深度解析:分布式存储系统实现快照隔离的常见时钟方案
前 言
随着互联网的快速发展以及全球互联网巨头的崛起,Google、Facebook、Twitter 等作为世界性的跨国跨洲互联网公司,对存储的数据的跨洲扩展、一致性、存储、容灾和可用提出了更高的要求,为了解决上面这些问题,业界出现了很多全球分布式系统的快照隔离解决方案。其中,因为 Snapshot Isolation 能解决大多分布式存储系统中的读写不一致异常、具有良好的性能且易于实现,被众多的分布式存储所采用。
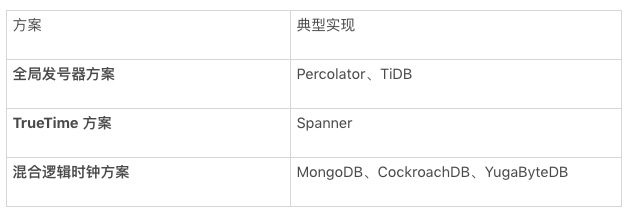
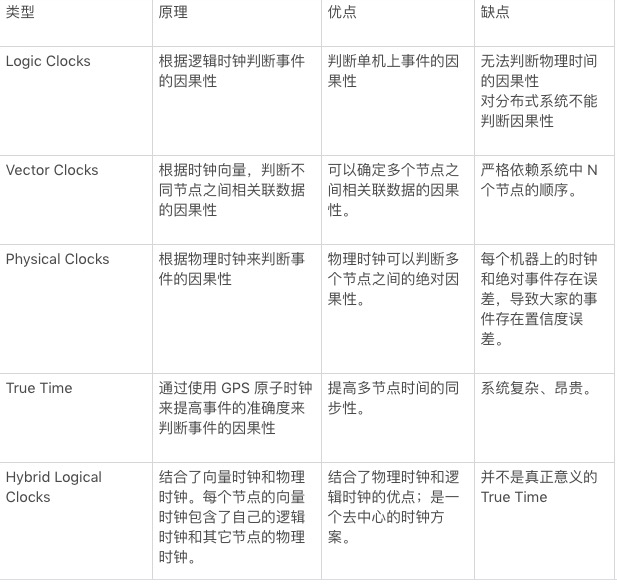
通常实现 Snapshot Isolation 的时钟方案有三大类:全局发号器方案、TrueTime 方案和混合逻辑时钟方案。其中,Percolator 和 TiDB 采用了全局发号器方案;Spanner 率先提出和使用了基于原子时钟和 GPS 构建的 TrueTime 方案;MongoDB、CockroachDB 和 YugaByteDB 采用了基于混合逻辑时钟方案。下表中简单列举了三种方案的典型实现:
隔离级别
数据库中的事务包含了 ACID 四个特性,A(Atomicity)是原子性、C(Consistency)是一致性、I(Isolation)是隔离性、D(Durability)是持久性。其中 ACD 三个特性相对容易理解,而隔离性指的就是数据库在并发事务下的表现。
通常传统关系型数据库中定义了 4 种隔离级别:读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)、可串行化(Serializable)。上面提出的隔离级别都是为了解决事务并发情况下存在的:脏写(Dirty Write)、脏读(Dirty Read)、不可重复读(Non-Repeatable Read)、幻读(Phantom)、更新丢失(Lost Update)、游标丢失更新(Cursor Lost Update)、读偏序(Read Skew)和写偏序(Write Skew)等异常。
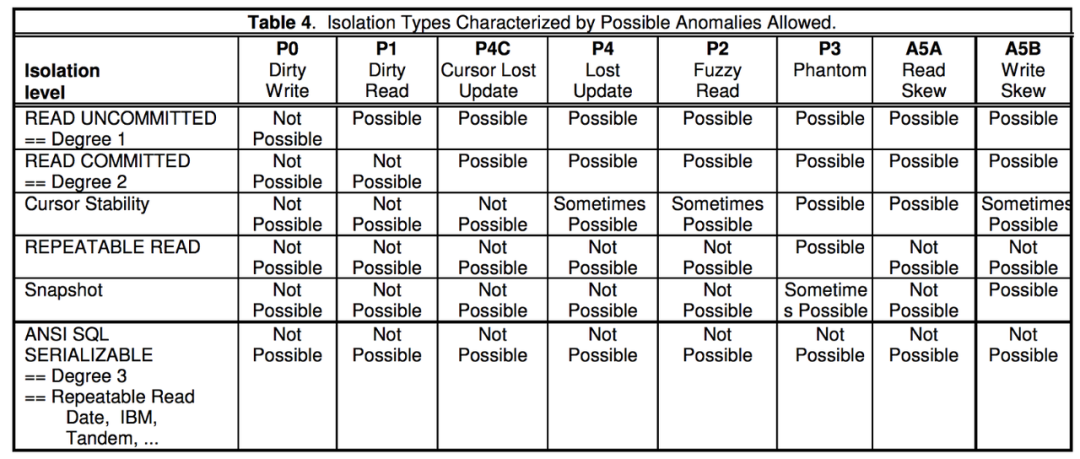
如上表,横向定义了 P0、P1、P4C、P4、P2、P3、A5A 和 A5B 八种导致读写不一致的情况,纵向定义了 Read Uncommitted、Read Committed、Curosr Stablity、Repeatable Read、Snaphot、Serializable 六种隔离级别,其中每种隔离级别可以解决若干种读写不一致的问题。如果严格实现了 Serializable 的隔离级别,就可以解决上述八种读写不一致的异常。
读写异常
下面详细介绍和分析了各种常见的读写异常(引自:https://blog.acolyer.org/2016/02/24/a-critique-of-ansi-sql-isolation-levels/ )。
P0: Dirty Write
当一个事务覆盖另一个正在运行的事务先前写入的值时,我们称这种现象为脏写。
