Redis源码解析:一条Redis命令是如何执行的?
Redis(Remote Dictionary Server)是一个开源的内存数据库,遵守 BSD 协议,它提供了一个高性能的键值(key-value)存储系统,常用于缓存、消息队列、会话存储等应用场景。本文主要向大家分享redis基本概念和流程,希望能和大家一起从源码角度分析一条命令执行过程,希望能帮助开发同学掌握redis的实现细节,提升编程水平、设计思想。
1.源码结构
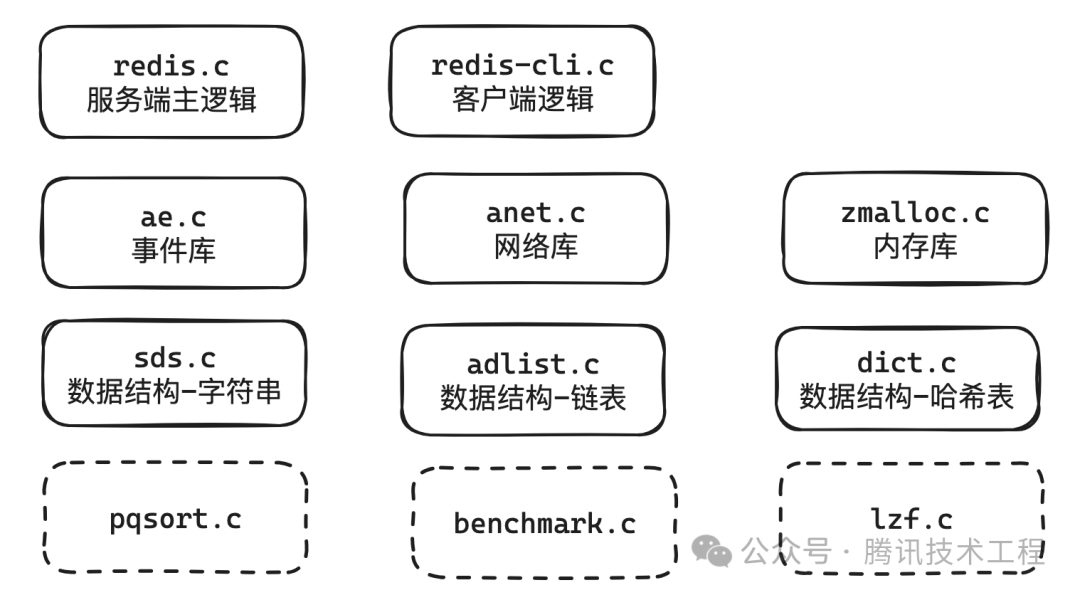
学习 Redis 源代码之前,我们需要对 Redis 代码的整体架构有一个了解,基于redis1.0源码,我们列出了主流程相关的如下源码文件。
2.核心数据结构
2.1 redisServer
redisServer是存储redis服务端运行的结构体,在启动的时候就会初始化完成,结构如下,它主要包含跟监听的socket有关的参数port和fd;对应存储数据的redisDb列表;链接的客户端列表clients;事件循环*el
struct redisServer {
int port; // 服务端监听的端口
int fd; // 服务端起的socket对应的文件句柄
redisDb *db; // redis db的列表,一般实际生产环境只用一个
// 3-lines
list *clients; // 服务端的列表
// 2 lines
aeEventLoop *el; // 事件循环
// 36 lines
};2.2 redisClient
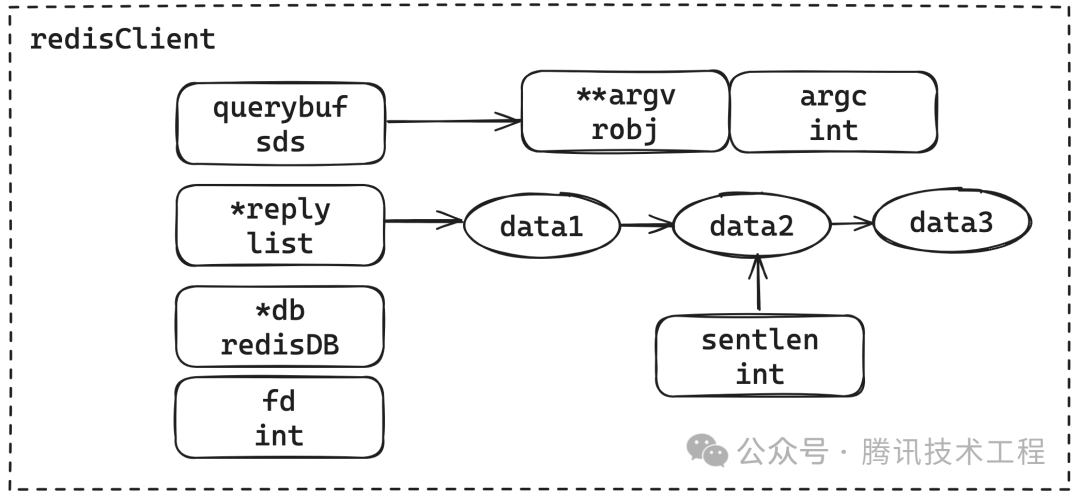
redisClient是客户端在服务端存储的状态信息,每当一个客户端与服务端链接时,都会新创建redisClient结构体到redisServer->clients列表中。
typedef struct redisClient {
int fd; // 客户端发送命令和接收结果的socket文件句柄
redisDb *db; // 对应的db
// 1-line
sds querybuf; // 查询命令存储的缓冲区
robj **argv; // 查询命令转成的命令参数
int argc; // 参数个数
// 1-lines
list *reply; // 命令执行完的回复的结果,是个列表
int sentlen; // 结果已经发送的长度
// 8-lines
} redisClient;我们也用简单的示意图展示了redisClient的结构,它包含命令传输所使用的querybuf,命令在经过处理后会存放到argv中;然后比较重要的是*reply表示服务端给到客户端的回复的数据,这是个列表会在客户端写就绪的时候一个一个写回客户端,sentlen则是标识了传输的长度;然后就是对应的db与socket句柄fd。
2.3 redisDb
redisDb是redis的键值对存储的位置,主要包含两大块,一块存储数据,另一块存储过期信信息,dict结构实际上是两个哈希表,至于为什么有两个,这里是为了做渐进式rehash使用(后面会详细介绍),rehashidx用于表示rehash进度,iterators迭代器是表示遍历集合操作个数,表里面的元素就是entry,这里面包含key和value以及指向下一个元素的指针。
typedef struct redisDb {
dict *dict; // 字典1 存储数据
dict *expires; // 字典2存储过期数据
int id; // db的id
} redisDb;
typedef struct dict {
dictType *type; // 类型,主要定义相关的函数
void *privdata;
dictht ht[2]; // 两个hash table,用于做渐进式rehash使用
int rehashidx; /* rehash进度 rehashidx == -1表示不是正在rehash*/
int iterators; /* number of iterators currently running */
} dict;
typedef struct dictht {
dictEntry **table; // 存储数据的表
unsigned long size; // 大小
unsigned long sizemask; // size-1,计算index的使用[1]
unsigned long used; // 已经使用的长度
} dictht;
typedef struct dictEntry {
void *key; // 键,在redis中一般是指向一个SDS类型的数据
union {
void *val; // 值,在redis中一般指向redisObject
uint64_t u64; // 特定情况下优化整数存储,比如过期
int64_t s64; // 特定情况下优化整数存储
} v;
struct dictEntry *next; // 下一个entry
} dictEntry;2.4 redisObject
redisObject是redis存储对象基本的表现形式,它可以存储类似SDS list set等数据结构,并且存储了一些信息用于内存管理,比如refcount这是一个整数字段,用于存储对象的引用计数。每当有一个新的指针指向这个对象时,引用计数会增加;当指针不再指向这个对象时,引用计数会减少。当引用计数降到 0 时,表示没有任何地方再使用这个对象,对象的内存可以被回收。lru在储对象的 LRU(最近最少使用)时间,这个时间戳是相对于服务器的 lruclock 的,用于实现缓存淘汰策略。当 Redis 需要释放内存时,它会根据这个时间戳来判断哪些对象是最近最少被使用的,从而决定淘汰哪些对象。
typedef struct redisObject {
void *ptr; // 指向具体数据的指针
