一个基于汇编的中心重定向框架
前言
最近看到了一个有趣的项目:TrampolineHook,一个中心重定向框架,简单来讲可以用于拦截指定函数,在函数被调用时,收到一个回调通知。这个项目没有使用常用的方法交换方案,而是选择汇编实现。非常 amazing 啊,让我对其实现的原理感到好奇。边学习相关知识,边阅读源码,有了初步的理解。
才疏学浅,有误内容还请多多指正。
TrampolineHook 使用说明
了解原理前,先了解 TrampolineHook 具体做了啥。
定义一个回调函数:
void myInterceptor() {
printf("调用了 myInterceptor\n");
}
使用 TrampolineHook 替换 -[UIView initWithFrame] 的实现:
THInterceptor *interceptor = [THInterceptor sharedInterceptorWithFunction:(IMP)myInterceptor];
Method m = class_getInstanceMethod([UIView class], @selector(initWithFrame:));
IMP imp = method_getImplementation(m);
THInterceptorResult *interceptorResult = [interceptor interceptFunction:imp];
if (interceptorResult.state == THInterceptStateSuccess) {
method_setImplementation(m, interceptorResult.replacedAddress); // 设置替换的地址
}
UIView *view = [[UIView alloc] initWithFrame:CGRectMake(0, 0, 200, 200)]; // 执行到这一行时,会调用 myInterceptor 方法
此时,每当调用 -[UIView initWithFrame],都会回调一次 myInterceptor。
必备知识回顾
先温习一下本文要用到内容,会让理解起来快速很多。
用到的 ARM64 汇编指令
ARM64 伪指令
.text
.text 用于声明以下是代码段。
.align
.align 用于将指令对齐到内存地址,对齐位置为参数的 2 的幂次方。
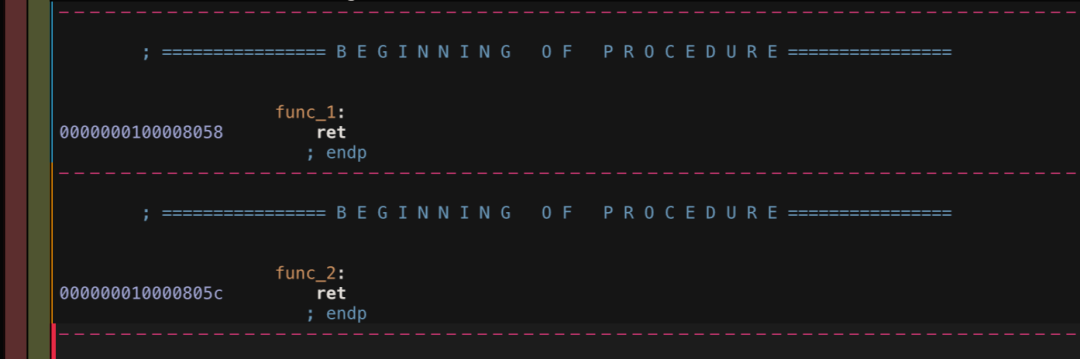
以 .align 10 举例,在没有添加对齐时:
func_1:
ret
func_2:
ret
得到的结果,两个指令构成了连续的地址:
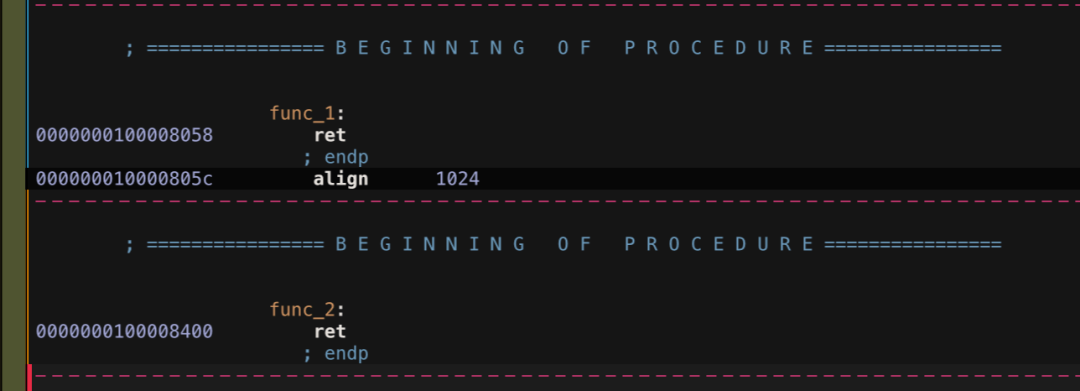
