理解Javascript执行过程

在程序中,有编译型语言和解释型语言。那么什么是编译型语言,什么是解释型语言呢?
编译型语言: 它首先将源代码编译成机器语言,再由机器运行机器码(二进制)。
解释型语言: 相对于编译型语言而存在的,源代码不是直接编译为目标代码,而是将源代码翻译成中间代码,再由解释器对中间代码进行解释运行的。 比如javascript/python等都是解释型语言(但是javascript是先编译完成后,再进行解释的)。
主要的编译型语言有c++, 解释型语言有Javascript, 和半解释半编译(比如java)。
一、了解代码是如何运行的?
我们都知道,代码是由CPU执行的,但是CPU不能直接执行我们的if...else这样的代码,它只能执行二进制指令,但是二进制对应我们的可读性来说并不友好,比如二进制 11100000 这样的,我们并不知道它代表的是什么含义, 因此科学家们就发明了汇编语言。
汇编语言
什么是汇编语言? 它解决了什么问题?
汇编语言是二进制指令的文本形式,和二进制指令是一一对应的关系,比如加法指令 00000011 写成汇编语言就是ADD。那么汇编语言的作用就是将ADD这样的还原成二进制,那么二进制就可以直接被CPU执行。它最主要的作用就是解决二进制指令的可读性问题。
但是汇编语言也有缺点:
- 编写的代码非常难懂,不好维护。
- 它是一种非常低的语言,它只针对特定的体系结构和处理器进行优化。
- 开发效率低。容易出现bug,不好调试。
因此这个时候就发明了高级语言。
高级语言
为什么我们叫它是高级语言? 因为它更符合我们人类的思维和阅读习惯,因为代码是写给人看的,不是写给机器看的,只是我们的计算机能运行而已,比如我们之前写的 if...else这样的代码 比我们之前的 二进制 11100000 可读性好很多,但是我们的计算机并不能直接执行高级语言。所以我们需要把高级语言转化为编译语言/机器指令,我们计算机CPU才能执行。那么这个过程就叫做编译。
我们的javascript是一种高级语言,因此我们的javascript也需要编译后才能执行,但是我们前面说过,javascript也是一种解释型语言, 那么它和编译型语言有什么区别呢? 因此我们可以先从编译说起。
了解编译
上面了解了编译的概念,那么我们来了解下我们的js代码为什么需要编译? 比如同样一份C++代码在windows上会编译成 .obj文件,但是在Linux上则会生成.o文件。他们两者生成的文件是不能通用的。这是因为可执行文件除了代码以外还需要操作系统,API,内存,线程,进程等系统资源。但是不同的操作系统他们实现的方式也是不相同的。因此针对不同的操作系统我们需要使用编译型语言对他们分别进行编译等。
了解解释型语言
先看下编译型语言, 编译型语言是代码在 运行前 编译器将人类可以理解的语言转换成机器可以理解的语言。
解释型语言: 也是将人类可以理解的语言转换成机器可以理解的语言,但是它是在 运行时 转换的。
最主要的区别是: 编译型语言编写的代码在编译后直接可以被CPU执行及运行的。但是解释型语言需要在环境中安装解释器才能被解析。
打个比方说: 我现在要演讲一篇中文文稿,但是演讲现场有个外国人,他只懂英文,因此我们事先把整个文章翻译成英文给他们听(这就是编译型语言),我们也可以同声传译的方法一句一句边读边翻译给他们听。(这就是解释型语言)。
二、了解javascript执行过程
1、 了解javascript解析引擎
javascript的引擎的作用简单的来讲,就是能够读懂javascript代码,并且准确地给出运行结果的程序,比如说,当我们写 var temp = 1+1; 这样一段代码的时候,javascript引擎就能解析我们这段代码,并且将temp的值变为2。
Javascript引擎的基本原理是:它可以把JS的源代码转换成高效,优化的代码,这样就可以通过浏览器解析甚至可以被嵌入到应用当中。
每个javascript引擎都实现了一个版本的ECMAScript, javascript只是它的一个分支,那么ECMAScript在不断的发展,那么javascript的引擎也会在不断的改变。
为什么会有那么多引擎,那是因为他们每个都被设计到不同的web浏览器或者像Node.js那样的运行环境当中。他们唯一的目的是读取和编译javascript代码。
那么常见的javascript引擎有如下:-
Mozilla浏览器 -----> 解析引擎为 Spidermonkey(由c语言实现的)
Chrome浏览器 ------> 解析引擎为 V8(它是由c++实现的)
Safari浏览器 ------> 解析引擎为 JavaScriptCore(c/c++)
IE and Edge ------> 解析引擎为 Chakra(c++)
Node.js ------> 解析引擎为 V8解析引擎是根据 ECMAScript定义的语言标准来动态执行javascript字符串的。
那么解析引擎是如何解析JS的呢?
