爬虫毕设(四):多页爬取和数据持久化
多页爬取
上次说到电视剧的列表信息是通过Ajax网络请求获取到数据的,当我们打开页面的时候,页面再向另一地址发出请求,得到数据后再渲染到网页上,我们是在network中找到的目标url。所以说,当我们想要爬取第二页,第三页以后的内容所要请求的url都可以在network中找到。
我们请求的目标url是https://movie.douban.com/j/search_subjects?type=tv&tag=热门&sort=recommend&page_limit=20&page_start=0,很明显请求是带了几个参数的,在network中找到它。
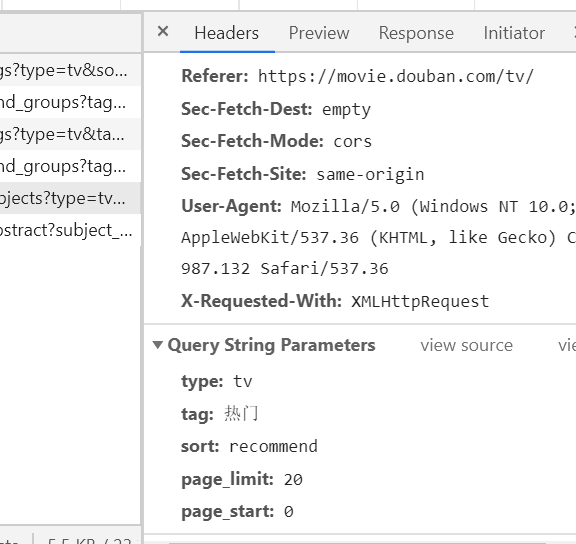
我们在请求头的参数里找到了,总共有五个参数,看字面意思很好理解:
- type:tv,我们爬取的是电视剧,所以是tv;
- tag:热门,我们选择的是
热门标签; - sort:排序,我们选择的是
recommend,按热度排序; - page_limit:页限制,每页的电视剧列表中含有20部电视剧;
- page_start:每页是从第几部电视剧开始的,这里是0,也就是从头开始。
根据对参数的分析,我们只需要改动最后一个参数就可以了,所以我们就有了思路,在一个整数列表里循环,得到0、20、40...然后再转换为字符串拼接的前边的字符串中:
str(x) for x in range(0, 60, 20)这里先爬取三页的做个示例,加入到__init__()中:
def __init__(self, *args, **kwargs):
super(tvSpider, self).__init__(*args, **kwargs)
self.start_urls = ["https://movie.douban.com/j/search_subjects?type=tv&tag=热门&sort=recommend&page_limit=20&page_start=" + str(x) for x in range(0, 60 ,20)]输入每页所有电视剧的url,运行结果:
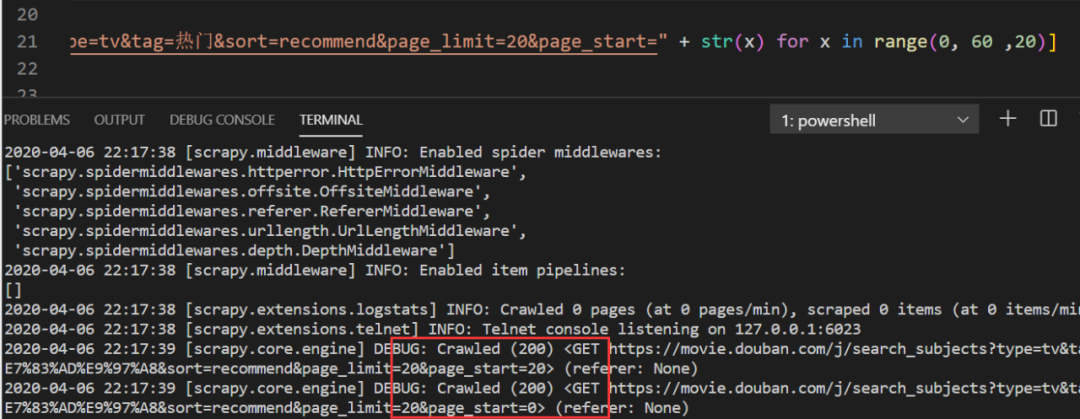
输出200,并且输出了60个url。然后注释掉打印url的代码,调用解析函数就可以了。
数据持久化
使用pipeline文件将数据持久化,存储到json文件,后期再存储到数据库中。
class tvSpiderPipeline(object):
def __init__(self):
# 打开文件,二进制写入
self.file = open('doubanTv.json', 'wb')
self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False)
self.exporter.start_exporting()
def close_spider(self, spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item将pipeline加入到settings文件中启用:
ITEM_PIPELINES = {
# 表示pipeline的优先级
'Spider.pipelines.tvSpiderPipeline': 300,
}运行以后,在文件夹中生成一个doubanTv.json的文件,打开文件并格式化,可以看到电视剧信息都以json格式写的整整齐齐。
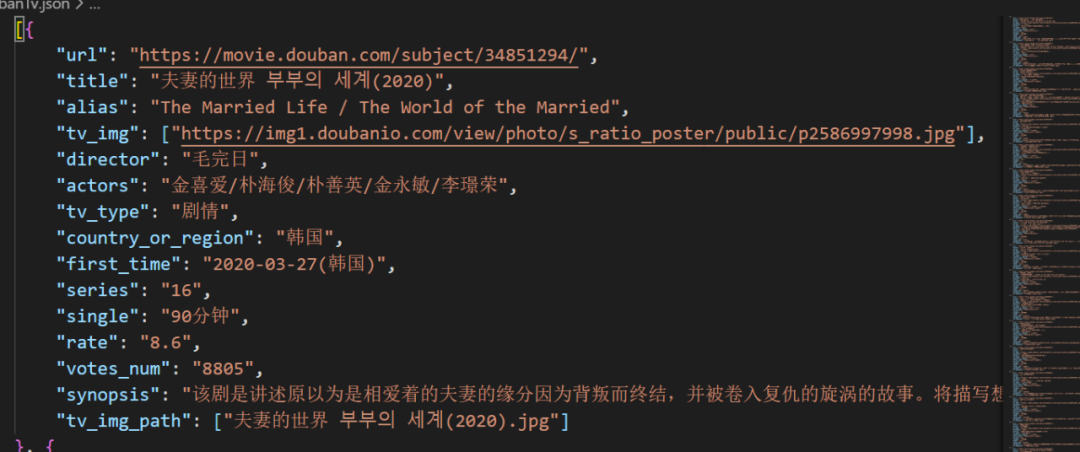