在 func_1 和 func_2 之间加入 .align 10:
func_1:
ret
.align 10
func_2:
ret
得到如下结果,如果 .align 只是个普通的指令,那 func_2 的 ret 对应地址应当为 0x0000000100008060,这里却变成了 0x000000010000840,0x000000010000840刚好是 210 的倍数。
在本文中,会有一个妙用点,我们在 func_1 也加入 .align 10:
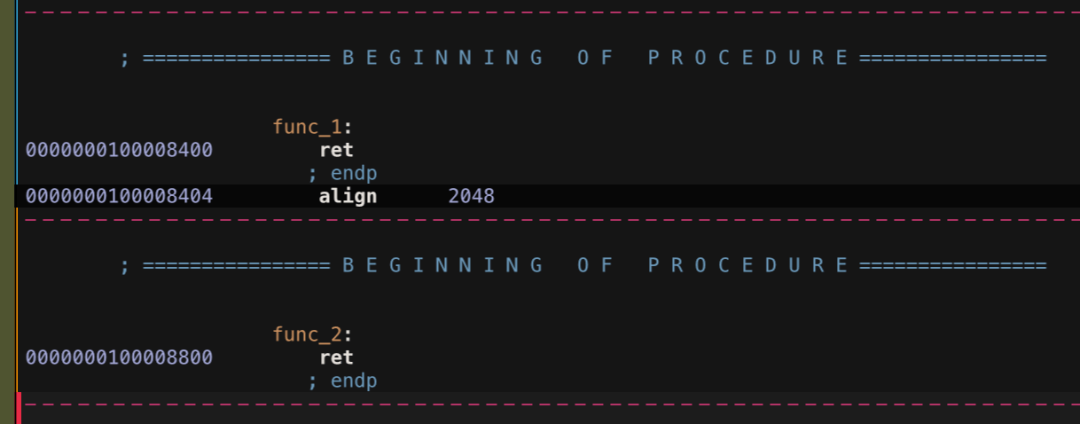
可以看到 0x8800 - 0x8400 = 0x400,0x400 刚好是 210,这说明我只要知道 func_2 的 ret 指令内存地址,就可以得到 func_1 的 ret 指令地址。
.rept 和 .endr
.rept 和 .endr 是一组循环伪指令。
func_1:
.rept 5
add x0, x0, x1
.endr
ret
上述指令得到内容如下:
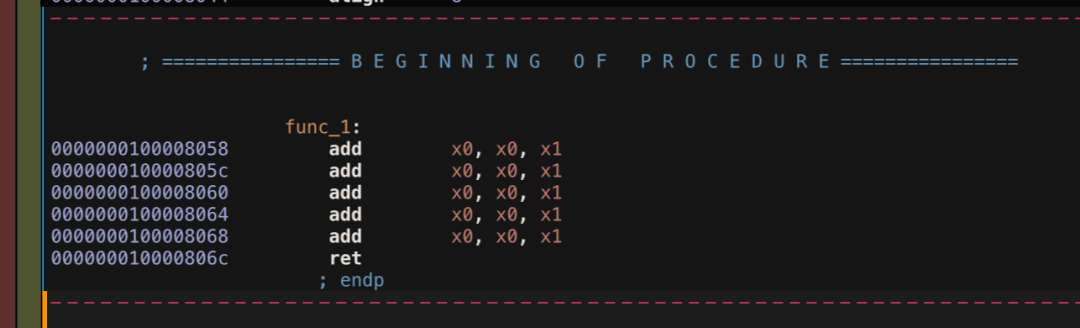
生成了 5 个连续的 add 指令。
标签
如下代码:
_my_label:
add x0, x0, x1
_my_label 会指向 add x0, x0, x1 的地址,用于辅助标记命令地址。
.globl
.globl 可以让一个标签对链接器可见,可以供其他链接对象模块使用。
换句话说 .global _my_func 可以在代码中调用到 my_func。
ARM64 指令
nop
什么也不做的指令,愣一下。没什么用途,但可以偏移指令地址。
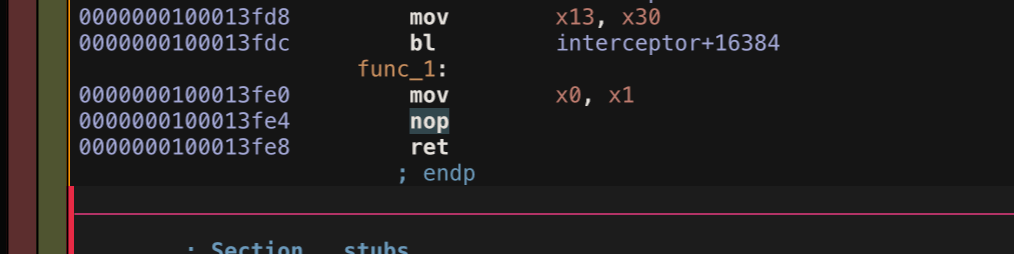
可以看到 nop 也占了 4 个字节,原本 0000000100013fe 对应的指令应当是 ret。
sub
减法指令,可以拿来做一些地址偏移计算,用法如下:
sub x1, x1, #0x8 ;相当于 x1 = x1 - 0x8
sub x2, x1, x2 ;相当于 x2 = x1 - x2
mov
赋值指令,用法如下:
mov x1, x0 ;相当于 x1 = x0
str 和 stp
两个入栈指令,stp 可以同时操作两个寄存器。
这里涉会及到一些寻址的格式,有 3 种方式:
[x10, #0x10] ;从 x10 + 0x10 的地址取值
[sp, #-16]! ;从 sp - 16 地址取值,取值完后在把 sp 向低地址移 -16 字节,即开辟一段新栈空间
[sp], #16 ;从 sp 地址取值,取值完后在把 sp 向高地址偏移 -16 字节,即释放一些栈空间
结合上面几种寻址方式,搭配入栈指令,用法如下:
str x8, [sp, #-16]! ;将 x8 存到 sp - 16 的位置,并将 sp -= 16
stp x4, x5, [sp, #-16]! ;将 x4 x5 的值存到 sp - 16 的位置,并将 sp -= 16
ldr 和 ldp
两个出栈指令,ldp 可以同时操作两个寄存器,用法如下:
ldr x8, [sp], #16 ;将 sp 位置的值取出来,存入 x8 中,并将 sp += 16
ldp x4, x5, [sp], #16 ;将 sp 位置的值取出来,存入 x4 x5 中,并将 sp += 16
br
跳转指令,直接跳转到指定地址,跳转完不返回。有些类似在一个函数末尾调用了另外的函数。用法如下:
br x10 ;跳转到 x10 中保存的地址
bl
跳转指令,将 bl 的下一个指令地址保存到 lr 寄存器,然后跳转到指定地址,因为将下一个指令保存到 lr 了,所以跳转完会回来执行下一个指令。用法如下:
mov x0, x1
bl 0x100221232 ;跳转到 0x100221232,执行完毕回来执行下一条指令
sub x0, x0, 0x10
blr
跳转指令,和 bl 类似,但可以使用动态地址,可以跳转到寄存器的值保存的地址,用法如下:
mov x8, 0x100221232
blr x8
ret
返回指令,子程序(函数调用)返回指令,返回到寄存器 lr 保存的地址。
函数、汇编、寄存器
汇编指令是对寄存器和栈进行各种操作,如何对应到我们日常编写的函数是关键。
寄存器相当于全局变量,在汇编中没有传入参数这样的形式,但我们可以用寄存器进行传递参数。为此,我们进行了一系列约定:
• x0 - x7:用于传递子程序参数和结果,使用时不需要保存,多余参数采用堆栈传递,子程序返回结果写入到 x0
• x8:用于保存子程序返回地址
• x9 - x15:临时寄存器
• x16 - x17:子程序内部调用寄存器
• x18:平台寄存器,它的使用与平台相关
• x19 - x28:临时寄存器
• x29:帧指针寄存器 fp(栈底指针),用于连接栈帧
• x30:链接寄存器 lr,保存了子程序返回的地址
• x31:堆栈指针寄存器 sp
连续调用多个子程序会面临寄存器不够用的问题,大家都要用 lr 作为返回地址,都要用 x0 传递参数。
栈来了!如果后面的操作会对寄存器有修改,先入栈保存起来,等执行完相关操作,在出栈读出来就好了。
比如 lr 是必须入栈的寄存器(当然你脾气硬,不怕其他寄存器被修改,保存到其他寄存器也可以,但一定别这样写,万一啥时候被修改了呢),如果没有保存 lr,调用子程序后,lr 不是当初的 lr 了,会找不到返回的位置。
如下汇编没有保存 lr:
add_func:
add x0, x0, x1
ret
.globl _my_add_func