int refcount; // 引用计数
unsigned type:4; // 类型
unsigned notused:2; // 未使用,可能是为了扩展/占位
unsigned encoding:4; // 编码方式
unsigned lru:22; // 最近最少使用
} robj;2.5 aeEventLoop
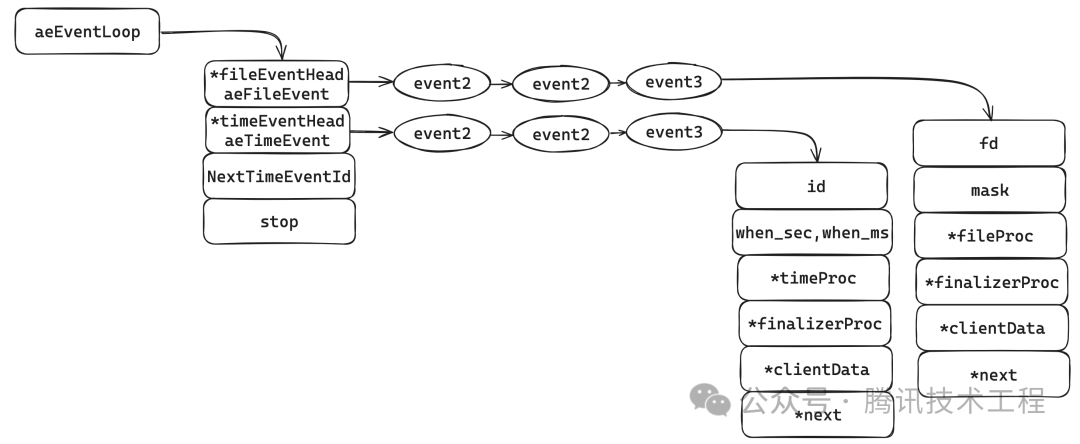
aeEventloop是redis事件模型基础数据,它主要包含文件事件和时间事件的两个链表。对于文件事件来说,包含文件句柄fd,事件类型mask,对应处理函数fileProc;对于时间事件来说包含id、执行时间(when_sec、when_ms)和对应执行函数timeProc 对应的源代码如下:
/* Types and data structures */
typedef void aeFileProc(struct aeEventLoop *eventLoop, int fd, void *clientData, int mask); // 文件事件回调函数
typedef int aeTimeProc(struct aeEventLoop *eventLoop, long long id, void *clientData); // 时间事件回调函数
typedef void aeEventFinalizerProc(struct aeEventLoop *eventLoop, void *clientData); // 事件结束时执行的函数
/* File event structure */
typedef struct aeFileEvent {
int fd; // 事件对应的文件句柄ID
int mask; /* one of AE_(READABLE|WRITABLE|EXCEPTION) */
aeFileProc *fileProc; // 文件事件回调函数
aeEventFinalizerProc *finalizerProc; // 事件结束时执行的函数
void *clientData; // 对应客户端的扩展数据
struct aeFileEvent *next; // 下一个文件事件(链表存储)
} aeFileEvent;
/* Time event structure */
typedef struct aeTimeEvent {
long long id; /* time event identifier. */
long when_sec; /* seconds */
long when_ms; /* milliseconds */
aeTimeProc *timeProc; // 事件事件回调函数
aeEventFinalizerProc *finalizerProc; // 事件结束时执行的函数
void *clientData; // 事件结束时执行的函数
struct aeTimeEvent *next;// 下一个事件(链表存储)
} aeTimeEvent;
/* State of an event based program */
typedef struct aeEventLoop {
long long timeEventNextId;
aeFileEvent *fileEventHead;
aeTimeEvent *timeEventHead;
int stop;
} aeEventLoop;2.6 小结
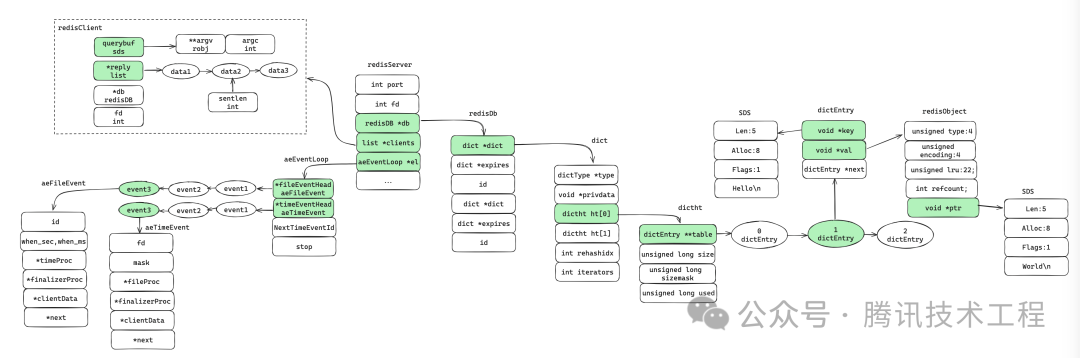
现在我们将redis核心概念的结构总结如下:
3 核心流程
了解完基本概念后,我们就看看基本流程了,首先我们从redis的main函数看起,看看启动的流程和命令执行的基本流程。
3.1 redis启动流程
3.1.1 主入口main()
在看一个软件的源码,一般从main函数看起,redis启动的main函数位于redis.c中,可以看起启动时,首先初始化了配置initServerConfig(),然后初始化了server端服务initServer(),接下来注册处理函数为acceptHandler的文件事件,然后启动了redis的主循环开始处理事件了。
int main(int argc, char **argv) {
initServerConfig(); // 初始化配置
// 8-lines 从文件中读取配置
initServer(); // 初始化服务
if (server.daemonize) daemonize(); // TODO
redisLog(REDIS_NOTICE,"Server started, Redis version " REDIS_VERSION);
// 5-lines,内存检查,加载rdb
if (aeCreateFileEvent(server.el, server.fd, AE_READABLE,
acceptHandler, NULL, NULL) == AE_ERR) oom("creating file event"); // 创建一个读的文件事件,处理者是acceptHandler
redisLog(REDIS_NOTICE,"The server is now ready to accept connections on port %d", server.port);
aeMain(server.el); // 启动redis主循环
aeDeleteEventLoop(server.el); // 主循环退出清理资源
return 0;
}然后我们看看initServer做了什么初始化,鉴于本文是阐述基本原理,因此注释掉了非主链路上的代码,可以看到它初始化了客户端列表、事件循环、db、创建了时间事件,将这几个核心的组件初始化了
static void initServer() {
// 5-lines ...
