详解区块链P2P网络
写于2018-03-13 原文链接:http://keeganlee.me/post/blockchain/20180313
根据前一篇文章《从微观到宏观理解区块链》我们已经了解到,微观上,区块链本质就是一种不可篡改且可追踪溯源的哈希链条;宏观上,还具备了另外三个基本特征:分布式存储、P2P 网络和共识机制。分布式存储无非就是网络上大部分节点都保存了整条区块链,这容易理解也不复杂,所以就没必要再展开细讲了。但区块链的 P2P 网络和共识机制相对则复杂得多,因此我将用两篇文章分别展开讲讲这两部分内容,本篇文章就先来了解区块链的 P2P 网络。
P2P 网络
由于大部分人对 P2P 网络了解甚少,因此有必要先聊聊 P2P 网络的一些基本原理。这个章节的内容主要来自《P2P对等网络原理与应用》这本书,这本书较为系统地介绍了 P2P 的理论基础,非常适合希望全面掌握 P2P 知识的初级读者,建议大伙都可以看看。
P2P 网络不同于传统的客户端/服务端(client/server,C/S)结构,P2P 网络中的每个节点都可以既是客户端也是服务端,因此也不适合使用 HTTP 协议进行节点之间的通信,一般都是直接使用 Socket 进行网络编程。
P2P 主要存在四种不同的网络模型,也代表着 P2P 技术的四个发展阶段:集中式、纯分布式、混合式和结构化模型。不过需要指出的是,这里所说的网络模型主要是指路由查询结构,即不同节点之间如何建立连接通道,两个节点之间一旦建立连接,具体传输什么数据则是两个节点之间的事情了。
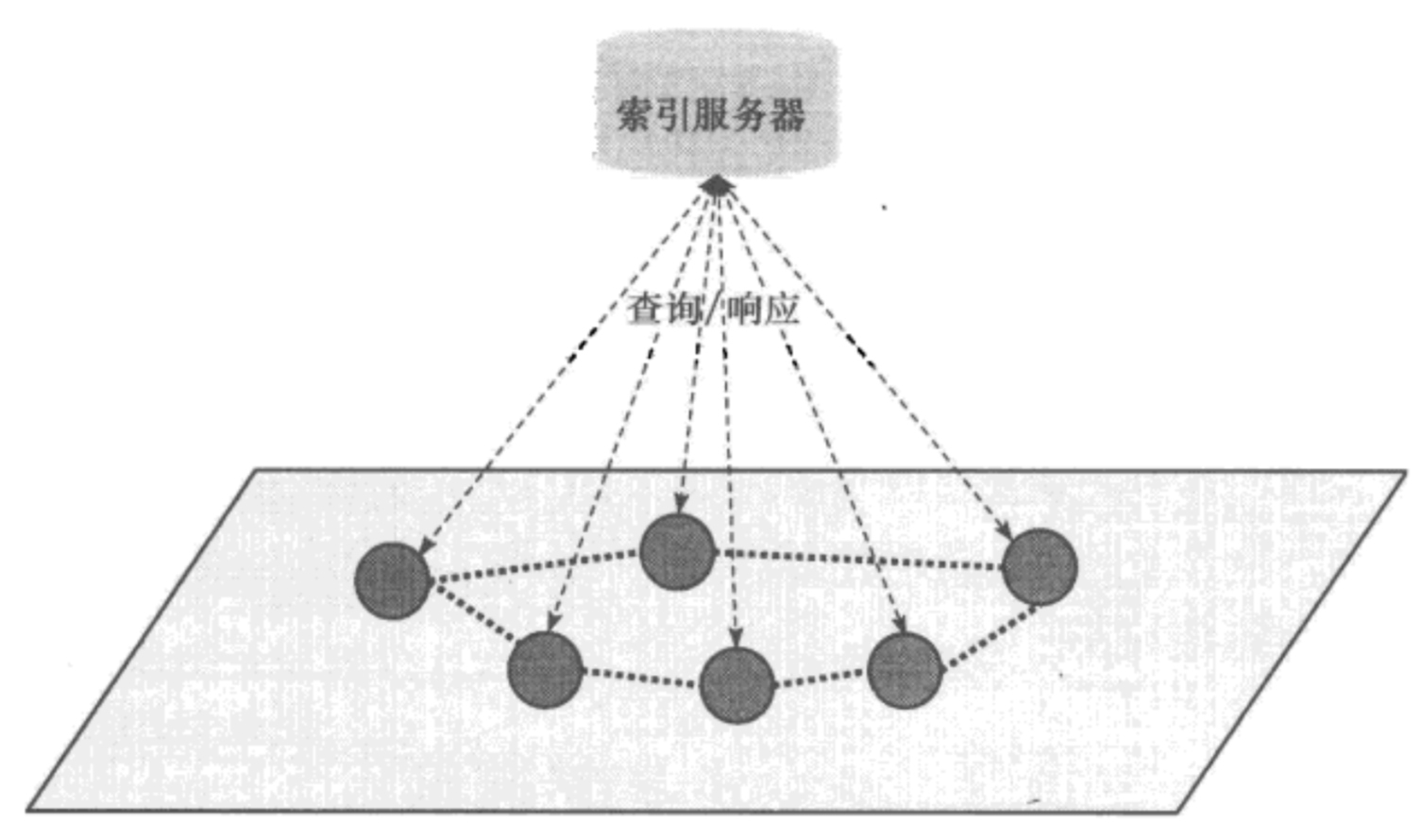