_my_add_func: ;没有保存 lr,调用后回不去了
bl add_func
ret
调用后:
FOUNDATION_EXTERN int my_add_func(int x, int y);
printf("开始执行 my_add_func\n");
int result = my_add_func(1, 1);
printf("执行 my_add_func 结果: %d\n", result);
得到的输出:
开始执行 my_add_func
为 _my_add_func 增加个 lr 入栈就行了:
_my_add_func:
str lr, [sp, #-16]!
bl add_func
ldr lr, [sp], #16
ret
此时得到的输出为:
开始执行 my_add_func
执行 my_add_func 结果: 2
更复杂的调用场景,需要将更多的寄存器入栈,避免寄存器内容被污染。
有了这些内容,我们可以开始了解 TrampolineHook 的实现原理了。
实现原理分析
流程设计
根据作者博客内容的描述,TrampolineHook 设计了精心构造的两个连续页,在这两页中保存所有要保存的内容。
为了完成中心重定向,主要思路:
• 取出原方法的 IMP A,保存起来
• 替换原方法 IMP 为一个新地址 B
• 当执行到该方法时,会跳转到新地址 B
• 在 B 中做一些自定义的操作(比如打个日志)
• 获取原先的 A,跳转过去
在 3 - 5 步骤中,注意不能把寄存器、返回地址搞乱了。
替换 IMP 很简单:
Method m = class_getInstanceMethod([UIView class], @selector(initWithFrame:));
IMP imp = method_getImplementation(m);
IMP newImp = ...;
method_setImplementation(m, newImp);
重点在新地址 B 怎么来,后续的跳转如何跳转。这就需要了解精心构造的两个连续页的内容。
两页内存
将 TrampolineHook 中汇编代码稍微调整一下,_th_entry 中的内容是执行自定义操作并恢复现场,跳转回原地址,为了理解页结构,先移除 _th_entry 的内容。
.text
.globl _th_dynamic_page
.align 14
interceptor: .quad 0 ;interceptor 是标签,`.quad 0` 分配了 8 字节空间,用于保存自定义跳转函数 IMP
.align 14
_th_dynamic_page: ;th_dynamic_page 是标签,地址在这里第二页起始位置
_th_entry: ;调用 interceptor 和原 IMP 逻辑
...
