JavaScript 启动性能瓶颈分析与解决方案
在 Web 开发中,随着需求的增加与代码库的扩张,我们最终发布的 Web 页面也逐渐膨胀。不过这种膨胀远不止意味着占据更多的传输带宽,其还意味着用户浏览网页时可能更差劲的性能体验。浏览器在下载完某个页面依赖的脚本之后,其还需要经过语法分析、解释与运行这些步骤。而本文则会深入分析浏览器对于 JavaScript 的这些处理流程,挖掘出那些影响你应用启动时间的罪魁祸首,并且根据我个人的经验提出相对应的解决方案。回顾过去,我们还没有专门地考虑过如何去优化 JavaScript 解析/编译这些步骤;我们预想中的是解析器在发现 <script>标签后会瞬时完成解析操作,不过这很明显是痴人说梦。下图是对于 V8 引擎工作原理的概述:
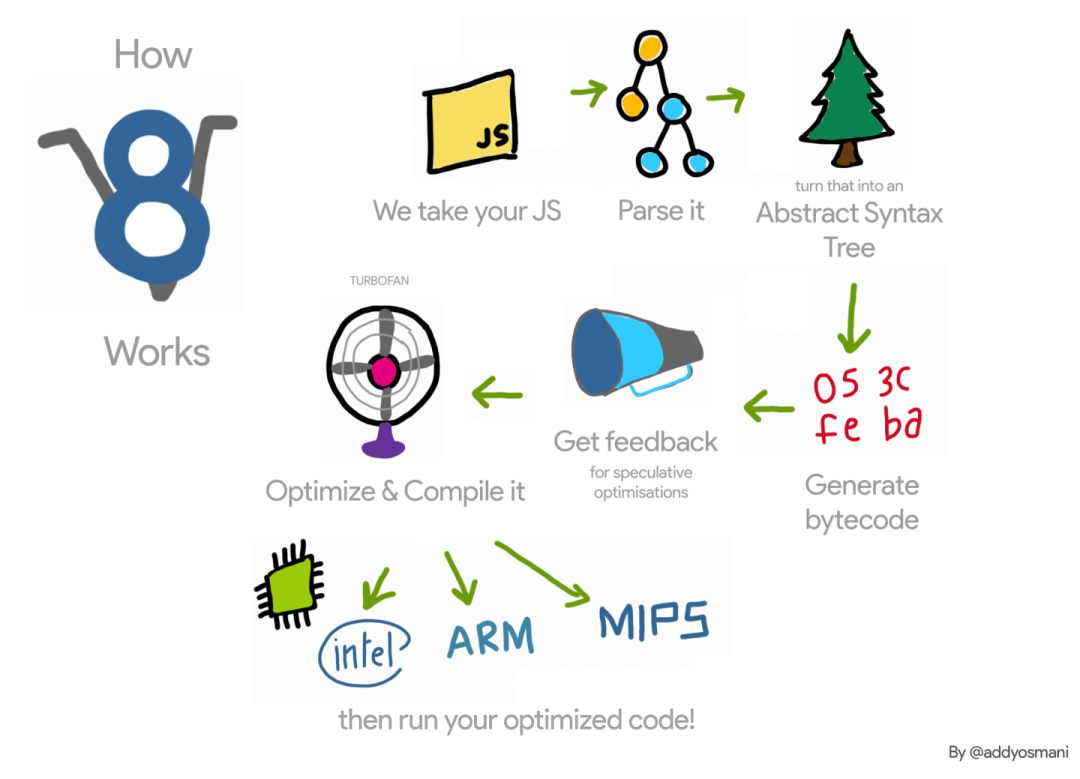
下面我们深入其中的关键步骤进行分析。
到底是什么拖慢了我们应用的启动时间?
