高可用的Redis主从复制集群,从理论到实践
前言
我们都知道,服务如果只部署一个节点,很容易出现单点故障,从而导致服务不可用。所以服务做成高可用是很有必要的,Redis服务自然也是这样。
本文主要从理论和实践两方面讲解Redis高可用集群。手把手教你搭建一个高可用的redis主从复制集群。
本文采取理论和实践穿插讲解的方式,如果只关心集群的搭建,可以跳过文中理论部分。
前置阅读
- Redis持久化:https://blog.csdn.net/Baisitao_/article/details/105461153
实验环境
- VMware Workstation 15
- CentOS Linux release 7.7.1908
- Redis-5.0.8
注意事项
- 三个节点ip分别为
192.168.1.101、192.168.1.102、192.168.1.103 - 确保三个节点都能访问互联网,并且三个节点能够相互通信
- 确保Linux的
yum、wget、tar、gcc等基础命令、编译器可用 - 建议先关闭防火墙,Centos 7操作如下
firewall-cmd --state ## 查看防火墙状态 not running表示已经关闭
systemctl stop firewalld.service ## 关闭防火墙
systemctl disable firewalld.service ## 禁止开机启动防火墙redis单机安装
下载
wget http://download.redis.io/releases/redis-5.0.8.tar.gz解压
tar -zxvf redis-5.0.8.tar.gz编译
cd redis-5.0.8
make安装
make install ## 或者指定安装目录 make install PREFIX=指定路径。默认路径是/usr/local/bin
./utils/install_server.sh ## 安装成服务,如果上一步配置了PREFIX,需要把安装路径配置到环境变量/etc/profileinstall_server.sh是redis提供的脚本,运行之后会让你指定几个配置:端口号、配置文件路径、日志文件路径、数据文件路径。
如果都设置成默认值,redis根据按照端口号来区分同一台主机上的不同的实例,因为install_server.sh可以多次运行,每次运行相当于安装了一个实例。
安装过程如果都是默认安装,会有以下几个配置:
- 端口号:
6379 - 配置文件路径:
/etc/redis/6379.conf - 日志文件路径:
/var/log/redis_6379.log - 数据文件路径:
/var/lib/redis/6379/ redis-server.sh路径:/usr/local/bin/redis-cli.sh路径:/usr/local/bin/
安装成功会出现如下日志
Copied /tmp/6379.conf => /etc/init.d/redis_6379
Installing service...
Successfully added to chkconfig!
Successfully added to runlevels 345!
Starting Redis server...
Installation successful!可以看到redis服务已经自动启动。
主从复制
Redis主从复制是redis3.0之后自带的一种集群实现方式,不需要其他的中间件。是一种基于异步复制的主从实现方式。所以Redis主从复制并不能保证数据的强一致性.。集群在特定的条件下可能会丢失写操作。
集群结构
现在来搭建一个一主两从的集群,集群拓扑图如下
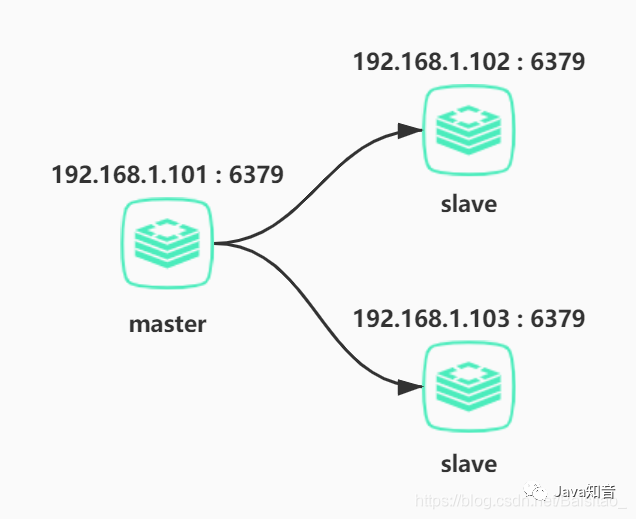
其中master节点可写可读,一般用来处理写请求,slave节点默认情况下是只读的,所以用来处理读请求。两个slave节点的数据都是从master节点复制过去的。所以这种集群也叫读写分离。
配置
redis配置文件默认路径为/etc/redis/6379.conf,用vi/vim打开,三个节点都配置如下内容
## 需要绑定的ip地址
bind 127.0.0.1 192.168.1.101 192.168.1.102 192.168.1.103
## 关闭后台运行,便于观察
daemonize no
## 注释日志路径,让日志直接输出在控制台,便于观察
# logfile /var/log/redis_6379.log
## 关闭AOF持久化模式
appendonly no启动
配置完成后分别启动三个节点
cd /usr/local/bin
redis-server /etc/redis/6379.conf设置主从关系
两个slave节点用redis-cli客户端连接redis-server后,均执行如下命令,把自己设置成master节点的slave
replicaof 192.168.1.101 6379replicaof也可以直接写在配置文件中(文中为了实验效果,以命令的方式执行)