.rept 2032 ;生成一堆可执行地址
mov x13, lr
bl _th_entry
.endr
我们知道 .align 会将地址对齐,.align 14 中 214 为 16KB,在 ARM64 中,这是一页内存的大小。从前面知识我们了解到,两个 .align 14 可以让两部分指令整整齐齐。
以上两个 .align 14 将指令分成两页,第一页只有一个 8 位的 interceptor 在起始地址,第二页起始地址部分为 _th_entry 逻辑,后面通过 .rept 2032 生成了一堆的 mov x13, lr 和 bl _th_entry 指令。
两页内容如图:
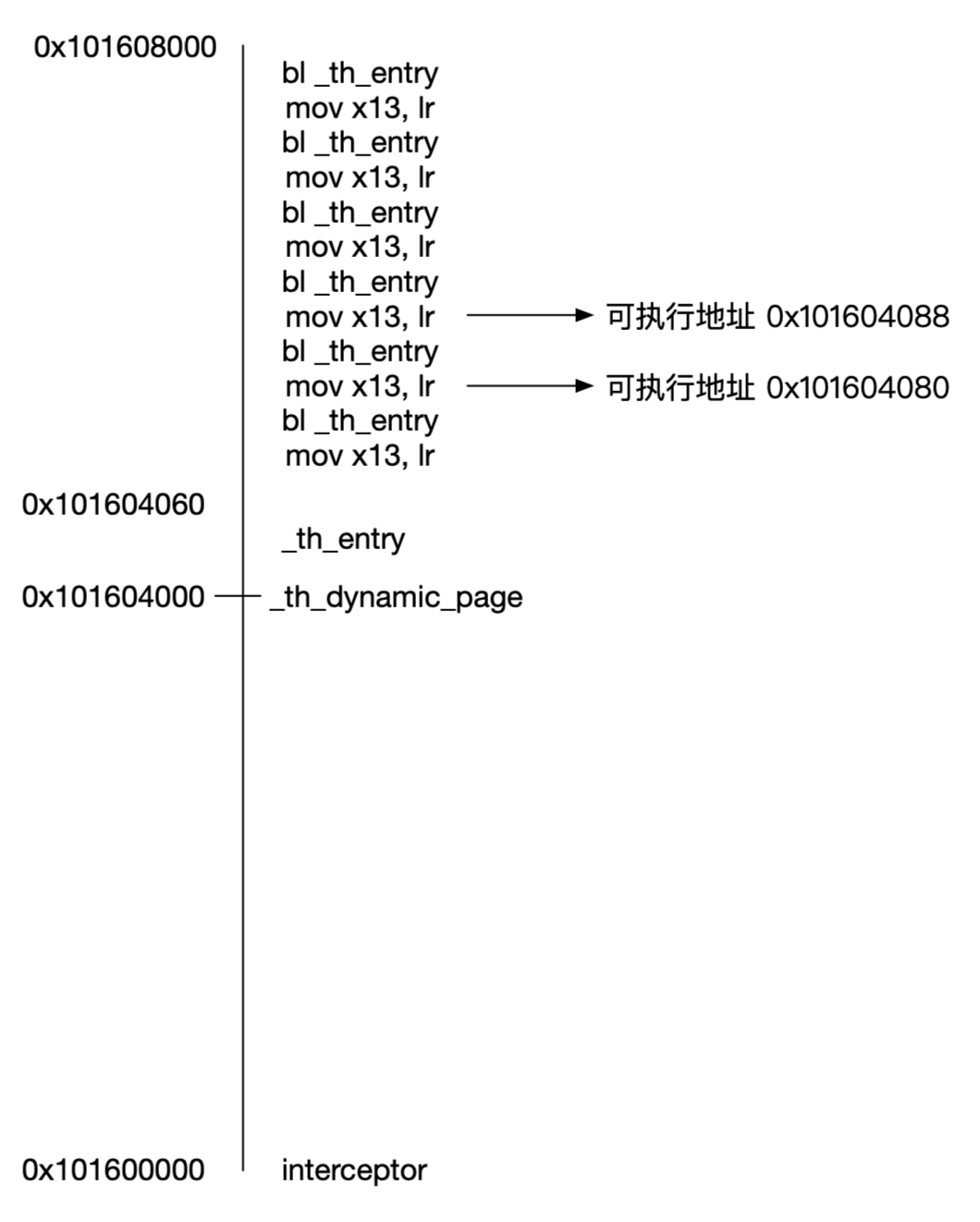
上图的可执行地址就是一堆新的 IMP B 的地址。
interceptor 用来保存自定义函数 IMP。
0x10160000 - 0x101604000 中空出来的一大堆地址刚好可以用来保存原 IMP A!!!在 IMP B 上向低地址偏移 0x4000就是原 IMP 了。
现在我们在汇编中既可以找到原 IMP,又可以找到自定义函数 IMP。保护好寄存器现场,就可以安稳调用两个 IMP 了。
接下来,我们还需要在代码中访问这两页内存。我们需要 vm_remap 完成访问,为了理解两页内存结构,先跳过 vm_remap 部分。
struct 本质上是一段内存,根据字段结构声明顺序构建内存结构。
使用 struct 构建和上面汇编的两页内存一样的结构后,可以准确访问每个地址。
typedef int32_t THDynamicPageEntryGroup[2];
static const int32_t THDynamicPageInstructionCount = 32;
static const int32_t THPageSize = 0x4000;
static const size_t THNumberOfDataPerPage = (0x4000 - THDynamicPageInstructionCount * sizeof(int32_t)) / sizeof(THDynamicPageEntryGroup);
