史上最贵“删库跑路”新进展:微盟七天七夜找回删库数据,决定赔付商家1.5亿,痛定思痛全面上云
“七天七夜,微盟被删除的数据全面找回!”
3月1日晚间,微盟发布公告,称在合作方腾讯云的协助下,数据已经全面找回,预计于2020年3月3日上午9点完成数据恢复上线。
腾讯云官方微博也发布消息,表示数据恢复的复杂度超出所有人想象,“连续通宵、排除万难,终于攻坚成功!”

不过,数据虽然恢复了,损失依旧惨烈。
事故发生在2月23日晚上,微盟公司的SaaS业务突然崩溃,基于微盟的商家小程序都处于宕机状态,300万家商户生意基本停摆。
而造成此次严重事故的,竟然是微盟的一名员工——凭一己之力,删除自家公司数据库,累计市值蒸发超30亿港元。
针对事故给商家造成的影响,微盟表示:
管理层深感自责和愧疚,准备了1.5亿元人民币赔付拨备金,其中公司承担1亿元,管理层承担5000万元。
经过这样“段子”一样的事件,也给企业敲响了一个警钟——“数据安全大于天”。
赔付1.5亿元,决定全面云上
今天,微盟在其官方网站上发布了自愿公告《SaaS业务生产环境和数据恢复》,描述此次事故及修复过程,以及赔付方案和数据安全保障计划。

本次事故及修复过程
2020年2月23日,因本公司员工故意破坏本公司 SaaS 业务生产环境及数据,导致本公司暂时无法向客户提供 SaaS 产品,目前该员工已被上海市公安局宝山分局刑事拘留。
2020年2月25日,本公司恢复了核心 SaaS 业务的生产环境,SaaS 业务新用户可继续使用本公司的 SaaS 产品,本公司也向老用户提供临时过渡方案,确保商家在数据恢复前可继续经营。
2020年2月28日,本公司恢复了所有 SaaS 业务的生产环境,并且开放了老用户登录,以及恢复了微站产品的所有备份数据。
截至2020年3月1日晚 8 点,在腾讯云的协助下,本公司备份的数据已经找回。由于此次数据量规模庞大,为了保证数据一致性和线上体验,本公司将于2020年3月2日凌晨2点至上午8点,进行数据恢复上线演练,在此期间本公司的系统将会暂停服务,演练完成后系统数据会回滚到 2020年3月2日的数据。
本公司将于2020年3月2晚上10点至2020年3月3日上午 9 点,正式进行数据恢复上线。本公司将恢复2020年2月23日及之前的数据,同时将2020年2月23日与2020年3月2日的数据进行合併,届时数据恢复将完成。
针对本次事故的赔付方案
鉴于本次事故给本公司的SaaS业务商家经营造成了不利影响及损失,本公司管理层在紧抓资料恢复的同时,也同步研究了商家赔付方案。
针对本次事故可能带来的潜在现金赔付和流量赔付,本公司和本公司管理层合计准备了人民币 1.5 亿元的赔付资金,其中人民币 1 亿元由本公司承担,人民币 5,000 万元由本公司管理层承担,具体进行赔付时本公司和上述本公司管理层将在上述披露的限额内将按比例做出支付。
数据安全计划
本次事故虽由员工的不当行为引起,但也暴露出本公司在数据安全管理方面的不足之处。
为此,本公司已邀请外部数据安全专家协助本公司制定和评估数据安全保障计划,主要覆盖生产环境和数据权限的分级管理和执行、将数据移转到腾讯云数据库、加强意外事件快速应对能力以及运维人员的法律和职业道德学习等方面。
本公司正在逐步落实上述数据安全保障措施,以避免此类事故的再次发生。
七天七夜,为何恢复数据如此漫长?
其实,我们也经历过许多常用软件崩溃的情况,例如去年12月5日,支付宝网络出现抖动,12月26日微信公众号崩溃,但是腾讯和阿里的恢复时间还是比较迅速,分别只用了25分钟和45分钟。
而微盟此次数据库被删,在腾讯云的协作下,为何还要耗时7天7夜之久?
对此,业界知名实战派软件质量和研发工程效能专家茹炳晟,发表了一些看法,主要原因归结于技术过于复杂。
首先需要了解的是数据库的运行环境,简化来讲,主要包括三种:“不上云”、“全上云”和“假上云”。

