深度学习基础总结,无一句废话(附完整思维导图)
1 线型回归
预测气温、预测销售额、预测商品价格等
模型:权重,偏差
模型训练:feed 数据学习模型参数值,使得误差尽可能小
训练集、测试集、验证集、样本、标签、特征
损失函数:回归常用平方误差函数;
优化算法:小批量随机梯度下降(每次选一小批样本训练参数),每批样本大小叫做 batch size
学习率:正数
超参数:不是通过训练学出的,如学习率,批量大小
网络输出层只有一个神经元节点
全连接层:输出层中的神经元和输入层中各个输入完全连接
基本要素:模型、训练数据、损失函数和优化算法
2 softmax 回归
图像分类、垃圾邮件识别、交易诈骗识别、恶意软件识别等
softmax运算符将输出值变换成值为正,且和为1的概率分布
交叉熵损失函数:更适合衡量两个概率分布差异

3 多层神经网络
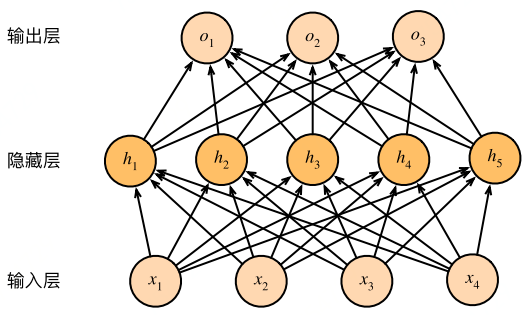
ReLU函数:只保留正数元素,负数元素清零
sigmoid函数:将元素值变换到0到1
tanh(双曲正切):元素值变换到-1到1
4 模型选择
模型在训练集上更准确时,不代表在测试集上就一定准确
训练误差:训练数据集上表现出的误差;泛化误差:模型在测试集上表现的误差期望
机器学习需要关注降低泛化误差
模型选择:评估若干候选模型的表现并从中选择模型
候选模型可以是有着不同超参数的同类模型
验证集:预留训练和测试集之外的数据; 折交叉验证:训练集分成份,共次轮询训练集
欠拟合:模型无法得到较低的训练误差
过拟合:模型的训练误差远小于测试集上的误差
模型复杂度:低,容易欠拟合;高,容易过拟合
数据集大小:训练样本少,尤其少于学习参数数时,容易过拟合;层数多时尽量数据大些
5 必知技巧
过拟合解决措施之一:权重衰减,常用L2正则
L2惩罚系数越大,惩罚项在损失函数中比重就越大
丢弃法(dropout):一定概率丢弃神经元
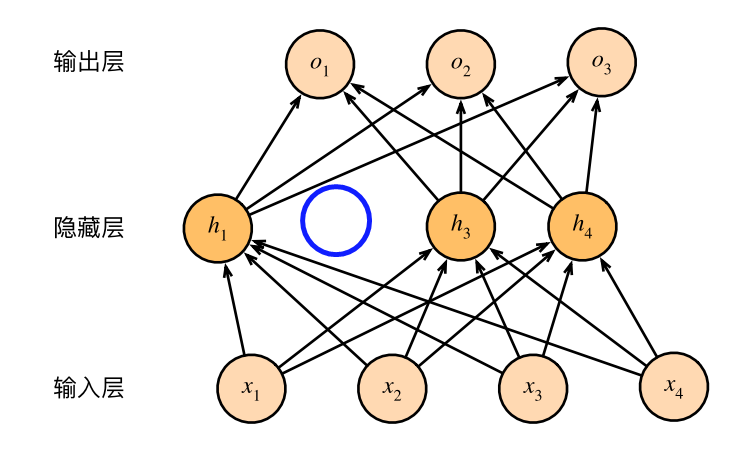
反向传播:从输出层到输入层参数调整过程
训练深度学习模型时,正向传播和反向传播间相互依赖
数值稳定性的问题:衰减和爆炸
层数较多时容易暴露,如每层都是一个神经元的30层网络,如果权重参数为0.2,会出现衰减;如果权重参数为2,会出现爆炸
权重参数初始化方法:正态分布的随机初始化;Xavier 随机初始化。
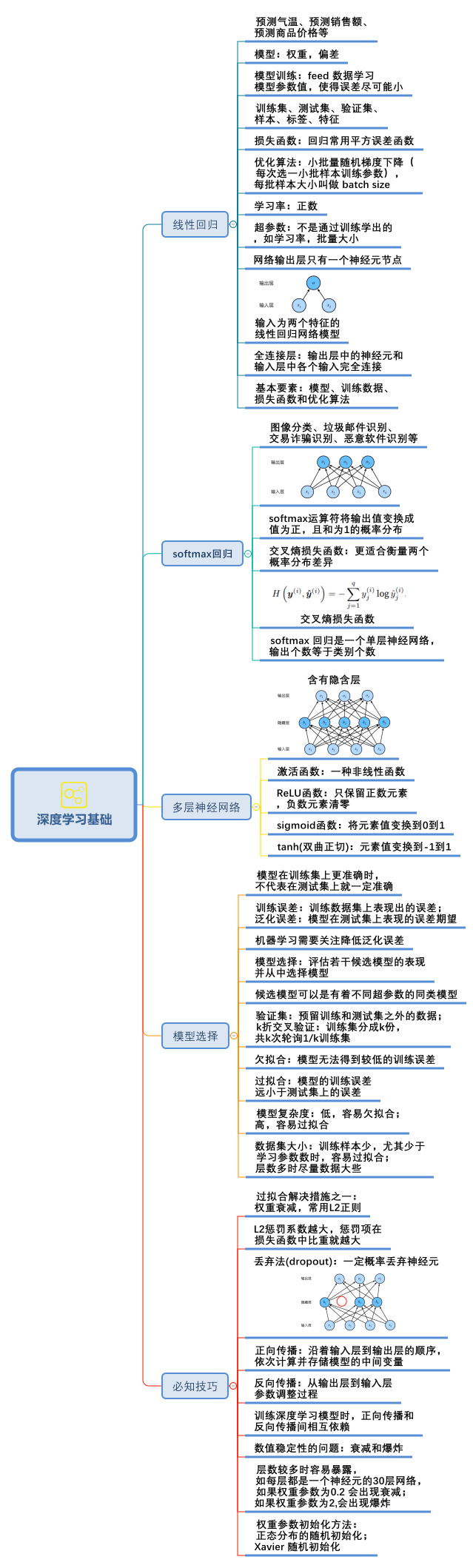
6 思维导图
以上1-5节的完整思维导图,制作出来方便大家更好学习:
<完>