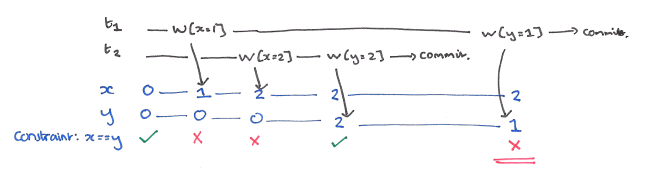
如上图:假定事务 T1 写入 x=1 和 y = 1,同时有并发执行的事务 T2 写入 x= 2 和 y = 2。最后当 T1 和 T2 都提交后,x = 2 但是 y = 1,这时就称为发生了脏写。
P1: Dirty Read
当一个事务 T1 能读取到另一个未提交事务 T2 写入的值时,就称为脏读。这里不论 T2 最终状态是被提交还是被回滚,只要在 T2 未结束的时候 T1 就读到了 T2 写的值,就是脏读。
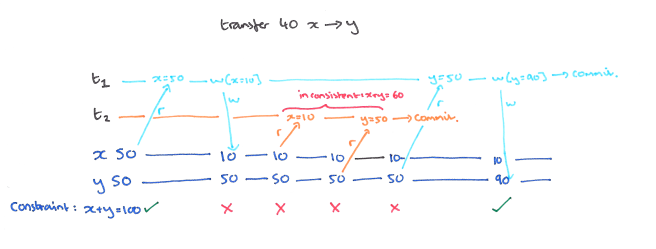
如下图,x 和 y 最开始值都为 50,并具有完整性约束,即 x + y = 100。现在需要从 x 转移 40 到 y,事务 T2 从 x 读取值为 50,扣除 40 后将 x = 10 写入数据库。这时事务 T1 读取 x = 10 和 y = 50,这时在事务 T1 看来,x + y = 60,其和不为 100,违背了一致性约束。
P2: Fuzzy Read
当进行中的事务 T1 读取到的值被另一个事务 T2 写的新值覆盖,并且新值在 T1 可见时,我们称发生了 Fuzzy Read(模糊读)或者 Non-Repeatable Read(不可重复读)。即使 T1 没有真正读取 T2 写入的新值,仍然可能导致违反数据库一致性约束。
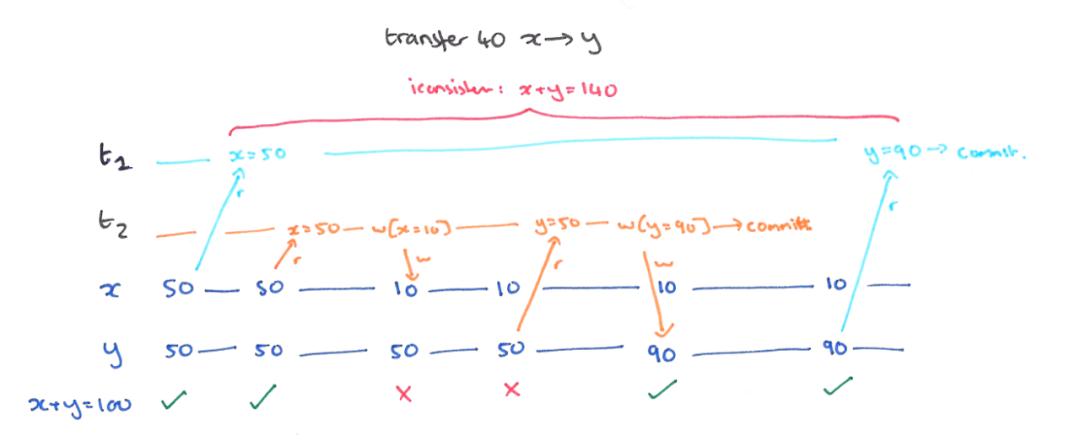
如下图,x 和 y 最开始值都为 50,并具有完整性约束,即 x + y = 100,现在仍需要从 x 转移 40 到 y。
事务 T1 开始读取 x = 50,同时并发执行了事务 T2。事务 T2 先后读取了 x 和 y 值,并将 x = 10,y = 90 写回了数据库。然后事务 T1 继续执行,读取了 y = 90,这时在事务 T2 看来,x + y = 140,同样违背了一致性约束。
P3: Phantom
当事务 T1 执行了基于谓词的读取(例如 SELECT…WHERE P),另外一个并发执行事务 T2 写入(删除、更新)与该谓词相匹配的数据项并在 T1 可见,我们称这种情况为幻读。
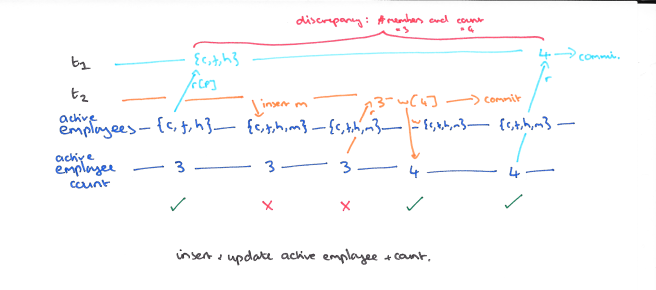
如下图:事务 T1 最开始读取了三个值分别为 {c,f,h},同时 T2 由插入了 m,这时数据库中的值为 {c,f,h,m}。然后事务 T1 再次读取了数据的 count 为 4,这时发生了异常。
P4: Lost Update
当事务 T1 读取一个数据项然后 T2 更新该数据项,然后 T1(基于 T2 更新前的读取值)更新该数据项并提交时,就会发生丢失更新异常。
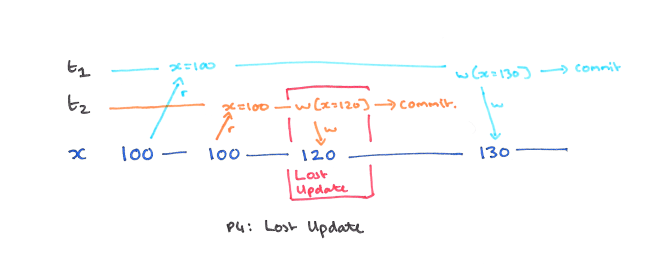
如上图:事务 T1 和 事务 T2 读取了 x = 100,事务 t2 将 x = 120 写回数据库。然后事务 T1 又将 x = 130 写回了数据库,在事务 T2 看来,自己的更新 x = 120 丢失了。
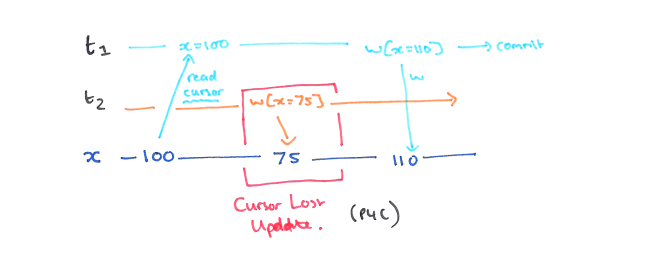
