ELF文件格式解析器 原理 + 代码

本文为看雪论坛精华文章 看雪论坛作者ID:菜鸟m号
写在前面
读《Linux 二进制》,发现作者对 ELF 文件格式部分并没有做详细介绍,为了加深对 ELF 文件格式理解,我自己着手写了个解析器, 会和 readelf 工具协同对比。
原理
ELF文件(目标文件)格式主要三种:
1. 可重定向文件(Relocatable file):文件保存着代码和适当的数据,用来和其他的目标文件一起来创建一个可执行文件或者是一个共享目标文件。(目标文件或者静态库文件,即 linux 通常后缀为 .a 和 .o 的文件)这是由汇编器汇编生成的 .o 文件。
后面的链接器(link editor)拿一个或一些 Relocatable object files 作为输入,经链接处理后,生成一个可执行的对象文件 (Executable file) 或者一个可被共享的对象文件(Shared object file),内核可加载模块 .ko 文件也是 Relocatable object file。
2. 可执行文件(Executable file):文件保存着一个用来执行的程序。(例如bash,gcc等)
3.共享目标文件:
即 .so 文件。如果拿前面的静态库来生成可执行程序,那每个生成的可执行程序中都会有一份库代码的拷贝。 如果在磁盘中存储这些可执行程序,那就会占用额外的磁盘空 间;另外如果拿它们放到 Linux 系统上一起运行,也会浪费掉宝贵的物理内存。 如果将静态库换成动态库,那么这些问题都不会出现。
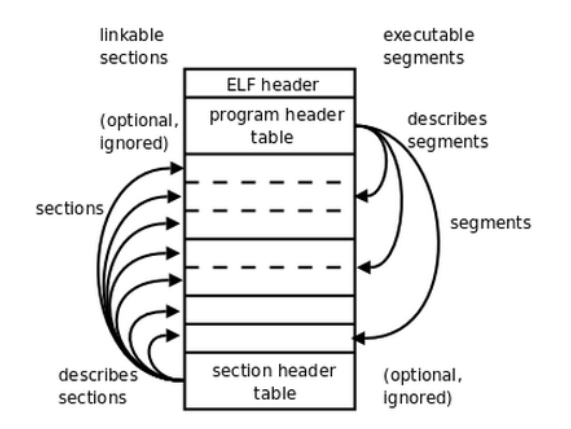
一般的ELF文件有三个重要的索引表
1. ELF header:在文件的开始,描述整个文件的组织。
2. Program header table:告诉系统如何创建进程映像。用来构造进程映像的目标文件必须具有程序头部表,可重定位文件不需要这个表。
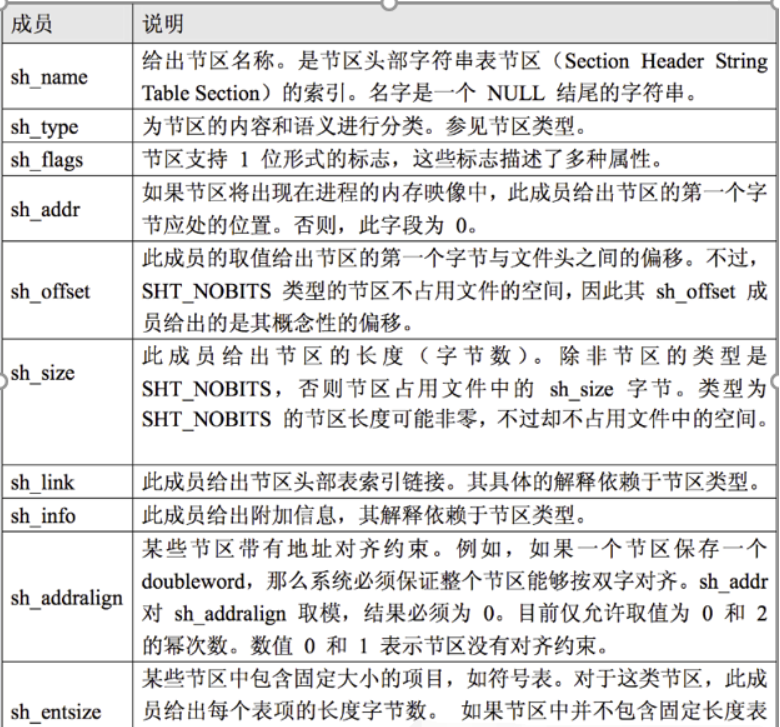
