爬虫毕设(五):数据库相关
数据库存储
数据库可以结构化存储大量数据,同时还可以有效的保证数据的完整性、一致性,降低数据冗余。而且数据库还可以满足应用的共享和安全方面的要求,方便智能化地分析数据,产生新的有用的信息。
将数据存储到mysql数据库中需要下载pymysql库,然后再pipelines文件中进行数据处理。
声明一个pipeline类,在__init__()中初始化mysql数据库连接参数。
self.conn = pymysql.connect(user="root", db="douban_tv", password="w123456",
host="localhost", charset="utf8", use_unicode=True)
self.cursor = self.conn.cursor()在process_item()中将数据插入数据库中。
def process_item(self, item, spider):
insert_sql = """
insert into tv_tb(title, alias, url, tv_img, director, actors, tv_type, c_or_r, first_time, series, single, rate, votes_num, synopsis)
value(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
self.cursor.execute(insert_sql, (item["title"], item["alias"], item["url"], item["tv_img"],item["director"], item["actors"], item["tv_type"],item["country_or_region"], item["first_time"], item["series"],
item["single"], item["rate"], item["votes_num"], item["synopsis"]))
self.conn.commit()将pipeline在setting中启用。
ITEM_PIPELINES = {
'Spider.pipelines.SaveDBPipeline':301
}分布式爬虫
既然说到分布式,那就说一说分布式和集群的区别。
简单的来说,集群就是多个人同时做相同的事,而分布式就是将不同的任务分开,多个人做不同的事。
分布式爬虫,就是有一个调度器负责分配任务,多个爬虫获取到任务进行爬取。我们使用Redis的消息队列进行调度。
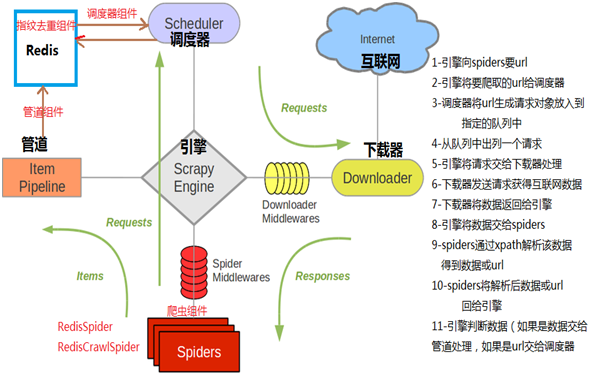
这张图就详细的解释了分布式爬虫是如何工作的。
实现分布式爬虫需要用到一个库scrapy-redis,由一个爬虫将所有的url存储到redis中,将url分配给其中一个爬虫后该url从redis中删除。
我们只需要将之前的爬虫略作修改,就变成了分布式爬虫。
将之前爬虫的第一层和第二层解析分离出来(parse和parse_detail)。
创建db_master`爬虫,将所有的url存储到redis中。
class db_master(scrapy.Spider):
name = 'db_master'
allow_domain = ["movie.douban.com"]
def __init__(self, *args, **kwargs):
super(db_master, self).__init__(*args, **kwargs)
self.start_urls = ["https://movie.douban.com/j/search_subjects?type=tv&tag=热门&sort=recommend&page_limit=20&page_start=0"]
def parse(self, response):
results = json.loads(response.body)['subjects']
for result in results:
item = db_masterItem()
url = result['url']
item['url'] = url.strip()
# print(url)
yield item在pipelines文件中加入数据处理。
import redis
class DoubanMasterPipeline(object):
def __init__(self):
# 初始化redis连接参数
self.REDIS_HOST = '127.0.0.1'
self.REDIS_PORT = '6379'
self.r = redis.Redis(host=self.REDIS_HOST, port=self.REDIS_PORT)
def process_item(self, item, spider):
# 向数据库中插入urls
self.r.lpush('douban:start_urls', item['url'])
return item在setting配置文件中启动DoubanMasterPipeline,运行爬虫,就会看到redis数据库中已经有了url。
然后再编写db_slaver爬虫,这个爬虫主要是原来爬虫的parse_detail,但有了一些不同。
首先,导入scrapy-redis,同时爬虫继承于RedisSpider。
# 爬虫继承于RedisSpider
class tvSpider(RedisSpider):
name = "db_slaver"
# start_urls注释掉,获取来源改为redis_key
redis_key = 'douban:start_urls'
# allowed_domain = ["movie.douban.com"]
# def __init__(self, *args, **kwargs):
# super(tvSpider, self).__init__(*args, **kwargs)
# # + str(x) for x in range(0, 60 ,20)
# self.start_urls = ["https://movie.douban.com/j/search_subjects?type=tv&tag=热门&sort=recommend&page_limit=20&page_start=0"]
# 动态获取域范围
def __init__(self, *args, **kwargs):
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
super(tvSpider, self).__init__(*args, **kwargs)
def parse(self, response):
pass最后在setting配置文件中配置一些新的东西。
# settings.py
# redis数据库连接参数
# 数据库连接参数
REDIS_HOST = '127.0.0.1'
REDIS_PORT = '6379'
REDIS_ENCODING = 'utf-8'
# 指定使用scrapy-redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 指定使用scrapy-redis的去重
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
# 默认的 按优先级排序(Scrapy默认),由sorted set实现的一种非FIFO、LIFO方式。
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
# 设置断点续传,也就是不清理redis queues,允许暂停,请求不丢失
SCHEDULER_PERSIST = True
#默认情况下,RFPDupeFilter只记录第一个重复请求。将DUPEFILTER_DEBUG设置为True会记录所有重复的请求。
DUPEFILTER_DEBUG =True在运行db_slaver爬虫,这次才是我们真正想要的数据,但是爬取完url时不会停止运行,而是会等待新的任务。
在平时的开发中,redis一般用于在web和数据库之间的缓存,这样可以提高web应用的性能。