server.clients = listCreate(); // 初始化客户端列表
// 4-lines
server.el = aeCreateEventLoop(); // 初始化事件循环
server.db = zmalloc(sizeof(redisDb)*server.dbnum); // 为db分配内存
// 3-lines ...
server.fd = anetTcpServer(server.neterr, server.port, server.bindaddr); // 初始化服务端的sever socket
// 4-lines ...
for (j = 0; j < server.dbnum; j++) { // 初始化数据存储
server.db[j].dict = dictCreate(&hashDictType,NULL);
server.db[j].expires = dictCreate(&setDictType,NULL);
server.db[j].id = j;
}
// 8-lines ...
aeCreateTimeEvent(server.el, 1000, serverCron, NULL, NULL);// 初始化时间事件
}3.1.2 主循环aeEventProcess执行过程
从上一节我们知道redis在main函数中调用aeMain函数 aeMain函数则不停的循环调用aeEventProcess处理事件,redis是事件驱动的程序,他主要包含文件事件和时间事件,在aeProcessEvents中处理处理这些事件。
void aeMain(aeEventLoop *eventLoop)
{
eventLoop->stop = 0;
while (!eventLoop->stop)
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}1)将这些文件事件装到不同的集合(可读、可写、异常)中
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
// 9-line 变量初始化和前置判断
FD_ZERO(&rfds); // 清空fd集合
FD_ZERO(&wfds); // 清空fd集合
FD_ZERO(&efds); // 清空fd集合
// 检查文件事件,将它们分别放到对应的集合中
if (flags & AE_FILE_EVENTS) {
while (fe != NULL) {
if (fe->mask & AE_READABLE) FD_SET(fe->fd, &rfds);
if (fe->mask & AE_WRITABLE) FD_SET(fe->fd, &wfds);
if (fe->mask & AE_EXCEPTION) FD_SET(fe->fd, &efds);
if (maxfd < fe->fd) maxfd = fe->fd;
numfd++;
fe = fe->next;
}
}
// ...
}2)计算超时时间 在调用select()函数的时候,在监听的fd没有就绪时,会阻塞住;这里还需要处理时间事件,因此我们需要给select()设置一个超时时间,以防阻塞的时候错过了执行时间事件。超时时间计算通过找到最近的一条时间事件的执行时间计算的到
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
// 42-lines ...接上文
if (numfd || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
int retval;
aeTimeEvent *shortest = NULL;
struct timeval tv, *tvp;
if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT))
shortest = aeSearchNearestTimer(eventLoop); // 遍历timeEvent的链表,拿到最近的执行时间事件
if (shortest) {
long now_sec, now_ms;
// 计算时间差
aeGetTime(&now_sec, &now_ms); // 拿到当前时间
tvp = &tv;
tvp->tv_sec = shortest->when_sec - now_sec;// 计算秒差
if (shortest->when_ms < now_ms) { // 比较毫秒位
tvp->tv_usec = ((shortest->when_ms+1000) - now_ms)*1000; // 计算微秒差
tvp->tv_sec --;
} else {
tvp->tv_usec = (shortest->when_ms - now_ms)*1000;
}
} else { //在某些情况下,事件循环需要立即返回,而不是等待事件的发生。这通常发生在非阻塞模式下,即使没有事件发生,事件循环也不应该阻塞等待。AE_DONT_WAIT 是一个标志,用于指示事件循环在这种非阻塞模式下运行。所以此处就进尽快返回ASAP
if (flags & AE_DONT_WAIT) {
tv.tv_sec = tv.tv_usec = 0;
tvp = &tv;
} else {
// 设置为NULL,永久阻塞等待就绪
tvp = NULL; /* wait forever */
}
}
}3)执行文件事件 拿到超时时间后就开始执行事件了,首先调用select(),传入事件集合(&rfds, &wfds, &efds),拿到就绪文件事件的个数,然后开始挨个检查就绪的文件事件执行,值的注意的是在redis1.0中调用的是select()系统调用,在后续的redis版本中调用的是epoll()相关函数。
retval = select(maxfd+1, &rfds, &wfds, &efds, tvp);
if (retval > 0) {
fe = eventLoop->fileEventHead;
while(fe != NULL) {
int fd = (int) fe->fd;
// 检查fd是不是在集合里面
if ((fe->mask & AE_READABLE && FD_ISSET(fd, &rfds)) ||
(fe->mask & AE_WRITABLE && FD_ISSET(fd, &wfds)) ||
(fe->mask & AE_EXCEPTION && FD_ISSET(fd, &efds)))