最简单的路由方式就是集中式,即存在一个中心节点保存了其他所有节点的索引信息,索引信息一般包括节点 IP 地址、端口、节点资源等。集中式路由的优点就是结构简单、实现容易。但缺点也很明显,由于中心节点需要存储所有节点的路由信息,当节点规模扩展时,就很容易出现性能瓶颈;而且也存在单点故障问题。
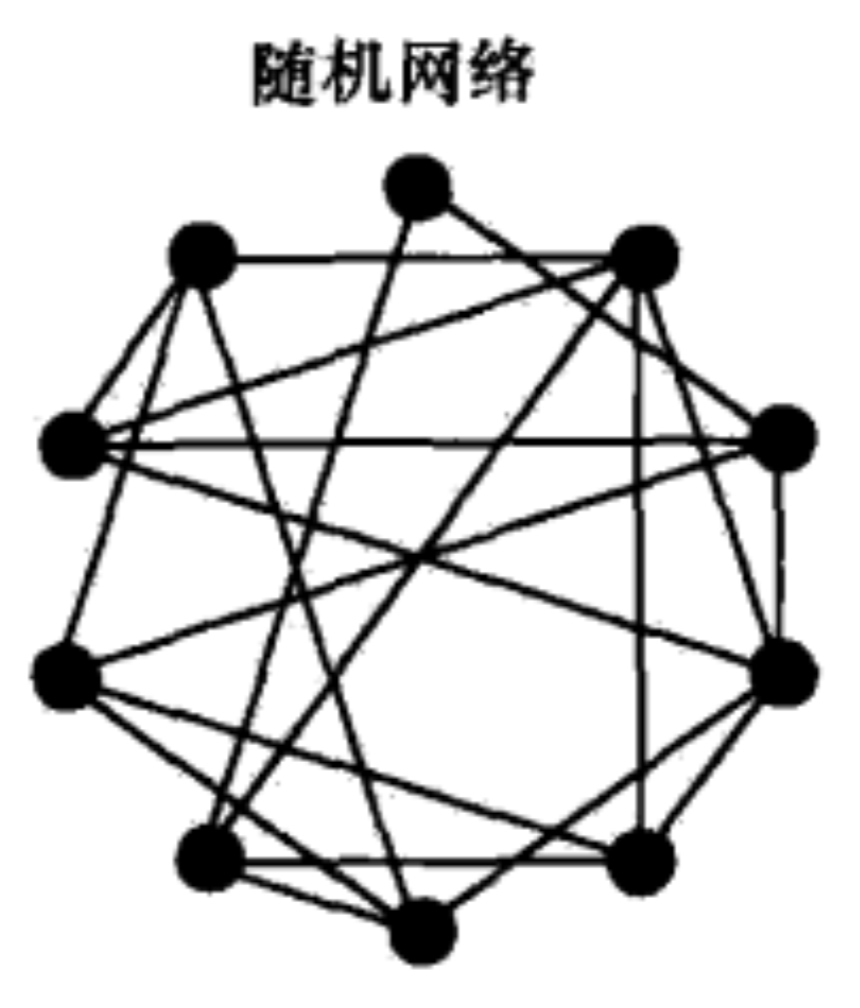
那第二种路由结构则是纯分布式的,移除了中心节点,在 P2P 节点之间建立随机网络,就是在一个新加入节点和 P2P 网络中的某个节点间随机建立连接通道,从而形成一个随机拓扑结构。新节点加入该网络的实现方法也有很多种,最简单的就是随机选择一个已经存在的节点并建立邻居关系。像比特币的话,则是使用 DNS 的方式来查询其他节点,DNS 一般是硬编码到代码里的,这些 DNS 服务器就会提供比特币节点的 IP 地址列表,从而新节点就可以找到其他节点建立连接通道。新节点与邻居节点建立连接后,还需要进行全网广播,让整个网络知道该节点的存在。全网广播的方式就是,该节点首先向邻居节点广播,邻居节点收到广播消息后,再继续向自己的邻居节点广播,以此类推,从而广播到整个网络。这种广播方法也称为泛洪机制。纯分布式结构不存在集中式结构的单点性能瓶颈问题和单点故障问题,具有较好的可扩展性,但泛洪机制引入了新的问题,主要是可控性差的问题,包括两个较大的问题,一是容易形成泛洪循环,比如节点 A 发出的消息经过节点 B 到 节点 C,节点 C 再广播到节点 A,这就形成了一个循环;另一个棘手问题则是响应消息风暴问题,如果节点 A 想请求的资源被很多节点所拥有,那么在很短时间内,会出现大量节点同时向节点 A 发送响应消息,这就可能会让节点 A 瞬间瘫痪。