解析JS分为2个阶段:如下所示:
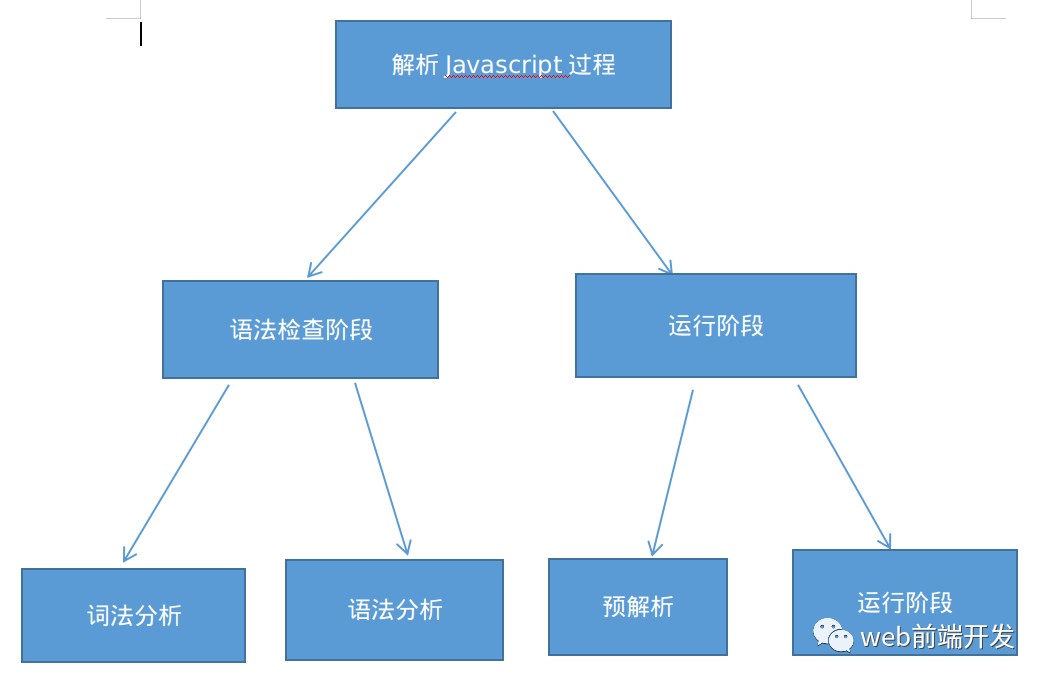
如上图我们可知: javascript解析分为:语法解析阶段 和 运行阶段,其中语法解析阶段又分为2种,分别为: 词法分析和语法分析。 运行阶段分为:预解析 和 运行阶段。
注意:在javascript解析过程中,如果遇到错误,会直接跳出当前的代码块,直接执行下一个script代码段,因此在同一个script内的代码段有错误的话就不会执行下去。但是它不会影响下一个script内的代码段。
1、语法解析阶段
语法解析阶段 包括 词法分析 和 语法分析。
1.1. 词法分析
词法分析会将js代码中的字符串分割为有意义的代码块,这些代码块我们可以称之为 "词法单元"。比如简单的如下代码:
var a = 1; 那么这行代码会被分为以下词法单元:var、a、=、1 那么这些零散的词法单元会组成一个词法单元流进行解析。 比如上面词义分析后结果变成如下:
[
{
"type": "Keyword",
"value": "var"
},
{
"type": "Identifier",
"value": "a"
},
{
"type": "Punctuator",
"value": "="
},
{
"type": "Numeric",
"value": "1"
}
]上面的转换结果,我们可以使用这个在线的网址转换(https://esprima.org/demo/parse.html)
我们可以把babel编译器的代码拿过来使用下,看下如何使用javascript来封装词法分析,仅供参考代码如下:
<!DOCTYPE html>
<html>
<head>
<title></title>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width,initial-scale=1.0,maximum-scale=1.0,user-scalable=0">
</head>
<body>
<div id="app">
</div>
<script type="text/javascript">
function tokenizer(input) {
// 记录当前解析到词的位置
var current = 0;
// tokens 用来保存我们解析的token
var tokens = [];
// 利用循环进行解析
while(current < input.length) {
// 提取出当前要解析的字符
var char = input[current];
// 处理符号: 检查是否是符号
var PUNCTUATOR = /[`~!@#$%^&*()_\-+=<>?:"{}|,.\/;'\\[\]·~!@#¥%……&*()——\-+={}|《》?:“”【】、;‘’,。、]/im;
if (PUNCTUATOR.test(char)) {
// 创建变量用于保存匹配的符号
var punctuators = char;
// 判断是否是箭头函数的符号
if (char === '=' && input[current + 1] === '>') {
punctuators += input[++current];
}
current++;
// 最后把数据存入到tokens中
tokens.push({
type: 'Punctuator',
value: punctuators
});
// 进入下一次循环
continue;
}
// 下面是处理空格,如果是空格的话,则直接进入下一个循环
var WHITESPACE = /\s/;
if (WHITESPACE.test(char)) {
current++;
continue;
}
// 处理数字,检查是否是数字
var NUMBERS = /[0-9]/;
if (NUMBERS.test(char)) {
// 创建变量,用于保存匹配的数字
var number = '';
// 循环当前的字符及下一个字符,直到不是数字为止
while(NUMBERS.test(char)) {
number += char;
char = input[++current];
}
// 最后我们把数据更新到tokens中
tokens.push({
type: 'Numeric',
value: number
});
// 进入下一个循环
continue;
}
// 检查是否是字符
var LETTERS = /[a-z]/i;
if (LETTERS.test(char)) {
// 创建一个临时变量保存该字符
var value = '';
// 循环遍历所有的字母
while(LETTERS.test(char)) {
value += char;
char = input[++current];
}
// 判断当前的字符串是否是关键字
var KEYWORD = /function|var|return|let|const|if|for/;
if (KEYWORD.test(value)) {
// 标记关键字
tokens.push({
type: 'Keyword',
value: value
})
} else {
// 标记变量
tokens.push({
type: 'Identifier',
value: value