P4C: Cursor Lost Update
Cursor Lost Update 是 Lost Update 的一种变种,只是这里的 read 是又游标读取的。
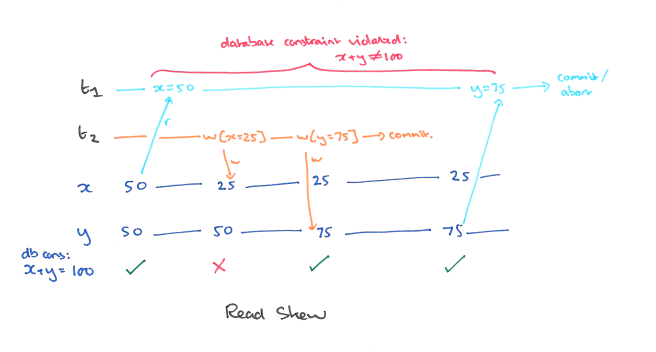
A5A: Read Skew
当两个或多个数据项之间存在完整性约束时,可能会发生 Read Skew(读偏序)。
如下图,有一致性约束 x + y = 100。事务 T1 首先读取 x = 50,同时事务 T2 写入了 x = 25 和 y = 75。然后事务 T1 继续读取了 x = 75。这时 x + y = 125,违背了一致性约束。
A5B: Write Skew
写偏斜和读偏序非常相似,只是数据库中的值违背了一致性约束。假设我们的约束是 x + y≤100。
如下图,事务 T1 读取了 x = 30,并将 y = 60 写入了数据库,事务 T2 读取了 y = 10,并将 x = 50 写回了数据库。此时数据库中 x + y = 110,违背了一致性约束。

快照隔离
1995 年 Hal Berenson 等人在《A critique of ANSI SQL Isolation levels》中提出了 Snapshot Isolation 的概念。在 Snapshot Isolation 隔离级别中,不会发生的读写异常为 P0 (Dirty Write)、P1 (Dirty Read)、P2 (Fuzzy Read)、P4 (Lost Update)、P4C (Cursor Lost Update)、A5A (Read skew),但是有可能会发生 P3(Phantom)、A5B(Write Skew)。
文章中给出了实现 Snapshot Isolation 的一般方案:
- 事务的读操作从 Committed 快照中读取数据,快照时间可以是事务的第一次读操作之前的任意时间,记为StartTimestamp。
- 事务准备提交时,获取一个CommitTimestamp,它需要比现存的StartTimestamp和CommitTimestamp都大。
- 事务提交时进行冲突检查,如果没有其它事务在[StartTS, CommitTS]区间内提交了与自己的 WriteSet 有交集的数据,则本事务可以提交;这里阻止了 Lost Update 异常。
- SI 允许事务用很旧的StartTS来执行,从而不被任何的写操作阻塞,或者读一个历史数据;当然,如果用一个很旧的CommitTS提交,大概率是会 Abort 的。
从上面的方案来看,核心都是需要一个递增序列号来实现 StartTS 和 CommitTS ,而分布式存储系统为了实现递增序列号通常有两种方案:全局发号器和时钟,由于在分布式系统中不存在绝对的时间一致,因此分化出两种方案:绝对时间 和 相对时间,其中绝对时间的方案主要是 Google 的 TrueTime 方案,而相对时间包含了物理时钟(Physical Clocks)、逻辑时钟(Logic Clocks)、向量时钟(Vector Clocks)、混合逻辑时钟(Hybrid Logic Clocks)等方案。
