认识布隆过滤器
什么是布隆过滤器
布隆过滤器本质上是一种概率型的数据结构,用于检索一个元素是否在集合中,它将告诉你一个数据“一定不存在或可能存在。
布隆过滤器由一个很长的二进制向量(位向量、位数组、Bit Array)和一系列的随机映射函数组成。
布隆过滤器的优点是高效、占用空间少。但缺点是返回的结果是概率性的,而不是准确的。
对布隆过滤器有了一个简单的印象之后,接下来就要继续深入。
如何判断一个元素是否在一个集合中
如果想要判断一个元素是否在一个集合中,首先想到的就是将所有元素保存起来,然后通过比较确定。在链表、树等数据结构中就是这样的思想。但是随着集合越来越大,检索速度就会越来越慢。
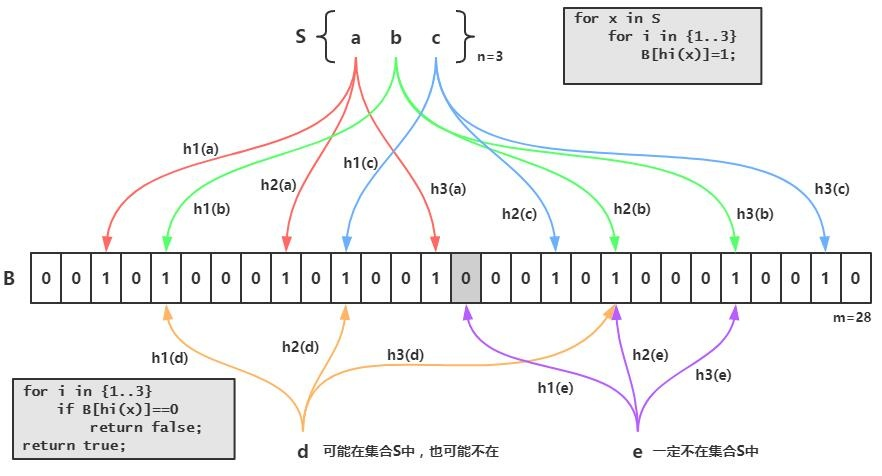
这时有一个更优的方案。使用一个映射函数将一个元素映射成一个位数组(Bit Array)中的一个点。当我们查找的时候,如果元素不存在,则对应位置为0,如果存在,那么该位置就为 1。

一个长度16的位数组,现在添加一个数据m,通过一个哈希函数,计算出该数据的位置,Hash(m)=5,然后下标为5的位置置为1。

但是哈希表也是有问题存在的,Hash面临的问题就是冲突。例如,假设Hash函数是良好的,想将冲突率降低到百分之一,那么位数组长度为m的哈希表就只能存储m/100个元素,显然浪费了很多的空间。
解决办法就是使用多个Hash函数,也就是布隆过滤器。如果有一个Hash说元素不在集合中,那肯定就不在;但是如果所有的Hash都说在,元素却不一定在里边。
我们通过一张图来表示出布隆过滤器是一个不确切的数据结构。
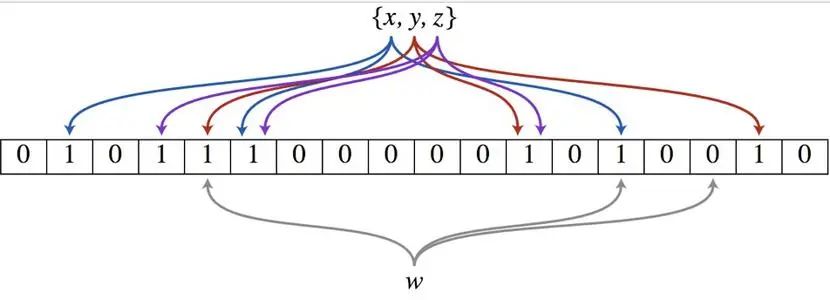
我们通过三个Hash函数分别将x,y,z存储到这个位数组中,将9个位置为1。当检索一个不存在于这个布隆过滤器中的元素w时,给出的结果却是w存在于该布隆过滤器中。
造成这种问题的原因是,布隆过滤器存在一定的误报率。随着存储的元素越来越多,置为1的位越来越多,就会导致了后边存储的元素要置为1的位置已经是1了。
为了避免或减少这种问题,我们需要选择合适的哈希函数的个数和布隆过滤器的长度。
Hash函数的个数太多,会导致布隆过滤器bit为置1 的速度过快;太少会导致误报率变高。
布隆过滤器的长度太小,会导致所有的bit为很快被置为1,直接结果就是查询任何数据的结果都是“可能存在”,也就是误报率过高。
对于布隆过滤器的bit位数m,插入元素数量n,误报率p,哈希函数个数k,我们可以使用以下的公式在决定哈希函数个数和布隆过滤器长度。
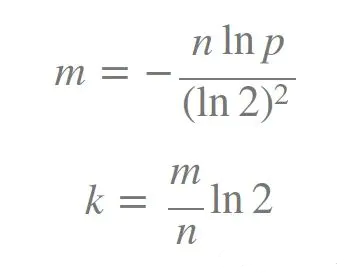
布隆过滤器的使用场景
根据布隆过滤器的特点,有以下的应用场景:
1、判定给定数据是否存在。
2、爬虫对于已经爬取过的url去重。
3、缓存穿透。
4、邮箱的垃圾邮件过滤、黑名单等。
正常流程缓存查询数据的流程是,依据key去查询value,数据查询前先进行缓存查询,如果缓存中不存在或者已经过期,再去数据库中查询,并将查询到的对象放入缓存中,如果数据库中为空,则查询失败。
缓存穿透是指,用户查询一个数据库中并不存在的数据。因为数据库中不存在该数据,缓存中也不会存在,这样就进行了两次无用的查询。
如果每次都查询一个没有value的key,缓存每次都不会命中,每次都会去数据库中查询数据,这样缓存失去了存在的意义还可能会对数据库造成影响。
布隆过滤器可以解决这一问题。将数据库中所有的查询条件放入布隆过滤器中,当收到一个查询请求时,先通过布隆过滤器,如果查询的值可能存在,那么在继续后边的查询;如果查询的值一定不存在,直接丢弃该请求,减少了对数据库的压力。