在启动阶段,语法分析,编译与脚本执行占据了 JavaScript 引擎运行的绝大部分时间。换言之,这些过程造成的延迟会真实地反应到用户可交互时延上;譬如用户已经看到了某个按钮,但是要好几秒之后才能真正地去点击操作,这一点会大大影响用户体验。
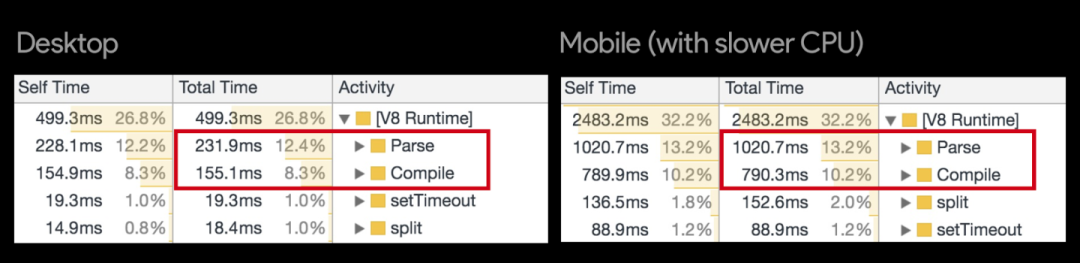
上图是我们使用 Chrome Canary 内置的 V8 RunTime Call Stats 对于某个网站的分析结果;需要注意的是桌面浏览器中语法解析与编译占用的时间还是蛮长的,而在移动端中占用的时间则更长。实际上,对于 Facebook, Wikipedia, Reddit 这些大型网站中语法解析与编译所占的时间也不容忽视:
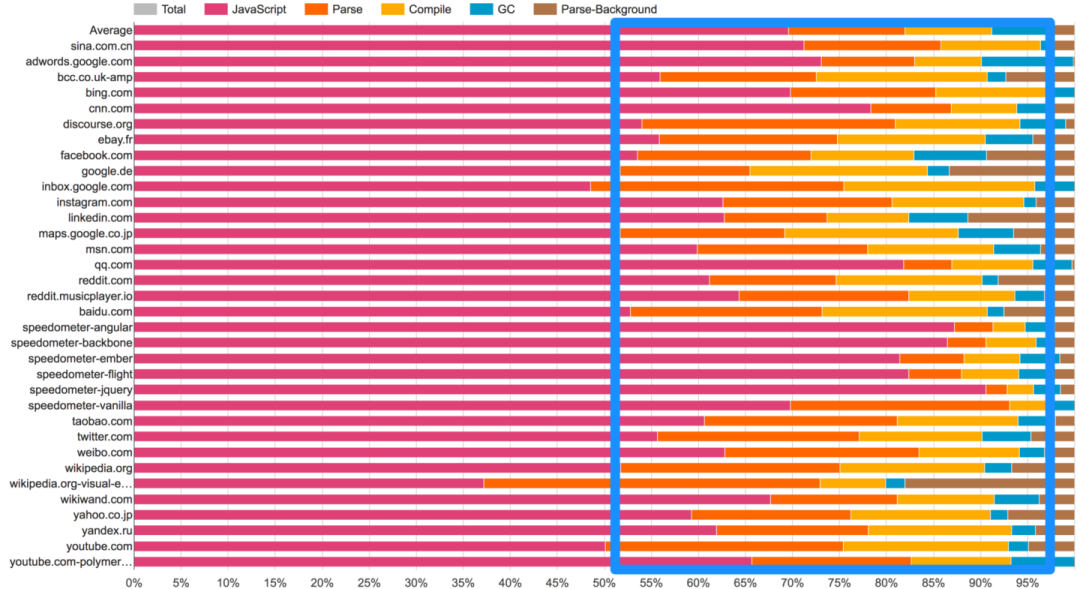
上图中的粉色区域表示花费在 V8 与 Blink's C++ 中的时间,而橙色和黄色分别表示语法解析与编译的时间占比。Facebook 的 Sebastian Markbage 与 Google 的 Rob Wormald 也都在 Twitter 发文表示过 JavaScript 的语法解析时间过长已经成为了不可忽视的问题,后者还表示这也是 Angular 启动时主要的消耗之一。
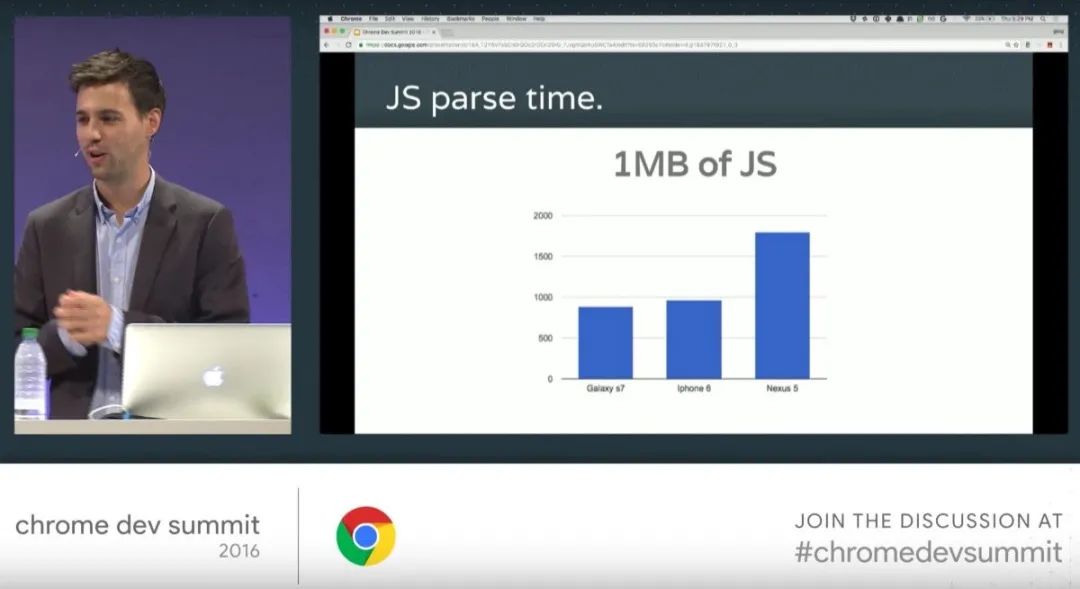
随着移动端浪潮的涌来,我们不得不面对一个残酷的事实:移动端对于相同包体的解析与编译过程要花费相当于桌面浏览器2~5倍的时间。当然,对于高配的 iPhone 或者 Pixel 这样的手机相较于 Moto G4 这样的中配手机表现会好很多;这一点提醒我们在测试的时候不能仅用身边那些高配的手机,而应该中高低配兼顾:

上图是部分桌面浏览器与移动端浏览器对于 1MB 的 JavaScript 包体进行解析的时间对比,显而易见的可以发现不同配置的移动端手机之间的巨大差异。当我们应用包体已经非常巨大的时候,使用一些现代的打包技巧,譬如代码分割,TreeShaking,Service Workder 缓存等等会对启动时间有很大的影响。另一个角度来看,即使是小模块,你代码写的很糟或者使用了很糟的依赖库都会导致你的主线程花费大量的时间在编译或者冗余的函数调用中。我们必须要清醒地认识到全面评测以挖掘出真正性能瓶颈的重要性。
JavaScript 语法解析与编译是否成为了大部分网站的瓶颈?