################################# REPLICATION #################################
# Master-Replica replication. Use replicaof to make a Redis instance a copy of
# another Redis server. A few things to understand ASAP about Redis replication.
#
# +------------------+ +---------------+
# | Master | ---> | Replica |
# | (receive writes) | | (exact copy) |
# +------------------+ +---------------+
#
# 1) Redis replication is asynchronous, but you can configure a master to
# stop accepting writes if it appears to be not connected with at least
# a given number of replicas.
# 2) Redis replicas are able to perform a partial resynchronization with the
# master if the replication link is lost for a relatively small amount of
# time. You may want to configure the replication backlog size (see the next
# sections of this file) with a sensible value depending on your needs.
# 3) Replication is automatic and does not need user intervention. After a
# network partition replicas automatically try to reconnect to masters
# and resynchronize with them.
#
# replicaof <masterip> <masterport>replicaof在redis5.0之前的版本叫slaveof,命令描述如下
127.0.0.1:6379> help slaveof
SLAVEOF host port
summary: Make the server a replica of another instance, or promote it as master. Deprecated starting with Redis 5. Use REPLICAOF instead.
since: 1.0.0
group: server
127.0.0.1:6379> help replicaof
REPLICAOF host port
summary: Make the server a replica of another instance, or promote it as master.
since: 5.0.0
group: server命令成功执行后192.168.1.101(master)会出现如下日志
1817:M 16 Apr 2020 22:33:36.802 * Replica 192.168.1.102:6379 asks for synchronization
1817:M 16 Apr 2020 22:33:36.802 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'e801c600a0a2381a65e1aec22daba7db82cb02f8', my replication IDs are 'be75572b8e6624da4971aa16448600c9822fd42a' and '0000000000000000000000000000000000000000')
1817:M 16 Apr 2020 22:33:36.803 * Starting BGSAVE for SYNC with target: disk
1817:M 16 Apr 2020 22:33:36.837 * Background saving started by pid 1822
1822:C 16 Apr 2020 22:33:36.944 * DB saved on disk
1822:C 16 Apr 2020 22:33:36.944 * RDB: 6 MB of memory used by copy-on-write
1817:M 16 Apr 2020 22:33:37.038 * Background saving terminated with success
1817:M 16 Apr 2020 22:33:37.038 * Synchronization with replica 192.168.1.102:6379 succeeded我们逐行看一下192.168.1.101(master)做了哪些事。
- 第一行意思是有一个
salve节点192.168.1.102:6379请求同步 - 第二行意思是会进行全量同步,因为是第一次请求同步
- 第三行意思是开始执行
BGSAVE把数据持久化到磁盘 - 第四行意思是pid为1822子进程开始执行持久化
- 第五行意思是持久化完成
- 第六行意思是
copy-on-write机制使用了6M内存
最后两行表示同步过程已经完成。master节点是把数据以RDB的形式持久化到磁盘,再通过网络发送给slave。参数repl-diskless-sync设置成no的话,表示数据不经过磁盘,直接发送给slave。
看了192.168.1.101(master)的日志,再来看salve的日志,任取一个slave的日志
2013:S 16 Apr 2020 22:33:36.233 * Before turning into a replica, using my master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
2013:S 16 Apr 2020 22:33:36.233 * REPLICAOF 192.168.1.101:6379 enabled (user request from 'id=3 addr=127.0.0.1:33550 fd=8 name= age=4 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=49 qbuf-free=32719 obl=0 oll=0 omem=0 events=r cmd=replicaof')
2013:S 16 Apr 2020 22:33:36.808 * Connecting to MASTER 192.168.1.101:6379
2013:S 16 Apr 2020 22:33:36.808 * MASTER <-> REPLICA sync started
2013:S 16 Apr 2020 22:33:36.809 * Non blocking connect for SYNC fired the event.
2013:S 16 Apr 2020 22:33:36.810 * Master replied to PING, replication can continue...