“不上云”是指建立在自己的数据中心,完全自己管理硬件、软件和数据,这是云平台普及以前的主流实践。
“全上云”是指完全建立在云端环境之上。这里的云可以是公有云,也可以是私有云。
“假上云”是把云方案当做虚拟机来使用。这种方式和上面的“不上云”很类似,完全没有用好云端的优势,只是把数据中心的机器移到了云端而已。
对于上面三种方式,“不上云”和“假上云”对于数据的风险相比“全上云”会更大。
运维人员在“不上云”和“假上云”的情况下更容易有机会去执行类似“rm -rf /*”和“fdisk”类型的极端操作。
而“全上云”,就比较难有机会从操作系统层面执行此类命令,数据库数据也就不会被rm -rf /给删掉。
同样,面对数据的误操作问题,“全上云”也比“不上云”和“假上云”有明显的优势。
从之前腾讯云对外的回应中,可以大概看到微盟被删的数据不在腾讯云上,再结合目前数据恢复的速度来看,几乎可以判定很大概率微盟没有采用“全上云”的架构,或者是只有部分数据在云端。
要在这种情况下恢复全部数据,可想而知技术难度是很大的。
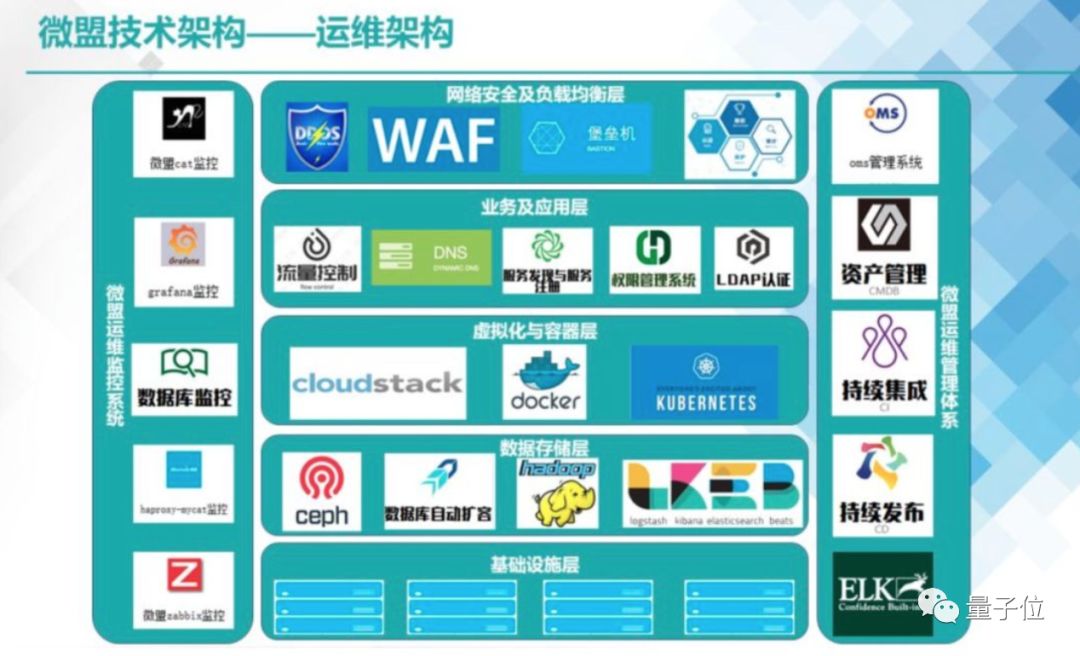
△图源:微盟技术中心
根据茹炳晟的理解,至少要跨过下面这些技术的槛:
⑴获取全量备份,如果存在异地的冷备或者灾备,那是比较理想的情况,但是由于全量备份通常非常庞大,所以需要较长的时间完成文件的传输和校验。
⑵获取增量备份,很多时候增量备份没有来得及做异地容灾备份,所以很大概率要从磁盘恢复,这又是大量的时间消耗,而且同样不能保证100%完全恢复。
⑶获取binlog,binlog是记录所有数据库表结构变更(例如CREATE、ALTER TABLE等)以及表数据修改(INSERT、UPDATE、DELETT等)的二进制日志文件。文件尺寸不小,而且个数也很多。
有了上面这些作为基本的输入,才能开始数据库层面的数据导入和恢复工作,这个过程也需要花费大量的时间,而且这是基于上述文件都可以100%得到为前提的。
数据库的数据文件和备份文件往往很大,那么只要有个别数据区出现了重写,那么恢复出来的文件就是不完整的,这个时候就需要人为介入来进行修正,这个工作量以及技术难度就会很大,有时还会需要借助专用的仪器设备。
除此之外,像微盟如此庞大的系统,各个垂直事业部可能都有各自的业务数据库,这些数据库甚至可能采用了不同的方案,这种架构上的异构性也会给恢复过程带来极大的挑战。
另外,即使部分数据恢复完成之后,也不能立即上线,而要等其他相关数据恢复,并且做好数据的交叉校验,确保数据万无一失,这些都需要大量的时间。
联想云领数据安全实验室负责人赵榛也认为,数据量规模过大,是数据恢复实施难点之一。
由于技术方案相对成熟,人工效率不是瓶颈,通过计算硬盘I/O速度,可以大致评估出整个恢复过程的时效。但是数据量规模过大会导致容错率降低,每一次人为原因或设备原因导致的错误都会增加很多额外的恢复时间。
同时数据量规模过大还会导致恢复所需资源的增加,对整个恢复的成本造成很大的影响。
数据安全大于天
经此一役,也让我们认识到了数据安全的重要性,如何预防这种数据丢失的情况,也开始被更多人讨论。
有一些过来人高赞建议:
公众号“成哥的世界”建议,企业可以使用云数据库产品,因为公有云厂商具有相对比较完善的自动备份和恢复机制,没有机会被删库;做好备份,做好全量备份、增量备份、延迟备份,而且要多机房异地备份;管理好控制权限,用主机安全管控软件或者堡垒机来拦截高危命令;进行普法宣传,给予警示告诫,防止相关人员想不开。
而知乎用户“空白白白白”则建议,企业应当建立敏感数据操作双人复核机制,需要双人审批;用异地灾备或异步通讯的方式做数据实时备份;建立关键应用业务的删库监控机制,做重要操作的时候需要确认。
而从茹炳晟对此次数据恢复技术难点的分析中,也可以看出“全上云”具有相对的安全性。
但同时,也有读者留言反馈道:
作为云管理者,全上云的数据还是能删光的。任何云都有初始化手段,全上云就是把安全交给别人。

那么问题来了,对于“全上云” or “Not 全上云”,你怎么看?
传送门
- 微盟官方公告:http://group.weimob.com/pages/relation
- 参考链接:https://tech.sina.com.cn/i/2020-03-01/doc-iimxxstf5622524.shtml
十三 发自 凹非寺 量子位 报道 | 公众号 QbitAI