3. Section header table:包含了描述文件节区的信息,每个节区在表中都有一项,每一项给出诸如节区名称、节区大小这类信息。
用于链接的目标文件必须包含节区头部表,其他目标文件可以有,也可以没有这个表。
4. sections 或者 segments:segments 是从运行的角度来描述 ELF 文件,sections 是从链接的角度来描述 ELF 文件。
也就是说,在链接阶段,我们可以忽略 program header table 来处理此文件,在运行阶段可以忽略 section header table 来处理此程序(所以很多加固手段删除了section header table)。
注意:segments与sections是包含的关系,一个segment包含若干个section。
(图片来自网络)
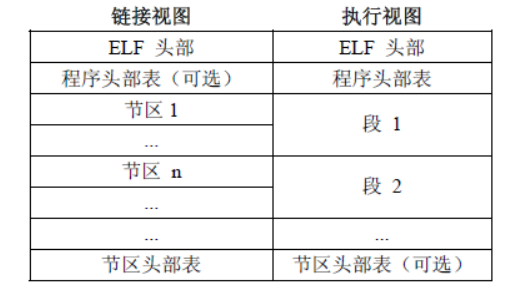
了解整体结构之后,我们就可以看一下具体的结构体和指针了。
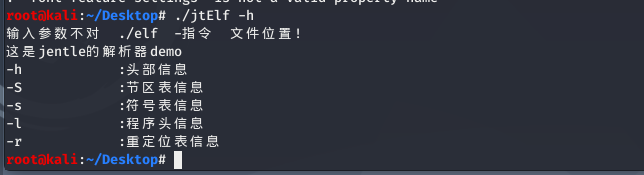
代码先写了一个 help 函数,包含基本信息和指令结构,效果如下:
void help()
{
printf("这是jentle的解析器demo\n");
printf("-h :头部信息\n");
printf("-S :节区表信息\n");
printf("-s :符号表信息\n");
printf("-l :程序头信息\n");
printf("-r :重定位表信息\n");
}
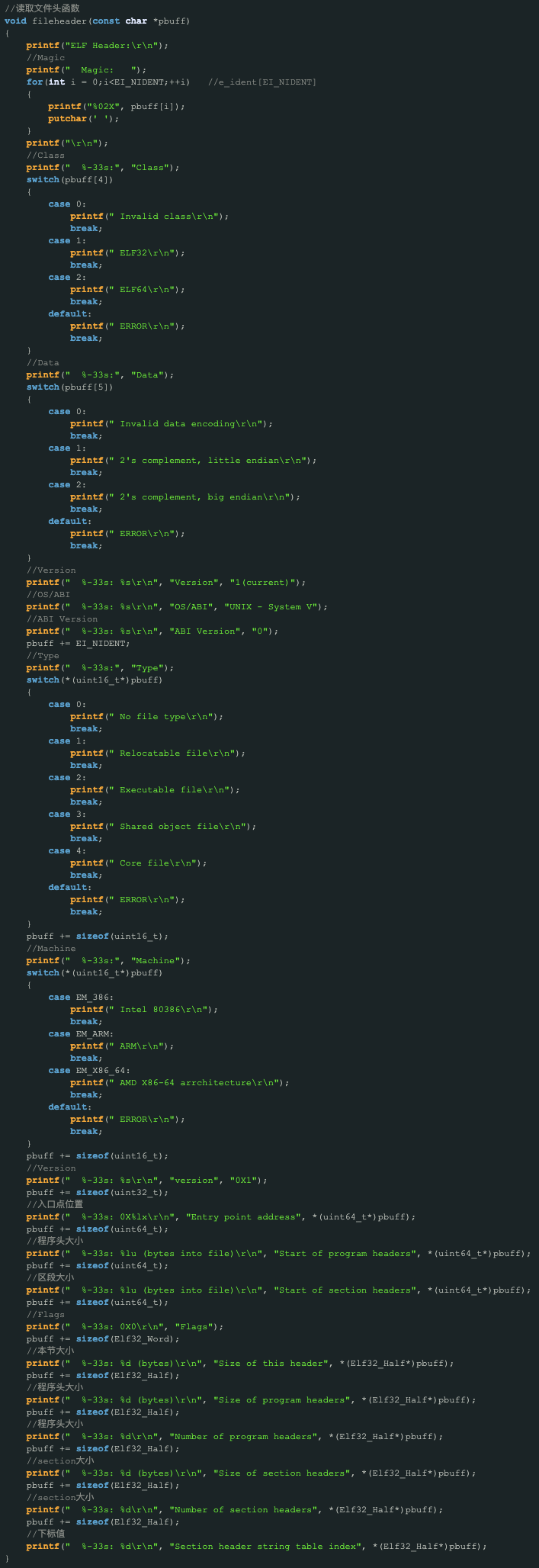
1. -h 指令,查看和打印程序 header 函数。
我们查看一下 elf headr 结构体:
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf32_Half e_type; /* Object file type */
Elf32_Half e_machine; /* Architecture */
Elf32_Word e_version; /* Object file version */