全局发号器
核心原理
全局发号器方案通过一个全局的授时服务器来生成严格单调递增的时间戳,因为所有的时间戳来自同一个全局的授时服务器,因此所有的时间戳存在严格的先后顺序。依据此特性,我们可以对系统中所有的并发事务进行严格定序,然后就可以用来实现严格的快照隔离。
Percolator 论文中将全局的授时服务器称为 TSO (Timestamp Oracle)。TSO 有实现简单、严格定序、性能好等优点,因此很多分布式系统采用了 TSO 作为时钟方案。不过 TSO 并不完美,也存在一些问题:
- 首先是单点故障,整个系统依赖 TSO 的高可用,这个问题可以通过多副本来降低不可用时间。常规的方案比如基于 Paxos / Raft 等共识协议构建 TSO 服务,但一旦发生网络分区就可能会触发重新选主,重新选主的期间依然是不用的。
- 其次是延迟问题,获取时间戳需要客户端和 TSO 进行 RPC 交互。如果客户端和 TSO 不在一个机房,延迟就会比较高,如果是全球化跨数据中心部署,问题会更加严重。这个问题并没有什么方案可以缓解,只能使用 TrueTime 或者 HLC 等其他时钟方案。
典型实现
- Percolator
Percolator 是典型使用 TSO 的系统,这里简单介绍下它的实现。因为每个事务都需要和 TSO 交互两次(开始事务获取 StartTs,提交事务获取 CommitTs),所以 TSO 的拓展性必须要好。Percolator 中 TSO 的实现方法是定期分配出一组连续递增的时间戳,并把其中最大的时间戳写到持久存储里,之后客户端获取时间戳时只需要从内存里分配就可以了,直到这组用完了再重新分配一组出来。如果 TSO 发生重启,会直接跳到持久存储中记录的时间戳开始继续分配,保证时间戳严格增加,不能回退。
为了减少 RPC 的开销,每个客户端会通过 Batch 在一次 RPC 中同时获取多个时间戳,当并发的事务越多,Batch 就越大,就越能降低 RPC 的开销。Percolator 的 TSO 每秒发号的速度在每秒 200 万,不会构成性能瓶颈。
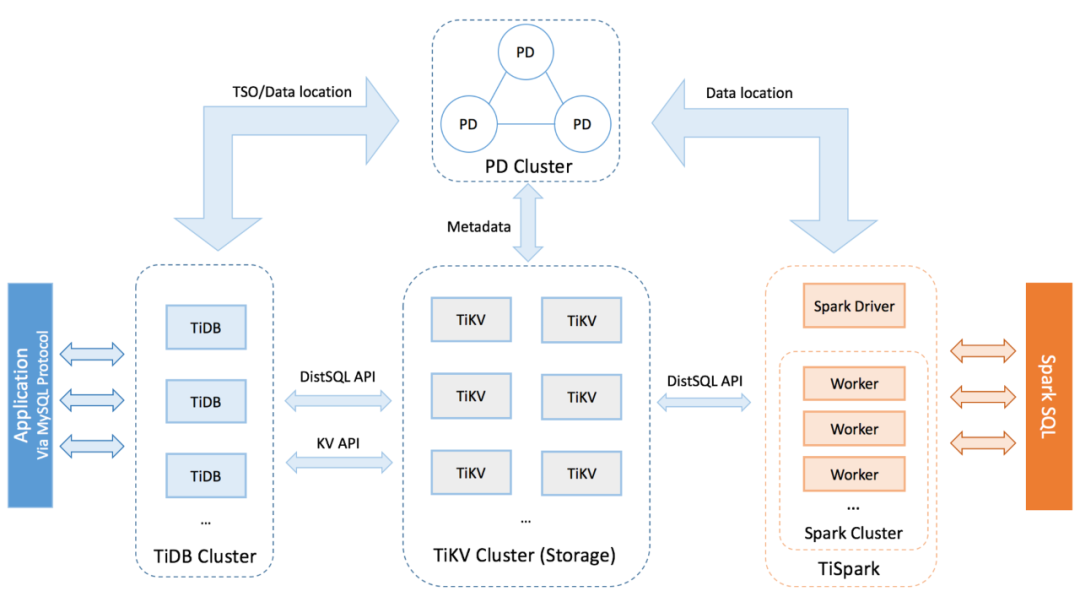
TiDB
TiDB 是一款定位于在线事务处理 / 在线分析处理( HTAP: Hybrid Transactional/Analytical Processing)的融合型数据库产品,实现了一键水平伸缩,线性一致性的多副本数据安全,分布式事务,实时 OLAP 等重要特性。同时兼容 MySQL 协议和生态,迁移便捷,运维成本极低。
TiDB 采用了 Percolator 相似的方案,采用集中式的服务 TSO 来获取全局一致的版本号,并保证事务版本号的单调递增。如下图所示,TSO 模块位于 TiDB 全局中心总控节点 PD 中,PD 通过集成了 ETCD 保证了持久化数据的强一致性并且可以做到 Auto Failover,因此可以解决集中式服务带来的单点故障问题。
TrueTime