{
// 求mask
int mask = 0;
if (fe->mask & AE_READABLE && FD_ISSET(fd, &rfds))
mask |= AE_READABLE;
if (fe->mask & AE_WRITABLE && FD_ISSET(fd, &wfds))
mask |= AE_WRITABLE;
if (fe->mask & AE_EXCEPTION && FD_ISSET(fd, &efds))
mask |= AE_EXCEPTION; fe->fileProc(eventLoop, fe->fd, fe->clientData, mask); // 执行文件事件中的回调函数
processed++; // 处理完成+1
fe = eventLoop->fileEventHead; // 在事件循环中处理完一个事件后,文件事件列表可能会发生变化。这种变化可能是因为在处理事件的过程中,某些操作(如关闭文件描述符、修改事件订阅等)导致了文件事件列表的更新。
FD_CLR(fd, &rfds); // 清除执行完毕的fd
FD_CLR(fd, &wfds); // 清除执行完毕的fd
FD_CLR(fd, &efds); // 清除执行完毕的fd
} else {
fe = fe->next; // 处理下一个
}
}
}4)执行时间事件 时间事件的执行就相对简单一些,主要逻辑就是比较事件执行时间是否比当前时间大了,到达执行时间便执行;另外一个点是看这个事件是一次性的还是周期性,一次性的事件要删掉;另外下一次执行的时间点是回调函数返回的,然后写到事件的结构体中
if (flags & AE_TIME_EVENTS) { // 需要处理时间事件
te = eventLoop->timeEventHead; // 取到第一个事件
maxId = eventLoop->timeEventNextId-1; // 记录最大的ID
while(te) {
long now_sec, now_ms;
long long id;
if (te->id > maxId) {// 如果ID>maxID则认为这个事件是新加的不在此次循环处理,否则可能出现无限循环的情况
te = te->next;
continue;
}
aeGetTime(&now_sec, &now_ms); //拿到当前时间
if (now_sec > te->when_sec || //比较秒
(now_sec == te->when_sec && now_ms >= te->when_ms)) // 比较毫秒
{
int retval;
id = te->id;
retval = te->timeProc(eventLoop, id, te->clientData); //执行时间事件的回调函数
if (retval != AE_NOMORE) {// 如果是不是一次性的
aeAddMillisecondsToNow(retval,&te->when_sec,&te->when_ms); //添加下一次时间事件
} else {
aeDeleteTimeEvent(eventLoop, id); //如果是一次性的删除这个时间
}
te = eventLoop->timeEventHead; // 执行完一次时间事件后,列表可能发生变化,下一次需要从头开始处理
} else {
te = te->next;
}
}3.1.3 小结
整个过程如图,简单来说:在redis启动时,在初始化配置和server的数据后,便启动了主循环aeMain,主循环的任务就是等待事件就绪和处理事件。对于文件事件,redis使用了 IO多路复用技术,通过系统调用select(),检查就绪的文件事件,就绪后则会遍历aeEventLoop进行事件处理;对于时间事件,则是与系统当前时间比较,就绪的执行。
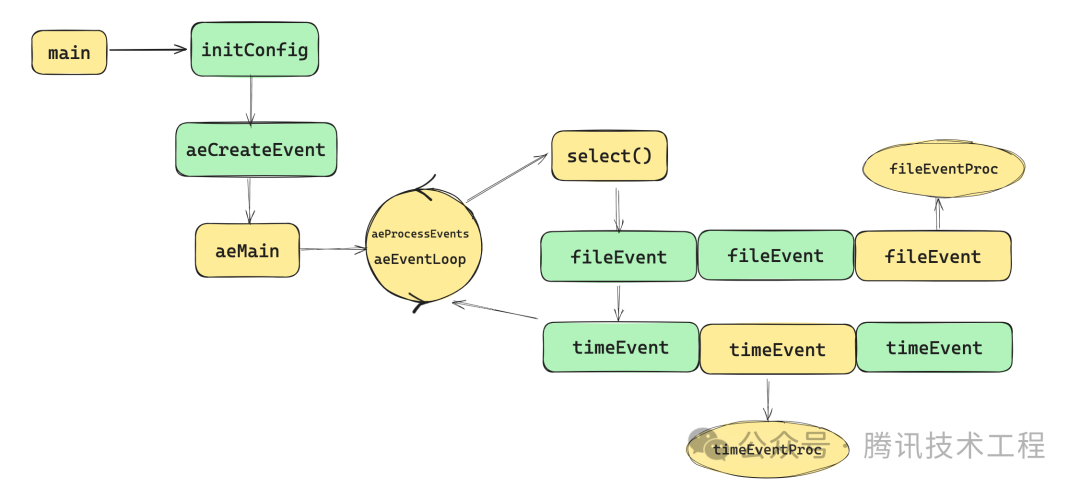
3.2 命令执行的完整流程
了解完redis整体事件驱动的运行架构后,我们看下redis的一条命令执行的过程中经过了哪些过程 简单来说有四个过程:redis启动、客户端前来连接、客户端发送命令到服务端、服务端回复结果给客户端。 下面让我们详细看看:
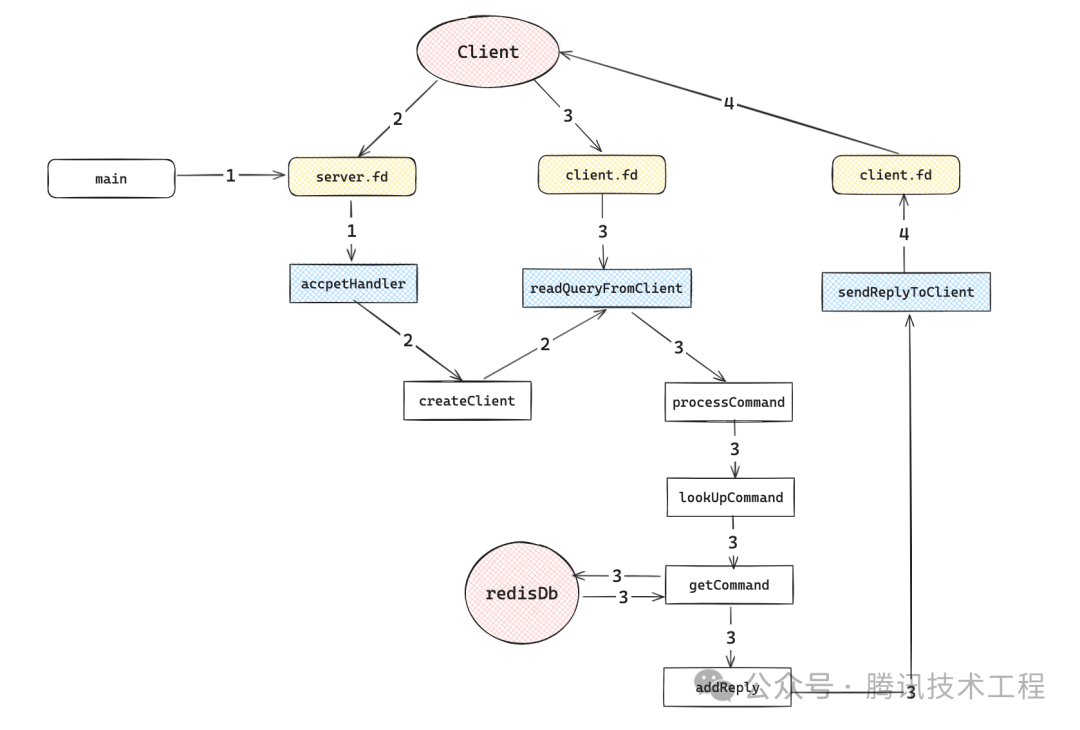
3.2.1 过程1(redis启动)
上一章中,redis在启动的时候会通过anetTcpSever创建一个socket server,再调用aeCreateFileEvent注册一个readable事件,回调函数为acceptHander,对应文件的句柄就是server的fd。
int main(int argc, char **argv) {
initServerConfig(); // 初始化配置
// 8-lines 从文件中读取配置
initServer(); // 初始化服务
if (server.daemonize) daemonize(); // TODO
redisLog(REDIS_NOTICE,"Server started, Redis version " REDIS_VERSION);
// 5-lines,内存检查,加载rdb
if (aeCreateFileEvent(server.el, server.fd, AE_READABLE,
acceptHandler, NULL, NULL) == AE_ERR) oom("creating file event"); // 创建一个读的文件事件,处理者是acceptHandler
redisLog(REDIS_NOTICE,"The server is now ready to accept connections on port %d", server.port);
aeMain(server.el); // 启动redis主循环
aeDeleteEventLoop(server.el); // 循环推出清理资源
return 0;
}3.2.2 过程2(客户端与服务端建立链接)
第一个事件中处理函数是acceptHander,顾名思义就是接收客户端了链接并进行进一步处理,首先执行了anetAccept()函数,拿到了客户端和服务端交互的文件句柄fd,接下来执行createClient()函数,创建客户端实例
static void acceptHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
// 6-lines ...