2013:S 16 Apr 2020 22:33:36.811 * Trying a partial resynchronization (request e801c600a0a2381a65e1aec22daba7db82cb02f8:1).
2013:S 16 Apr 2020 22:33:36.946 * Full resync from master: a9861cdcfdb3358ea0a3bb5a4df2895938c1c2d0:0
2013:S 16 Apr 2020 22:33:36.946 * Discarding previously cached master state.
2013:S 16 Apr 2020 22:33:37.048 * MASTER <-> REPLICA sync: receiving 175 bytes from master
2013:S 16 Apr 2020 22:33:37.048 * MASTER <-> REPLICA sync: Flushing old data
2013:S 16 Apr 2020 22:33:37.048 * MASTER <-> REPLICA sync: Loading DB in memory
2013:S 16 Apr 2020 22:33:37.048 * MASTER <-> REPLICA sync: Finished with successsalve节点日志较多,告诉我们具体做了这些事
- 向
192.168.1.101:6379(master)请求同步 - 发送指令
SYNC - 收到
master的回复 - 全量同步,收到了175 bytes
- 清空自身的数据(
Flushing old data) - 加载
master传送的数据到内存(Loading DB in memory)
结合master和slave日志,可以看出复制的大致过程。
完整的主从复制的过程如下
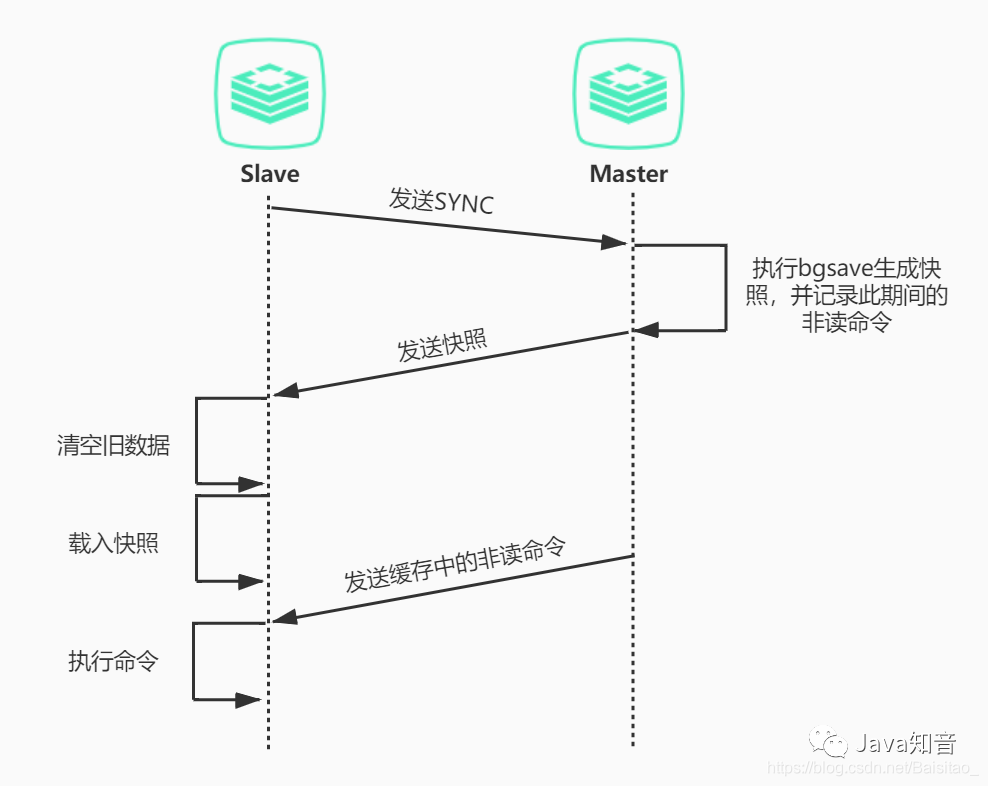
redis主从复制
master收到某个slave第一次请求的同步时,会进行全量同步,在同步期间会把执行过的修改数据的命令写入缓存,等同步完成后,再发送给slave节点执行。第一次全量同步完成后,master会持续给slave节点发送写命令,以保证主从节点数据一致性。
在这里可以思考一个问题,slave节点在全量同步的这段时间中,里面的数据能不能被客户端查询呢?
replicaof-server-stale-data参数设置成yes表示可以查,设置成no表示同步必须完成才能查。
操作
先往master节点写入数据
192.168.1.101:6379> set key1 hello
OK再从slave节点获取(注意提示符中的ip地址),毫无疑问是可以获取的
192.168.1.102:6379> get key1
"hello"如果往slave节点写入数据会怎样?