// THNumberOfDataPerPage 为 2032
typedef struct {
union {
struct {
IMP redirectFunction;
int32_t nextAvailableIndex;
};
int32_t placeholder[THDynamicPageInstructionCount]; // 占位
};
THDynamicData dynamicData[THNumberOfDataPerPage]; // IMP 刚好是 8 个字节
} THDataPage;
typedef struct {
int32_t fixedInstructions[THDynamicPageInstructionCount]; // 占位
THDynamicPageEntryGroup jumpInstructions[THNumberOfDataPerPage]; // 可执行地址
} THCodePage;
typedef struct {
THDataPage dataPage;
THCodePage codePage;
} THDynamicPage;
上述的 THDataPage 和 THCodePage 均为 0x4000 大小,对应一页内存大小。
fixedInstructions 和 placeholder 是同大小,用于占位,对应的是 _th_entry 部分指令,这部分地址不能拿来写入 IMP。
下图是 THDynamicPage 和汇编指令地址对应关系:
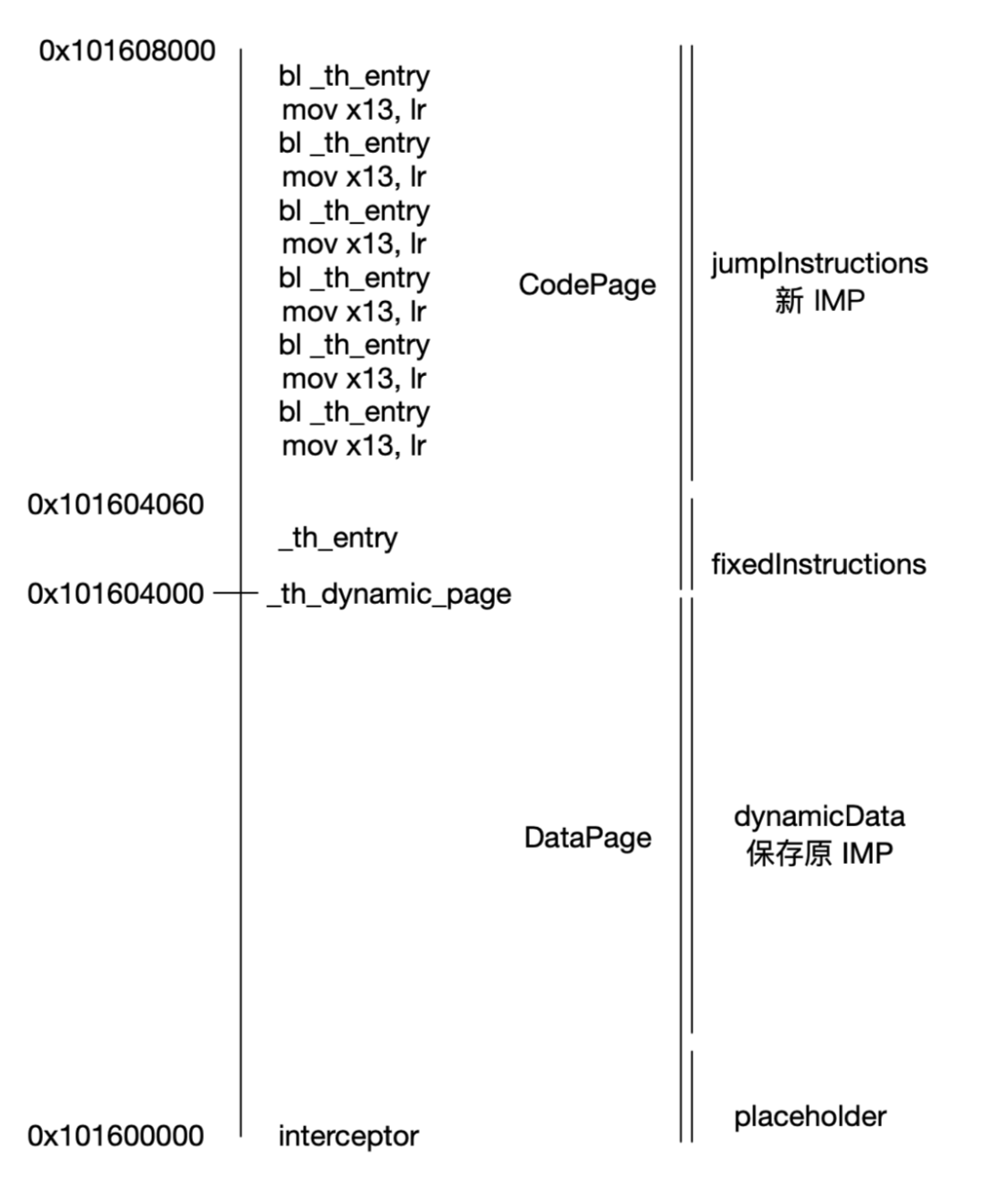
这里 placeholder 不能太浪费,还用到了 union 关键字,给 redirectFunction 和 nextAvailableIndex 留给空间。
重定向函数指针 redirectFunction 声明在头部,地址对应 0x101600000,正是 interceptor。