Elf32_Addr e_entry; /* Entry point virtual address */
Elf32_Off e_phoff; /* Program header table file offset */
Elf32_Off e_shoff; /* Section header table file offset */
Elf32_Word e_flags; /* Processor-specific flags */
Elf32_Half e_ehsize; /* ELF header size in bytes */
Elf32_Half e_phentsize; /* Program header table entry size */
Elf32_Half e_phnum; /* Program header table entry count */
Elf32_Half e_shentsize; /* Section header table entry size */
Elf32_Half e_shnum; /* Section header table entry count */
Elf32_Half e_shstrndx; /* Section header string table index */
} Elf32_Ehdr;这里面包括后面的 code 都会涉及到 elf 的数据格式,在这给出:
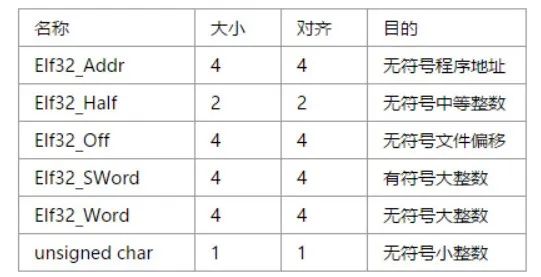
所以打印 ELF 的头信息可以设计为:
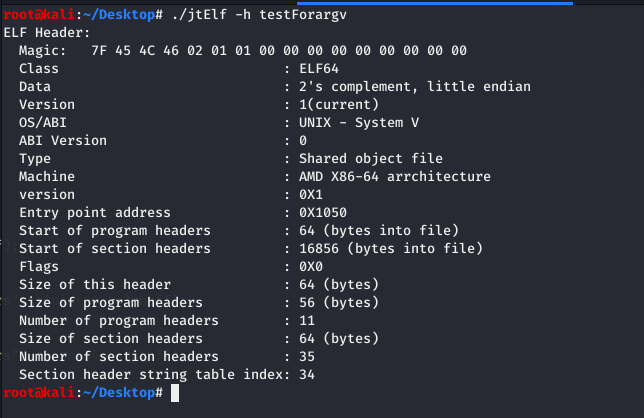
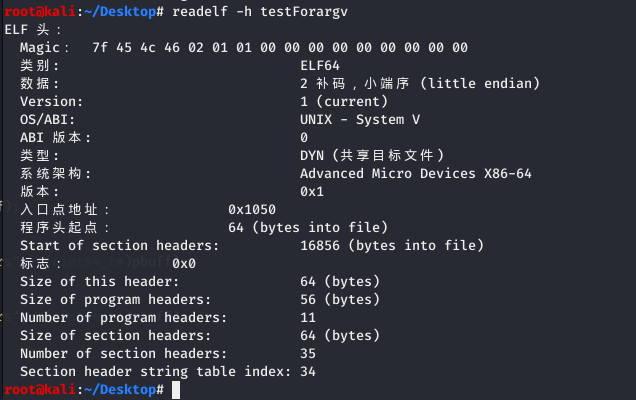
readelf 对比:
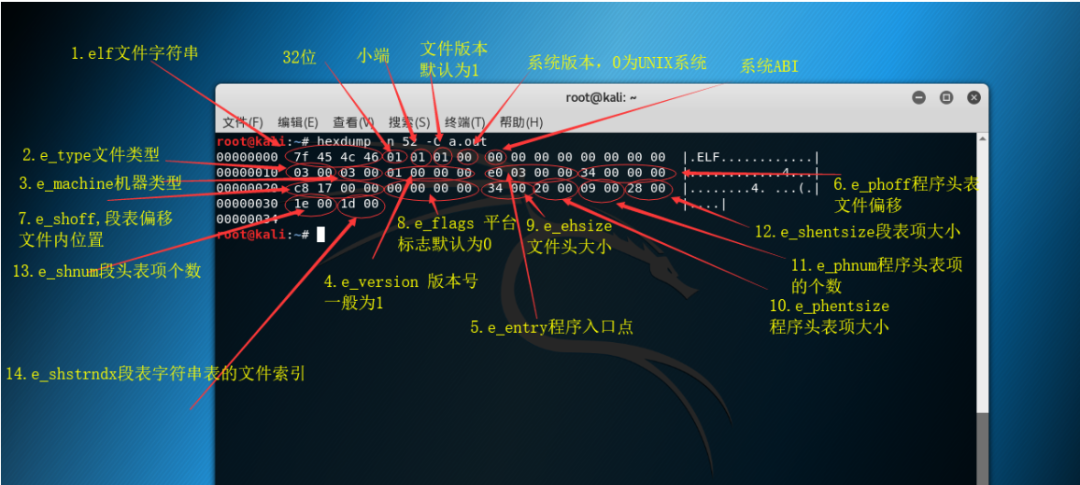
参考前辈图解:
https://blog.csdn.net/qq_37431937
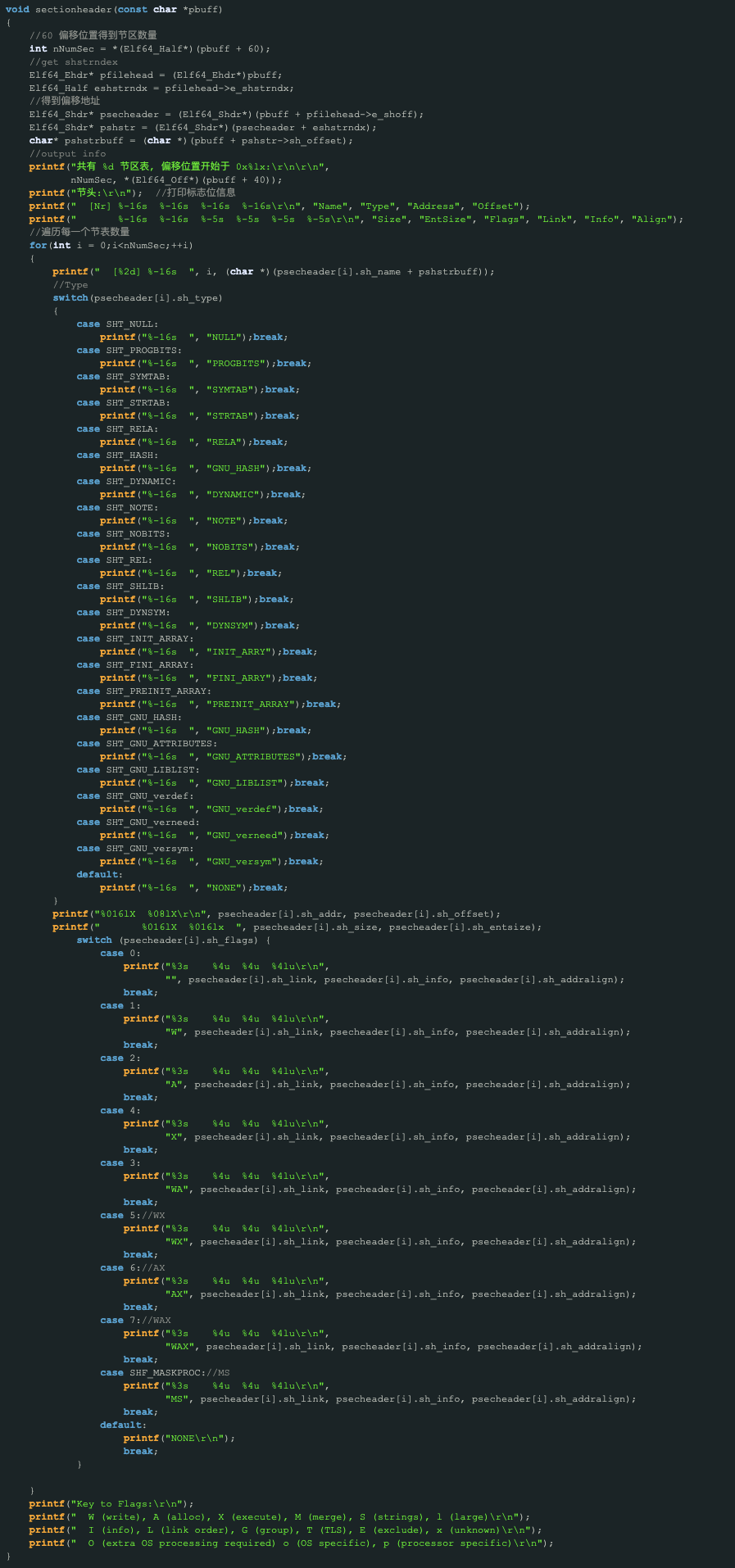