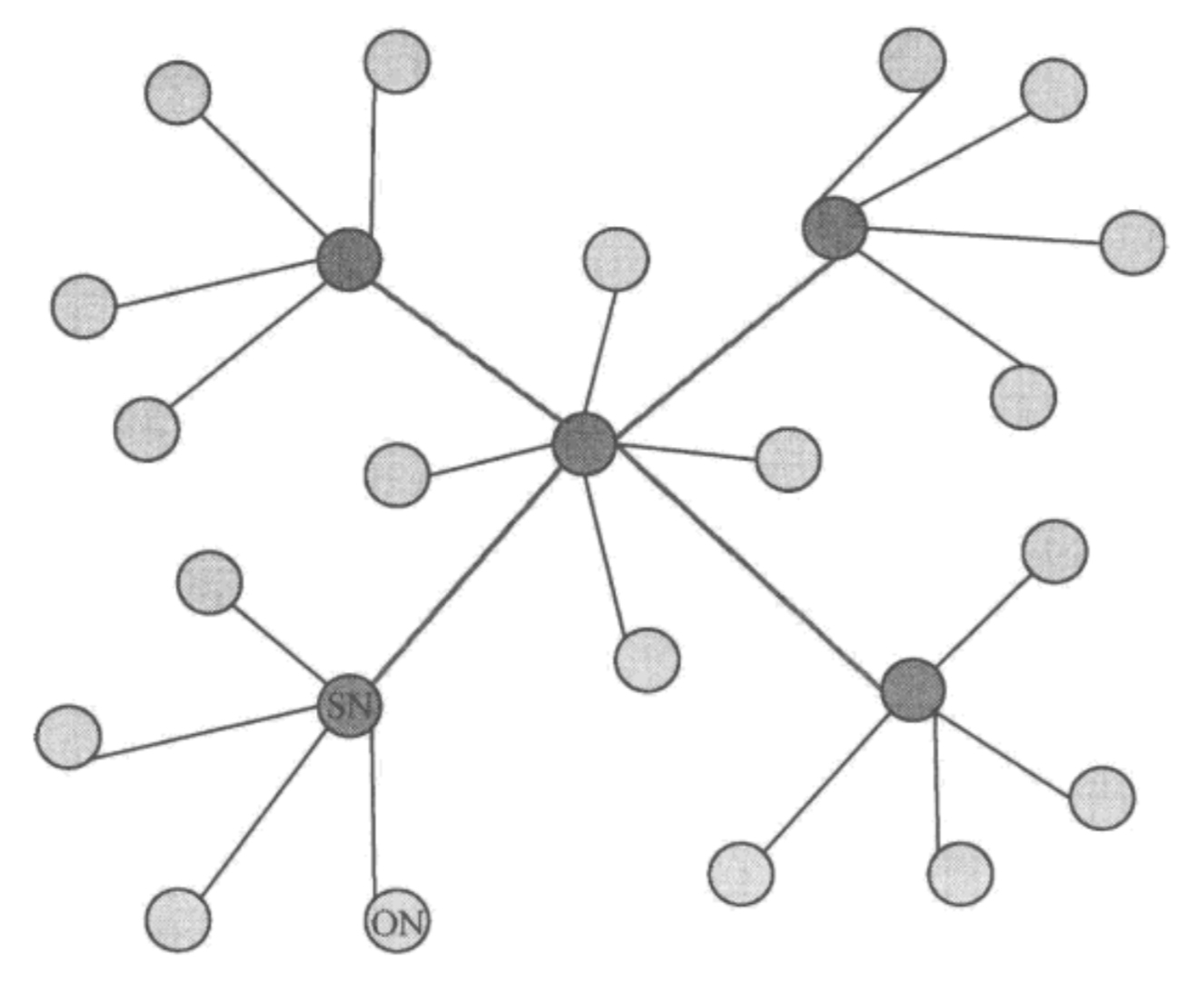
再来看看第三种路由结构:混合式。混合式其实就是混合了集中式和分布式结构,如下图所示,网络中存在多个超级节点组成分布式网络,而每个超级节点则有多个普通节点与它组成局部的集中式网络。一个新的普通节点加入,则先选择一个超级节点进行通信,该超级节点再推送其他超级节点列表给新加入节点,加入节点再根据列表中的超级节点状态决定选择哪个具体的超级节点作为父节点。这种结构的泛洪广播就只是发生在超级节点之间,就可以避免大规模泛洪存在的问题。在实际应用中,混合式结构是相对灵活并且比较有效的组网架构,实现难度也相对较小,因此目前较多系统基于混合式结构进行开发实现。其实,比特币网络如今也是这种结构,后面再细说。
最后一种网络则是结构化 P2P 网络,它也是一种分布式网络结构,但与纯分布式结构不同。纯分布式网络就是一个随机网络,而结构化网络则将所有节点按照某种结构进行有序组织,比如形成一个环状网络或树状网络。而结构化网络的具体实现上,普遍都是基于 DHT(Distributed Hash Table,分布式哈希表) 算法思想。DHT 只是提出一种网络模型,并不涉及具体实现,主要想解决如何在分布式环境下快速而又准确地路由、定位数据的问题。具体的实现方案有 Chord、Pastry、CAN、Kademlia 等算法,其中 Kademlia 也是以太坊网络的实现算法,很多常用的 P2P 应用如 BitTorrent、电驴等也是使用 Kademlia。因为篇幅有限,就不展开讲这些算法的具体原理了。目前,我们主要理解 DHT 的核心思想即可。