TrueTime 是 Google 在 Spanner 论文中提出的方案,Spanner 中虽然使用了很多类似 2PL、2PC、Paxos 等核心技术,但 TrueTime API 的提出才是论文中最有价值的部分。TrueTime 是基于 GPS 和原子钟实现的,它能将各数据节点的时间误差缩小并控制在 7ms 以内。全球分布式数据库对时间要求很高,假如不同地区的数据节点时间不一致,会造成数据一致性、恢复等问题。传统的 NTP 时间同步由于不太可靠,因此很少被分布式存储系统采用。逻辑时钟(如 Lamport 时钟、向量时钟)又有因果顺序、通信开销等问题,所以 Google 采用了基于 GPS 和原子钟构建的 True Time API 来解决全球跨洲、跨地区分布式节点时间同步问题。
核心原理
在分布式系统中,由于每台机器产生的时间戳完全不同,并且时钟增长的速度也不同,会导致每台机器从自身读取的时间戳无法用于对事件的定序。在不想引入中心时间戳服务器的场景下,我们可以通过 NTP 服务不断地校准每台机器的时间,但是一般的机房使用的时钟源理论误差上限比较大 ,很难用于对事件的定序。
在 Google Spanner 论文中,提出了基于 GPS 和原子钟两个时钟源的 TrueTime 方案,该方案能够在理论上保证时钟的误差范围很小,而机器的时钟漂移速度也是有界的。在这些已知前提下,我们可以在分布式系统中对不确定的时间通过一定的等待来消除时间的误差。

上表中表示的是 TrueTime 提供的 API,TrueTime 会把时间表示为 TTinterval,TTinterval 是一个时间区间。earliest 和 latest 表示了当前绝对时间以及不确定性误差,比如执行 tt = TT.now(),那么 TrueTime 能够保证 tt.earliest <= Tabs(now) <= tt.latest。
事务在选择 ts 时,会选择不小于 TT.now().latest 的一个时间戳 s 作为事务时间戳,并一直等待直至 TT.now().earliest 不小于 s,这样就能保证绝对时间已经超过了 s,这样既可对事务进行定序。当然由于 Spanner 是分布式事务,会综合多台机器上数据写入的时间戳来选取最终事务提交的时间戳,不过是类似的,不再赘述。
典型实现
TrueTime 是由每个数据中心里一组称为 Time-Master 的机器和数据中心所有机器上的 Time-Slave daemon 来结合实现的。大多数 Time-Master 都有具备专用天线的 GPS 接收器,同时 Master 在物理上是相互隔离的,这样可以减少 Master 之间的相互影响。部分 Master(我们称为 Armageddon Master)则配备了原子钟。所有 Master 的时间参考值都会进行彼此校对。每个 Master 也会交叉检查时间参考值和本地时间的比值,如果二者差别太大,就会把自己驱逐出去。在同步期间,Armageddon Master 会表现出一个逐渐增加的时间不确定性,这是由保守应用的最差时钟漂移引起的。GPS Master 表现出的时间不确定性几乎接近于 0。
