Swift 底层原子操作

前两天 Apple 的团队发布了 swift-atomics,让我们可以用纯 Swift 代码实现高性能的无锁并发数据结构,这里我就把它的前身 SE-0282 Low-Level Atomic Operations 翻译出来,希望可以帮助大家更好地理解 swift-atomics,也欢迎留言指正。
本文翻译的这个版本与最终版本的提案有比较大的出入,提案在 Joe 的提议下,把 Atomics 作为一个独立的 Swift Package 发布出来,摆脱 API/ABI 稳定的顾虑,也不需要跟着 Swift 的发布周期走,可以快速地进行迭代。
并且这个版本的提案内容最终被拆分成了三个部分进行实现:
- 对于编译器必要的修改作为私有功能直接合并到主分支里。
- 对于内存模型的定义演变成 SE-0282 Clarify the Swift memory consistency model ⚛︎ 提案,并且优化了与 C Atomics 的交互,最终提案在 Swift 5.3 里完成了实现。
- 核心的功能改为在 C Atomics 的基础上实现,作为 swift-atomics 发布出来。
简介
这个提案提议给标准库添加几个 low-level 的 atomic 操作,包括 C++ 风格的原生 memory ordering。我们的目标是让框架作者可以开始在 Swift 里直接构建同步结构。
Swift-evolution thread: Low-Level Atomic Operations https://forums.swift.org/t/low-level-atomic-operations/34683
作为一个前菜,我们先看一下它的使用例子:
import Atomics
import Dispatch
let counter = UnsafeAtomic<Int>.create(initialValue: 0)
DispatchQueue.concurrentPerform(iterations: 10) { _ in
for _ in 0 ..< 1_000_000 {
counter.wrappingIncrement(ordering: .relaxed)
}
}
print(counter.load(ordering: .relaxed))
counter.destroy()背景说明
目前在 Swift 里,开发者在并发线程里同步访问共享数据需要通过 DispatchQueue 或者 Foundation 的 NSLocking,
然而,Swift 想要成为一门系统编程语言,还需要提供底层的接口,能够让 Swift 直接实现这种同步结构。
其中一种底层接口就是 atomic 值,它会起到两种重要的作用:
- 首先,atomics 会引入一系列新的类型,它们会给特定类型的并发访问提供明确的语义。这其中包括了显式的并发修改(concurrent mutations) – Swift 之前缺失的一个概念。
- 然后,atomics 操作还需要带上显式的 memory ordering 参数,这些操作带来的影响会在何时/如何展示给之前或者之后的内存访问(同一块内存),都会由这个参数来控制并且提供保证。这样的保证对于搭建上层同步抽象来说至关重要
这些新的原语让大家可以通过纯 Swift 代码实现同步结构或并发的数据结构。需要注意,这是一个充满陷阱的危险领域。虽然一套设计良好的 atomic 操作接口可以帮助简化实现过程,但这个提案的目标只是让这件事情变得可能,但并不一定是要让它变得容易。我们的期望是让大家可以在此基础上,搭建一个更加易用的抽象层。
我们想要给这个提案加一些约束条件,以便让它符合以下要求:
- 所有 atomic 操作都需要在 Swift 代码里显式声明,并且可以简单地与其它非 atomic 操作的代码区分开来。
- 我们提供的这些 atomic 类型在能够提供支持的平台上必须使用无锁实现。(无法提供无锁实现的平台就不会提供 atomic 类型)
- 每个 atomic 操作都必须编译到与之对应的 CPU 指令(如果有的话),并且伴随着最小的开销。(理想情况下,即使优化过的代码也要做到这一点)。无等待则不是硬性要求 - 如果没有指令与操作一一对应的话,也必须提供实现,例如将它映射为成一个 compare-exchange 循环。
注意,虽然这个提案不包含,但也不排斥上层的并发设计。事实上,我们希望底层 atomics 接口的加入可以让语言层面的并发设计往前迈进,通过简化这件事情让大家可以从框架层面去探索设计空间。
这份文档里提及的设计实现可以在这个 URL 里看到:https://github.com/apple/swift/pull/30553
解决方案
我们提议正式采纳一种类似 C/C++ 的内存模型:
- 同一块内存空间的并发写/写或读/写访问是未定义/非法的行为,除非所有这些访问都通过一套特殊的atomics 操作实现。
- 相同的 atomic 操作也可以通过 memory ordering 进行约束,让多线程的访问达成严格的先后顺序。这种约束也可以通过显式的 memory fences 来实现,不需要绑定到某个特定的 atomic 操作上。
恰当使用时,atomic 操作和 memory ordering 约束就可以用来实现高层级的同步算法,通过严格限制这些操作对于时间线的生效顺序(confining their effects into some sequential timeline),保证特定变量在多线程随机访问时不会产生未定义行为,
虽然我们相信引入了 C++ 的内存模型之后,其它语言的并发内存模型经验和工具也可以应用到 Swift 里,但这份文档并没有正式定义 Swift 的并发内存模型。
目前来说,我们将会重度依赖于 [SE-0176] 和 [Ownership Manifesto] 里定义的独占性原则,并且我们会仔细说明 memory orderings 会怎么跟 Swift 的语言功能交互。目的是让 Swift 的 memory ordering 与 C/C++ 对应的部分完全兼容。
Atomic 模块
虽然大部分 Swift 程序都不会直接使用新的 atomic 原语,但我们还是将它看作是 Swift 核心标准库必要的组成部分。
- atomic 操作的实现需要使用那些只暴露给标准库的编译器接口。
- 总体上来看,这里引入的 Memory orderings 为 Swift 定义了一种并发内存模型。(幸运的是,Swift 的设计已经可以跟 C/C++ 内存模型进行无缝交互,所以将 C++ Memory Ordering 的子集引入标准库并不需要做语言层面的改动)
也就是说,把底层的 atomics 操作加到每一个 Swift 程序默认的命名空间下似乎不那么合适,所以我们提议将 atomic 接口放到一个新的 Swift 标准库模块 Atomics 里。需要使用底层 atomics 时需要显式地导入这个新模块:
import Atomics我们认为大部分 Swift 项目,都只会通过更高层级的同步结构间接使用 atomics 操作。所以,很少会需要导入 Atomics 模块,只有少数实现了高层级同步结构的项目需要导入。
在这个提案里,我们会给 atomic 操作增加一个基本类型集合。
所有的这些都会通过一个泛型结构体 UnsafeAtomic 实现,它实现了一个 unsafe 引用类型,持有一个原始 atomic 类型的 untagged 的值(a single, untagged primitive value of some atomic type):
struct UnsafeAtomic<Value: AtomicProtocol> { ... }这个提案里引入的 atomic 类型包括:
- 所有标准的定长整型类型,
- 标准的指针类型和 unmanaged 引用,
- Optional 的指针和 Optional 的 unmanaged 引用,
- atomic 的 raw-representable 自定义类型。
下面是完整的列表:
// Standard signed integers:
let i: UnsafeAtomic<Int> = ...
let i64: UnsafeAtomic<Int64> = ...
let i32: UnsafeAtomic<Int32> = ...
let i16: UnsafeAtomic<Int16> = ...
let i8: UnsafeAtomic<Int8> = ...
// Standard unsigned integers:
let u: UnsafeAtomic<UInt> = ...
let u64: UnsafeAtomic<UInt64> = ...
let u32: UnsafeAtomic<UInt32> = ...
let u16: UnsafeAtomic<UInt16> = ...
let u8: UnsafeAtomic<UInt8> = ...
// Standard unsafe pointers:
let r: UnsafeAtomic<UnsafeRawPointer> = ...
let mr: UnsafeAtomic<UnsafeMutableRawPointer> = ...
let p: UnsafeAtomic<UnsafePointer<T>> = ...
let mp: UnsafeAtomic<UnsafeMutablePointer<T>> = ...
// Standard optional unsafe pointers:
let or: UnsafeAtomic<Optional<UnsafeRawPointer>> = ...
let omr: UnsafeAtomic<Optional<UnsafeMutableRawPointer>> = ...
let op: UnsafeAtomic<Optional<UnsafePointer<T>>> = ...
let omp: UnsafeAtomic<Optional<UnsafeMutablePointer<T>>> = ...
// Unmanaged references:
let u: UnsafeAtomic<Unmanaged<T>> = ...
let ou: UnsafeAtomic<Optional<Unmanaged<T>>> = ...