我曾不止一次听到有人说,我又不是 Facebook,你说的 JavaScript 语法解析与编译到
底会对其他网站造成什么样的影响呢?对于这个问题我也很好奇,于是我花费了两个月的时间对于超过 6000 个网站进行分析;这些网站囊括了 React,Angular,Ember,Vue 这些流行的框架或者库。大部分的测试是基于 WebPageTest 进行的,因此你可以很方便地重现这些测试结果。光纤接入的桌面浏览器大概需要 8 秒的时间才能允许用户交互,而 3G 环境下的 Moto G4 大概需要 16 秒 才能允许用户交互。
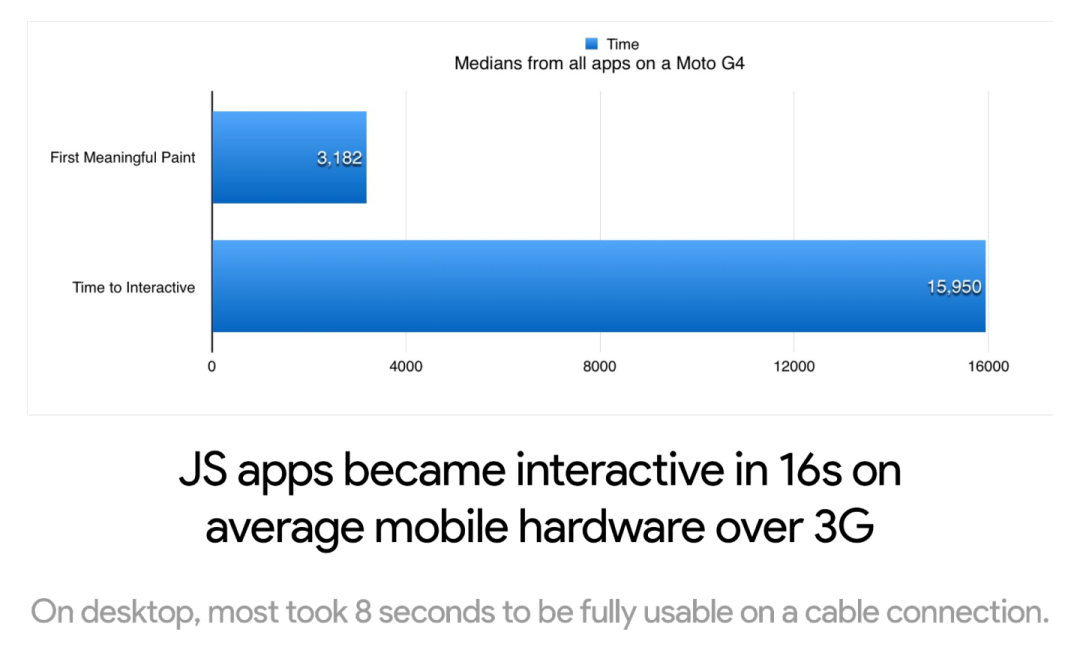
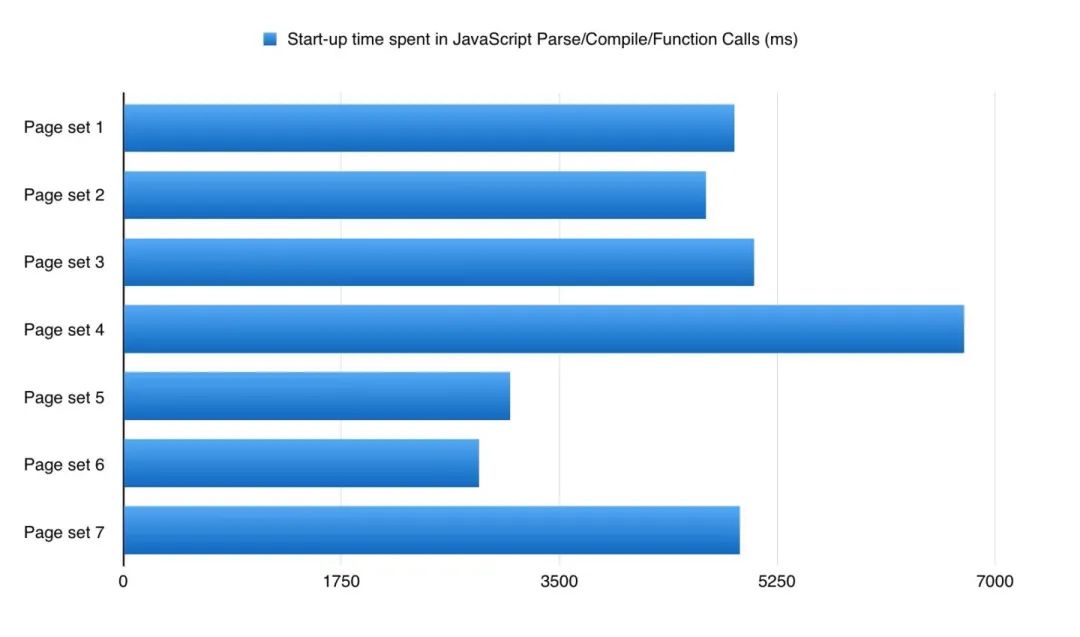
大部分应用在桌面浏览器中会耗费约 4 秒的时间进行 JavaScript 启动阶段(语法解析、编译、执行):
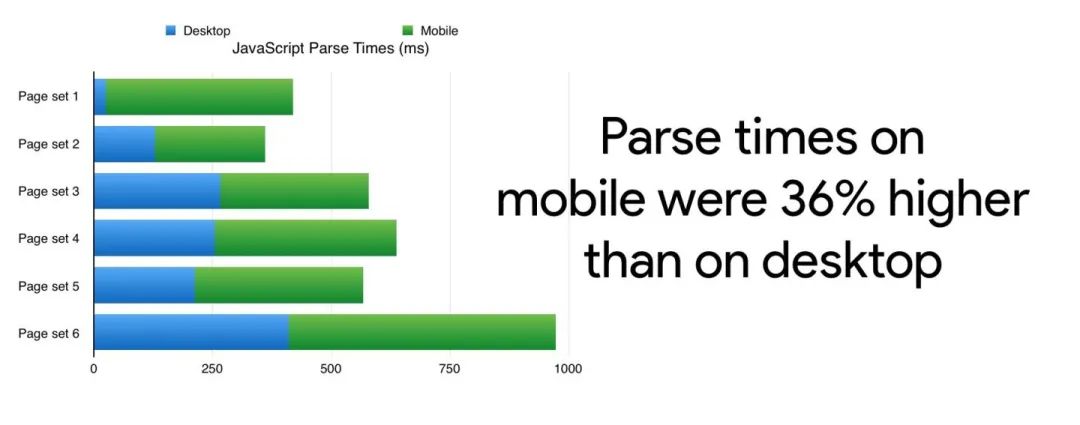
而在移动端浏览器中,大概要花费额外 36% 的时间来进行语法解析:
另外,统计显示并不是所有的网站都甩给用户一个庞大的 JS 包体,用户下载的经过 Gzip 压缩的平均包体大小是 410KB,这一点与 HTTPArchive 之前发布的 420KB 的数据基本一致。不过最差劲的网站则是直接甩了 10MB 的脚本给用户,简直可怕。
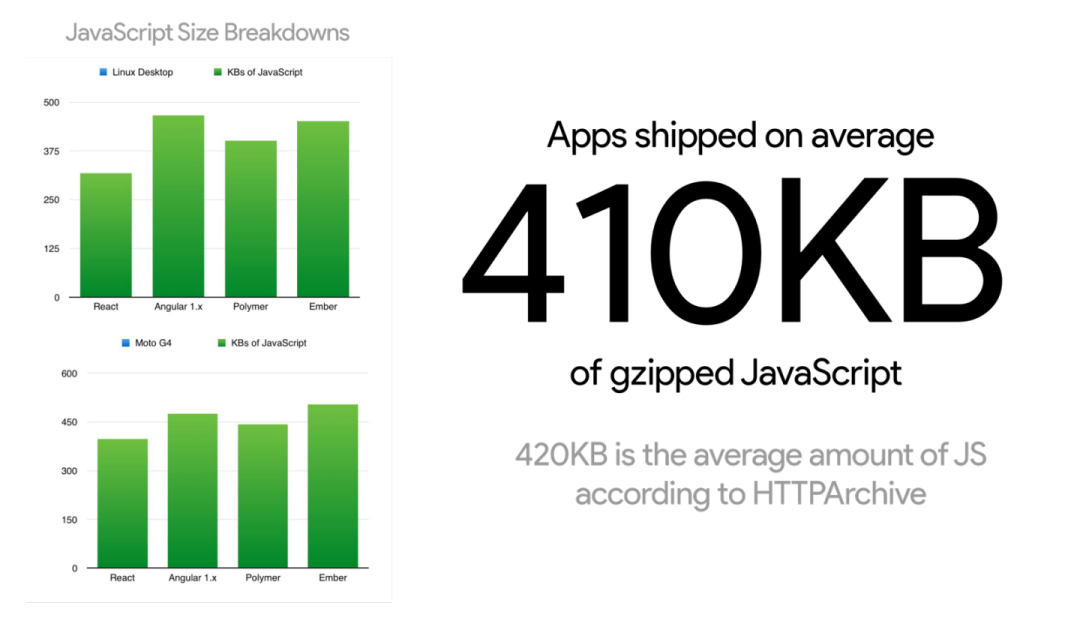