})
}
// 进入下一次循环
continue;
}
// 如果我们没有匹配上任何类型的token; 那么就抛出一个错误
throw new TypeError('I dont konw what this character is:' + char);
}
// 最后我们返回词法单元数组
return tokens;
}
var str = 'var a = 1';
console.log(tokenizer(str));
</script>
</body>
</html>效果执行打印如下所示:

var str = 'var a = 1';
console.log(tokenizer(str));如上可以看到,该str的长度为9,current从0开始,也就是说从第一个字符开始进行解析,判断该字符是否为 符号、空格、数字、字母等操作。
如果是字母的话,继续判断下一个字符是否是字母,依次类推,直到下一个字符不是字母的话,就获取该值,因此获取到的 value为 'var';
然后会判断该字符串是否为关键字,如关键字: var KEYWORD = /function|var|return|let|const|if|for/;这些其中的一个,如果是的话,直接标记为关键字,存入tokens数组中,如下代码:
tokens.push({
type: 'Keyword',
value: value
});
因此 tokens = [{ type: 'Keyword', value: 'var' }];然后继续循环,此时 current = 3了; 因此是空格,如果是空格的话,代码会跳过该循环,进行执行下一次循环, 因此current=4了; 因此vaule = a 了;因此就执行标记变量的代码,如下所示:
// 标记变量
tokens.push({
type: 'Identifier',
value: value
});因此tokens的值为 = [{ type: 'Keyword', value: 'var' }, { type: 'Identifier', value: 'a' }];
继续下一次循环 current = 5; 可知,也是一个空格,跳过该空格,继续下一次循环,因此current = 6; 此时的value = '='; 因此会进入 检查是否是符号 是代码内部,因此 tokens 值变为如下:
tokens = [
{ type: 'Keyword', value: 'var' },
{ type: 'Identifier', value: 'a' },
{ type: 'Punctuator', value: '=' }
];同理 current = 7 也是一个空格,因此跳过循环, 此时current = 8; 字符就变为 1;即 value = 1; 因此会进入 检查是否是数字if语句内部,该内部也会依次循环下一个字符是否为数字,直到不是数字为止。因此 value = 1; 最后的tokens的值变为:
tokens = [
{ type: 'Keyword', value: 'var' },
{ type: 'Identifier', value: 'a' },
{ type: 'Punctuator', value: '=' },
{ type: 'Numeric', value: '1' }];如上就是一个词法分析的一个整个过程。
1.2、语法分析语法分析在这个过程中会将词法单元流转换成一颗 抽象语法树(AST)。比如 var a = 1; 的词法单元流就会被解析成下面的AST;
我们也可以使用这个在线的网址转换(https://esprima.org/demo/parse.html), 结果变为如下所示:
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "a"
},
"init": {
"type": "Literal",
"value": 1,
"raw": "1"
}
}
],
"kind": "var"
}
],
"sourceType": "script"
}基本的解析成AST函数代码如下:
// 接收tokens作为参数, 生成抽象语法树AST
function parser(tokens) {
// 记录当前解析到词的位置
var current = 0;
// 通过遍历来解析token节点
function walk() {
// 从token中第一项进行解析
var token = tokens[current];
// 检查是不是数字类型
if (token.type === 'Numeric') {
// 如果是数字类型的话,把current当前的指针移动到下一个位置
current++;
// 然后返回一个新的AST节点
return {
type: 'Literal',
value: Number(token.value),
row: token.value
}
}
// 检查是不是变量类型
if (token.type === 'Identifier') {
// 如果是,把current当前的指针移动到下一个位置
current++;
// 然后返回我们一个新的AST节点
return {
type: 'Identifier',
name: token.value
}
}
// 检查是不是运输符类型