cfd = anetAccept(server.neterr, fd, cip, &cport); // 核心是执行了accept,建立了连接拿到了与client交互的cfd
if (cfd == AE_ERR) {
redisLog(REDIS_DEBUG,"Accepting client connection: %s", server.neterr);
return;
}
redisLog(REDIS_DEBUG,"Accepted %s:%d", cip, cport);
if ((c = createClient(cfd)) == NULL) { // 初始化客户端
redisLog(REDIS_WARNING,"Error allocating resoures for the client");
close(cfd); /* May be already closed, just ingore errors */
return;
}
// 如果当前客户端数量超过了 `maxclients` 的设置,服务器会接受新的连接,发送错误消息,然后关闭连接。
if (server.maxclients && listLength(server.clients) > server.maxclients) {
char *err = "-ERR max number of clients reached\r\n";
/* That's a best effort error message, don't check write errors */
(void) write(c->fd,err,strlen(err));
freeClient(c);
return;
}
server.stat_numconnections++;
}在createClient()中,初始化了redisClient的一些参数,最重要的是注册了一个文件事件,对应的执行函数是readQueryFromClient
static redisClient *createClient(int fd) {
redisClient *c = zmalloc(sizeof(*c));
// 15-lines...
listSetFreeMethod(c->reply,decrRefCount); //设置了链表 c->reply 的释放方法为 decrRefCount 函数
listSetDupMethod(c->reply,dupClientReplyValue);// 设置了链表 c->reply 的复制方法为 dupClientReplyValue 函数
if (aeCreateFileEvent(server.el, c->fd, AE_READABLE,
readQueryFromClient, c, NULL) == AE_ERR) { // 创建了一个文件事件,执行函数为readQueryFromClient
freeClient(c);
return NULL;
}
if (!listAddNodeTail(server.clients,c)) oom("listAddNodeTail");
return c;
}3.2.3 过程3 (客户端发送命令给服务端)
接上文 当客户端发送命令到服务端时,数据到达服务端经过网卡、协议栈等一系列操作后,达到可读状态后,就会执行readQueryFromClient(),处理客户端传过来的命令,首先会执行read()方法从缓冲区中读取一块数据,将其追加到c->querybuf后面,根据redis协议进行querybuf的解析,并将其转换成sds的redisObject,存储到argv中,然后执行processCommand()处理命令,注意这里只是展示主流程的代码和说明,这里为了保证客户端输入能在各种情况下都work做了比较多的校验和错误处理;另外redis客户端和服务端交互的协议有两种一种是inline的、另外一种是bulk的,在querybuf转换成argv时,根据协议不同(bulklen==-1),走的也是不同的解析逻辑。
static void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
redisClient *c = (redisClient*) privdata;
char buf[REDIS_IOBUF_LEN];
int nread;
REDIS_NOTUSED(el);
REDIS_NOTUSED(mask);
nread = read(fd, buf, REDIS_IOBUF_LEN);
// 14-lines ... 读取buf检验处理
if (nread) {
c->querybuf = sdscatlen(c->querybuf, buf, nread); // 将buf追加到querybuf后面
c->lastinteraction = time(NULL); // 更新最后一次交互时间
} else {
return;
}
again:
if (c->bulklen == -1) { // inline协议
/* Read the first line of the query */
char *p = strchr(c->querybuf,'\n');
size_t querylen;
if (p) {
// 28-lines... 处理读取的buf
// 这里将输入的参数存到argv中,argc++
for (j = 0; j < argc; j++) {
if (sdslen(argv[j])) {
c->argv[c->argc] = createObject(REDIS_STRING,argv[j]);
c->argc++;
} else {
sdsfree(argv[j]);
}
}
zfree(argv);
// 执行processCommand处理命令
if (c->argc && processCommand(c) && sdslen(c->querybuf)) goto again;
return;
} else if (sdslen(c->querybuf) >= REDIS_REQUEST_MAX_SIZE) {
redisLog(REDIS_DEBUG, "Client protocol error");
freeClient(c);
return;
}
}
// 15 lines ... bulk命令处理
}接下来我们继续看看重头戏processCommand的处理过程,首先执行lookupCommand,从cmdTable中遍历找到符合要求的命令,然后进行一些认证和数据合法性校验后,执行cmd的proc函数执行命令,执行完毕后,清理命令执行的过程数据。
static int processCommand(redisClient *c) {
// 11 lines...