每台机器的 Time-Slave daemon 会从多个 Time-Master 获取时间,从而减少单个 Master 带来的误差。这些 Master 中,既有 GPS Master,又有 Armageddon Master,其中 GPS Master 分别分布在当前数据中心和临近数据中心中。Time-Slave daemon 会使用一种 Marzullo 算法的变种算法,来获取一个比较真实的时间。同时,会将 Marzullo 算法计算出来的时间和本地时钟进行对比,如果机器的本地时钟误差频繁超出这个界限,这个机器就会被驱逐出去。
在两次时钟同步期间,slave daemon 会逐渐增加的时间的不确定性。这里用ε来表示时间的不确定性,它是整个集群中最大时钟漂移。ε也会被 Time-Master 的时间不确定性,以及 slave deamon 与 Time-Master 之间的通讯延迟所影响。在 Google 的线上应用环境中,ε的值通常是一个的锯齿形函数。在两次时钟同步间隔中,ε会在 1 到 7ms 之间变化。因此,在大多数情况下,ε的平均值是 4ms。slave daemon 的同步间隔,在当前是 30 秒,当前使用的时钟漂移比率是 200 微秒 / 秒,二者一起意味着 0 到 6ms 的锯齿形函数。剩余的 1ms 主要来自到 Time-Master 的通讯延迟。在某些及其糟糕情况下,ε超过锯齿形边界也是有可能的。例如,某些时候 Time-Master 不确定性,可能会引起整个数据中心范围内的ε值的增加。类似的,过载的机器或者网络连接,都会导致ε值偶尔地局部增大。
混合逻辑时钟
混合逻辑时钟(HLC,Hyper Logic Clocks)是结合了逻辑时钟(Logical Clocks)和物理时钟(Physical Clocks)。在混合逻辑时钟提出之前,对于时钟主要有物理时钟和逻辑时钟两种。混合逻辑时钟结合了两者的优势,既能够对有因果关系的事件定序,并且能够对分布式系统获取快照。
核心原理
HLC 的设计思想是结合物理时钟和逻辑时钟的优点。物理时钟与物理世界有紧密的联系,逻辑时钟能够对有因果的事件定序,因此 HLC 需要满足以下要求:
- 若事件e先行发生于f,则有hlc.e < hlc.f。这个要求保留了逻辑时钟的因果序。
- 存储hlc.e需要的空间为 O(1),且值域有界。这个要求与向量时钟形成对比,向量时钟所需的存储空间是 O(n) 与进程数相关,HLC 则只需要常量个整数。
- hlc.e和pt.e的差值是有界的,这里的pt.e代表 e 时间发生机器上的物理时钟。这个要求则保留了物理时钟与物理世界的联系,要求 HLC 与物理时间足够接近。
典型实现
CockroachDB 是一款开源的分布式数据库,具有 NoSQL 对海量数据的存储管理能力,又保持了传统数据库支持的 ACID 和 SQL 等,还支持跨地域、去中心、高并发、多副本强一致和高可用等特性。支持 OLTP 场景,同时支持轻量级 OLAP 场景。
CockroachDB 在每个事务启动时会在本地获取一个 HLC 时间hlc.e作为事务启动时间并携带一个节点之间物理时间偏差的上限MaxOffset(默认 500ms)。当事务消息发送到其它参与者节点后更新参与节点的本地 HLC 时间,和参与节点后续启动的事务产生关联关系「hb(happen before)关联关系」。