if (token.type === 'Punctuator') {
// 如果是,current自增
current++;
// 判断运算符类型,根据类型返回新的AST节点
if (/[\+\-\*/]/im.test(token.value)) {
return {
type: 'BinaryExpression',
operator: token.value
}
}
if (/\=/.test(token.value)) {
return {
type: 'AssignmentExpression',
operator: token.value
}
}
}
// 检查是不是关键字
if (token.type === 'Keyword') {
var value = token.value;
// 检查是不是定义的语句
if (value === 'var' || value === 'let' || value === 'const') {
current++;
// 获取定义的变量
var variable = walk();
// 判断是否是赋值符号
var equal = walk();
var rightVar;
if (equal.operator === '=') {
// 获取所赋予的值
rightVar = walk();
} else {
// 不是赋值符号, 说明只是定义的变量
rightVar = null;
current--;
}
// 定义声明
var declaration = {
type: 'VariableDeclarator',
id: variable, // 定义的变量
init: rightVar
};
// 定义要返回的节点
return {
type: 'VariableDeclaration',
declarations: [declaration],
kind: value
}
}
}
// 遇到一个未知类型就抛出一个错误
throw new TypeError(token.type);
}
// 现在,我们创建一个AST,根节点是一个类型为 'Program' 的节点
var ast = {
type: 'Program',
body: [],
sourceType: 'script'
};
// 循环执行walk函数,把节点放入到ast.body中
while(current < tokens.length) {
ast.body.push(walk());
}
// 最后返回我们的AST
return ast;
}
var tokens = [
{ type: 'Keyword', value: 'var' },
{ type: 'Identifier', value: 'a' },
{ type: 'Punctuator', value: '=' },
{ type: 'Numeric', value: '1' }
];
console.log(parser(tokens));结果如下所示: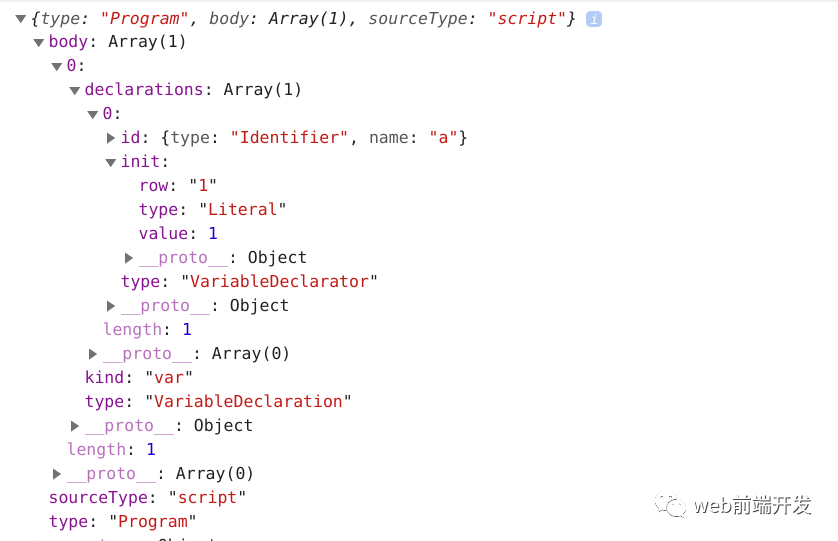
转换
我们对生成的AST树节点需要进行处理下,比如我们使用ES6编写的代码,比如用到了let,const这样的,我们需要转换成var。 因此我们需要对AST树节点进行转换操作。
转换AST的时候,我们可以添加、移动、替换及删除AST抽象树中的节点操作。
基本的代码如下:
/*
为了修改AST抽象树,我们首先要对节点进行遍历
@param AST语法树
@param visitor定义转换函数,也可以使用visitor函数进行转换
*/
function traverser(ast, visitor) {
// 遍历树中的每个节点
function traverseArray(array, parent) {
if (typeof array.forEach === 'function') {
array.forEach(function(child) {
traverseNode(child, parent);
});
}
}
function traverseNode(node, parent) {
// 看下 vistory中有没有对应的type处理函数
var method = visitor[node.type];
if (method) {
method(node, parent);
}
switch(node.type) {
// 从顶层的Program开始
case 'Program':
traverseArray(node.body, node);
break;
// 如下的是不需要转换的
case 'VariableDeclaration':
case 'VariableDeclarator':
case 'AssignmentExpression':
case 'Identifier':
case 'Literal':
break;
default:
throw new TypeError(node.type)
}
}
traverseNode(ast, null)
}
/*
下面是转换器,它用于遍历过程中转换数据,
我们接收之前的AST树作为参数,最后会生成一个新的AST抽象树
*/
function transformer(ast) {
// 创建新的ast抽象树