调用 interceptor 和原 IMP 的 thentry
_th_entry 主要任务是:
• 偏移地址取出原 IMP
• 保存原 IMP 用的参数寄存器 x0 - x7、浮点寄存器 q0 - q7 、返回地址寄存器 lr
• 调用 interceptor
• 恢复 x0 - x7、q0 - q7、lr
• 转到原 IMP 地址(不返回)
取出原 IMP 地址
_th_dynamic_page 中每次循环有两个命令,拿出两个循环:
0x101600080 mov x13, lr ;这是替换的新 IMP 地址,此时 lr 也是返回的地址,需要保存下来
0x101600084 bl _th_entry ;开始调用,此时 lr 为下一个指令 0x101600088
0x101600088 mov x13, lr
0x10160008c bl _th_entry
在 _th_entry 中的 lr 为 0x101600088,那 0x101600088 - 0x8 = 0x101600080,也就是新 IMP 地址。再偏移一页内存就得到原 IMP 地址了!
指令如下:
sub x12, lr, #0x8
sub x12, x12, #0x4000
ldr x10, [x12] ;取出 x12 作为地址上保存的 IMP 地址
保存恢复现场 & 调用自定义的 interceptor
调用我们加载的函数,会影响寄存器,需要提前入栈保存起来:
stp q0, q1, [sp, #-32]!
stp q2, q3, [sp, #-32]!
stp q4, q5, [sp, #-32]!
stp q6, q7, [sp, #-32]!
stp lr, x10, [sp, #-16]! ;保存 lr 和原 IMP
stp x0, x1, [sp, #-16]!
stp x2, x3, [sp, #-16]!
stp x4, x5, [sp, #-16]!
stp x6, x7, [sp, #-16]!
str x8, [sp, #-16]!