cmd = lookupCommand(c->argv[0]->ptr); // 从表里面查找命令
// 46 lines ... cmd、argv、argc、内存、认证等校验
dirty = server.dirty;
cmd->proc(c); // 执行命令
// 4 lines.. 变更通知给连接的从服务器(slaves)和监控客户端(monitors)
if (c->flags & REDIS_CLOSE) {
freeClient(c);
return 0;
}
resetClient(c); // 清理client命令相关字段
return 1;
}
static struct redisCommand cmdTable[] = {
{"get",getCommand,2,REDIS_CMD_INLINE},
{"set",setCommand,3,REDIS_CMD_BULK|REDIS_CMD_DENYOOM},
{"setnx",setnxCommand,3,REDIS_CMD_BULK|REDIS_CMD_DENYOOM},
{"del",delCommand,-2,REDIS_CMD_INLINE},
{"exists",existsCommand,2,REDIS_CMD_INLINE},
{"incr",incrCommand,2,REDIS_CMD_INLINE|REDIS_CMD_DENYOOM}
}让我们以get命令为例看看 getCommand()做了什么事,首先从DB里面去查找这个key,然后调用addReply,将结果回复加到回复队列中去,可以看到它回复了协议头、数据、协议尾三段数据。
static void getCommand(redisClient *c) {
robj *o = lookupKeyRead(c->db,c->argv[1]);
if (o == NULL) {
addReply(c,shared.nullbulk);
} else {
if (o->type != REDIS_STRING) {
addReply(c,shared.wrongtypeerr);
} else {
addReplySds(c,sdscatprintf(sdsempty(),"$%d\r\n",(int)sdslen(o->ptr)));
addReply(c,o);
addReply(c,shared.crlf);
}
}
}让我们看看lookupKeyRead 做了什么,最终执行的是dict的方法dictFind,这个函数首先根据key算出在table中的位置,然后开始遍历entry链表,通过dictCompareHashKeys方法比较key是不是相等最终找到这个key取出返回。
static robj *lookupKeyRead(redisDb *db, robj *key) {
expireIfNeeded(db,key); // 检查过期
return lookupKey(db,key);
} static robj *lookupKey(redisDb *db, robj *key) {
dictEntry *de = dictFind(db->dict,key); //找到key
return de ? dictGetEntryVal(de) : NULL; //找到key对应的value
}
dictEntry *dictFind(dict *ht, const void *key)
{
dictEntry *he;
unsigned int h;
if (ht->size == 0) return NULL;
h = dictHashKey(ht, key) & ht->sizemask; // 计算在哈希表的位置
he = ht->table[h];
while(he) {
if (dictCompareHashKeys(ht, key, he->key)) // 比较entry和key是否相等
return he;
he = he->next;
}
return NULL;
}具体是怎么回复结果的呢,addReply函数通过调用aeCreateFileEvent 创建了写入类型的文件事件,然后就是尾插法将要回复的obj添加到c->reply的尾部,等待fd写就绪时执行事件
static void addReply(redisClient *c, robj *obj) {
if (listLength(c->reply) == 0 &&
(c->replstate == REDIS_REPL_NONE ||
c->replstate == REDIS_REPL_ONLINE) &&
aeCreateFileEvent(server.el, c->fd, AE_WRITABLE,
sendReplyToClient, c, NULL) == AE_ERR) return; //创建了文件事件
if (!listAddNodeTail(c->reply,obj)) oom("listAddNodeTail");
incrRefCount(obj); // 引用+1
}3.2.4 过程4 (写就绪将结果写回客户端)
当 socket 的发送缓冲区有足够空间,并且网络状态允许数据发送时,socket 变为写就绪状态时,这时候就会aeEventLoop->fileEvents中取出就绪的reply事件,执行sendReplyToClient()函数,这个函数会遍历c->reply列表,按照顺序一个一个通过调用write()方法写回给客户端,值的注意的是,Redis 限制了单次事件循环中可以写入的最大字节数(REDIS_MAX_WRITE_PER_EVENT),防止一个客户端占用所有的服务器资源,特别是当该客户端连接速度非常快(例如通过本地回环接口 loopback interface)并且发送了一个大请求(如 KEYS * 命令),如果c->reply全写完了,就干掉这个写入事件
static void sendReplyToClient(aeEventLoop *el, int fd, void *privdata, int mask) {
redisClient *c = privdata;
int nwritten = 0, totwritten = 0, objlen;
robj *o;
// 4 lines ...
while(listLength(c->reply)) {
o = listNodeValue(listFirst(c->reply)); // 取出第一个
objlen = sdslen(o->ptr); // 拿到长度
if (objlen == 0) { // 长度为零删掉
listDelNode(c->reply,listFirst(c->reply));
continue;
}
if (c->flags & REDIS_MASTER) {
/* Don't reply to a master */
nwritten = objlen - c->sentlen;
} else {
// 从上一次发送的最后的位置(c—>sentlen),发送剩余长度的数据(objlen - c->sentlen)
nwritten = write(fd, ((char*)o->ptr)+c->sentlen, objlen - c->sentlen);
if (nwritten <= 0) break;
}
c->sentlen += nwritten; // 更新已经发送的长度
totwritten += nwritten; // 更新本次事件已经发送的长度
// 如果已经发送的长度==要发送的对象长度,这个对象就发送完了,删掉
if (c->sentlen == objlen) {
listDelNode(c->reply,listFirst(c->reply));
c->sentlen = 0;
}
// 对单个客户端单个事件发送的长度进行限制,因为redis时单线程,防止一个客户端有
// 大量返回数据时,会阻塞主循环处理,导致无法服务其他客户端
if (totwritten > REDIS_MAX_WRITE_PER_EVENT) break;
}
// 9-lines...
if (totwritten > 0) c->lastinteraction = time(NULL); // 更新最后交互时间
/*
* 当Redis在事件循环中处理客户端连接的数据发送时,它会逐个取出回复列表中的数据进行发送。
* 每发送完一个数据,就从列表中删除该数据。
* 因此,如果回复列表的长度为0,说明所有的回复数据都已经发送完毕。
*/
if (listLength(c->reply) == 0) {
c->sentlen = 0;
aeDeleteFileEvent(server.el,c->fd,AE_WRITABLE);
}
}4 其他关键功能实现
4.1 过期的实现
如前文所说,redis单独有个dict记录key的过期信息
typedef struct redisDb {
dict *dict; // 字典1 存储数据
dict *expires; // 字典2存储过期数据
int id; // db的id
} redisDb;redis的key过期了不会立即删除,截止redis2.6的源码,有两种删除方式,一种是在执行key相关的命令执行之前调用expireIfNeeded(),检查key是否过期了。
static robj *lookupKeyRead(redisDb *db, robj *key) {
expireIfNeeded(db,key); // 检查过期
return lookupKey(db,key); // 查找key
}
static int expireIfNeeded(redisDb *db, robj *key) {
time_t when;
dictEntry *de;
/* No expire? return ASAP(as soon as possbile) */
if (dictSize(db->expires) == 0 ||
(de = dictFind(db->expires,key)) == NULL) return 0;
/* Lookup the expire */
when = (time_t) dictGetEntryVal(de);
if (time(NULL) <= when) return 0;
/* Delete the key */
dictDelete(db->expires,key);
return dictDelete(db->dict,key) == DICT_OK;
}另外一种是在启动的时候注册了serverCron时间事件,severcorn会定期调用activeExpireCycle()方法,这个方法核心逻辑调用dictGetRandomKey获取一些随机的key,然后检查下key是否过期了,如果过期了执行key删除和资源释放操作,值的一提的是activeExpireCycle使用了一种自适应算法来尝试过期(expire)一些超时的键。这个算法的目的是平衡 CPU 使用和内存占用,感兴趣的同学自己翻阅代码了解下。
// main()
// ->initServer();
// ->aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL);
// ->serverCron()
// ->activeExpireCycle()
void activeExpireCycle(void) {
// 21 lines......
while (num--) {
dictEntry *de;
long long t;
if ((de = dictGetRandomKey(db->expires)) == NULL) break;
t = dictGetSignedIntegerVal(de);
if (now > t) {
sds key = dictGetKey(de);
robj *keyobj = createStringObject(key,sdslen(key));
propagateExpire(db,keyobj);
dbDelete(db,keyobj);
decrRefCount(keyobj);
expired++;
server.stat_expiredkeys++;
}
}
// 7 lines .......