默认情况下slave节点禁止写入,所以会报错。
192.168.1.102:6379> set key2 world
(error) READONLY You can't write against a read only replica.replica-read-only参数可以设置slave允许写入
# You can configure a replica instance to accept writes or not. Writing against
# a replica instance may be useful to store some ephemeral data (because data
# written on a replica will be easily deleted after resync with the master) but
# may also cause problems if clients are writing to it because of a
# misconfiguration.
#
# Since Redis 2.6 by default replicas are read-only.
#
# Note: read only replicas are not designed to be exposed to untrusted clients
# on the internet. It's just a protection layer against misuse of the instance.
# Still a read only replica exports by default all the administrative commands
# such as CONFIG, DEBUG, and so forth. To a limited extent you can improve
# security of read only replicas using 'rename-command' to shadow all the
# administrative / dangerous commands.
replica-read-only yes至此,最简单的主从复制集群已经搭建完成。

故障
你已经是一个成熟的程序员了,应该要学会面向故障编程。
在这个集群中有三个节点,两种角色。salve可能会挂,master也可能会挂。我们先看下salve节点挂了会怎样。
slave故障
首先让一台slave宕机,由于配置了2个slave节点,所以一个出了故障,不至于整个服务不可用。只要尽快处理故障,恢复slave即可,实验步骤如下。

现在重启出故障的slave节点
/usr/local/bin/redis-server /etc/redis/6379.conf --replicaof 192.168.1.101 6379观察master,会打印如下日志信息
2168:M 17 Apr 2020 13:38:16.282 * Replica 192.168.1.102:6379 asks for synchronization
2168:M 17 Apr 2020 13:38:16.282 * Partial resynchronization request from 192.168.1.102:6379 accepted. Sending 143 bytes of backlog starting from offset 1473.可以看到只打印了2行日志。表示收到了192.168.1.102:6379(slave)节点的同步请求,并且接受同步,从偏移(offset)1473开始传输,共传输了143 bytes。这意味着slave的重新连接,并没有触发全量同步,而是增量同步。同步的数据只是故障期间在master写入的那部分数据。
上面的操作是没有开启AOF的情况,如果开启AOF,情况又不一样。下面来操作开启AOF的情况,操作步骤和上面一样,区别仅仅是slave节点重启时开启AOF
/usr/local/bin/redis-server /etc/redis/6379.conf --replicaof 192.168.1.101 6379 --appendonly yes观察master节点,可以看到如下日志
2168:M 17 Apr 2020 13:45:21.977 * Replica 192.168.1.102:6379 asks for synchronization
2168:M 17 Apr 2020 13:45:21.977 * Full resync requested by replica 192.168.1.102:6379
2168:M 17 Apr 2020 13:45:21.977 * Starting BGSAVE for SYNC with target: disk
2168:M 17 Apr 2020 13:45:21.978 * Background saving started by pid 2306
2306:C 17 Apr 2020 13:45:22.009 * DB saved on disk
2306:C 17 Apr 2020 13:45:22.010 * RDB: 8 MB of memory used by copy-on-write
2168:M 17 Apr 2020 13:45:22.111 * Background saving terminated with success
2168:M 17 Apr 2020 13:45:22.111 * Synchronization with replica 192.168.1.102:6379 succeeded根据日志可以看出,slave节点重启时如果开启了AOF,会触发全量同步。即使整个实验一开始就把所以节点都开启AOF,这里也会触发全量同步。
下面是slave日志,也可以证明触发了全量同步。
2598:S 17 Apr 2020 13:45:21.967 * Ready to accept connections
2598:S 17 Apr 2020 13:45:21.968 * Connecting to MASTER 192.168.1.101:6379
2598:S 17 Apr 2020 13:45:21.968 * MASTER <-> REPLICA sync started
2598:S 17 Apr 2020 13:45:21.969 * Non blocking connect for SYNC fired the event.
2598:S 17 Apr 2020 13:45:21.971 * Master replied to PING, replication can continue...