// Custom atomic representable types:
enum MyState: Int, AtomicProtocol {
case starting
case running
case stopped
}
let ar: UnsafeAtomic<MyState> = ...作为一个特例,我们也需要引入一个懒加载,只读的 atomic 强引用结构。与其他类型不同,它提供的操作非常有限,并且它是使用一个独立的泛型结构体实现的:
struct UnsafeAtomicLazyReference<Instance: AnyObject>这些基本的 Atomic 类型大部分都是围绕着“单精度”的 atomic 操作构建起来的 —— 意味着所有操作都可以让编译器实现为单精度整型指针的操作。(Int64 和 UInt64 在 32-bit 平台上的情况比较特殊,需要双精度的 atmoics)
指针和引用类型的 atomic 操作都可以视作是 atmoic 的 Int 操作来实现。所以理论上我们可以忽略掉它,并且不会造成任何性能和泛用性上的损失。然而在实践中,我们认为用户无论如何都会给 atomic 指针建立抽象,所以为此建立标准化的 API 也非常合理,减少重复劳动和模版代码,并且也减少了项目间不必要的定义差异。通过标准库直接提供实现,用户可以给自定义的类型添加 AtomicProtocol 的 conformance,让它们可以直接装进 UnsafeAtomic 里。同样的,我们也会给自定义的 atomic-representable 类型提供支持。
特别的是,这些 atomic 类型都没有提供组合值 —— 它们不会存储任何附带信息(例如版本标签)。双精度 Atomics 小节里介绍了一些我们之后可能会想要引入的类型。我们的期望是这个初始提案的经验,可以帮助到未来的设计。
Atomics 模块也定义三个 enum-like 的结构体来表示三种风格的 memory orderings,并且有一个独立的全局函数来负责 memory barriers。我们在 Atomic Memory Orderings 里有详细的介绍。
内存管理(缺乏)
Unsafe 的前缀意味着新的 atomic 结构并不支持自动内存管理。同样的,提供了 init(at:) 构造器的 unsafe atomic 类型也不会:
public struct UnsafeAtomic<Value: AtomicProtocol> {
public struct Storage {
// Transform `value` into a new storage instance.
init(_ value: __owned Value)
// Dispose of this storage instance, returning the final value it represents.
mutating func dispose() -> Value
}
public init(at address: UnsafeMutablePointer<Storage>)
}
public struct UnsafeAtomicLazyReference<Instance: AnyObject> {
public struct Storage {
init()
mutating func dispose() -> Instance?
}
public init(at address: UnsafeMutablePointer<Storage>)
}使用了这些 unsafe atomic 类型的代码必须手动管理它们的生命周期去保证
- 它通过正确的 Storage 类型提供边界,
- 它通过 Storage.init(_:) 初始化了一个定义清晰的值,
- 它通过 atomic 操作访问时,对应位置的值始终是合法的,并且
- 它在内存被回收之前,storage 对应的值必须被正确地回收(通过 Storage.dispose())。
以上这些通常会通过分配一个专门用来存储 atomic 值的动态变量来完成:
// Create an unsafe atomic integer, initialized to 0
func atomicDemo<Value: AtomicProtocol>(initialValue: Value) {
typealias Storage = UnsafeAtomic<Value>.Storage
let ptr = UnsafeMutablePointer<Storage>.allocate(capacity: 1)
ptr.initialize(to: Storage(initialValue))
let atomic = UnsafeAtomic<Int>(at: ptr)
... // Use `atomic`
// Destroy it
_ = ptr.pointee.dispose()
ptr.deinitialize(count: 1)
ptr.deallocate()
}实际上,这是一种很常见的模式,所以全部 UnsafeAtomic* 类型都为此提供了便捷方法:
extension UnsafeAtomic {
// Dynamically allocates & initializes storage
public static func create(initialValue: __owned Value) -> Self
// Deinitializes and deallocates storage, returning final value
@discardableResult
public func destroy() -> Value
}
extension UnsafeAtomicLazyReference {
public static func create() -> Self // Initializes to `nil`
public static func create() -> Self // 初始化为 `nil`
@discardableResult
public func destroy() -> Instance?
}我们可以使用这些来提高可读性:
let atomic = UnsafeAtomic<Value>.create(initialValue: 0)
... // Use `atomic`
atomic.destroy()成对使用 create/destroy 可以简化对象生命周期的管理。例如,典型情况下 UnsafeAtomic 值会在作为类的实例属性使用,我们期望看到 init 时调用 create,deinit 时调用 destroy:
class AtomicCounter {
private let _value = UnsafeAtomic<Int>.create(initialValue: 0)
deinit {
_value.destroy()
}
func increment() {
_value.wrappingIncrement(by: 1, ordering: .relaxed)
}
func get() -> Int {
_value.load(ordering: .relaxed)
}
}虽然 create/destroy 很方便,但手动控制存储位置也很有必要,有些使用场景下分别为每个 atomic 值申请内存会显得浪费。(例如,这些用例可以使用 ManageBuffer 接口来直接创建atomic 存储空间)
译者注:这里的意思应该是,如果同时要用多个 atomic 值,为每个值分别分配内存不如一次性分配。
现在我们知道如何创建和销毁 atomic 值,该开始介绍实际使用的 atomic 操作了。
基础的 Atomic 操作
UnsafeAtomic 给所有支持类型提供了六个基础的 atomic 操作:
extension UnsafeAtomic {
// Atomically load and return the current value.
public func load(ordering: AtomicLoadOrdering) -> Value
// Atomically update the current value.
public func store(_ desired: __owned Value, ordering: AtomicStoreOrdering)
// Atomically update the current value, returning the original value.
public func exchange(
_ desired: __owned Value,
ordering: AtomicUpdateOrdering
) -> Value
public func compareExchange(
expected: Value,
desired: __owned Value,
ordering: AtomicUpdateOrdering
) -> (exchanged: Bool, original: Value)
public func compareExchange(
expected: Value,
desired: __owned Value,
successOrdering: AtomicUpdateOrdering,
failureOrdering: AtomicLoadOrdering
) -> (exchanged: Bool, original: Value)
public func weakCompareExchange(
expected: Value,
desired: __owned Value,
successOrdering: AtomicUpdateOrdering,
failureOrdering: AtomicLoadOrdering
) -> (exchanged: Bool, original: Value)
}ordering 参数用来表示 atomic 操作是否需要同步前一个(或者后一个)访问带来的效用。在下面有一个单独的小节进行解释。
前三个操作相对比较简单:
- load 返回当前值。
- store 更新当前值。
- exchange 是 load 和 store 的结合;它会更新当前值并且返回旧值,并且整体会作为一个 atomic 操作完成。
接下来三种 compareExchange 的变种就相对比较复杂 :它们会先比较新旧值,只有新旧值不同时才会执行 exchange 的操作。具体来说,它们会在一个 atomic 事务里完成下面的逻辑:
guard currentValue == expected else {
return (exchanged: false, original: currentValue)
}
currentValue = desired
return (exchanged: true, original: expected)这三个变种实现了相同的算法。第一个变种使用同样的 memory order,无论 exchange 是否成功,而另外两个则允许调用者给成功和失败的情况分别指定 memory ordering。这两种顺序各自独立 —— update/load 所有 orderings 的组合都是支持的 [P0418]。(当然,可能需要根据代码生成和目标的 CPU 架构,改为最近似的可用的 ordering)
weakCompareExchange 的形式偶尔在 original 和 expected 相等时也会返回 false。(这种情况会在底层操作处于某些中间状态时出现 —— 例如在 load-link/store-conditional 的指令序列里突然从外部插入了一个中断),这种变种是为了在循环中调用,只有 exchange 成功时才退出循环;在这种循环里使用 weakCompareExchange 可能会有性能提升,因为它可以避免使用 “strong” 的 compareExchange 时造成的循环嵌套。
译者注:具体的细节可以参考 Understanding std::atomic::compare_exchange_weak() in C++11
这种 compare-exchange 原语是很特殊的,因为它通用到可以用来实现其它所有 atomic 操作。例如,下面展示了我们可以如何通过 compareExchange 给 UnsafeAtomic 实现 increment 操作:
extension UnsafeAtomic where Value == Int {
func wrappingIncrement(
by operand: Int,
ordering: AtomicUpdateOrdering
) {
var done = false
var current = load(ordering: .relaxed)
while !done {
(done, current) = compareExchange(
expected: current,
desired: current &+ operand,
ordering: ordering)
}
}
}专门的 Integer 操作
大多数的 CPU 架构都提供了专用的 atmoic 指令,用于特定的整型操作,通常它们都比 compareExchange 的实现更加高效。所以,把这一系列的整型操作都暴露出来,可以让更高效的实现变得可能。
这些专门的整型操作通常有两种变形,基于它们是否会在操作前或操作后返回值:
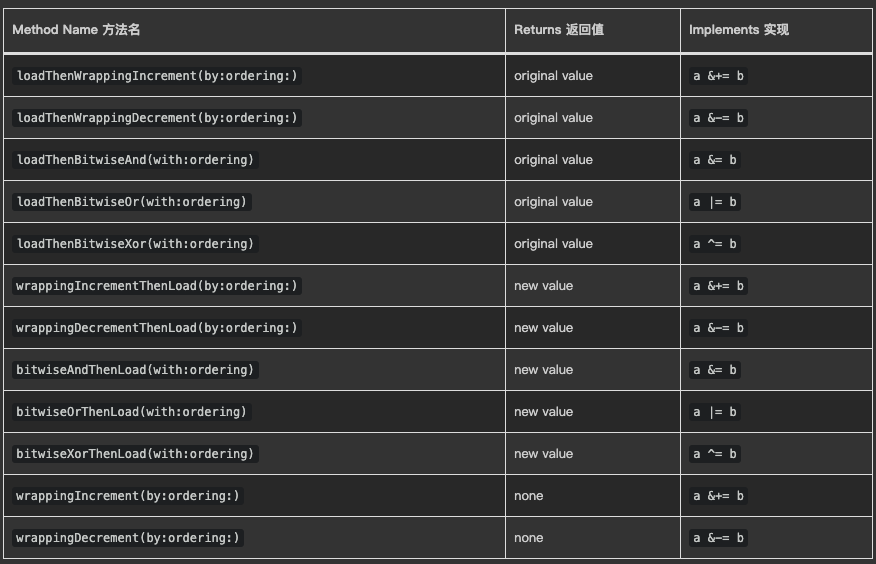
wrappingIncrement 和 wrappingDecrement 操作是为了自增/自减提供的便捷方法(不需要返回值时)。
虽然我们要求所有 atomic 操作都无需加锁,但并不要求无等待(wait-free)。所以,在那些无法为操作直接提供硬件支持的架构上,我们会要求它们使用 compareExchange 循环来实现上述的操作。
UnsafeAtomic 在 Value 遵循 AtomicInteger 协议时会提供下列方法,并且所有标准定长的整数类型都满足这个条件:
extension UnsafeAtomic where Value: AtomicInteger {
public func loadThenWrappingIncrement(
by delta: Value,
ordering: AtomicUpdateOrdering
) -> Value
...