var newAst = {
type: 'Program',
body: [],
sourceType: 'script'
};
ast._context = newAst.body;
// 我们把AST 和 vistor 作为参数传入进去
traverser(ast, {
VariableDeclaration: function(node, parent) {
var variableDeclaration = {
type: 'VariableDeclaration',
declarations: node.declarations,
kind: 'var'
};
// 把新的 VariableDeclaration 放入到context中
parent._context.push(variableDeclaration);
}
});
// 最后返回创建号的新AST
return newAst;
}
var ast = {
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "a"
},
"init": {
"type": "Literal",
"value": 1,
"raw": "1"
}
}
],
"kind": "const"
}
],
"sourceType": "script"
}
console.log(ast);
console.log('转换后的-------');
console.log(transformer(ast));打印结果如下所示,可以看到,ES6的语法已经被转换了,如下所示:

代码生成我们会根据上面生成的AST树来生成一个很大的字符串当中。
基本代码如下所示:
var newAst = {
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "a"
},
"init": {
"type": "Literal",
"value": 1,
"raw": "1"
}
}
],
"kind": "var"
}
],
"sourceType": "script"
}
function codeGenerator(node) {
console.log(node.type);
// 对于不同类型的节点分开处理\
switch (node.type) {
// 如果是Program节点,我们会遍历它的body属性中的每一个节点
case 'Program':
return node.body.map(codeGenerator).join('\n');
// VariableDeclaration节点
case 'VariableDeclaration':
return node.kind + ' ' + node.declarations.map(codeGenerator);
// VariableDeclarator 节点
case "VariableDeclarator":
return codeGenerator(node.id) + ' = ' + codeGenerator(node.init);
// 处理变量
case 'Identifier':
return node.name;
//
case 'Literal':
return node.value;
default:
throw new TypeError(node.type);
}
}
console.log(codeGenerator(newAst));如上最后打印了 var a = 1; 如上就是js整个编译的过程。
2、 运行阶段
运行阶段包括 预解析 和 运行阶段。
2.1、预解析
如上我们已经编译完成了,那么现在我们需要对js代码进行预解析,那么什么是预解析呢,它的作用是什么呢?
预解析指的是:在js文件或script里面的代码在正式开始执行之前,会进行一些解析工作。
比如上在全局中寻找var关键字声明的变量和通过function关键字声明的函数。
找到全局变量或函数后,我们会对该进行作用域提升,但是在变量提升声明的情况下不会赋值操作,因此它的默认值是undefined。
通过声明提升,对于函数来讲,函数可以在声明函数体之上进行调用。变量也可以在赋值之前进行输出,只是变量输出的值为undefined而已。
比如如下代码:
var a = 1;
function abc() {
console.log(a);
var a = 2;
}
abc();
如上代码,我们在全局变量中定义了一个变量a = 1; 在函数abc中先打印a,然后给 var a = 2; 进行赋值,但是最后打印的结果为undefined;那是因为var在作用域中有提升的。上面的代码在预解析的时候,会被解析成如下代码:
var a = 1;
function abc() {
var a;
console.log(a);
a = 2;
}
abc();预编译需要注意如下几个问题:
- 预编译首先是全局预编译,函数体未调用时是不进行预编译的。
- 只有var 和 function 声明会被提升。
- 在所在的作用域会被提升,不会扩展到其他的作用域。
- 预编译后会顺序执行代码。
2.2 、运行阶段
在浏览器环境中,javascript引擎会按照
Copyright© 2013-2020
All Rights Reserved 京ICP备2023019179号-8