2598:S 17 Apr 2020 13:45:21.973 * Partial resynchronization not possible (no cached master)
2598:S 17 Apr 2020 13:45:21.977 * Full resync from master: 8b57ea32e3bada6e91d3f371123cb693df2eec8b:2235
2598:S 17 Apr 2020 13:45:22.107 * MASTER <-> REPLICA sync: receiving 271 bytes from master
2598:S 17 Apr 2020 13:45:22.108 * MASTER <-> REPLICA sync: Flushing old data
2598:S 17 Apr 2020 13:45:22.122 * MASTER <-> REPLICA sync: Loading DB in memory
2598:S 17 Apr 2020 13:45:22.122 * MASTER <-> REPLICA sync: Finished with success
2598:S 17 Apr 2020 13:45:22.125 * Background append only file rewriting started by pid 2602
2598:S 17 Apr 2020 13:45:22.178 * AOF rewrite child asks to stop sending diffs.
2602:C 17 Apr 2020 13:45:22.179 * Parent agreed to stop sending diffs. Finalizing AOF...
2602:C 17 Apr 2020 13:45:22.179 * Concatenating 0.00 MB of AOF diff received from parent.
2602:C 17 Apr 2020 13:45:22.179 * SYNC append only file rewrite performed
2602:C 17 Apr 2020 13:45:22.180 * AOF rewrite: 4 MB of memory used by copy-on-write
2598:S 17 Apr 2020 13:45:22.274 * Background AOF rewrite terminated with success
2598:S 17 Apr 2020 13:45:22.274 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
2598:S 17 Apr 2020 13:45:22.275 * Background AOF rewrite finished successfullymaster故障
由于在这个集群中,master节点只有一个,万一宕机了,整个服务就无法写入数据了,相当于服务不可用。这个时候救世主就出现了。哦,不,是哨兵(Sentinel)出现了。
Redis Sentinel(哨兵)是Redis官方的高可用性解决方案,用于管理多个 Redis 服务器(instance),哨兵的作用主要有三个:
- 监控(Monitoring):Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification):当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover):当一个主服务器不能正常工作时,Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器(
master)的其中一个从服务器(slave)升级为新的主服务器(master),并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
如果单单只是一个哨兵实例来监控集群,那哨兵必定也存在单点故障的问题,所以需要多个哨兵实例。加入哨兵后的集群结构如下
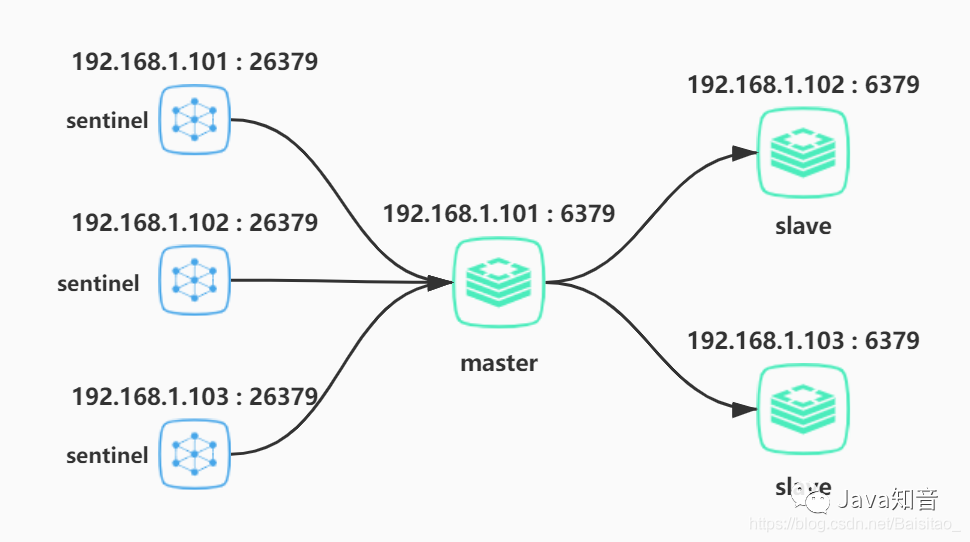
redis集群
26379是sentinel的默认端口,三个哨兵分别放在三个节点上。
哨兵
redis安装包的解压目录下会有一个sentinel.conf文件,这就是哨兵的配置文件,为了方便,把它拷贝到和redis配置文件相同的目录
## 拷贝哨兵配置文件
cp sentinel.conf /etc/redis/
## 配置哨兵的配置文件
vim /etc/redis/sentinel.conf需要改的地方只有一个,就是指定哨兵要监控哪个master,因为master是可以知道有哪些slave节点连接了自己,所以监控master就够了。注意三个sentinel节点都是配置master的ip和端口