在 P2P 网络中,可以抽象出两种空间:资源空间和节点空间。资源空间就是所有节点保存的资源集合,节点空间就是所有节点的集合。对所有资源和节点分别进行编号,如把资源名称或内容用 Hash 函数变成一个数值(这也是 DHT 常用的一种方法),这样,每个资源就有对应的一个 ID,每个节点也有一个 ID,资源 ID 和节点 ID 之间建立起一种映射关系,比如,将资源 n 的所有索引信息存放到节点 n 上,那要搜索资源 n 时,只要找到节点 n 即可,从而就可以避免泛洪广播,能更快速而又准确地路由和定位数据。当然,在实际应用中,资源 ID 和节点 ID 之间是无法做到一一对应的,但因为 ID 都是数字,就存在大小关系或偏序关系等,基于这些关系就能建立两者的映射关系。这就是 DHT 的核心思想。DHT 算法在资源编号和节点编号上就是使用了分布式哈希表,使得资源空间和节点空间的编号有唯一性、均匀分布式等较好的性质,能够适合结构化分布式网络的要求。
综上,这就是 P2P 网络的一点理论基础,不同的区块链可能会使用不一样的网络模型,但基本原理是一样的。后面分别讲解下最有代表性的两个区块链的网络:比特币网络和以太坊网络。
比特币网络
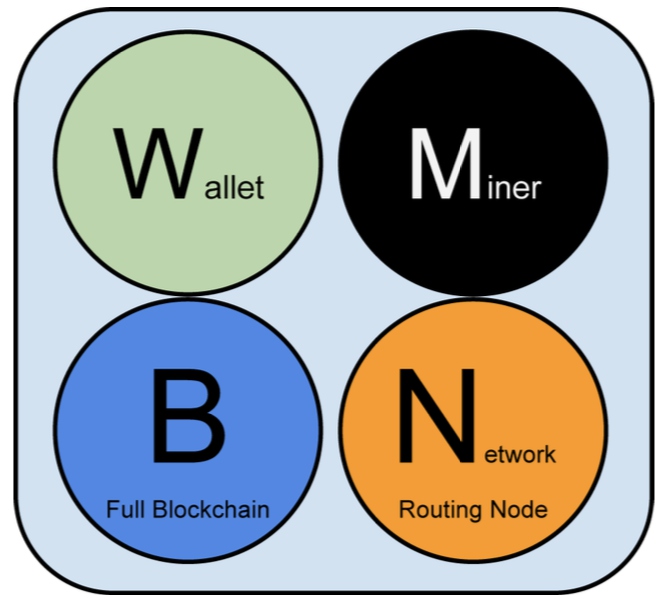
首先,比特币网络中的节点主要有四大功能:钱包、挖矿、区块链数据库、网络路由。每个节点都会具备路由功能,但其他功能不一定都具备,不同类型的节点可能只包含部分功能,一般只有比特币核心(bitcoin core)节点才会包含所有四大功能。
所有节点都会参与校验和广播交易及区块信息,且会发现和维持与其他节点的连接。有些节点会包含完整的区块链数据库,包括所有交易数据,这种节点也称为全节点(Full Node)。