public func bitwiseOrThenLoad(
with value: Value,
ordering: AtomicUpdateOrdering
) -> Value
...
public func wrappingIncrement(
by delta: Value,
ordering: AtomicUpdateOrdering
)
}
let counter = UnsafeAtomic<Int>.create(initialValue: 0)
defer { counter.destroy() }
counter.wrappingIncrement(by: 42, ordering: .relaxed)Atomic Lazy References
UnsafeAtomic
注意,读取 atomic unmanaged 引用和将它转化为强引用是两个独立的操作,它们无法在一个 atomic 事务操作里完成。当其它线程释放了对象,当前线程又读取它的时候就会产生竞态:
// BROKEN CODE. DO NOT EMULATE IN PRODUCTION.
let myAtomicRef = UnsafeAtomic<Unmanaged<Foo>>.create(initialValue: ...)
// Thread A: Load the unmanaged value and then convert it to a regular
// strong reference.
let ref = myAtomicRef.load(ordering: .acquiring).takeUnretainedValue()
...
// Thread B: Store a new reference in the atomic unmanaged value and
// release the previous reference.
let new = Unmanaged.passRetained(...)
let old = myAtomicRef.exchange(new, ordering: .acquiringAndReleasing)
old.release() // RACE CONDITION如果线程 B 释放的对象刚好是线程 A 正在加载的,那此时线程 A 的 takeUnretainedValue 也许会 retain 一个已经释放掉的对象。
这种问题让 UnsafeAtomic
就目前来说,我们会提供一个独立的类型 UnsafeAtomicLazyReference 来处理这种场景,它是在 UnsafeAtomic 的基础上封装实现的。(这个提案里引入的所有 atomic 类型,只有 UnsafeAtomicLazyReference 像一个常规的类实例的引用一样 —— 其它的指针/引用类型都需要让用户手动管理内存。)
一个 UnsafeAtomicLazyReference 会持有一个 optional 引用并且将它的初始值设为 nil。这个引用之后只能再设置一次,但可以进行任意次数的读取。storeIfNilThenLoad 只会在第一次调用时生效,后续的调用都会被忽略,并且返回当前的值。
public struct UnsafeAtomicLazyReference<Instance: AnyObject> {
public typealias Value = Instance?
public struct Storage {
public init()
@discardableResult
public mutating func dispose() -> Value
}
public init(at address: UnsafeMutablePointer<Storage>)
public static func create() -> Self
@discardableResult
public func destroy() -> Value
public func storeIfNilThenLoad(_ desired: __owned Instance) -> Instance
public func load() -> Instance?
}这是提案里唯一一个不提供 load/store/exchange/compareExchange 操作的 atomic 类型。
这个结构可以让库作者实现一个线程安全,懒加载的模式:
var _foo: UnsafeAtomicLazyReference<Foo> = ...
// This is safe to call concurrently from multiple threads.
var atomicLazyFoo: Foo {
if let foo = _foo.load() { return foo }
// Note: the code here may run concurrently on multiple threads.
// All but one of the resulting values will be discarded.
let foo = Foo()
return _foo.storeIfNilThenLoad(foo)
}标准库内部已经通过这种模式来实现 Array, Dictionary 和 Set 的延迟桥接。
注意,它并不像其它 atomic 类型那样,load 和 storeIfNilThenLoad(_:) 并没有提供 ordering 参数。(在内部,它们会映射为抢占/释放操作来保证正确的顺序)
Atomic Memory Orderings
想要使用纯 Swift 代码实现同步结构的话,我们必须给语言引入一套内存一致性模型。幸运的是,Swift 已经可以跟 C/C++ 的内存模型进行无缝交互,所以基于抢占/释放的顺序,直接采用 C/C++ 风格的内存模型也很合理。在这个模型里,并发访问共享状态依旧是未定义行为,除非所有访问都通过显式的同步操作强制合并到一条无冲突的时间线里。
前面介绍的 atomic 结构会将并发读/写访问映射为底层架构对应的 atomic 指令。无论从哪个线程执行,特定 atomic 值的全部访问都会被插入到某个连续的全局时间线里。
然而,仅靠它还无法让我们同步多个常规变量的访问,或者是同步不同内存位置的 atomic 访问。为了支持这种同步功能,每一个 atomic 操作都需要能够配置成同线程里其它变量访问的同步节点,避免之前的变量访问在 atomic 操作后执行,诸如此类。另一个线程的 atomic 操作也可以与同一个节点进行同步,让多线程的访问建立起一条严格的(局部的)时间线。这样,我们就可以推导出多线程操作可能的顺序,尽管底层实现对于我们来说是不透明的(这就是锁和 DispatchQueue 用来序列化随机访问共享变量的方式),详细细节可以看 [C++17, N2153, Boehm 2008]。
这一段比较复杂,少了一些上下文讲解,其实就是 CPU 为了最大化执行效率会乱序执行我们的代码,只保证最终的运行效果,这个过程中需要我们提供一些额外的信息,让 CPU 知道线程间共享的数据以及它们共享的方式。
推荐阅读:
- 什么是 Memory Ordering?
- 如何理解 C++11 的六种 memory order?
另外这里也可以参考原文:
However, this alone does not give us a way to synchronize accesses to regular variables, or between atomic accesses to different memory locations. To support such synchronization, each atomic operation can be configured to also act as a synchronization point for other variable accesses within the same thread, preventing previous accesses from getting executed after the atomic operation, and/or vice versa. Atomic operations on another thread can then synchronize with the same point, establishing a strict (although partial) timeline between accesses performed by both threads. This way, we can reason about the possible ordering of operations across threads, even if we know nothing about how those operations are implemented. (This is how locks or dispatch queues can be used to serialize the execution of arbitrary blocks containing regular accesses to shared variables.) For more details, see [C++17, N2153, Boehm 2008].