通过上面的统计我们可以发现,包体体积固然重要,但是其并非唯一因素,语法解析与编译的耗时也不一定随着包体体积的增长而线性增长。总体而言小的 JavaScript 包体是会加载地更快(忽略浏览器、设备与网络连接的差异),但是同样 200KB 的大小,不同开发者的包体在语法解析、编译上的时间却是天差地别,不可同日而语。
现代 JavaScript 语法解析 & 编译性能评测
Chrome DevTools
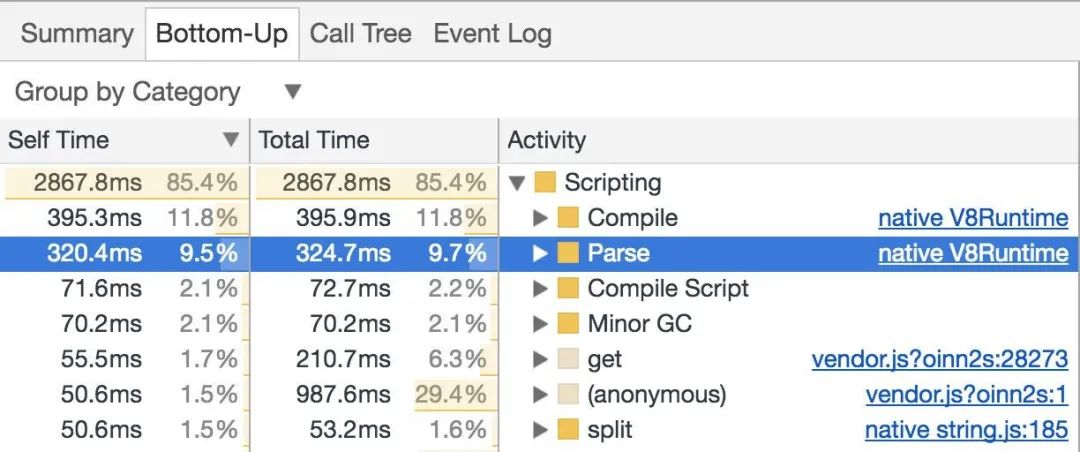
打开 Timeline( Performance panel ) > Bottom-Up/Call Tree/Event Log 就会显示出当前网站在语法解析/编译上的时间占比。如果你希望得到更完整的信息,那么可以打开 V8 的 Runtime Call Stats。在 Canary 中,其位于 Timeline 的 Experims > V8 Runtime Call Stats 下。
Chrome Tracing
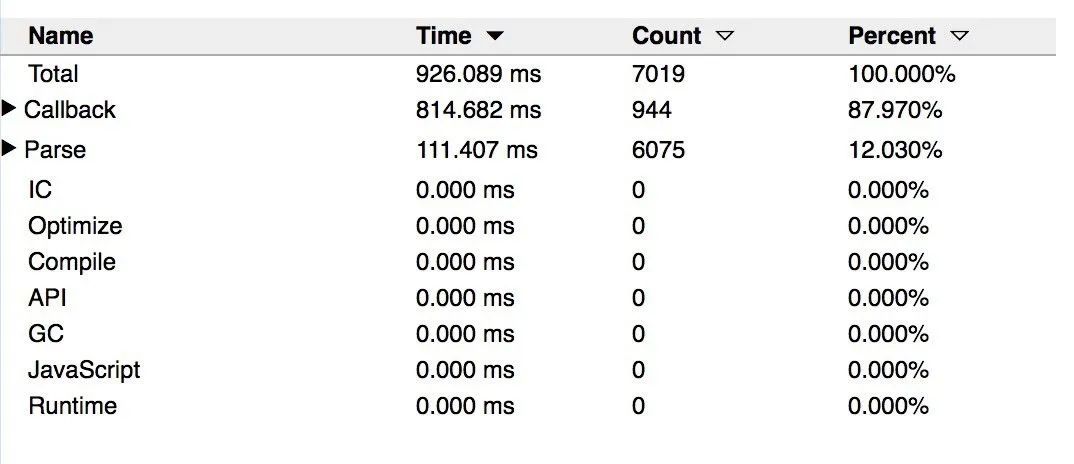
打开 about:tracing 页面,Chrome 提供的底层的追踪工具允许我们使用disabled-by-default-v8.runtime_stats来深度了解 V8 的时间消耗情况。V8 也提供了详细的指南来介绍如何使用这个功能。
WebPageTest
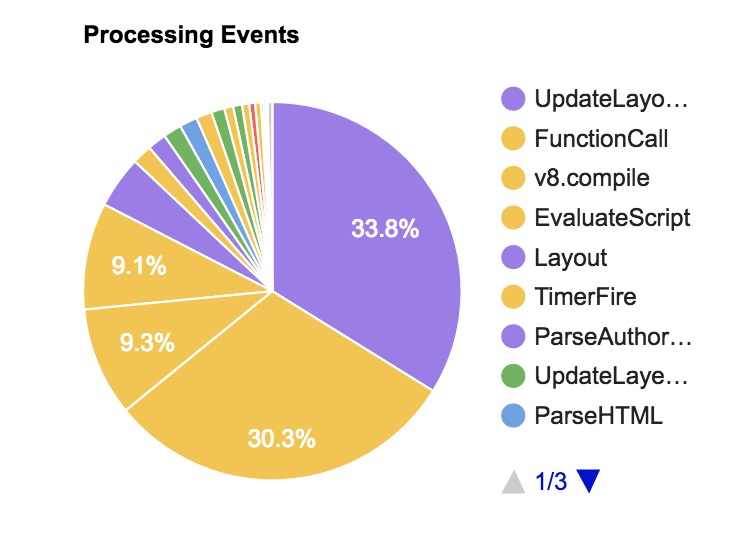