}4.2 渐进式rehash
4.2.1 大哈希表rehash问题
经过上文我们已经知道dict实际上是个两个拉链的哈希表,在不断的添加key的过程中,hash表的冲突会增多,导致拉链会越来越长,极端情况下,哈希表的查找速度会退化到O(n),这时候就需要进行扩容处理了,扩容时会涉及大量的key计算新的hash值转移到新表,如果key的数量很多,这将是一个成本很高的操作。在早期的redis版本中(redis 1.0时)还是直接进行rehash操作。
/* Expand or create the hashtable */
int dictExpand(dict *ht, unsigned long size)
{
// 14 lines ...
// 复制所有旧表的元素到新表
n.used = ht->used;
for (i = 0; i < ht->size && ht->used > 0; i++) {
dictEntry *he, *nextHe;
if (ht->table[i] == NULL) continue;
/* For each hash entry on this slot... */
he = ht->table[i];
while(he) {
unsigned int h;
nextHe = he->next;
/* Get the new element index */
h = dictHashKey(ht, he->key) & n.sizemask;
he->next = n.table[h];
n.table[h] = he;
ht->used--;
/* Pass to the next element */
he = nextHe;
}
}
assert(ht->used == 0);
_dictFree(ht->table);
/* Remap the new hashtable in the old */
*ht = n;
return DICT_OK;
}4.2.2 渐进式rehash出现
显然,当哈希表巨大无比的时候,这样重的操作对于单线程的redis是不可以接受的,于是redis在2.x引入了渐进式rehash的方式,渐进式rehash将大而重的rehash操作分解为一个一个小的操作,将消耗均摊到每一个add请求中,我们从set key value 看起,看看redis rehash具体是怎么做的。
4.2.3 渐进式rehash-单步rehash
首先 setGenericCommand(),最终会调用dictAddRawd()函数,dictAddRawd()会在dict中新增一个key,然后调用dictSetVal()函数将值写进去。
// setGenericCommand()
// setKey(c->db,key,val);
// dbAdd(db,key,val);
// dictAdd(db->dict, copy, val);
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key); // 调用dictAddRaw 增加一个可以
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val); // 为这个可以设置value
return DICT_OK;
}接下看看dictAddRaw(),这个函数比较清晰,首先先看看是不是正在处于rehash状态(通过判断rehashIdx == -1),如果是则进行一步rehash,然后调用 _dictKeyIndex() 拿到这个新元素在表里面的index,接下来就是为新的entry分配内存,将节点插在头部,最后设置entry的key字段。
#define dictIsRehashing(ht) ((ht)->rehashidx != -1) // 判断是否在rehash状态
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); // 是否正在rehash,如果是进行一步
if ((index = _dictKeyIndex(d, key)) == -1) // 找到新元素的index, -1表示元素已经存在
return NULL;
/* 分配内存 存储新的entry */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* 设置entry的key */
dictSetKey(d, entry, key);
return entry;
}我们重点看看_dictRehashStep做了什么,首先判断了迭代器是不是为0,判断是不是迭代器正在遍历字典,如果有则不rehash,如果没有则开始执行一步rehash,首先校验下rehash是不是正在进行,如果不是则退出;接下来通过判断d->ht[0].used == 0(ht[0]表的元素完全被转移到ht[1]中了)看看是不是rehash完了,如果是的话,将ht[1]作为主表,清理原本的ht[0],并且将rehash标志位置为-1 (d->rehashidx = -1) 当然,如果没有rehash完,则开始rehash操作,首先找到第一个不为空的槽位,然后把这个槽位以及后面的entry list一个一个转移到ht[1]中。
static void _dictRehashStep(dict *d) { // 执行单步rehash
if (d->iterators == 0) dictRehash(d,1); // 如果迭代器值为0,可以进行进行一步rehash
}
int dictRehash(dict *d, int n) {
if (!dictIsRehashing(d)) return 0; //如果没有正在rehash,撤出
while(n--) {
dictEntry *de, *nextde;
/* 检查是否全表都rehash完毕了 通过ht[0]的used判断 */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++; // 找到第一个不为0的index
de = d->ht[0].table[d->rehashidx]; // 取出这个槽位的元素
/* 将这个槽位下面的entry都移动到新表ht[1] */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask; //求出在新表的哈希值
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de; // 头插法插到新表的头部
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
return 1;
}4.2.4 rehash扩容时机
什么时候开始rehash呢,这就看_dictKeyIndex()了,它调用了_dictExpandIfNeeded()函数。
static int _dictKeyIndex(dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
/* Expand the hash table if needed */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
// 12-lines... Compute the key hash value
}_dictExpandIfNeeded()函数首先看看是不是初始化扩容,如果表ht[0]的size是0,则进行初始化扩容;如果不是则计算负载因子是不是达到了扩容的阈值,然后调用dictExpand()
static int _dictExpandIfNeeded(dict *d)
{
/* 正在进行rehash返回ok */
if (dictIsRehashing(d)) return DICT_OK;
/* ht[0].size 为0 表示这是初始化扩容 */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
// used >size 达到扩容条件;如果配置可以扩容或者达到一个安全值(影响性能的阈值)触发扩容
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) // 达到负载因子
{
return dictExpand(d, ((d->ht[0].size > d->ht[0].used) ?