我们可以使用 ordering: 参数来指定每一个 atomic 操作的同步级别。这个提案会引入五个不同的 memory orderings,它们可以根据逻辑分为三个类别,从最宽松到最严格:
- .relaxed
- .acquiring, .releasing, .acquiringAndReleasing
- .sequentiallyConsistent
这与 C++ 标准库的 std::memory_order 相对应,并且它们的语义也是一致的:
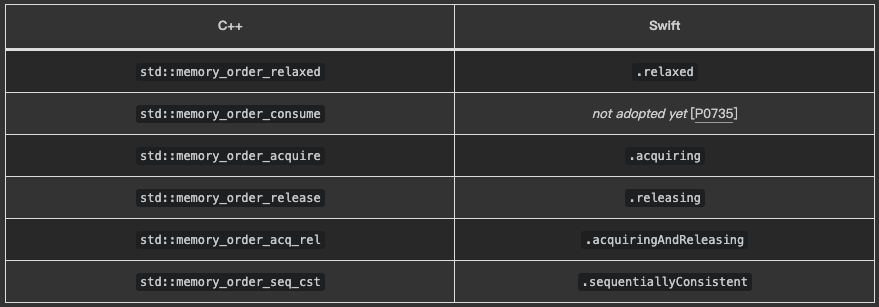
我们认为这些 ordering 参数属于底层 atomic 操作的必要组成部分,所以我们要求 UnsafeAtomic 的所有 atomic 操作都必须提供 ordering 参数。这里的意图是强制开发者去谨慎思考每个 atomic 操作该使用的 ordering。(也许更重要的是,让阅读代码的人能够注意到这里使用的 ordering —— 让 .sequentiallyConsistent 在意图不明确时没那么容易通过 code review)
倾向于默认使用 sequentiallyConsistent ordering 的项目也可以给 UnsafeAtomic 添加一个 non-public 的 extension 去实现它。但我们还是认为 Atomics 在使用时不应该提供默认的 ordering。
Atomic orderings 根据操作类型分为三个结构体,就像下面列出来的那样。通过把它们建模成不同的类型,我们可以保证不支持的操作/ordering 会抛出明确的编译期错误:
@frozen
struct AtomicLoadOrdering {
static var relaxed: Self { get }
static var acquiring: Self { get }
static var sequentiallyConsistent: Self { get }
}
@frozen
struct AtomicStoreOrdering {
static var relaxed: Self { get }
static var releasing: Self { get }
static var sequentiallyConsistent: Self { get }
}
@frozen
struct AtomicUpdateOrdering {
static var relaxed: Self { get }
static var acquiring: Self { get }
static var releasing: Self { get }
static var acquiringAndReleasing: Self { get }
static var sequentiallyConsistent: Self { get }
}这些结构体表现得像是 non-frozen 的 enum,并且使用(non-public)已知的原始值展现形式。这让它们可以得到充分的优化,并且在未来也可以随时添加新的 memory orderings(必要时)。(它们不能是 frozon 的 enum,因为这样会让我们无法添加的 ordering,并且这样生成的内存布局也无法获得优化,特别是在 -Onone 时)
我们也有一个全局函数 atomicMemoryFence 去提供 memory ordering 约束,而无需关联到特定的 atomic 操作。它与 C++ [C++17] 的 std::memory_thread_fence 相对应。
public func atomicMemoryFence(ordering: AtomicUpdateOrdering)Fences 比绑定到特定 atomic 操作的 Ordering 稍微更强力一些 [N2153](但也更难使用);我们期望它们的使用只限于性能最敏感的使用场景。
Atomic 协议的继承
atomic 类型的概念会通过 AtomicProtocol 表达出来。AtomicInteger 将它提炼出来并且添加了一系列整型操作的支持。
public protocol AtomicProtocol {
...
}
public protocol AtomicInteger: AtomicProtocol, FixedWidthInteger
where ... {
...
}虽然 AtomicProtocol 和 AtomicInteger 是公开协议,但它们的 requirements 会被看作是标准库的实现细节隐藏起来。(也就是上面省略掉的部分)
这些隐藏的 requirements 会给 atomic 类型的值和关联的存储形式设置了一个双向映射,由存储形式负责去实现原始的 atomic 操作。
这些特定的细节不会纳入到 Swift Evolution 的过程中,不同版本的标准库可能会有不同的实现,只要能够保持 ABI 兼容性。
根据现有的标准库 API 设计习惯,这些协议的相关类型和成员都会使用下划线作为前缀。就像标准库里其它下划线开头的公开 API,手动实现或者访问这些下划线的属性和方法都有可能会导致编译或者运行错误。(when built using any Swift release other than the one for which it was initially written)
下面列举的就是标准库里实现了 AtomicProtocol 的所有类型:
extension UnsafeRawPointer: AtomicProtocol {...}
extension UnsafeMutableRawPointer: AtomicProtocol {...}
extension UnsafePointer: AtomicProtocol {...}
extension UnsafeMutablePointer: AtomicProtocol {...}
extension Unmanaged: AtomicProtocol {...}
extension Int: AtomicInteger {...}
extension Int64: AtomicInteger {...}
extension Int32: AtomicInteger {...}
extension Int16: AtomicInteger {...}
extension Int8: AtomicInteger {...}
extension UInt: AtomicInteger {...}
extension UInt64: AtomicInteger {...}
extension UInt32: AtomicInteger {...}
extension UInt16: AtomicInteger {...}
extension UInt8: AtomicInteger {...}
extension Optional: AtomicProtocol where Wrapped: AtomicProtocol, ... {...}我们只给整型类型提供 atomic 算数操作。虽然理论上我们可以让 atomic 指针也支持算数操作,但这本身就不是安全的做法,除非接入显式的指针逃逸检查。我们也不认为这种操作足够实用,以至于需要纳入进标准库里;并且用户可以自己通过 compare-exchange 循环很便捷地实现。
Optional Atomics
标准库的 atomic 指针类型和 unmanaged 引用也支持在它们的 optional-wrapped 类型上使用 atomic 操作。Optional 通过 AtomicProtocol 的 Conditional Conformance 实现这一点;实际的约束是一个实现细节(它会要求封装类型内部的 atomic 存储格式支持 nil 值)
extension Optional: AtomicProtocol where ... {
...
}这个提案会为下列类型提供 optional-atomics 的支持:
UnsafeRawPointer
UnsafeMutableRawPointer
UnsafePointer<Pointee>
UnsafeMutablePointer<Pointee>
Unmanaged<Instance>用户无法通过代码手动实现和扩充这个列表,只能通过后续的提案去做这件事情。
在构建 lock-free 的数据结构时,Atomic optional 指针和引用非常有用。(尽管这些初始的引用类型限制了它能够搭建的东西;更多细节,请看关于 ABA 问题和未来的方向小节里提到的内存回收问题)
举个例子,请看下面一个 lock-free,单一消费者的栈实现。(它支持随机并发多线程插入,但只允许每次 pop 一个)
class LockFreeSingleConsumerStack<Element> {
struct Node {
let value: Element
var next: UnsafeMutablePointer<Node>?
}
typealias NodePtr = UnsafeMutablePointer<Node>
private var _last = UnsafeAtomic<NodePtr?>.create(initialValue: nil)
private var _consumerCount = UnsafeAtomic<Int>.create(initialValue: 0)
deinit {
// Discard remaining nodes
// 丢弃掉剩余的 nodes
while let _ = pop() {}
_last.destroy()
_consumerCount.destroy()
}
// Push the given element to the top of the stack.
// It is okay to concurrently call this in an arbitrary number of threads.
func push(_ value: Element) {
let new = NodePtr.allocate(capacity: 1)
new.initialize(to: Node(value: value, next: nil))
var done = false
var current = _last.load(ordering: .relaxed)
while !done {
new.pointee.next = current
(done, current) = _last.compareExchange(
expected: current,
desired: new,
ordering: .releasing)
}
}
// Pop and return the topmost element from the stack.
// This method does not support multiple overlapping concurrent calls.
func pop() -> Element? {
precondition(
_consumerCount.loadThenWrappingIncrement(ordering: .acquiring) == 0,
"Multiple consumers detected")
defer { _consumerCount.wrappingDecrement(ordering: .releasing) }
var done = false
var current = _last.load(ordering: .acquiring)
while let c = current {
(done, current) = _last.compareExchange(
expected: c,
desired: c.pointee.next,
ordering: .acquiring)
if done {
let result = c.move()
c.deallocate()
return result.value
}
}
return nil
}
}自定义 Atomic 类型
为了支持用户自定义 atomic 类型,AtomicProtocol 为 RawPresentable 提供了一系列完整的默认实现,只要它的 rawValue 也是 atomic 的:
extension AtomicProtocol
where Self: RawRepresentable, RawValue: AtomicProtocol, ... {
...
}被省略的约束设置了一个与 RawValue 相匹配(隐藏的)atomic 存储类型。默认的实现会转发所有 atomic 操作给 rawValue 的实现,根据需要转化 to/from。
这样让标准库以外的代码也可以添加新的 AtomicProtocol conformance,并且不需要手动实现所有隐藏的实现要求。在实现一些简单的 raw-represenable 的枚举时特别实用,例如简单的 atomic 状态机:
enum MyState: Int, AtomicProtocol {
case starting
case running
case stopped
}
let currentState = UnsafeAtomic<MyState>.create(initialValue: .starting)
...
if currentState.compareExchange(
expected: .starting,
desired: .running,
ordering: .sequentiallyConsistent
).exchanged {
...