另外一些节点只存储了区块链数据库的一部分,一般只存储区块头而不存储交易数据,它们会通过“简化交易验证(SPV)”的方式完成交易校验,这样的节点也称为 SPV节点或轻节点(Lightweight Node)。钱包一般是 PC 或手机客户端的功能,用户通过钱包查看自己的账户金额、管理钱包地址和私钥、发起交易等。除了比特币核心钱包是全节点之外,大部分钱包都是轻节点。挖矿节点则通过解决工作量证明(PoW)算法问题,与其他挖矿节点相互竞争创建新区块。有些挖矿节点同时也是全节点,即也存储了完整的区块链数据库,这种节点一般都是独立矿工(Solo Miner)。还有一些挖矿节点不是独立挖矿的,而是和其他节点一起连接到矿池,参与集体挖矿,这种节点一般也称为矿池矿工(Pool Miner)。这会形成一个局部的集中式矿池网络,中心节点是一个矿池服务器,其他挖矿节点全部连接到矿池服务器。矿池矿工和矿池服务器之间的通信也不是采用标准的比特币协议,而是使用矿池挖矿协议,而矿池服务器作为一个全节点再与其他比特币节点使用主网络的比特币协议进行通信。
在整个比特币网络中,除了不同节点间使用比特币协议作为通信协议的主网络,也存在很多扩展网络,包括上面提到的矿池网络。不同的矿池网络可能还会使用不同的矿池挖矿协议,目前主流的具体矿池协议应该是 Stratum协议,该协议除了支持挖矿节点,也支持瘦客户端钱包。一个包含了比特币协议主网络各种节点和 Stratum 网络,以及其他矿池网络的扩展比特币网络大概如下图所示:
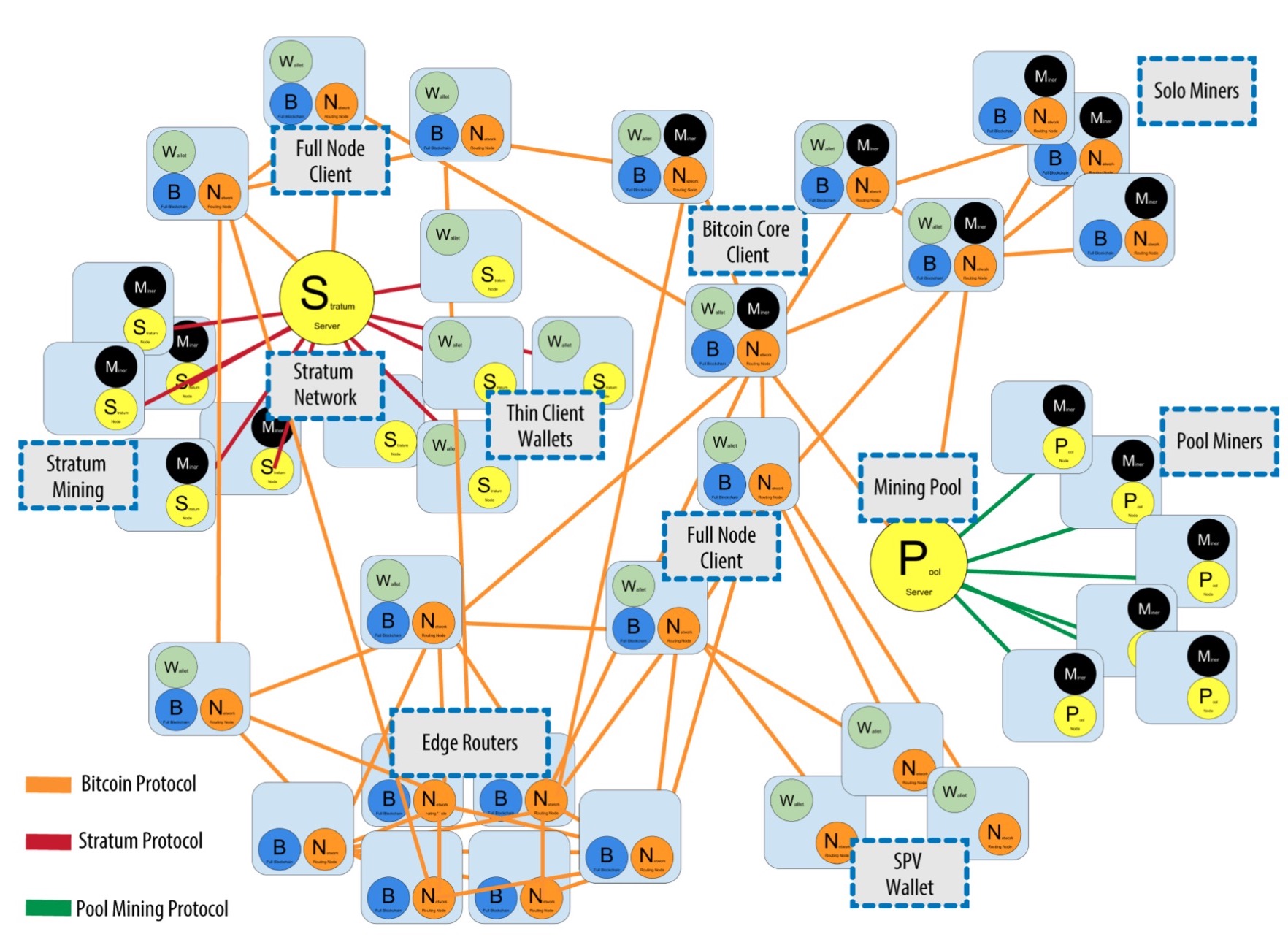