d->ht[0].size : d->ht[0].used)*2); // 扩容为原来的两倍
}
return DICT_OK;
}4.2.5 渐进式rehash前置准备
dictExpand函数中,分配一个新的ht表,初始化参数,如果ht[0]是空的,说明是初始化扩容,直接将新创建的ht表给到ht[0],如果不是则将新创建的ht表给到ht[1],并且将rehashidx置为0,这时候就开始rehash了。
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}4.2.6 小结
redis渐进式rehash的过程如下图:
-
在有添加key的操作中,会调用dictAddRaw()函数,这里会根据rehashidx== -1看看是不是在rehash中,如果是则进行单步rehash;
-
另外再尝试获取一个entry的index时,redis会看看当前ht[0]表是不是该扩容了,如果是则分配ht[1]的资源并将rehashidx置为0,开始reshsh;
-
当ht[0].used变为0时,则认为rehash完成了,这时候将h[1]作为主表,释放之前h[0]的资源
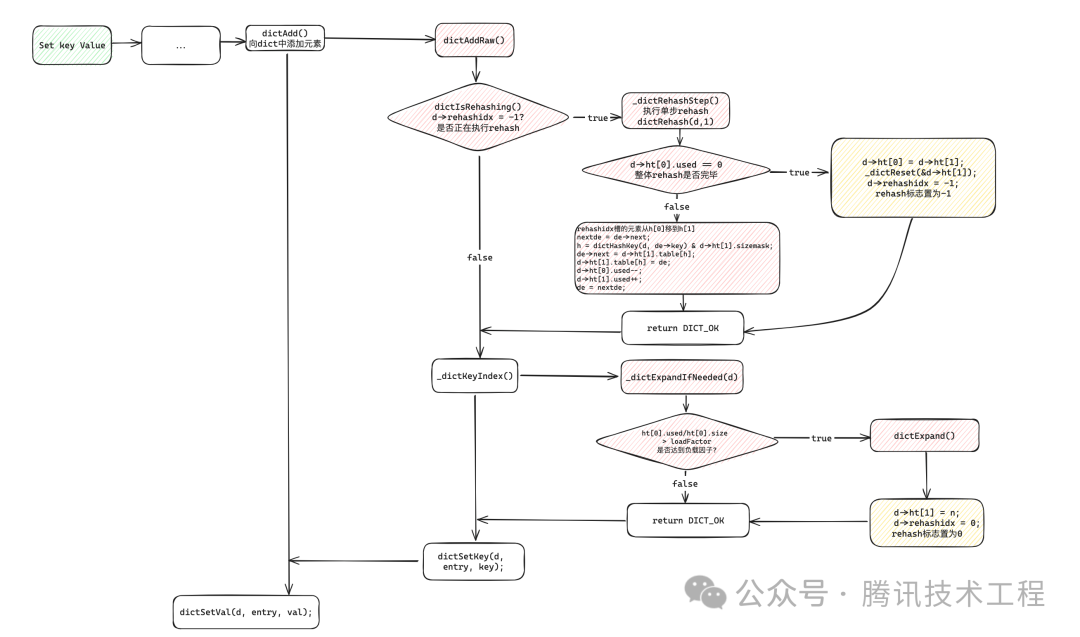
4.3 redis对象生命周期
4.3.1 redisObject与refcount
上文中我们了解到,为了高效管理内存,避免在命令处理时产生的拷贝,redis提出了share everything的思想,采用了引用计数法管理内存,计数在redisObject->refcount字段,在新创建redisObject时设置refcount为1,调用incrRefCount(),引用计数会+1
static robj *
createObject(int type, void *ptr) {
robj *o;
// 8-lines...
o->type = type;
o->ptr = ptr;
o->refcount = 1; //设置refcount为1
return o;
}
static void incrRefCount(robj *o) {
o->refcount++;
//3 -lines
}调用decrRefCount()时,会讲refcount-1,当引用计数为0时,会按照类型进行内存释放。
static void decrRefCount(void *obj) {
robj *o = obj;
// 4-lines ...
if (--(o->refcount) == 0) { // 先-- 引用计数减一;如果是0则进行内存释放
switch(o->type) {
case REDIS_STRING: freeStringObject(o); break;
case REDIS_LIST: freeListObject(o); break;
case REDIS_SET: freeSetObject(o); break;
case REDIS_HASH: freeHashObject(o); break;
default: assert(0 != 0); break;
}
if (listLength(server.objfreelist) > REDIS_OBJFREELIST_MAX ||
!listAddNodeHead(server.objfreelist,o))
zfree(o);
}
}4.3.2 set命令key/value生命周期
让我们以set命令为例,看看key和value声明周期是怎么管理的 首先从上文知道 当调用set命令发送到服务端时会调用readQueryFromClient读取并进行预处理时会调用createObject,将key和value转成redisObject放到argv中,这时候key:1 value:1
static void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
// ....
for (j = 0; j < argc; j++) {
if (sdslen(argv[j])) {
c->argv[c->argc] = createObject(REDIS_STRING,argv[j]);
c->argc++;
} else {
sdsfree(argv[j]);
}
}
// ....
}然后调用processCommand()处理命令,processCommand()通过lookupCommand()拿到:
static int processCommand(redisClient *c) {
// 11 lines...
cmd = lookupCommand(c->argv[0]->ptr); // 从表里面查找命令
// 46 lines ... cmd、argv、argc、内存、认证等校验
dirty = server.dirty;
cmd->proc(c); // 执行命令
// 4 lines.. 变更通知给连接的从服务器(slaves)和监控客户端(monitors)
if (c->flags & REDIS_CLOSE) { // 清理client命令相关字段
freeClient(c);
return 0;
}
resetClient(c);
return 1;
}最终执行了setGenericCommand(),这里如果是正常处理的话,可以看到调用了incrRefCount将argv[1]和argv[2]的引用计数都增加了1,这时候key:2 value:2
static void setGenericCommand(redisClient *c, int nx) {
int retval;
retval = dictAdd(c->db->dict,c->argv[1],c->argv[2]);
if (retval == DICT_ERR) {
if (!nx) {
dictReplace(c->db->dict,c->argv[1],c->argv[2]);
incrRefCount(c->argv[2]);
} else {
addReply(c,shared.czero);
return;
}
} else {
incrRefCount(c->argv[1]);
incrRefCount(c->argv[2]);
}
server.dirty++;
removeExpire(c->db,c->argv[1]);
addReply(c, nx ? shared.cone : shared.ok);
}在processCommand()执行结束的时候,会调用resetClient重制客户端资源为下次命令做好准备,这时候会将argv的引用计数全部-1,这时候key:1 value:1,就仅仅是dict存储的那一份了再引用了。
static int processCommand(redisClient *c) {
//
resetClient(c);
return 1;
}
static void resetClient(redisClient *c) {
freeClientArgv(c);
c->bulklen = -1;
}
static void freeClientArgv(redisClient *c) {
int j;
for (j = 0; j < c->argc; j++)
decrRefCount(c->argv[j]);
c->argc = 0;
}小结:整个过程可以通过下图看到:
-
命令处理时,createObject()得到keyObj valueObj,refcount都为1
-
执行setCommand的时候,调用了incrRefCount()方法,两者refCount都变为2
-
在processCommand调用结束的时候,执行resetClient清理资源为下条做准备时,执行了decrRefCount,两者又都变为1,此时,key val的引用计数为1,即在dict中存在的一个引用
get命令我们不过多阐述,这里阐述下具体过程:
-
命令处理时,createObject()得到keyObj valueObj,key refcount为1
-
然后调用getCommand后,再调用dictFind,在找到后addreply的时候调用了incrRefCount(),value的refcount此时从1变为2
-
在命令执行完毕的时候,会重置客户端,执行了decrRefCount,此时key的refcount变为0,被清除掉
-
在reply元素传输完毕删除的时候调用listDelNode删除元素,然后会调用list->free函数,free函数实际上是decrRefCount,这是value的refcount由2变为1。

5 参考
6 总结与展望
本文阐述了三方面的基本内容:
- redis基本的概念,包含redisServer redisDb redisClient aeEventLoop等核心概念;
- 介绍了redis启动和命令处理的基本流程;
- 介绍了重要的过程,过期、渐进式rehash和redisObject生命周期,当然redis 除了本文介绍了单机方面的一些知识外,还有分布式、集群、数据结构等很多值得学习的地方。