}
...
currentState.store(.stopped, ordering: .sequentiallyConsistent)
...
currentState.destroy()将 Ordering 参数约束为编译期可推导的常量
把 ordering 建模为普通的函数参数可以让我们使用所有 Swift 程序员都熟悉的语法。不幸的是,这意味着 atomic 操作的实现里我们必须使用 switch 匹配 ordering 参数:
extension Int: AtomicInteger {
public typealias AtomicStorage = Self
...
public func atomicCompareExchange(
expected: Int,
desired: Int,
at address: UnsafeMutablePointer<AtomicStorage>,
ordering: AtomicUpdateOrdering
) -> (exchanged: Bool, original: Int) {
// Note: This is a simplified version of the actual implementation
let won: Bool
let oldValue: Int
switch ordering {
case .relaxed:
(oldValue, won) = Builtin.cmpxchg_monotonic_monotonic_Word(
address, expected, desired)
case .acquiring:
(oldValue, won) = Builtin.cmpxchg_acquire_acquire_Word(
address, expected, desired)
case .releasing:
(oldValue, won) = Builtin.cmpxchg_release_monotonic_Word(
address, expected, desired)
case .acquiringAndReleasing:
(oldValue, won) = Builtin.cmpxchg_acqrel_acquire_Word(
address, expected, desired)
default: // .sequentiallyConsistent
(oldValue, won) = Builtin.cmpxchg_seqcst_seqcst_Word(
address, expected, desired)
}
return (won, oldValue)
}
}由于我们要求 atomic 原语必须以最少的代价编译到对应的 atomic 指令,我们必须保证 switch 语句总能优化成我们需要的单个 case;它们不能放到运行时去计算。
幸运的是,这些特殊的函数可以通过配置,强制内联到每一个调用方里,保证让 constant folding 移除掉 switch 语句,只要 ordering 是一个编译期的常数。不幸的是,第二个要求很难达成,并且也没办法达到 atomic 操作期望的性能。
假设我们要使用 compareExchange 来定义一个 atomic 整型的加法运算,会在溢出时触发 trap,而不是产生任何未定义行为:
extension UnsafeAtomic where Value == Int {
// Non-inlinable
public func checkedIncrement(by delta: Int, ordering: AtomicUpdateOrdering) {
var done = false
var current = load(ordering: .relaxed)
while !done {
(done, current) = compareExchange(
expected: current,
desired: current + operand, // Traps on overflow
ordering: ordering)
}
}
}
// Elsewhere:
counter.checkedIncrement(by: 1, ordering: .relaxed)如果 Swift 编译器出于某些原因无法内联 checkedIncrement 的调用,那么 ordering 的值就无法在编译期推断出来,即使 compareExchange 会被内联,它的 switch 语句也无法省略。这会导致潜在的性能严重劣化,影响操作的可伸缩性(scalability)。
为了避免这些问题,我们会添加一个特殊的类型检查阶段,规定所有的 atomic 操作的 ordering 参数都必须为编译器常量。任何试图传递动态 ordering 值的代码都会产生编译错误(例如上面的 compareExchange 调用)
一个 ordering 表达式想要在编译期优化为常数需要满足(1)直接调用 Atomic*Ordering 的工厂方法(.relaxed, .acquiring, 等等),或者(2)它引用了可计算的常量。
注意 这个功能的实现在另外一个的 PR 里 apple/swift#26969。
实现这个功能相关的编译器改动最终可以变成一个通用功能,围绕着表达式常量化展开(constant-evluable expressions);然而,第一版的实现只是为了支持这个计划里引入的 atomic 操作。(目前,用户自定义的封装作为 ordering 参数传递给底层的 atomic 操作,例如 checkedIncrement)
与现有的语言功能交互
独占性原则的修正
新的 atomic 操作看起来就是变量的读或写访问,但与常规的读/写访问不同的是,并发地执行它们是安全的。实际上,安全的并发访问就是我们引入的原因!所以我们必须保证独占性原则不会禁止这种用例。
提案里的 atomic 操作会实现为 unsafe 指针操作;实际上,新的 atomic 类型基本上就是 unsafe 指针的一层薄薄的封装。虽然 [SE-0176] 的独占性原则没有涉及 unsafe 指针,但它还是将 pointee 重叠的读写访问判定为违反独占性原则。
为了解决这个问题,我们提议引入 atomic 访问的概念,并且将独占性访问原则修正为:
同一变量的两个访问不能重叠,除非它们都是读访问或者都是 atomic 访问。
我们将atomic 访问解释为这个提案里引入的 atomic 操作:load(ordering:), compareExchange(expected:desired:ordering:), 等等。如果两个访问了相同内存地址的操作属于上述的 atomic 操作,那我们就认为是在它们是在访问同一个变量。(未来的提案可能会引入更多 atomic 访问的方式)
我们认为上述的修正只是换了个方式重新阐述之前已有的内容,而并不是引入新的约束。
注意,类似于这样,这个提案里绝大部分都是在 library 层面做加法;它的实现不需要改变 Swift 编译器实现 Swift 内存模型的方式。例如,不需要减少任何现有编译时/运行时的独占性检查,因为 unsafe 指针操作不在检查的范围内。同样的,因为新的操作会直接映射为 LLVM 的 atoimc 指令,它们可以与现有的 LLVM Thread Sanitizer 工具无缝兼容 [Tsan1, TSan2])。
目前,我们暂时将混合使用 atomic/non-atomic 访问同一内存位置的行为看作是未定义行为,即便混合访问能够保证不会重叠(这个限制不会作用于存储空间初始化和销毁期间的访问,它们总是 nonatomic 的)。可能未来的提案会放宽这个限制。
非瞬时访问
注意:这个小节只是再强调一遍独占性原则带来的连锁反应,它不是在提议要做任何语言或者标准库的改动。
就像 [SE-0176] 里阐述的那样,Swift 允许非瞬时访问(non-instantaneous)。举个例子,调用变量的 mutating 方法会被视为函数调用期间活跃的读写访问:
var integers: [Int] = ...
...
integers.sort() // A single, long write access独占性原则禁止同一变量同时发生的读/写和写/写访问,所以当一个线程调用 sort() 时,其它的线程都不允许访问 integers。注意这与 sort() 的实现无关,只是声明为 mutating 产生的连锁效应。
注意:这么做的理由是,编译器也许会调整 mutating 的实现,先将当前值拷贝到一个临时变量,运行完 sort 之后,再复制回原本的 integers。如果 integers 是一个计算属性,这是唯一一个合理实现 mutating 调用的方式。如果没有禁止重叠访问,这种隐式拷贝也许会导致竞态问题,即便 mutating 方法的实现里没有实际改变任何数据。
atomic memory orderings 重要的一点是,它们在 atomic 操作期间只可以进行同步访问,并且不会重叠。在其它 atomic 操作执行期间它们无法同步访问变量。
这意味着不可能实现任何“线程安全”的 mutating 方法,无论我们在它们的实现里有多少同步操作。例如,下面尝试给 Int 实现一个 “atomic” 的加法操作,它注定失败:
import Dispatch
import Foundation
let _mutex = NSLock()
extension Int {
mutating func atomicIncrement() { // BROKEN, DO NOT USE
_mutex.lock()
self += 1
_mutex.unlock()
}
}
var i: Int
...
i = 0
DispatchQueue.concurrentPerform(iterations: 10) { _ in
for _ in 0 ..< 1_000_000 {
i.atomicIncrement() // Exclusivity violation
}
}
print(i)虽然 NSLock 能够保证 self += 1 这一行总是顺序执行,并发的 atomicIncrement 调用还是被判定为违反了独占性原则,因为 i 的写访问在函数调用时就开始了,在 mutex.lock() 的调用之前。所以,上面的代码存在未定义行为,尽管它们都加锁了。(举个例子,它也许会打印任何 1 到 10000_000 之间的任何值,或者它会触发运行时的独占性检查,亦或者其它。)
注意这个约束不是新的 low-level atomic 原语引入的 —— 它之前就存在于语言里。
这也是前面提到的 AtomicCounter 和 LockFreeSingleCosumerStack 声明为 class 的其中一个原因。类实例方法允许改变它们的存储变量,无需声明为 mutating,因此它们并不在独占性原则的访问内。(当然,它们的实现必须保证它们访问的变量遵守这个原则)
注意:这些结构被声明为 class 更本质的原因是它们难以使用 struct 进行建模 —— 它们的实例倾向于持有一个固定的标识去避免拷贝,它们经常需要使用稳定的内存空间,诸如此类。Ownership Manifesto 的 non-copiable 类型也许最终会提供一个更高效和更安全的模型,但目前的 Swift 里我们需要某种引用类型来呈现它们:通常来说,是 class(像是 AtomicCounter)或者是一些 unsafe 指针类型(像是 UnsafeAtomic)
隐式指针转换
为了简化导入的 C 函数的交互,Swift 提供了几种隐式转换让 Swift 的值可以转换为 unsafe 指针。这通常需要使用 Swift 特殊的 & 语法来传递 inout 值。乍一看这个符号跟 C 的取址语法很像,而且作用也一样:
func a(_ ptr: UnsafePointer<CChar>)
func b(_ ptr: UnsafePointer<Int>)
// Implicit conversion from String to nul-terminated C string
a("Hello")
// Implicit conversion from Array to UnsafePointer<Element>
var array = [1, 2, 3]
b(array) // passes a pointer to array's underlying storage buffer
b(&array) // another way to spell the same
// Implicit conversion from inout T to UnsafePointer<T>
var value = 42
b(&value)
b(&array[0])不幸的是,Swift 的变量内存位置并不一定是固定的,即使是它们在被赋值时,也没有可靠的方式去获取它们存储的地址。(当然,我们显式地 allocate 时例外。)
尽管这些转换有时可以让我们调用 C 函数时少写一些代码,但它们也非常容易产生误导 —— 甚至造成损失。问题在于 Swift 跟 C 不一样,生成的指针只在函数调用期间保证有效。上面的指针的转换可能(也经常)会给 inout 值创建一个临时拷贝,并且在函数返回时销毁。在函数返回之后继续使用这些指针就会导致未定义行为。(即使特定情况下它似乎没有引起任何问题,但也许在一些不相关的代码修改后被破坏。)
举个例子,我们也许想要减少 UnsafeAtomic 实例的内存分配,直接通过 & 将一个实例转换为指针,然后将它传递给 UnsafeAtomic.init(at:) 构造器。但语言层面是不支持这么做的,并且会导致未定义行为。
class BrokenAtomicCounter { // THIS IS BROKEN; DO NOT USE
private var _storage = UnsafeAtomic<Int>.Storage(0)
private var _value: UnsafeAtomic<Int>?
init() {
// This escapes the ephemeral pointer generated by the inout expression,
// so it leads to undefined behavior when the pointer gets dereferenced
// in the atomic operations below. DO NOT DO THIS.