2. -S 指令 打印 section 信息
段表结构体:
typedef struct {
Elf32_Word st_name; //符号表项名称。如果该值非0,则表示符号名的字
//符串表索引(offset),否则符号表项没有名称。
Elf32_Addr st_value; //符号的取值。依赖于具体的上下文,可能是一个绝对值、一个地址等等。
Elf32_Word st_size; //符号的尺寸大小。例如一个数据对象的大小是对象中包含的字节数。
unsigned char st_info; //符号的类型和绑定属性。
unsigned char st_other; //未定义。
Elf32_Half st_shndx; //每个符号表项都以和其他节区的关系的方式给出定义。
//此成员给出相关的节区头部表索引。
} Elf32_sym;一些成员参数解释:
代码设计:
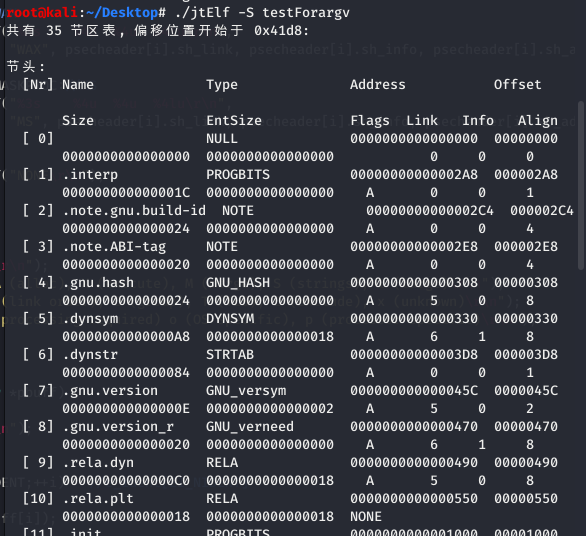
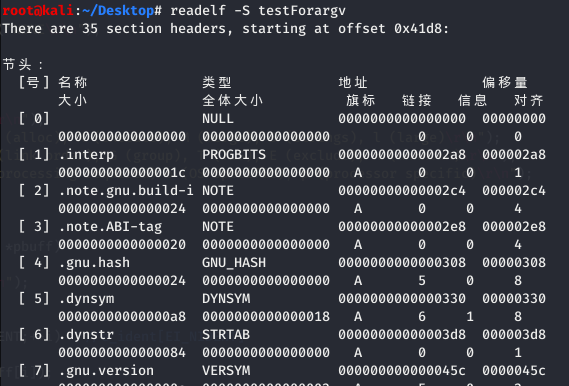
readelf 对比:
3. -s 打印符号表信息
目标文件的符号表中包含用来定位、重定位程序中符号定义和引用的信息。符号表 索引是对此数组的索引。索引 0 表示表中的第一表项,同时也作为 定义符号的索引。
符号是对某些类型的数据或者代码(如全局变量或函数)的符号引用。例如,printf()函数会在动态符号表 .dynsym 中存有一个指向该函数的符号条目。
在大多数共享库和动态链接可执行文件中,存在两个符号表。如前面使用readelf –S 命令输出的内容中,可以看到有两个节:.dynsym 和.symtab。
.dynsym 保存了引用来自外部文件符号的全局符号,如 printf 这样的库函数,.dynsym 保存的符号是 .symtab 所保存符号的子集,.symtab 中还保存了可执行文件的本地符号,如全局变量,或者代码中定义的本地函数等。因此,.symtab 保存了所有的符号,而 .dynsym 只保存动态/全局符号。