下图中时钟由 3 部分组成,分别是pt(当前机器的物理时钟)、l(hlc 的物理部分)、c(hlc. 的逻辑部分)。
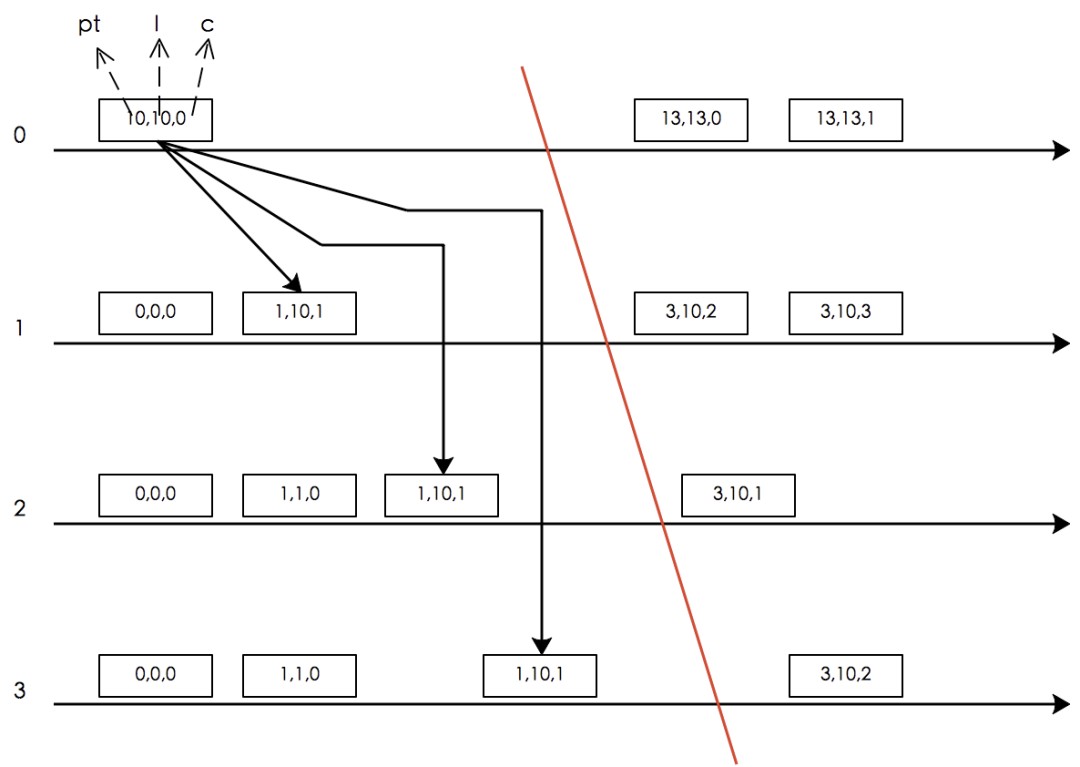
下面我们根据上图来分析 CockroachDB 如何实现 Snapshot Read。假定存在假设:当前物理时间pt.e+MaxOffset一定是当前系统的最大时间,发生在pt.e+MaxOffset之后的事务的物理时间一定大于当前事务(根据 NTP 时间同步特性ε ≥ |ptnode1 – ptnode2|得出该假设成立,ε代表集群中最大时钟漂移,也就是MaxOffset),CockroachDB 启动事务e,根据 HLC 的特性ε ≥ |pt.e – l.e| ,可得推论:任意时刻当前集群的整体物理时间不可能超过hlc.e+MaxOffset。那么当 CockroachDB 执行 Snapshot Read 的时候有:
1. 若事务g满足hlc.e + MaxOffset < hlc.g。根据 HLC 算法的特性 2(对任一事件e,一定有l.e ≥ pt.e),可得出:pt.e < pt.g,e hb g,事务e发生在g之前。
2. 若事务g满足hlc.e < hlc.g <= hlc.e + MaxOffset,那么此时事务e陷入一个叫 Uncertain Read 的状态,意思是不确定事务g的物理时间pt.g一定大于 pt.e。例如:
- hlc.e=(10,10,2),hlc.g=(11,11,0),假设MaxOffset=5,此时hlc.g > hlc.e,但是pt.g > pt.e。
- hlc.e=(10,10,2),hlc.g=(9,11,0),假设MaxOffset=5,此时hlc.g > hlc.e,但是pt.g < pt.e。
3. 在这种两种情况下 CockroachDB 无法获得一致的 Snapshot,因此当前事务e必须 Restart 并等待时间足够长之后,获取一个新的时间戳 hlc.g +1 重新执行。
若事务g满足hlc.g < hlc.e, 那么根据 HLC 算法的 Snapshot Read,事务e可以直接执行 Snapshot Read。
存在的问题
CockroachDB 虽然实现了 Serializable,但是并没有实现 Linearizable,严格来说并不是 Strict Serializable。例如下面这个例子,存在三个事务:
T1:insert into hacker_news_comments (id, parent_id, text) values (1, NULL, 'a root comment')
T2:insert into hacker_news_comments (id, parent_id, text) values (2, 1, 'OP is wrong')
T3:select id, text from comments同时存在三个进程 A、B、C。考虑以下时序:
1、进程 A 执行了 T1,在拿到返回结果前
2、进程 A 通知进程 B 执行了 T2,在 T1 和 T2 拿到返回结果前