另外,挖矿这块还有特殊需求。我们知道,矿工创建新区块后,是需要广播给全网所有节点的,当全网都接受了该区块,给矿工的挖矿奖励才算是有效的,这之后才好开始下一个区块 Hash 的计算。所以矿工必须最大限度缩短新区块的广播和下一个区块 Hash 计算之间的时间。如果矿工之间传播区块只采用上图所示的比特币协议网络,那无疑会有很高的网络延迟,所以,需要一个专门的传播网络用来加快新区块在矿工之间的同步传播,这个专门网络也叫比特币传播网络或比特币中继网络(Bitcoin Relay Network)。
以太坊网络
和比特币一样,以太坊的节点也具备钱包、挖矿、区块链数据库、网络路由四大功能,也同样存在很多不同类型的节点,除了主网络之外也同样存在很多扩展网络。但与比特币不同的,比特币主网的 P2P 网络是无结构的,但以太坊的 P2P 网络是有结构的。前面我们已经提过,以太坊的 P2P 网络主要采用了 Kademlia(简称 Kad) 算法实现,Kad 是一种分布式哈希表(DHT)技术,使用该技术,可以实现在分布式环境下快速而又准确地路由、定位数据的问题。所以,下面主要讲解下以太坊的 Kad 网络。
在 Kad 网络中,每个节点都具有一个唯一的节点 ID。另外,也会计算不同节点之间的距离,但这个距离不是物理上的距离,而是逻辑上的距离,是通过对两个节点 ID 进行 异或(符号为^) 计算得到的,即 A、B 两节点之间的距离的计算公式为:D(A,B) = A.ID^B.ID。异或有一个重要的性质:假设 a、b、c 为任意三个数,如果 a^b = a^c 成立,那就一定 b = c。因此,如果给定一个结点 a 和距离 L,那就有且仅有一个结点 b, 会使得 D(a,b) = L。通过这种方式,就能有效度量 Kad 网络中不同节点之间的逻辑距离。
在异或距离度量的基础上,Kad 还可以将整个网络拓扑组织成如下图所示的一个二叉前缀树,每个 NodeID 会映射到二叉树上的某个叶子。
