 个字节都是 0 并没有携带有效信息,导致存储空间的浪费。Varint 编码通过变长编码优化了这一点,将同样的数字 150 编码为仅需要两个字节的序列: 10010110 00000001 。
Varint 编码的工作原理如下:每个字节的最高位(最左边的一位)用作控制位,指示随后的字节是否也属于这个数的编码。如果该位为 1,则表示后续还有字节;如果是 0,则表示这是最后一个字节。每个字节剩余的七位则用于表示实际的数字。(对于变长编码,显然我们需要一个信息位来表示是否到达了编码末尾。)
10010110 00000001 // 原始字节流
// 10010110 开头的 1 说明后面字节 00000001 也是编码的一部分
0010110 0000001 // 丢弃信息位
0000001 0010110 // 由于 varint 编码时采用小段顺序,我们需要将其调换顺序转换为大段顺序
00000010010110 // 链接有效载荷
128 + 16 + 4 + 2 = 150 // 解释为无符号 64 位整数 这就是 Varint 编码的工作原理,上述例子也说明了在处理小整数时的确非常高效。但它在编码较大的整数时会需要更多的字节,这是因为每个字节只能贡献七位有效数据。对于负数,由于它们在计算机中通常以补码形式表示,这使得它们在 varint 编码中看起来像是非常大的整数,因此编码效率也不理想。例如 -5: 11111111 11111111 11111111 11111011,对于 sintN 类型的数据, protobuf 中采用的是后文将要提到 ZigZag 编码。
ZigZag 编码
工作原理:将所有整数映射成无符号整数,然后再采用 Varint 编码方式编码。 其基本思想是负数和正数进行交错,使得负数映射为奇数,例如 0 -> 0, -1 -> 1, 1 -> 2, -2 -> 3 。这样的好处是,无论正负,数值的绝对大小都能较为紧凑地表示。具体的映射方式如下:
(n << 1) ^ (n >> 31) // 32 bit
(n << 1) ^ (n >> 63) // 64 bit具体而言,当我们使用 ZigZag 对 -5 进行编码时,结果为 00001001 。
最佳实践
建议阅读官方文档:protobuf.dev/program...
- 不要重复使用字段编号,如果你想要删除某个字段,请使用
reserved关键字保留该字段对应的字段编号。 - 不要轻易改变已有字段的类型,尽管在某些情况下是安全的。
- 在单独的文件中定义广泛使用的消息类型。
- 避免使用语言的关键字作为字段名称。
- 不要依赖于 protobuf 序列化的稳定性
- map 序列化时的顺序是不确定的。
- 不要使用序列化后的内容作为 key。
- 不要通过比较序列化后的内容来确定两条消息是否相同。
个人建议:
- 常用字段尽量使用
[1,15]内的字段编码,也注意为日后可能的拓展保留该区间的字段; - 尽量使用小整数。
- 如果负数占据数据的大多数,请使用
sintN类型。
总结
序列化目的是跨平台存储或者网络传输,而 protobuf 作为一款序列化的协议,其最主要的特点就是序列化后的数据更小,传输更快并且具有良好的兼容性;主要的缺点就是通信双方必须维护好 proto 定义文件。