_value = UnsafeAtomic<Int>(at: &_storage)
}
func increment() {
_value!.wrappingIncrement(by: 1, ordering: .relaxed)
}
func get() -> Int {
_value!.load(ordering: .relaxed)
}
}为了避免这种错误的用法,这个提案目前的实现里,这样的代码会生成一个警告:
warning: inout expression creates a temporary pointer, but argument 'at' should be
a pointer that outlives the call to 'init(at:)'
_value = UnsafeAtomic<Int>(at: &_storage)
^~~~~~~~~这是借助一个已有 Diagnostic 机制实现的。理想情况下这个警告会升级为编译期错误。
注意:如何为变量取址提供语言支持,可以看 内存安全的 Atomic 结构 里虚构的 @addressable。
方案设计细节
为了尽量让这份文档保持简洁,下面的 API 概要不包含文档,inlinable 的函数实现或者 @usableFromInline 的命名,并且省略掉大部分的注解(@available, @inlinable 等等)。
为了让 Atomic 操作能够编译到它对应的 CPU 指令,下面大部分罗列的入口点都会定义为 @ininable。
完整的 API 定义请查看 implementation。
Atomic Memory Orderings
public func atomicMemoryFence(ordering: AtomicUpdateOrdering)
@frozen
public struct AtomicLoadOrdering: Equatable, Hashable, CustomStringConvertible {
public static var relaxed: Self { get }
public static var acquiring: Self { get }
public static var sequentiallyConsistent: Self { get }
public static func ==(left: Self, right: Self) -> Bool
public func hash(into hasher: inout Hasher)
public var description: String { get }
}
@frozen
public struct AtomicStoreOrdering: Equatable, Hashable, CustomStringConvertible {
public static var relaxed: Self { get }
public static var releasing: Self { get }
public static var sequentiallyConsistent: Self { get }
public static func ==(left: Self, right: Self) -> Bool
public func hash(into hasher: inout Hasher)
public var description: String { get }
}
@frozen
public struct AtomicUpdateOrdering: Equatable, Hashable, CustomStringConvertible {
public static var relaxed: Self { get }
public static var acquiring: Self { get }
public static var releasing: Self { get }
public static var acquiringAndReleasing: Self { get }
public static var sequentiallyConsistent: Self { get }
public static func ==(left: Self, right: Self) -> Bool
public func hash(into hasher: inout Hasher)
public var description: String { get }
}Atomic 协议
protocol AtomicProtocol
public protocol AtomicProtocol {
// Requirements aren't public API.
}这里的 requirements 会给 Atomic 类型的值和关联的 Storage 建立了双向映射,让 Storage 提供实际的原始的 atomic 操作。
确切的 requirements 是标准库的私有实现细节。他们不在 Swift Evolution 的范围内,随着 Swift 版本迭代它们随时可能会被改变。用户不能手动通过代码直接使用或者实现它们。
遵循的类型:
extension UnsafeRawPointer: AtomicProtocol {...}
extension UnsafeMutableRawPointer: AtomicProtocol {...}
extension UnsafePointer: AtomicProtocol {...}
extension UnsafeMutablePointer: AtomicProtocol {...}
extension Unmanaged: AtomicProtocol {...}
extension Optional: AtomicProtocol where Wrapped: AtomicProtocol, ... {...}Optional 的 conditional conformance 确切的约束也是一个私有的实现细节。(它们指定了底层(私有)的存储形式,这种形式必须能够表现一个额外的 nil 值)
当 Wrapped 为以下类型时,Atomic 的 Optional 才会提供 atomic 操作:
UnsafeRawPointer
UnsafeMutableRawPointer
UnsafePointer<Pointee>
UnsafeMutablePointer<Pointee>
Unmanaged<Instance>用户不能通过代码手动扩展这个列表;这个权力(能力)会保留给后续的提案。
为了支持自定义的 “atomic-representable” 类型,只要一个类型遵循 RawRepresentable 并且它的 RawValue 也是 atomic 的,那 AtomicProtocol 就会提供默认的实现:
extension AtomicProtocol where Self: RawRepresentable, RawValue: AtomicProtocol, ... {
// Implementations for all requirements.
}这里省略掉的约束会给 RawValue 类型提供对应的 atomic storage 类型。默认的实现会将它们转成 rawValue 形式,然后转发所有 atomic 操作给它。
protocol AtomicInteger
public protocol AtomicInteger: AtomicProtocol, FixedWidthInteger {
// Requirements aren't public API.
}(其中一个实现要求是 atomic 整型必须使用它们自身作为 atomic storage)
遵循的类型:
extension Int: AtomicInteger { ... }
extension Int64: AtomicInteger { ... }
extension Int32: AtomicInteger { ... }
extension Int16: AtomicInteger { ... }
extension Int8: AtomicInteger { ... }
extension UInt: AtomicInteger { ... }
extension UInt64: AtomicInteger { ... }
extension UInt32: AtomicInteger { ... }
extension UInt16: AtomicInteger { ... }
extension UInt8: AtomicInteger { ... }这个协议的设计不是为了让用户自己提供 conformance。
Atomic 类型
struct UnsafeAtomic<Value>
@frozen
public struct UnsafeAtomic<Value: AtomicProtocol> {
@frozen
public struct Storage {
public init(_ value: __owned Value)
@discardableResult
public mutating func dispose() -> Value
}
public init(at pointer: UnsafeMutablePointer<Storage>)
public static func create(initialValue: __owned Value) -> Self
@discardableResult
public func destroy() -> Value
// Atomic operations:
public func load(ordering: AtomicLoadOrdering) -> Value
public func store(_ desired: __owned Value, ordering: AtomicStoreOrdering)
public func exchange(
_ desired: __owned Value,
ordering: AtomicUpdateOrdering
) -> Value
public func compareExchange(
expected: Value,
desired: __owned Value,
ordering: AtomicUpdateOrdering
) -> (exchanged: Bool, original: Value)
public func compareExchange(
expected: Value,
desired: __owned Value,
successOrdering: AtomicUpdateOrdering,
failureOrdering: AtomicLoadOrdering
) -> (exchanged: Bool, original: Value)
public func weakCompareExchange(
expected: Value,
desired: __owned Value,
successOrdering: AtomicUpdateOrdering,
failureOrdering: AtomicLoadOrdering
) -> (exchanged: Bool, original: Value)
}UnsafeAtomic 也给标准库定长的整型类型提供了一些实用的整型操作。这些都是通过 AtomicInteger 协议提供的:
extension UnsafeAtomic where Value: AtomicInteger {
public func loadThenWrappingIncrement(
by operand: Value = 1,
ordering: AtomicUpdateOrdering
) -> Value
public func wrappingIncrementThenLoad(
by operand: Value = 1,
ordering: AtomicUpdateOrdering
) -> Value
public func wrappingIncrement(
by operand: Value = 1,
ordering: AtomicUpdateOrdering
)
public func loadThenWrappingDecrement(
by operand: Value = 1,
ordering: AtomicUpdateOrdering
) -> Value
public func wrappingDecrementThenLoad(
by operand: Value = 1,
ordering: AtomicUpdateOrdering
) -> Value
public func wrappingDecrement(
by operand: Value = 1,
ordering: AtomicUpdateOrdering
)
public func loadThenBitwiseAnd(
_ operand: Value,
ordering: AtomicUpdateOrdering
) -> Value
public func bitwiseAndThenLoad(
_ operand: Value,
ordering: AtomicUpdateOrdering
) -> Value
public func loadThenBitwiseOr(
_ operand: Value,
ordering: AtomicUpdateOrdering
) -> Value
public func bitwiseOrThenLoad(
_ operand: Value,
ordering: AtomicUpdateOrdering
) -> Value
public func loadThenBitwiseXor(
_ operand: Value,
ordering: AtomicUpdateOrdering
) -> Value
public func bitwiseXorThenLoad(
_ operand: Value,
ordering: AtomicUpdateOrdering
) -> Value
}
struct UnsafeAtomicLazyReference<Instance>
public struct UnsafeAtomicLazyReference<Instance: AnyObject> {
public typealias Value = Instance?
