gcc a.c 究竟经历了什么?
你知道一次gcc命令究竟经历了什么吗?
我们先来看一段C语言示例源代码:
// test.cc
#include <stdio.h>
int main() {
printf("Hello 程序喵\n");
return 0;
}编译运行
$ gcc test.cc
$ ./a.out
Hello 程序喵如图一,
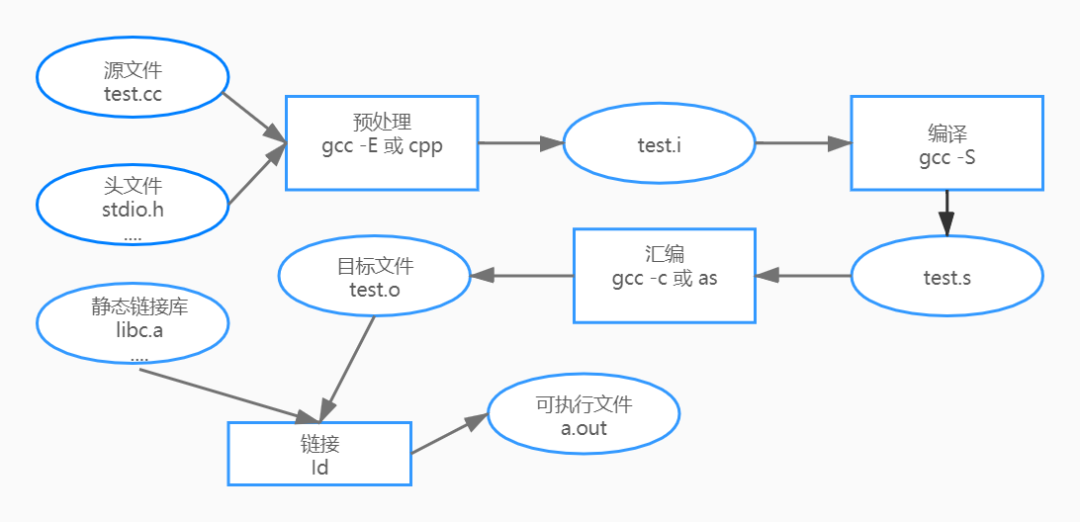
gcc构建过程分解
我们平时都会使用gcc来编译程序,这一行简单的命令其实经历了很多复杂的过程:
- 预处理
- 编译
- 汇编
- 链接
首先使用file看一下test.cc文件类型:
$ file test.cc
test.cc: C source, UTF-8 Unicode text, with CRLF line terminators我们接下来看看这每个过程都做了什么?
预处理
命令:
$ gcc -E test.cc -o test.i
或者
$ cpp test.cc -o test.i再看下test.i的文件类型
$ file test.i
test.i: C source, UTF-8 Unicode text这里可以看出预处理后的文件和预处理前的文件类型是相同的,都是文本文件,也可以直接查看test.i的内容,里面代码较多,就不贴上来了。
其实预处理主要操作有这几个:
- 展开所有#define宏定义,进行文本替换
- 删除程序中所有的注释
- 处理所有的条件编译,#if、#ifdef、#elif等
- 处理所有的#include指令,把这些头文件的内容都复制到引用的源文件中
- 添加行号和文件名标识,方便编译器产生警告及调试信息
- 保留所有的#pragma编译器指令,因为编译器会使用他们
编译
命令:
gcc -S test.cc -o test.s再查看文件类型
$ file test.s
test.s: assembler source, ASCII text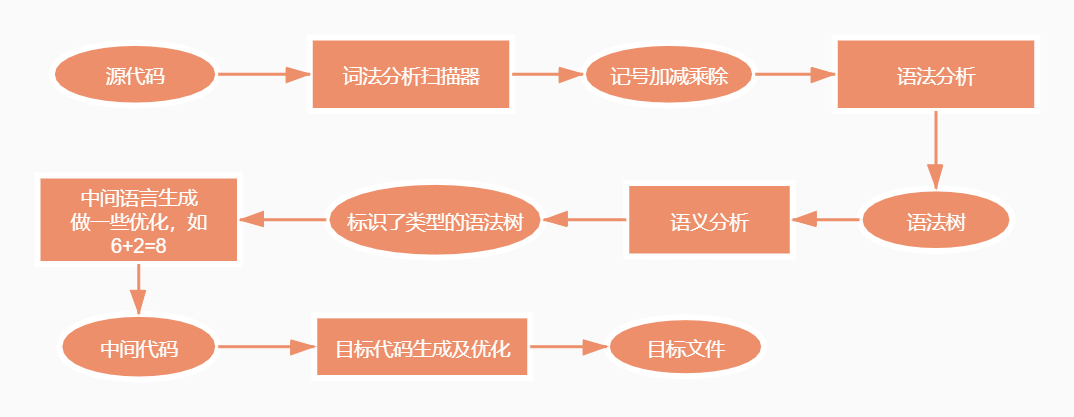
编译过程分解
如图二,编译过程就是把预处理后的文件进行一系列操作生成相应的汇编文件:
- 词法分析:又称词法扫描,通过扫描器,利用有限状态机的算法将源码中的字符串分割成一系列记号,如加减乘除数字括号等。
- 语法分析:使用语法分析器对词法分析产生的记号运用上下文无关语法的手段进行语法分析,产生语法分析树。这期间如果表达式不合法(括号不匹配等),就会报错。
- 语义分析:语法分析检查表达式是否合法,语义分析检查表达式是否有意义,如浮点型整数赋值给指针,编译器就会报错。
- 中间语言生成:做一些语法树优化,如6+2=8。
- 目标代码生成及优化:将中间代码生成目标汇编代码。
汇编
命令:
$ gcc -c test.s -o test.o
或
$ as test.s -o test.o查看文件类型:
$ file test.o
testt.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped使用汇编器将汇编代码转成机器可以执行的指令,其实就是将汇编指令和机器指令按照对照表一一翻译。
链接
为什么汇编器不直接生成可执行文件而是生成一个目标文件呢,因为一个文件需要依赖其它好多个库,这些库的符号需要通过链接过程才可以互相配合生成一个可执行文件,需要经历地址和空间分配、符号决议、重定位等步骤,这块内容较多,后续会详细介绍,现在我们可以简单的通过ldd查看一下可执行程序需要依赖的库,这些库都需要在链接过程中被链接才可以使用。
$ ldd a.out
linux-vdso.so.1 (0x00007ffff5b4a000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fa1fc660000)
/lib64/ld-linux-x86-64.so.2 (0x00007fa1fce00000)