因此,就存在这样一个问题:既然.symtab 中保存了.dynsym 中所有的符号,那么为什么还需要两个符号表呢?
使用 readelf –S 命令查看可执行文件的输出,可以看到一部分节被标记为了 A(ALLOC) 、WA(WRITE/ALLOC)或者 AX(ALLOC/EXEC)。
.dynsym 是被标记了 ALLOC 的,而.symtab 则没有标记。ALLOC 表示有该标记的节会在运行时分配并装载进入内存,而 .symtab 不是在运行时必需的,因此不会被装载到内存中。
.dynsym 保存的符号只能在运行时被解析,因此是运行时动态链接器所需要的唯一符号。
.dynsym 符号表对于动态链接可执行文件的执行来说是必需的,而 .symtab 符号表只是用来进行调试和链接的,有时候为了节省空间,会将 .symtab 符号表从生产二进制文件中删掉。
符号表:.dynsym
符号表包含用来定位、重定位程序中符号定义和引用的信息,简单的理解就是符号表记录了该文件中的所有符号,所谓的符号就是经过修饰了的函数名或者变量名,不同的编译器有不同的修饰规则。
例如符号_ZL15global_static_a,就是由 global_static_a 变量名经过修饰而来。
符号表格式如下:
typedef struct {
Elf32_Word st_name; //符号表项名称。如果该值非0,则表示符号名的字
//符串表索引(offset),否则符号表项没有名称。
Elf32_Addr st_value; //符号的取值。依赖于具体的上下文,可能是一个绝对值、一个地址等等。
Elf32_Word st_size; //符号的尺寸大小。例如一个数据对象的大小是对象中包含的字节数。
unsigned char st_info; //符号的类型和绑定属性。
unsigned char st_other; //未定义。
Elf32_Half st_shndx; //每个符号表项都以和其他节区的关系的方式给出定义。
//此成员给出相关的节区头部表索引。
} Elf32_sym;字符串表 .dynstr 略