3、进程 A 和进程 B 通知进程 C 执行了 T3在 CockroachDB 的实现中,T3 可能返回了 T2 插入的值,但是并没有返回 T1 插入的值。根据线性一致性的描述,T1 先于 T2 发生,因此需要先读到 T1 的结果再读到 T2 的结果,不可能出现只读到 T2 的结果没有读到 T1 的结果。
总 结
在分布式数据库存在事务并发的情况下,数据的读写一致性是一个很复杂的问题。从 Google 的 Percolator 方案,再到 Google 在 Spanner 中使用的 TrueTime 方案,以及其它分布式数据库中使用的混合时钟方案以及加强版混合时钟方案,代表了目前业界目前三种主要方案。其中 Percolator 使用的全局发号器方案存在单点问题以及全球数据库情况下延迟大等问题;Spanner 虽然实现了全球范围的分布式数据库方案,TrueTime 使用基于原子时钟和 GPS 的 TrueTime 时间方案,不是业界其它公司的数据库解决方案可以企及的;而混合逻辑时钟方案虽然不能实现严格的串行化并解决所有的读写一致性异常,但仍然是目前分布式存储系统使用较多的方案。
引用:
- https://blog.acolyer.org/2016/02/24/a-critique-of-ansi-sql-isolation-levels/
- Logical Physical Clocks and Consistent Snapshots in Globally Distributed Databases
- http://mysql.taobao.org/monthly/2019/02/03/
- http://www.cockroachchina.cn/?p=976
- https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-95-51.pdf
- https://www.cockroachlabs.com/blog/consistency-model/
- Keith Marzullo and Susan Owicki. “Maintaining the time in a distributed system”. Proc. of PODC. 1983, pp. 295–305.
- http://dblab.xmu.edu.cn/post/google-spanner/
作者介绍:
-
王林强,2016 年 3 月 -2018 年 10 月在微信支付从事后台开发,主要参与支付系统相关特性开发和支付系统可用性治理工作;2018 年 10 月 - 至今就职于字节跳动,参与了存储项目开发和支付项目的开发。作者主要兴趣在分布式一致性、分布式事务、分布式存储系统、海量交易系统架构和高可用、区块链 和数字货币等,并参与过分布式存储系统和海量交易系统的开发和可用性治理。 陈超,2018 年 6 月至今就职于字节跳动,参与了分布式图数据库开发。作者主要兴趣在分布式一致性、分布式事务、分布式存储系统。 李磊,2018 年 7 月至今就职于字条跳动,参与分布式图数据库和分布式图计算系统的研发。作者主要兴趣在分布式一致性、分布式事务、分布式存储系统。
-