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
#
# Tells Sentinel to monitor this master, and to consider it in O_DOWN
# (Objectively Down) state only if at least <quorum> sentinels agree.
#
# Note that whatever is the ODOWN quorum, a Sentinel will require to
# be elected by the majority of the known Sentinels in order to
# start a failover, so no failover can be performed in minority.
#
# Replicas are auto-discovered, so you don't need to specify replicas in
# any way. Sentinel itself will rewrite this configuration file adding
# the replicas using additional configuration options.
# Also note that the configuration file is rewritten when a
# replica is promoted to master.
#
# Note: master name should not include special characters or spaces.
# The valid charset is A-z 0-9 and the three characters ".-_".
sentinel monitor mymaster 192.168.1.101 6379 2配置指示 Sentinel 去监视一个名为mymaster的主服务器, 这个主服务器的 IP 地址为 192.168.1.101 , 端口号为 6379 。后面那个2表示这个主服务器判断为失效至少需要 2 个 Sentinel 同意 (只要同意 Sentinel 的数量不达标,自动故障迁移就不会执行)。
不过要注意, 无论设置要多少个 Sentinel 同意才能判断一个服务器失效, 一个 Sentinel 都需要获得系统中多数(majority) Sentinel 的支持, 才能发起一次自动故障迁移
正是为了更好的区分多数和少数,所以一般使用奇数个sentinel实例来监控集群。
配置文件修改完成后,开始启动三个哨兵,哨兵的启动有两种方式:直接运行redis-sentinel、运行redis-server --sentinel
redis-server /etc/redis/sentinel.conf --sentinel第一个哨兵启动日志如下
2873:X 17 Apr 2020 20:56:54.495 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
2873:X 17 Apr 2020 20:56:54.498 # Sentinel ID is 643817dcf5ba6d53a737782a75706a62df869e33
2873:X 17 Apr 2020 20:56:54.498 # +monitor master mymaster 192.168.1.101 6379 quorum 2
2873:X 17 Apr 2020 20:56:54.500 * +slave slave 192.168.1.102:6379 192.168.1.102 6379 @ mymaster 192.168.1.101 6379
2873:X 17 Apr 2020 20:56:54.503 * +slave slave 192.168.1.103:6379 192.168.1.103 6379 @ mymaster 192.168.1.101 6379可以看到哨兵打印出了自己的ID,还监控了192.168.1.101 6379(master)和两个slave节点
3031:X 17 Apr 2020 20:59:59.153 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
3031:X 17 Apr 2020 20:59:59.158 # Sentinel ID is e784d728f7a813de688ea800a88bda6aca0512ff
3031:X 17 Apr 2020 20:59:59.158 # +monitor master mymaster 192.168.1.101 6379 quorum 2
3031:X 17 Apr 2020 20:59:59.164 * +slave slave 192.168.1.102:6379 192.168.1.102 6379 @ mymaster 192.168.1.101 6379
3031:X 17 Apr 2020 20:59:59.166 * +slave slave 192.168.1.103:6379 192.168.1.103 6379 @ mymaster 192.168.1.101 6379
3031:X 17 Apr 2020 21:00:00.115 * +sentinel sentinel 643817dcf5ba6d53a737782a75706a62df869e33 192.168.1.101 26379 @ mymaster 192.168.1.101 6379启动第二个哨兵时,也打印了同样的日志。除此之外,还多打印了一行关于sentinel的日志。可以看出打印出的sentinel的ID就是第一个哨兵的。也就是说哨兵在监控master的时候,除了可以发下slave节点,还可以发现监控master节点的其他哨兵。回头再看第一个哨兵的日志,也会多打印一行,就是第二个哨兵的ID。