void tableheader(const char *pbuff)
{
//从节区里面定位到偏移
Elf64_Ehdr* pfilehead = (Elf64_Ehdr*)pbuff;
Elf64_Half eshstrndx = pfilehead->e_shstrndx;
Elf64_Shdr* psecheader = (Elf64_Shdr*)(pbuff + pfilehead->e_shoff);
Elf64_Shdr* pshstr = (Elf64_Shdr*)(psecheader + eshstrndx);
char* pshstrbuff = (char *)(pbuff + pshstr->sh_offset);
for(int i = 0;i<pfilehead->e_shnum;++i)
{
if(!strcmp(psecheader[i].sh_name + pshstrbuff, ".dynsym") || !strcmp(psecheader[i].sh_name + pshstrbuff, ".symtab"))
{
Elf64_Sym* psym = (Elf64_Sym*)(pbuff + psecheader[i].sh_offset);
int ncount = psecheader[i].sh_size / psecheader[i].sh_entsize;
char* pbuffstr = (char*)((psecheader + psecheader[i].sh_link)->sh_offset + pbuff);
printf("Symbol table '%s' contains %d entries:\r\n", psecheader[i].sh_name + pshstrbuff, ncount);
outputsyminfo(psym, pbuffstr, ncount);
continue;
}
}
}效果展示:
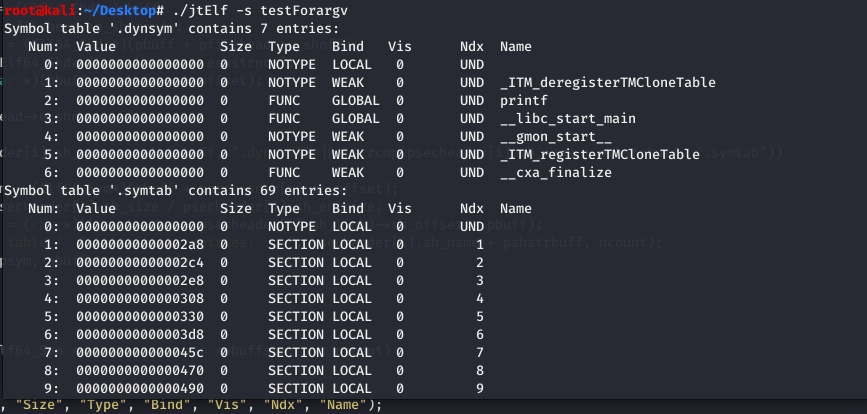
readelf 对比:
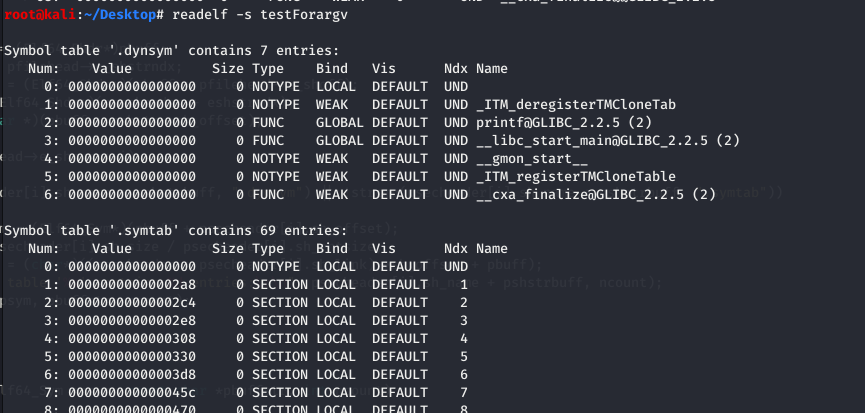
参数解释:
STT_NOTYPE:符号类型未定义。
STT_FUNC:表示该符号与函数或者其他可执行代码关联。
STT_OBJECT:表示该符号与数据目标文件关联。
符号绑定:
STB_LOCAL:本地符号在目标文件之外是不可见的,目标文件包含了符号的定义,如一个声明为 static 的函数。
STB_GLOBAL:全局符号对于所有要合并的目标文件来说都是可见的。一个全局符号在一个文件中进行定义后,另外一个文件可以对这个符号进行引用。
STB_WEAK:与全局绑定类似,不过比 STB_GLOBAL 的优先级低。被标记为 STB_WEAK 的符号有可能会被同名的未被标记为 STB_WEAK的符号覆盖。
下面是对绑定和类型字段进行打包和解包的宏指令。
ELF32_ST_BIND(info) 或者 ELF64_ST_BIND(info):从 st_info 值中提取出一个绑定。
ELF32_ST_TYPE(info) 或者 ELF64_ST_TYPE(info):从 st_info 值中提取类型。
ELF32_ST_TYPE(bind,type) 或者 ELF64_ST_INFO(bind,type):将一个绑定和类型转换成 st_info 值。
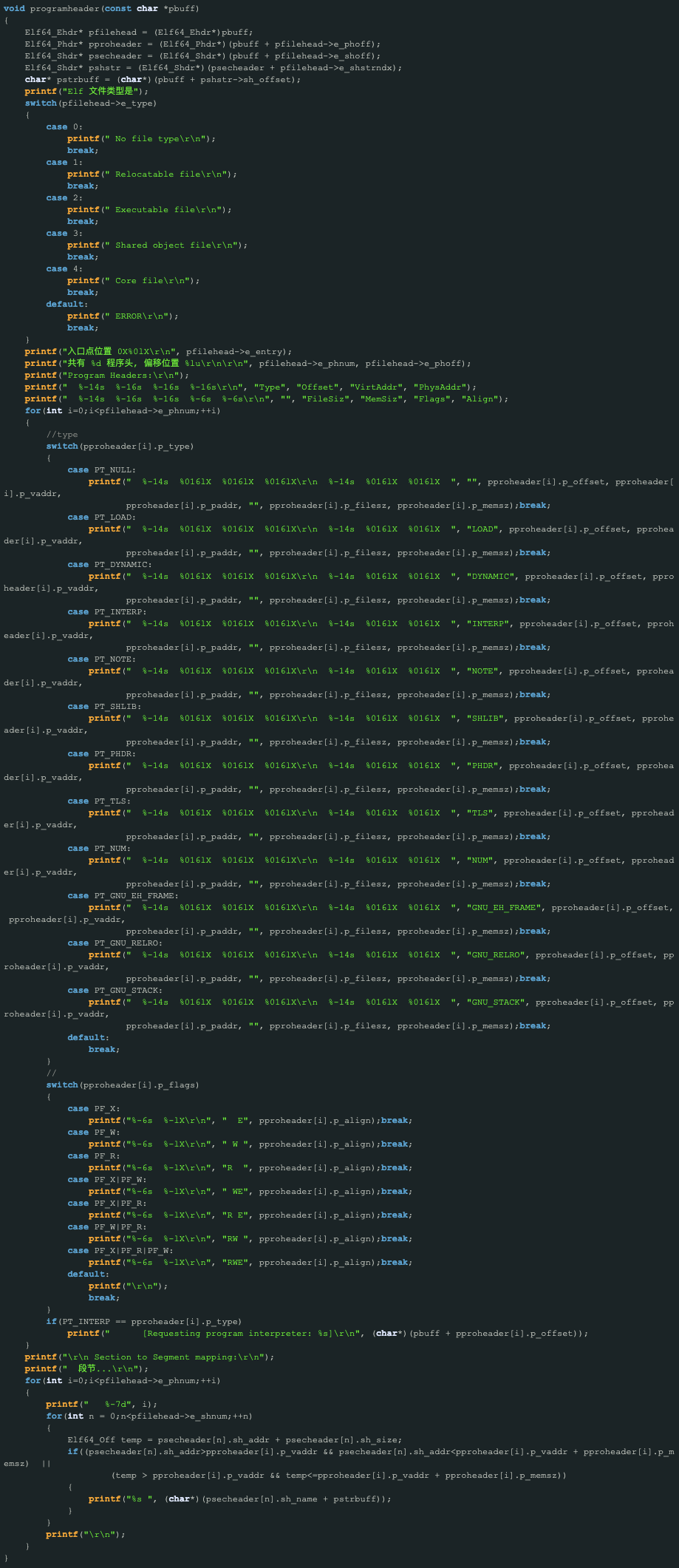
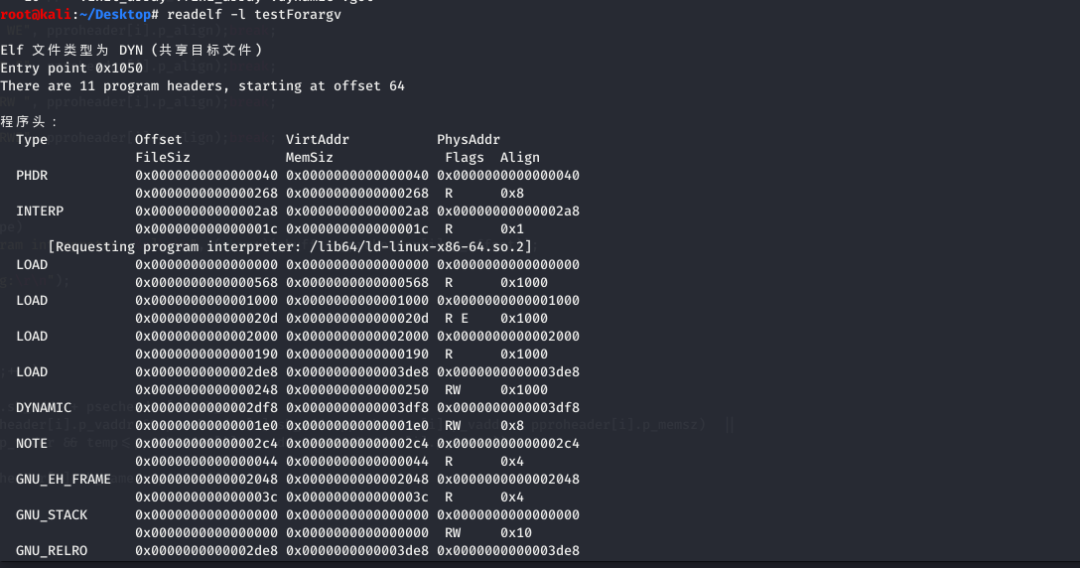
4. -l 指令 program头信息。
程序头表与段表互相独立,有 ELF 文件头同一管理。
结构信息:
typedef struct {
Elf32_Word p_type; //此数组元素描述的段的类型,或者如何解释此数组元素的信息。
Elf32_Off p_offset; //此成员给出从文件头到该段第一个字节的偏移
Elf32_Addr p_vaddr; //此成员给出段的第一个字节将被放到内存中的虚拟地址
Elf32_Addr p_paddr; //此成员仅用于与物理地址相关的系统中。System V忽略所有应用程序的物理地址信息。