@frozen
public struct Storage {
public init()
@discardableResult
public mutating func dispose() -> Value
}
public init(at address: UnsafeMutablePointer<Storage>)
public static func create() -> Self
@discardableResult
public func destroy() -> Value
// Atomic operations:
public func storeIfNil(_ desired: __owned Instance) -> Instance
public func load() -> Instance?
}代码兼容性
这是单纯的附加改动(additive change),不会带来任何代码兼容性的影响。
对于 ABI 稳定性的影响
这个提案会给标准库添加一个独立的 Atomics 模块,但对于 ABI 稳定没有影响。
在 ABI 稳定的平台上,结构体和协议会作为标准库 ABI 的一部分,在第一个包含了这些的操作系统上可以使用。
这份文档引入的大部分 Atomic 函数都会被强制内联到调用方的代码里。这样,就没有理由将它们包含到标准库的 ABI 里了,因为标准库不会暴露它们的符号。
对于 API 的影响
这是单纯的附加改动;它不会对现有代码的 API 产生影响。
这里引入的新结构,提案的设计允许我们在未来对 Swift 标准库做下列改变:
添加新的 Atomic 类型(和更高层级的抽象)。(These new types would not directly back-deploy to OS versions that predate their introduction.) 添加新的 memory orderings。因为所有的 atomic 操作都会直接内联编译到用户代码里,后续决定新引入的 memory ordering 可以部署到任何包含这个提案的 OS 里。 给这里引入的类型添加新的 atomic 操作,这会影响内部的 protocol requirements,所以他们无法向后部署到 ABI 稳定的系统版本里。 给 Atomic 操作引入一个默认的 memory ordering(给 ordering 添加一个默认值,或者添加一个新的重载)。这也会是一个可以向后部署的改动。 (我们不一定会做这些改动,我们只是保留可以这么做的空间)
未来的方向
内存安全的 Atomic 结构
Ownership Manifesto 引入的non-copiable 类型也许可以让我们更有效地表达那些需要固定内存位置的结构。Atomics 和其它同步工具就是这种结构的典型例子,相比起这个提案里引入的 unsafe 类型,把他们建模为 non-copiable 类型可以减少 unsafe 动态变量和手动内存管理,并且没有显著的缺陷。
moveonly struct Atomic<Value: AtomicProtocol> {
typealias Storage = PrivateAtomicStorage<Value>
@addressable private var storage: Storage
init(_ value: Value) {
storage = Storage(initialValue: value)
}
deinit {
storage.dispose()
}
func load(ordering: AtomicLoadOrdering) -> Value {
let ptr = mutablePointer(to: \.storage, in: self)
let result = Storage.atomicLoad(at: ptr, ordering: ordering)
return Storage(decoding: result)
}
func store(_ desired: Value, ordering: AtomicStoreOrdering) {
let ptr = mutablePointer(to: \.storage, in: self)
let desiredRaw = Storage(encoding: desired)
Storage.atomicStore(desiredRaw, at: ptr, ordering: ordering)
}
...
}
moveonly struct UnfairLock {
@addressable private var value: os_unfair_lock
init() {
self.value = os_unfair_lock()
}
func lock() {
os_unfair_lock_lock(mutablePointer(to: \.value, in: self))
}
func unlock() {
os_unfair_lock_unlock(mutablePointer(to: \.value, in: self))
}
}注意:除了不可复制类型之外,这个例子也依赖了一个虚构的语言功能,这个功能可以获取存储属性的内存位置(@addressable 和 mutablePointer(to:in:))。另外为了简化,它也假设不可复制类型允许在没有标记 mutating 的函数里修改它们的状态。
正确地设计和实现这些功能需要大量的工作。然而,我们觉得让并发功能先启动开发工作更重要,即使不可复制类型还没有实现。当这些功能实现时,提案里引入的这些类型也不会阻碍我们后续引入 memory-safe 和 non-copiable 的 atomic 类型。
虽然现在我们可以使用 class 去建模 atomic 类型(例如,上面讨论里的 AtomicCounter 类型),但我们觉得长期而言,基于 class 的方案带来的潜在开销是不可接受的。所以,我们更倾向于 unsafe 但是低开销的方案,把 Atomic 这个“优雅的”命名保留给后续的提案。(Swift 程序员依旧可以使用基于 class 的 atomics,如果他们不想在同步代码里使用 unsafe 结构)
双精度 Atomics 和 ABA 问题
译者注:swift-atomics 里已经实现了双精度的 atomics。
在它们的目前的单精度形式里,Atomic 指针和引用类型容易遇到一种叫做 ABA 问题的竞态问题。一个被销毁的对象的内存位置,可能会被申请存放另一个新创建的对象。所以,对 Atomic 指针连续两次 load 可能会访问到相同的值,即使指针已经在两次 load 中间已经发生了好几次变更,并且指向的内存已经被完全替换掉了。在原生实现的并发数据结构里,可能会成为一个难以捉摸且致命的竞态问题的来源。
虽然这份文档里引入的单精度 atomic 原语对于一些应用场景来说已经很实用了,但额外提供一些能够在同一个事务里操作两个 Int 大小的值的 atomic 操作也会很实用。所有支持(atomics)的架构也都提供了双精度 atomic 的硬件支持。
例如,第二个 word 可以用来作为 atomic 值的版本计数器(有时候也被称为 “stamp” 或 “tag”),这样就可以通过检验同一个值在两次 load 之间是否产生过变化来解决 ABA 问题。
为了在标准库里支持双精度的 atomic 操作,我们需要引入抽象来描述它们的值,包括(可能 platform-specific)内存对齐的要求,去迎合底层的 CPU 指令。我们认为这些不在这个提案的范围内,所以我们决定推迟到后续的提案里讨论。
Atomic 强引用和 Memory Reclamation 问题
译者注:swift-atomics 里已经实现了 Atomic 强引用。
也许这有点反直觉,但实现一个高性能,无锁的 atomic 强引用并不是一件简单的事情。这个提案并不包含相关的结构去做这件事,除了 UnsafeAtomicLazyReference。
Swift 的强引用总是使用 atomic 操作来实现引用计数。这让引用可以在多线程并发读取(但不包括修改),并且每个对象总能在它最后一个引用消失时销毁。然而,atomic 引用自身需要有额外的同步机制,才能让多个线程共享同一个可变的引用。
难点在于 atomic load 操作的实现,这里面包含了两个独立的子操作,它们都需要作为同一个 atomic 事务的一部分:
- 加载引用的值。
- 增加对象的引用计数。
如果允许一个 store 操作在 1 和 2 中间释放掉引用,那已经读取到的引用就有可能在 load 操作尝试增加引用计数时就已经被回收了。
如果没有一个高效的方式将这两个步骤作为一个 atomic 事务实现的话,那 store 的实现就需要延迟释放被覆盖的值,直到它能保证所有的 load 操作都结束了为止。如何实现它其实就是并发数据结构里的 memory recalmation 问题。
有很多不同的方式可以绕过这个问题,有些可能足够通用,可以放到后续的提案里。(例如说基于双精度 atomic,在第二个 word 里进行引用计数操作。)
(atomic 强引用基于锁去实现会更加直观;虽然这样的一个结构显然不是无锁的,但它还是很实用,所以可能也有加入标准库的价值。但这并不在这个提案的范围内。)
添加新的底层 Atomic 功能
为了支持那些比 atomic 操作粒度更小的操作,额外提供这些底层 atomic 功能可能会有帮助:
- 支持更多类型 atomic 值(例如双精度 atomic 和浮点 atomic [P0020]))
- 新的 memory ordering,例如 consuming load ordering [P0750] 或者 tearable atomics [P0690]
- 避免某些特定编译优化的 “volatile” atomics
- 只影响编译器的 memory fences(避免单线程竞态,例如信号处理)
- 等等…
我们会把这些推迟到后续提案里。
其它替代方案
默认的 ordering
我们考虑过把 Atomics 模块里所有的 atomic 操作默认的 order 设置为 sequentially consistent。虽然我们承认这么做可以让 atomics 稍微更加易用,但隐式 ordering 值会影响性能敏感的使用场景(atomics 的主要使用场景)。Sequential consistency 相对来很少使用在这种场景下,并且隐式的默认值更容易让它通过 code review。
希望使用默认 ordering 的用户可以定义函数去重载:
extension UnsafeAtomic {
func load() -> Value {
load(ordering: .sequentiallyConsistent)
}
func store(_ desired: Value) {
store(desired, ordering: .sequentiallyConsistent)
}
func exchange(_ desired: Value) -> Value {
exchange(desired, ordering: .sequentiallyConsistent)
}
func compareExchange(
expected: Value,
desired: Value
) -> (exchanged: Bool, original: Value) {
compareExchange(
expected: expected,
desired: desired,
ordering: .sequentiallyConsistent)
}
func weakCompareExchange(
expected: Value,
desired: Value
) -> (exchanged: Bool, original: Value) {
weakCompareExchange(
expected: expected,
desired: desired,
successOrdering: .sequentiallyConsistent,
failureOrdering: .sequentiallyConsistent)
}
}
extension UnsafeAtomic where Value: AtomicInteger {
func wrappingIncrement(by delta: Value = 1) {
wrappingIncrement(by: delta, ordering: .sequentiallyConsistent)
}
etc.