WebPageTest 中 Processing Breakdown 页面在我们启用 Chrome > Capture Dev Tools Timeline 时会自动记录 V8 编译、EvaluateScript 以及 FunctionCall 的时间。我们同样可以通过指明disabled-by-default-v8.runtime_stats的方式来启用 Runtime Call Stats。

更多使用说明参考我的gist。
User Timing
我们还可以使用 Nolan Lawson 推荐的User Timing API来评估语法解析的时间。不过这种方式可能会受 V8 预解析过程的影响,我们可以借鉴 Nolan 在 optimize-js 评测中的方式,在脚本的尾部添加随机字符串来解决这个问题。我基于 Google Analytics 使用相似的方式来评估真实用户与设备访问网站时候的解析时间:
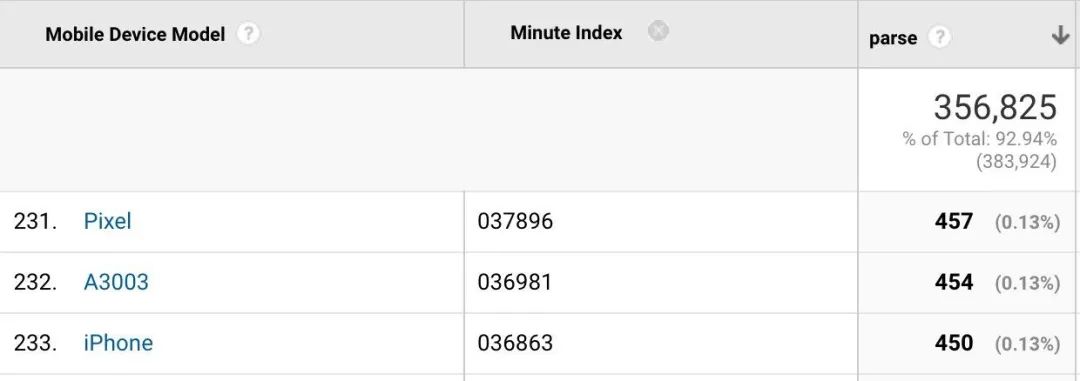
DeviceTiming
Etsy 的 DeviceTiming 工具能够模拟某些受限环境来评估页面的语法解析与执行时间。其将本地脚本包裹在了某个仪表工具代码内从而使我们的页面能够模拟从不同的设备中访问。可以阅读 Daniel Espeset 的Benchmarking JS Parsing and Execution on Mobile Devices 一文来了解更详细的使用方式。

我们可以做些什么以降低 JavaScript 的解析时间?