图片下载
图片下载只需要使用内置的ImagesPipeline就可以。
我们先写get_media_requests(名字不可以改)函数,对每个图片的url发送请求:
def get_media_requests(self, item, info):
for image_url in item['tv_img']:
# meta作为参数传给后边调用的函数
yield scrapy.Request(image_url, meta={ 'item': item })然后会自动调用item_completed函数,这个同样是不可以改名的:
def item_completed(self, results, item, info):
# 将下载的图片路径(传入到results中)存储到 image_paths 项目组中,如果其中没有图片,我们将丢弃项目:
tv_img_path = [x['path'] for ok, x in results if ok]
if not tv_img_path:
raise DropItem("Item contains no images")
item['tv_img_path'] = tv_img_path
return item这里有一个异常处理,如果没有图片,就丢弃掉这个item。
这时图片就可以下载了,但是图片的文件名都是哈希值,我们可以自定义文件名,这样我们可以方便的找到想要的图片:
def file_path(self, request, response=None, info=None):
# 图片名与网页中的一致
url = request.url
file_name = url.split('/')[-1]
# 使用剧名命名
# item = request.meta['item']
# title = item['title']
# url = request.url
# file_name = title + '.' + url.split('.')[-1]
return file_name这里写了两种方法,第一种方法是与网页中的文件名保持一致,只需要对url使用split()方法就可以。
第二种可以使用电影名作为文件名,但是文件名中含有中文韩文等字符,可能会在后续编码中出现一系列稀奇古怪的问题。(这种方法真的显得花里胡哨并且没有卵用,有部剧的名字太长导致该剧的信息被丢弃)

little tip:如果不对文件名做改变,可以使用哈希值作为文件名,哈希值是唯一的,可以验证图片,在后期可以做查重使用。
在pipelines.py文件中完成以后同样要在settings文件中启用:
# settings.py
ITEM_PIPELINES = {
'Spider.pipelines.tvSpiderPipeline': 300,
'Spider.pipelines.GetImagePipeline': 299,
}
# 图片存储路径
IMAGES_STORE = 'D:\\Design\\code\\Spider\\Spider\\image'
# 图片有效期
IMAGES_EXPIRES = 30运行代码,结果如下:
报错
Missing scheme in request url: h
这个报错是url的问题,request的参数url是列表类型的,而前边代码里是字符串类型的。
解决方法:在图片的字段外加中括号。

No module named 'PIL'
这个报错是由于python3中这个包已经被pillow代替。
解决办法:pip install pillow