}UnsafeAtomic 类型改用别的命名
我们曾经考虑过将提案里的 unsafe atomic 引用类型命名为 UnsafePointerToAtomic 和 UnsafePointerToAtomicLazyReference,强调它们只是 unsafe pointer 的简单封装。
然而,实际使用了这些命名一段时间后,由于不合适所以我们不得不拒绝这个命名。这些新的泛型类型显然不是指针 —— 它们只是在内部实现里使用了指针。
把这些类型想象成对应的 non-copiable 结构的 unsafe 先行版本会更恰当,让我们可以在语言支持 non-copiable 类型之前就定义并且开始使用这些功能。
我们期望这些使用 unsafe 先行版本的代码,在未来可以轻松地升级到 non-copiable 实现的版本。同时,因为它们是 Atomic 和 AtomicLazyReference 类型的 unsafe 版,在他们的命名前面直接加上 Unsafe 前缀也非常合理。
逻辑上来说,UnsafeAtomic 和 UnsafeAtomicLazyReference 都是引用类型,使用自治的存储形式,需要手动管理内存。它们共享的这套 API 建立起一个新的模式,可以在现有版本的 Swift 驱动低开销的同步结构:
struct UnsafeDemo {
typealias Value
struct Storage {
// Initialize a new storage instance by converting the given value.
// The conversion may involve side effects such as unbalanced retain/release
// operations; to ensure correct results, the resulting storage instance
// must be used to initialize exactly one memory location.
init(_ initialValue: __owned Value)
// Dispose of this storage instance, and return the last stored value.
// This undoes any side effects that happened when the value was stored.
// (For example, it may balance previous retain/release operations.)
//
// Note: this is different from deinitializing a memory location holding
// a Storage value.
@discardableResult
mutating func dispose() -> Value
}
// Initialize a new instance using the specified storage location.
// The caller code must have previously initialized the storage location.
//
// It is the caller's code responsibility to keep the storage location
// valid while accessing it through the resulting instance,
// and to correctly dispose of the storage value at the end of its useful life.
init(at address: UnsafeMutablePointer<Storage>)
// Return a new instance by allocating and initializing a dynamic variable
// dedicated to holding its storage. Must be paired with a call to `destroy()`.
static func create(initialValue: Value) -> Self
// Destroy an instance previously created by `Self.create(initialValue:)`,
// deinitializing and deallocating the dynamic variable that backs it,
// and returning the last value it held before destruction.
func destroy() -> Value
... // Custom operations
}未来的提案也许会遵循着同样的模式添加新的底层同步结构。non-copiable 类型的出现最终会让我们不再需要这种模式;不过如果我们需要这种灵活性的话,应该也会继续保留这些 unsafe 结构。
一个真正泛用的 Atomic 泛型类型
未来的提案也许会提供其它的 atomic 类型,但我们不认为以后会提供一个真正的泛型 Atomic 结构。Atomics 模块的设计是为了提供高性能,无等待的原语,这些会被 Swift 支持的 CPU 架构提供的 atomic 指令约束。
一个普适的,可以持有任何值的 Atomic 类型不可能基于无锁实现,所以它不在这个提案的范围内 —— 并且,它也不在 Atomics 模块的范围内。最终我们可能会考虑在未来的并发提案里加入这样一个结构:
@propertyWrapper
moveonly struct Serialized<Value> {
private let _lock = UnfairLock()
private var _value: Value
init(wrappedValue: Value) {
self._value = wrappedValue
}
var wrappedValue: Value {
get { _lock.locked { _value } }
modify {
_lock.lock()
defer { _lock.unlock() }
yield &_value
}
}
}提供一个 value 属性
我们的 atomic 结构并不常见,因为它们语义上像是持有某个值的容器,但实际上他们并不提供直接的访问。它们提供了笨拙的 load 和 store 函数,而不是给 value 属性提供 getter 和 setter。这个不一致有两个理由:
第一,直接提供一个带有 getter/setter 的属性最明显的问题就是无法指定 ordering 参数。
第二,property 语法有一个潜在的问题:它鼓励用户忽略竞态。例如下面的代码:
var counter = UnsafeAtomic<Int>.create(initialValue: 0)
...
counter.value += 1虽然这个自增操作看起来像是一个单独的 atomic 操作,但实际上它的执行会触发两个 atomic 事务:
var temp = counter.value // atomic load
temp += 1
counter.value = temp // atomic store如果其它线程刚好在 atomic load 之后更新了这个值,那么这个更新就会被后续的 store 给覆盖,导致数据丢失。
为了避免这个问题,提案里的 atomic 类型都不会提供这么一个属性去访问它们的值,并且可见的未来我们也不会考虑添加这么一个属性。
(注意,这个问题也没办法通过 modify accessors 的实现去解决。无锁更新不可能在不重试的情况实现,并且 modify 访问也只能 yield 一次)
Memory Orderings 的另一套设计方案
将 memory orderings 建模为类似于枚举的值,非常符合标准库现有的 API 设计,但 ordering 参数不是完美的。最重要的是,代码生成的质量取决于编译器的能力,看它是否能通过 constant-fold 将 ordering 值的 switch 语句压缩成一条指令。这会让逻辑变得脆弱 —— 特别是在无优化的 build 里。我们认为将这些参数约束为编译器可推导的常量在可读性和性能中间取得一个很好的平衡,但在一切尘埃落定之前也可以看看还有没有更好的选择。
将 ordering 编码到函数名里
一个显而易见的方法就是把 ordering 直接放到函数名里。这样实现起来就会很简单,但它也导致 API 变得不好用,例如下面 compare / exchange 的变种:
flag.sequentiallyConsistentButAcquiringAndReleasingOnFailureCompareExchange(
expected: 0,
desired: 1)我们可以使用更短的名字(例如 Serialized,Barrier 等),但核心问题是这种方式将太多信息塞到函数名里,很多相似但又不相同的函数最终会变成一团乱麻。
将 ordering 建模为泛型参数 第二个方案是把 ordering 建模成 atomic 类型的泛型参数:
struct UnsafeAtomic<Value: AtomicProtocol, Ordering: AtomicMemoryOrdering> {
...
}
let counter = UnsafeAtomic<Int, Relaxed>.create(initialValue: 0)
counter.wrappingIncrement()这样可以简化只使用同一个 “level” 的 ordering 的 atomic 值。然而,这就有很多缺点:
- 这个设计把 ordering 从 atomic 操作中剥离出来 —— 混淆了它的含义。
- 特定的操作想要指定 ordering 变得很困难(就像前面 Atomic 操作 小节里提到的 wrappingIncrement 的例子)。
- 我们没办法给泛型参数提供默认值。
- 最后,没有特化过的泛型可能会影响运行时性能。
Ordering Views
最有潜力的替代方案是将 memory ordering 建模成类似于 String 的 encoding view 那样:
var counter = UnsafeAtomic<Int>.create(initialValue: 0)
counter.relaxed.increment()
let current = counter.acquiring.load()这个 “ordering view” 的方案有几个点我们很喜欢;
- 它不需要去 switch ordering,避免了所有 constant folding 相关的问题。
- 它让 memory ordering 看起来就应该成为编译时的参数。
- 语法优雅。
然而,我们最终还是决定不走这条路,因为这些原因:
- 可组合性。ordering view 对于 compareExchange 这种需要分别指定成功/失败的 ordering 的情况太过于笨重。ordering view 没办法很好的嵌套:
counter.acquiringAndReleasing.butAcquiringOnFailure.compareExchange(...)- API 会变得很多很杂。Ordering views 会让 API 指数级增长。在我们的原型实现里,引入 ordering views 让 atomics 的 API 增加了 3 倍;我们从 6 个结构体 53 个函数变成 27 个结构体 175 个函数。虽然使用协议和泛型可以缓解这个情况,但复杂度会增加。(例如,泛型 ordering views 又会因为未特化的泛型导致性能问题)
- API 增多不是最重要的考量,但公开函数确实会产生一些损耗(例如,标准库的体积,API 文档等等)
- 不直观的语法。虽然语法层面上看起来确实很诱人,但把 memory ordering 放到操作前面似乎有些本末倒置。虽然 memory ordering 很重要,但我认为大多数人都会把它们排在操作后面。
- 有限的复用。实现 ordering views 需要大量的模版代码,而不是直接复用。每一个新的 Atomic 类型都需要实现所有这些 ordering views,并且根据它的使用场景进行增删。