接下来就可以放心调用 interceptor 了,注意 blr只能传入寄存器,所以要进行一次传值:
ldr x8, interceptor
blr x8
调用完再依次出栈恢复寄存器信息,注意要和入栈顺序一一对应:
ldr x8, [sp], #16
ldp x6, x7, [sp], #16
ldp x4, x5, [sp], #16
ldp x2, x3, [sp], #16
ldp x0, x1, [sp], #16
ldp lr, x10, [sp], #16
ldp q6, q7, [sp], #32
ldp q4, q5, [sp], #32
ldp q2, q3, [sp], #32
ldp q0, q1, [sp], #32
br x10 ;最后跳转到原 IMP 就行啦
5 个 nop 做了啥
为啥作者说不要小看这五行汇编,看到这里,我想我们已经清楚了。
用于对齐内存地址,将可执行动态地址和原 IMP 地址对齐。
原本的 _th_entry 有 27 个指令 ,5 个 nop 将 _th_entry 的指令格式变成了 32,用到了 128 个字节。
我们知道 _th_entry 也会在两页内存中占一点空间,占的空间不整齐,后面对齐可执行动态地址和原 IMP 都会遇到阻碍。
同时回顾如下代码:
static const size_t THNumberOfDataPerPage = (0x4000 - THDynamicPageInstructionCount * sizeof(int32_t)) / sizeof(THDynamicPageEntryGroup);
THDynamicPageEntryGroup 是对应两条指令,8 字节大小,一个有 0x4000 字节,增加 5 个 nop,得到 2032 = (0x4000 - 32 * 4) / 8。这就对的整整齐齐了。
如果后续迭代调整了 _th_entry 指令个数,也要调整 nop 和 THDynamicPageInstructionCount。
vm_remap 技术
iOS 系统存在限制,我们没有权限创建可写可执行内存,但有了 vm_remap 可以将已有地址进行映射拷贝一份可写可执行内存。
这里我们通过 vm_allocate 分配两页内存(0x8000),通过 vm_deallocate 释放第二页内存,最后通过 vm_remap 将 th_dynamic_page 映射到第二页内存。这就构建好了我们需要的两页内存,第一页空的,用于存重定向函数地址和 IMP 地址,第二页映射好了所有的动态可执行地址。
代码如下:
vm_address_t fixedPage = (vm_address_t)&th_dynamic_page; // th_dynamic_page 的地址
vm_address_t newDynamicPage = 0;
kern_return_t kernResult = KERN_SUCCESS;
kernResult = vm_allocate(current_task(), &newDynamicPage, PAGE_SIZE * 2, VM_FLAGS_ANYWHERE); // 申请两页大小的虚拟内存
NSCAssert1(kernResult == KERN_SUCCESS, @"[THDynamicPage]::vm_allocate failed", kernResult);
vm_address_t newCodePageAddress = newDynamicPage + PAGE_SIZE;
kernResult = vm_deallocate(current_task(), newCodePageAddress, PAGE_SIZE); // 释放第二页
NSCAssert1(kernResult == KERN_SUCCESS, @"[THDynamicPage]::vm_deallocate failed", kernResult);
vm_prot_t currentProtection, maxProtection;
kernResult = vm_remap(current_task(), &newCodePageAddress, PAGE_SIZE, 0, 0, current_task(), fixedPage, FALSE, ¤tProtection, &maxProtection, VM_INHERIT_SHARE); // 第二页映射 th_dynamic_page
NSCAssert1(kernResult == KERN_SUCCESS, @"[THDynamicPage]::vm_remap failed", kernResult);
参考文章
[1]https://satanwoo.github.io/2020/04/22/NewBridgeHook/
[2]https://satanwoo.github.io/2020/04/26/TrampolineHookOpenSource/
[3]https://juejin.im/post/5a786ac96fb9a0633229890a
[4]https://juejin.im/post/5a786ba0f265da4e747f972b
[5]https://amywushu.github.io/2017/03/23/%E9%80%86%E5%90%91%E7%9F%A5%E8%AF%86-Hook-%E5%8E%9F%E7%90%86%E4%B9%8B-CydiaSubstrate%EF%BC%88%E4%BA%8C%EF%BC%89%EF%BC%9AMSHookMessageEx.html
[6]https://juejin.im/post/5c5281e0e51d45517334dd34
[7]https://zhuanlan.zhihu.com/p/130680057