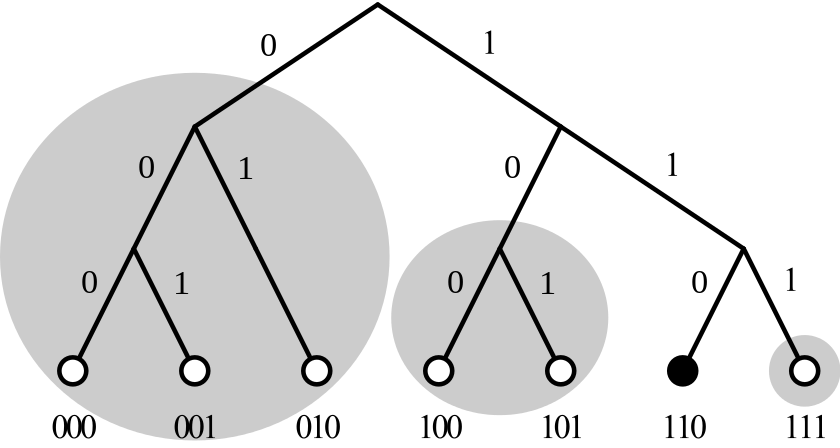
映射规则主要是:
- 将 NodeID 以二进制形式表示,然后从高到低对每一位的 0 或 1 依次处理;
- 二进制的第 n 位就对应了二叉树的第 n 层;
- 如果该位是 0,进入左子树,是 1 则进入右子树(反过来也可以);
- 全部位都处理完后,这个 NodeID 就对应了二叉树上的某个叶子。
在这种二叉树结构下,对每个节点来说,离它越近的节点异或距离也是越近的。接着,可以按照离自己异或距离的远近,对整颗二叉树进行拆分。拆分规则是:从根节点开始,将不包括自己的那颗子树拆分出来,然后在包含自己的子树中,把不包括自己的下一层子树再拆分出来,以此类推,直到只剩下自己。以上图的 110 节点为例,从根节点开始,由于 110 节点在右子树,所以将左边的整颗子树拆分出来,即包含 000、001、010 这三个节点的这颗子树;接着,到第二层子树,将不包含 110 节点的左子树再拆分出来,即包含 100 和 101 这两个节点的子树;最后,再将 111 拆分出来。这样,就将 110 节点之外的整个二叉树拆分出了三颗子树。
完成子树拆分后,只要知道每个子树里面的其中一个节点,就可以进行递归路由实现整颗二叉树所有节点的遍历。但在实际场景下,由于节点是动态变化的,所以一般不会只知道每个子树的一个节点,而是需要知道多个节点。因此,Kad 中有一个叫 K-桶(K-bucket)的概念,每个桶会记录每颗子树里所知道的多个节点。其实,一个K-桶就是一张路由表,如果拆分出来有 m 颗子树,那对应节点就需要维护 m 个路由表。