减少 JavaScript 包体体积。我们在上文中也提及,更小的包体往往意味着更少的解析工作量,也就能降低浏览器在解析与编译阶段的时间消耗。
使用代码分割工具来按需传递代码与懒加载剩余模块。这可能是最佳的方式了,类似于PRPL这样的模式鼓励基于路由的分组,目前被 Flipkart, Housing.com 与 Twitter 广泛使用。
Script streaming: 过去 V8 鼓励开发者使用async/defer来基于script streaming实现 10-20% 的性能提升。这个技术会允许 HTML 解析器将相应的脚本加载任务分配给专门的 script streaming 线程,从而避免阻塞文档解析。V8 推荐尽早加载较大的模块,毕竟我们只有一个 streamer 线程。
评估我们依赖的解析消耗。我们应该尽可能地选择具有相同功能但是加载地更快的依赖,譬如使用 Preact 或者 Inferno 来代替 React,二者相较于 React 体积更小具有更少的语法解析与编译时间。Paul Lewis 在最近的一篇文章中也讨论了框架启动的代价,与 Sebastian Markbage 的说法不谋而合:最好地评测某个框架启动消耗的方式就是先渲染一个界面,然后删除,最后进行重新渲染。第一次渲染的过程会包含了分析与编译,通过对比就能发现该框架的启动消耗。
如果你的 JavaScript 框架支持 AOT(ahead-of-time)编译模式,那么能够有效地减少解析与编译的时间。Angular 应用就受益于这种模式:

现代浏览器是如何提高解析与编译速度的?