Elf32_Word p_filesz; //此成员给出段在文件映像中所占的字节数。可以为0。
Elf32_Word p_memsz; //此成员给出段在内存映像中占用的字节数。可以为0。
Elf32_Word p_flags; //此成员给出与段相关的标志。
Elf32_Word p_align; //此成员给出段在文件中和内存中如何对齐。
} Elf32_phdr;参数解释:
(1) p_type表示当前描述的段的种类。常见有以下常数。
#define PT_NULL 0 //空段
#define PT_LOAD 1 //可装载段
#define PT_DYNAMIC 2 //表示该段包含了用于动态连接器的信息
#define PT_INTERP 3 //表示当前段指定了用于动态连接的程序解释器,通常是ld-linux.so
#define PT_NOTE 4 //该段包含有专有的编译器信息
#define PT_SHLIB 5 //该段包含有共享库(2) p_offset给出了该段在二进制文件中的偏移量,单位为字节。
(3) p_vaddr给出了该段需要映射到进程虚拟地址空间中的位置。
(4) p_paddr在只支持物理寻址,不支持虚拟寻址的系统当中才使用。
(5) p_filesz给出了该段在二进制文件当中的长度,单位为字节。
(6) p_memsz给出了段在虚拟地址空间当中的长度,单位为字节。与p_filesz不等时会通过截断数据或者以0填充的方式处理。
(7) p_flags保存了标志信息,定义了该段的访问权限。有如下值
#define PF_R 0x4 //该段可读
#define PF_W 0x2 //该段可写
#define PF_X 0x1 //该段可执行(8) p_align指定了段在内存和二进制文件当中的对齐方式,即p_offset和p_vaddr必须是p_align的整数倍。
设计代码:
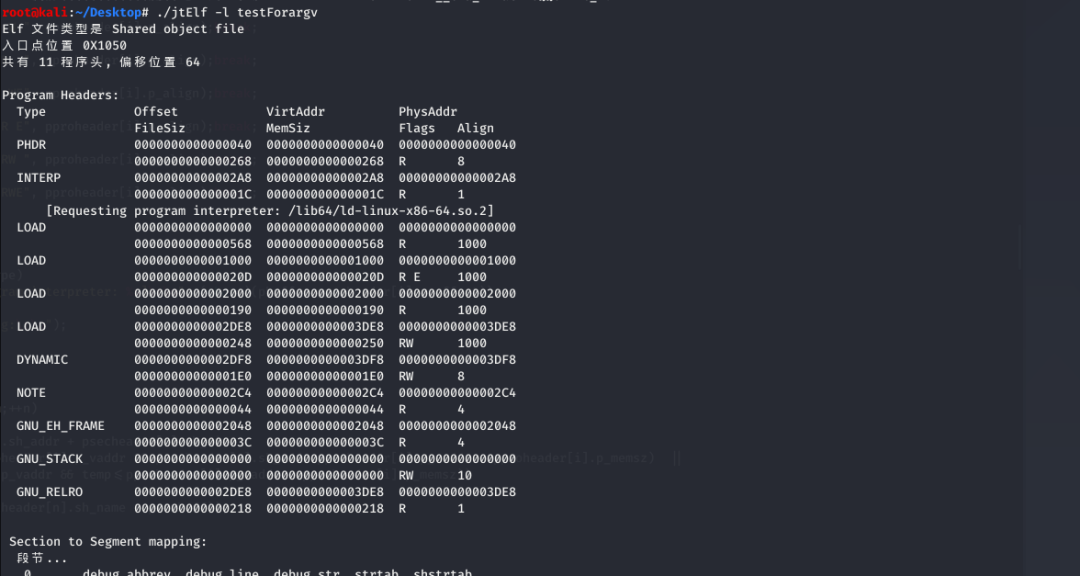
readelf对比:
最后还有一个重定位表的打印函数,暂时不介绍了。