三个哨兵已经准备就绪,接下来再让master宕机。
master宕机30秒后,Sentinel 认为服务器已经宕机,由参数sentinel down-after-milliseconds指定
# sentinel down-after-milliseconds <master-name> <milliseconds>
#
# Number of milliseconds the master (or any attached replica or sentinel) should
# be unreachable (as in, not acceptable reply to PING, continuously, for the
# specified period) in order to consider it in S_DOWN state (Subjectively
# Down).
#
# Default is 30 seconds.超过半数的Sentinel感知到master宕机后会进行投票选举,从剩下的两个slave中选出一个master。三个哨兵日志分别如下
2873:X 17 Apr 2020 21:02:57.687 # +sdown master mymaster 192.168.1.101 6379
2873:X 17 Apr 2020 21:02:57.765 # +new-epoch 1
2873:X 17 Apr 2020 21:02:57.766 # +vote-for-leader a32bc56146695d9ebcbceaff2b0b8a5339c61a5b 1
2873:X 17 Apr 2020 21:02:58.326 # +config-update-from sentinel a32bc56146695d9ebcbceaff2b0b8a5339c61a5b 192.168.1.103 26379 @ mymaster 192.168.1.101 6379
2873:X 17 Apr 2020 21:02:58.326 # +switch-master mymaster 192.168.1.101 6379 192.168.1.103 6379
2873:X 17 Apr 2020 21:02:58.327 * +slave slave 192.168.1.102:6379 192.168.1.102 6379 @ mymaster 192.168.1.103 6379
2873:X 17 Apr 2020 21:02:58.327 * +slave slave 192.168.1.101:6379 192.168.1.101 6379 @ mymaster 192.168.1.103 6379
2873:X 17 Apr 2020 21:03:28.343 # +sdown slave 192.168.1.101:6379 192.168.1.101 6379 @ mymaster 192.168.1.103 63793031:X 17 Apr 2020 21:02:57.686 # +sdown master mymaster 192.168.1.101 6379
3031:X 17 Apr 2020 21:02:57.743 # +new-epoch 1
3031:X 17 Apr 2020 21:02:57.745 # +vote-for-leader a32bc56146695d9ebcbceaff2b0b8a5339c61a5b 1
3031:X 17 Apr 2020 21:02:57.776 # +odown master mymaster 192.168.1.101 6379 #quorum 3/2
3031:X 17 Apr 2020 21:02:57.776 # Next failover delay: I will not start a failover before Fri Apr 17 21:08:57 2020
3031:X 17 Apr 2020 21:02:58.308 # +config-update-from sentinel a32bc56146695d9ebcbceaff2b0b8a5339c61a5b 192.168.1.103 26379 @ mymaster 192.168.1.101 6379
3031:X 17 Apr 2020 21:02:58.308 # +switch-master mymaster 192.168.1.101 6379 192.168.1.103 6379
3031:X 17 Apr 2020 21:02:58.309 * +slave slave 192.168.1.102:6379 192.168.1.102 6379 @ mymaster 192.168.1.103 6379
3031:X 17 Apr 2020 21:02:58.309 * +slave slave 192.168.1.101:6379 192.168.1.101 6379 @ mymaster 192.168.1.103 6379
3031:X 17 Apr 2020 21:03:28.352 # +sdown slave 192.168.1.101:6379 192.168.1.101 6379 @ mymaster 192.168.1.103 63792833:X 17 Apr 2020 21:02:57.690 # +sdown master mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:57.749 # +odown master mymaster 192.168.1.101 6379 #quorum 2/2
2833:X 17 Apr 2020 21:02:57.749 # +new-epoch 1
2833:X 17 Apr 2020 21:02:57.749 # +try-failover master mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:57.750 # +vote-for-leader a32bc56146695d9ebcbceaff2b0b8a5339c61a5b 1
2833:X 17 Apr 2020 21:02:57.759 # 643817dcf5ba6d53a737782a75706a62df869e33 voted for a32bc56146695d9ebcbceaff2b0b8a5339c61a5b 1
2833:X 17 Apr 2020 21:02:57.759 # e784d728f7a813de688ea800a88bda6aca0512ff voted for a32bc56146695d9ebcbceaff2b0b8a5339c61a5b 1
2833:X 17 Apr 2020 21:02:57.841 # +elected-leader master mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:57.841 # +failover-state-select-slave master mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:57.924 # +selected-slave slave 192.168.1.103:6379 192.168.1.103 6379 @ mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:57.925 * +failover-state-send-slaveof-noone slave 192.168.1.103:6379 192.168.1.103 6379 @ mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:58.001 * +failover-state-wait-promotion slave 192.168.1.103:6379 192.168.1.103 6379 @ mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:58.266 # +promoted-slave slave 192.168.1.103:6379 192.168.1.103 6379 @ mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:58.266 # +failover-state-reconf-slaves master mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:58.317 * +slave-reconf-sent slave 192.168.1.102:6379 192.168.1.102 6379 @ mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:58.817 # -odown master mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:59.292 * +slave-reconf-inprog slave 192.168.1.102:6379 192.168.1.102 6379 @ mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:59.292 * +slave-reconf-done slave 192.168.1.102:6379 192.168.1.102 6379 @ mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:59.347 # +failover-end master mymaster 192.168.1.101 6379
2833:X 17 Apr 2020 21:02:59.347 # +switch-master mymaster 192.168.1.101 6379 192.168.1.103 6379
2833:X 17 Apr 2020 21:02:59.347 * +slave slave 192.168.1.102:6379 192.168.1.102 6379 @ mymaster 192.168.1.103 6379
2833:X 17 Apr 2020 21:02:59.347 * +slave slave 192.168.1.101:6379 192.168.1.101 6379 @ mymaster 192.168.1.103 6379
2833:X 17 Apr 2020 21:03:29.355 # +sdown slave 192.168.1.101:6379 192.168.1.101 6379 @ mymaster从日志可以看到大致的过程
- 三个sentinel都发下
master宕机了,把它的状态设置成odown - 开启一轮投票,选出了新的
master为192.168.1.103:6379 - sentinel更新配置文件
192.168.1.103:6379成为新的master,故障转移完成
从最后几行日志可以看出,现在的master是192.168.1.103 6379,而slave是192.168.1.102:6379和192.168.1.101:6379,并且192.168.1.101:6379是sdown状态的slave。
Redis 的 Sentinel 中关于下线(down)有两个不同的概念:
- 主观下线(Subjectively Down, 简称
SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。 - 客观下线(Objectively Down, 简称
ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过SENTINEL is-master-down-by-addr命令互相交流之后, 得出的服务器下线判断。(一个 Sentinel 可以通过向另一个 Sentinel 发送SENTINEL is-master-down-by-addr命令来询问对方是否认为给定的服务器已下线。)
查看哨兵配置文件,发现哨兵监控的节点已经成新的master了
[root@localhost redis-5.0.8]> cat /etc/redis/sentinel.conf |grep "sentinel monitor mymaster"
sentinel monitor mymaster 192.168.1.103 6379 2之前的master出故障了,但是现在故障修复了,准备重启。重新启动原来的192.168.1.101(master),它会心甘情愿的成为slave,还是抢回master地位呢?
欲知后事如何,请听下回分解。

看下哨兵日志就知道,哨兵会打印如下日志
3031:X 17 Apr 2020 21:05:32.297 * +convert-to-slave slave 192.168.1.101:6379 192.168.1.101 6379 @ mymaster 192.168.1.103 63791就是把192.168.1.101:6379变成可用的slave,所以即使原来的master重启了,也不会去抢回master地位。
至此,基于哨兵的高可用redis集群才算搭建完成。
补充
这里再把主从复制相关的理论总结一下。slave节点第一次追随master的时候,会发送sync请求同步。请求同步在Redis2.8之后由psync [runId] [offset]命令完成,psync命令既支持全量复制,也支持增量复制。Redis4.0之后,psync再一次进行了优化。
runId:是每个redis节点启动都会生成的唯一标识,每次redis重启后,runId也会发生变化offset:是复制的偏移量,master和slave都会记录自己和对方的复制偏移量,如果不一致,表示需要继续同步
除此之外master节点还会维护一个缓冲队列(replication backlog buffer,复制积压缓冲区默认大小1M,参数repl-backing-size设置),当slave正在复制master时,如果出现网络异常导致命令丢失时。slave会向master要求重新发送丢失的命令数据,如果master的复制积压缓冲区内存将这部分数据则直接发送给slave,这样就可以保持主从节点复制的一致性。
然而redis2.8版本的psync还有两个问题无法解决:redis重启时触发全量复制、故障切换之后,slave追随新的master触发全量同步。
这两个问题在redis4.0版本的psync得到了解决。主要通过两个复制id(master_replid和master_replid2)来实现
这些信息都可以通过info replication命令来查询
这是master节点的信息
192.168.1.103:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.1.101,port=6379,state=online,offset=98,lag=0
slave1:ip=192.168.1.102,port=6379,state=online,offset=98,lag=0
master_replid:8b1d6db7a9e63c0360ffed0ec6d3a51199f08f2b
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:98
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:98这是slave节点的信息
192.168.1.101:6379> info replication
# Replication
role:slave
master_host:192.168.1.103
master_port:6379
master_link_status:up
master_last_io_seconds_ago:3
master_sync_in_progress:0
slave_repl_offset:5334
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:8b1d6db7a9e63c0360ffed0ec6d3a51199f08f2b
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:5334
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:5334总结
本文以穿插的方式讲解了redis主从复制的实践和部分原理,可能会导致看起来略显凌乱。之所以采用穿插的方式,是为了让读者把理论和实践关联起来,形成一个完整的知识体系,而不仅仅是零碎的知识点。
只关心实验的旁友可以先跳过文中理论部分,并不会影响实验效果。