不用灰心,你并不是唯一纠结于如何提升启动时间的人,我们 V8 团队也一直在努力。我们发现之前的某个评测工具 Octane 是个不错的对于真实场景的模拟,它在微型框架与冷启动方面很符合真实的用户习惯。而基于这些工具,V8 团队在过去的工作中也实现了大约 25% 的启动性能提升:
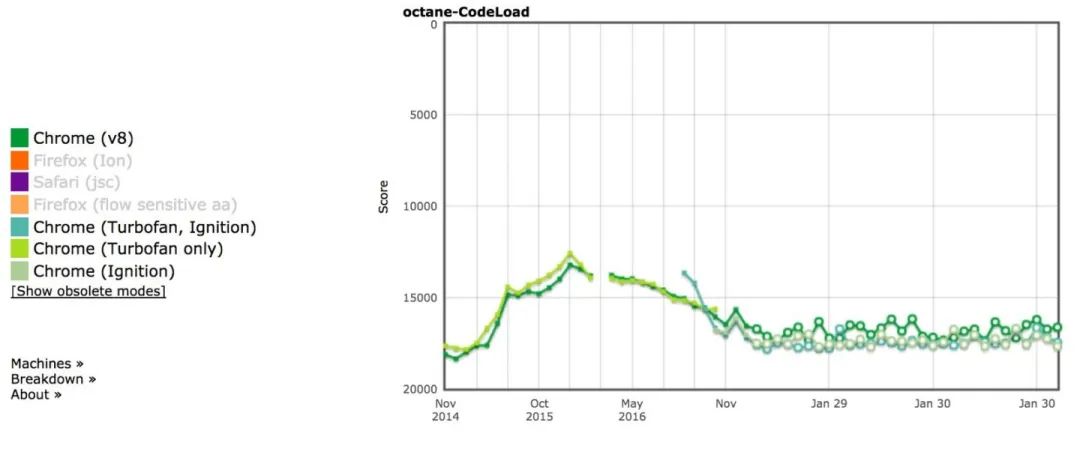
本部分我们就会对过去几年中我们使用的提升语法解析与编译时间的技巧进行阐述。
代码缓存
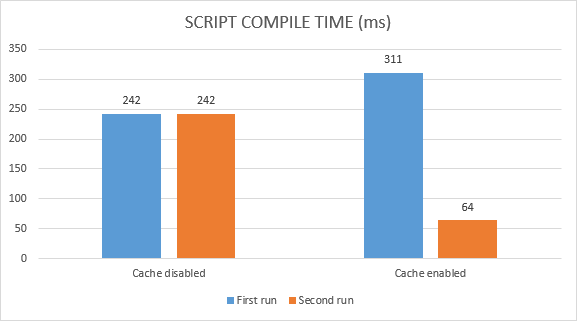
Chrome 42 开始引入了所谓的代码缓存的概念,为我们提供了一种存放编译后的代码副本的机制,从而当用户二次访问该页面时可以避免脚本抓取、解析与编译这些步骤。除以之外,我们还发现在重复访问的时候这种机制还能避免 40% 左右的编译时间,这里我会深入介绍一些内容:
- 代码缓存会对于那些在 72 小时之内重复执行的脚本起作用。
- 对于 Service Worker 中的脚本,代码缓存同样对 72 小时之内的脚本起作用。
- 对于利用 Service Worker 缓存在 Cache Storage 中的脚本,代码缓存能在脚本首次执行的时候起作用。
总而言之,对于主动缓存的 JavaScript 代码,最多在第三次调用的时候其能够跳过语法分析与编译的步骤。我们可以通过chrome://flags/#v8-cache-strategies-for-cache-storage来查看其中的差异,也可以设置 js-flags=profile-deserialization运行 Chrome 来查看代码是否加载自代码缓存。不过需要注意的是,代码缓存机制仅会缓存那些经过编译的代码,主要是指那些顶层的往往用于设置全局变量的代码。而对于类似于函数定义这样懒编译的代码并不会被缓存,不过 IIFE 同样被包含在了 V8 中,因此这些函数也是可以被缓存的。
Script Streaming
Script Streaming允许在后台线程中对异步脚本执行解析操作,可以对于页面加载时间有大概 10% 的提升。上文也提到过,这个机制同样会对同步脚本起作用。
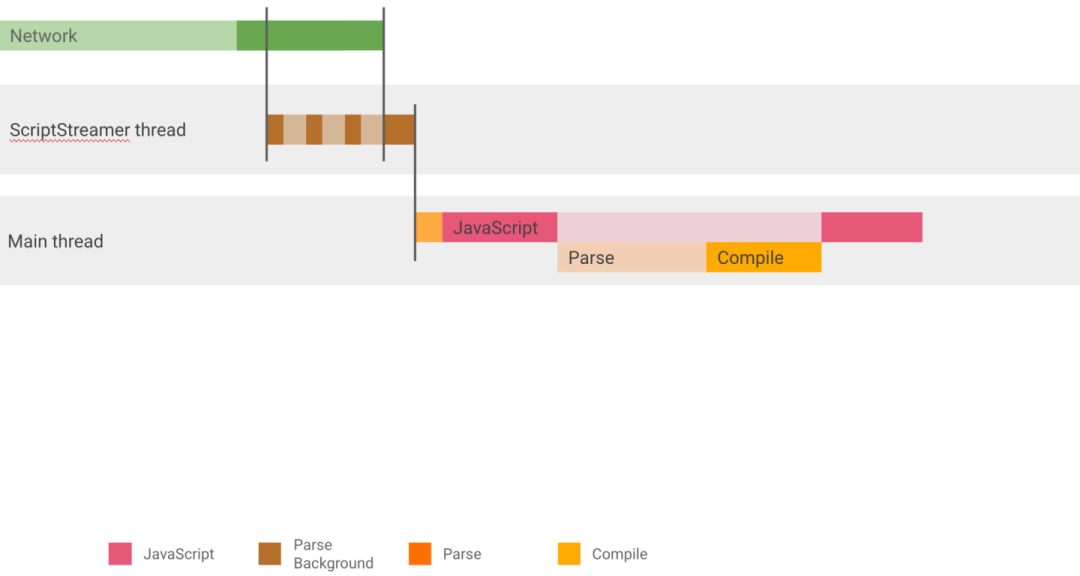
这个特性倒是第一次提及,因此 V8 会允许所有的脚本,即使阻塞型的 <scriptsrc=''>脚本也可以由后台线程进行解析。不过缺陷就是目前仅有一个 streaming 后台线程存在,因此我们建议首先解析大的、关键性的脚本。在实践中,我们建议将 <scriptdefer>添加到 <head>块内,这样浏览器引擎就能够尽早地发现需要解析的脚本,然后将其分配给后台线程进行处理。我们也可以查看 DevTools Timeline 来确定脚本是否被后台解析,特别是当你存在某个关键性脚本需要解析的时候,更需要确定该脚本是由 streaming 线程解析的。