每个节点都会各自维护自己的 m 个 K-桶,每个 K-桶里记录的节点信息一般会包括 NodeID、IP、Endpoint、与 Target 节点(即维护该 K-桶的节点)的异或距离等信息。以太坊中,每个节点维护的 K-桶数量为 256 个,这 256 个 K-桶会根据与 Target 节点的异或距离进行排序,每个 K-桶保存的节点数量上限是 16。
在以太坊的 Kad 网络中,节点之间的通信是基于 UDP 的,另外设置了 4 个主要的通信协议:
- Ping:用于探测一个节点是否在线
- Pong:用于响应 Ping 命令
- FindNode:用于查找与 Target 节点异或距离最近的其他节点
- Neighbours:用于响应 FindNode 命令,会返回一或多个节点
通过以上 4 个命令,就可以实现新节点的加入、K-桶的刷新等机制。具体的实现流程就不细讲了,留给大伙自己去思考。
总结
不同结构的 P2P 网络,会有不同的优点和缺点。比特币网络的结构明显容易理解,实现起来也相对容易得多,而以太坊网络引入了异或距离、二叉前缀树、K-桶等,结构上复杂不少,但在节点路由上的确会比比特币快很多。另外,不管是比特币还是以太坊,其实都只是一种或多种协议的集合,不同节点其实可以用不同的具体实现,比如,比特币就有用 C++ 实现的 Bitcoin Core,还有用 Java 实现的 BitcoinJ;以太坊也有用 Go 语言实现的 go-ethereum,也有用 C++ 实现的 go-ethereum,还有用 Java 实现的 Ethereum(J)。
思考和实践
在以太坊的 Kad 网络中,新节点的加入和 K-桶的刷新流程是怎样的?比特币的新节点加入流程又是怎样的?哈希表有哪些实现方式?
作者个人博客地址:https://keeganlee.me