语法解析 & 编译优化
我们同样致力于打造更轻量级、更快的解析器,目前 V8 主线程中最大的瓶颈在于所谓的非线性解析消耗。譬如我们有如下的代码片:
(function(global, module) { … })(this, functionmodule() { my functions })V8 并不知道我们编译主脚本的时候是否需要module这个模块,因此我们会暂时放弃编译它。而当我们打算编译module时,我们需要重分析所有的内部函数。这也就是所谓的 V8 解析时间非线性的原因,任何一个处于 N 层深度的函数都有可能被重新分析 N 次。V8 已经能够在首次编译的时候搜集所有内部函数的信息,因此在未来的编译过程中 V8 会忽略所有的内部函数。对于上面这种module形式的函数会是很大的性能提升,建议阅读The V8 Parser(s) — Design, Challenges, and Parsing JavaScript Better来获取更多内容。V8 同样在寻找合适的分流机制以保证启动时能在后台线程中执行 JavaScript 编译过程。
预编译 JavaScript?
每隔几年就有人提出引擎应该提供一些处理预编译脚本的机制,换言之,开发者可以使用构建工具或者其他服务端工具将脚本转化为字节码,然后浏览器直接运行这些字节码即可。从我个人观点来看,直接传送字节码意味着更大的包体,势必会增加加载时间;并且我们需要去对代码进行签名以保证能够安全运行。目前我们对于 V8 的定位是尽可能地避免上文所说的内部重分析以提高启动时间,而预编译则会带来额外的风险。不过我们欢迎大家一起来讨论这个问题,虽然 V8 目前专注于提升编译效率以及推广利用 Service Worker 缓存脚本代码来提升启动效率。我们在 BlinkOn7 上与 Facebook 以及 Akamai 也讨论过预编译相关内容。
Optimize JS 优化
类似于 V8 这样的 JavaScript 引擎在进行完整的解析之前会对脚本中的大部分函数进行预解析,这主要是考虑到大部分页面中包含的 JavaScript 函数并不会立刻被执行。
预编译能够通过只处理那些浏览器运行所需要的最小函数集合来提升启动时间,不过这种机制在 IIFE 面前却反而降低了效率。尽管引擎希望避免对这些函数进行预处理,但是远不如optimize-js这样的库有作用。optimize-js 会在引擎之前对于脚本进行处理,对于那些立即执行的函数插入圆括号从而保证更快速地执行。这种预处理对于 Browserify, Webpack 生成包体这样包含了大量即刻执行的小模块起到了非常不错的优化效果。尽管这种小技巧并非 V8 所希望使用的,但是在当前阶段不得不引入相应的优化机制。
总结
启动阶段的性能至关重要,缓慢的解析、编译与执行时间可能成为你网页性能的瓶颈所在。我们应该评估页面在这个阶段的时间占比并且选择合适的方式来优化。我们也会继续致力于提升 V8 的启动性能,尽我所能!