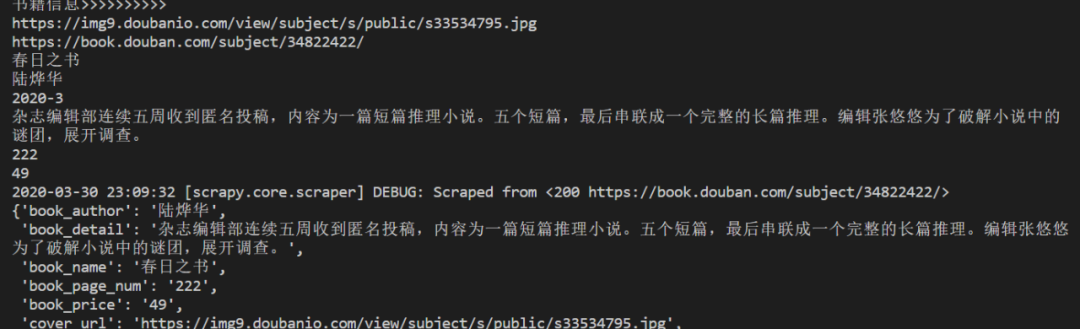
爬虫毕设(一):创建第一个爬虫
创建项目
使用scrapy startproject Spider创建一个名为Spider的项目。
使用vscode打开项目,可以看见该项目的文件结构:
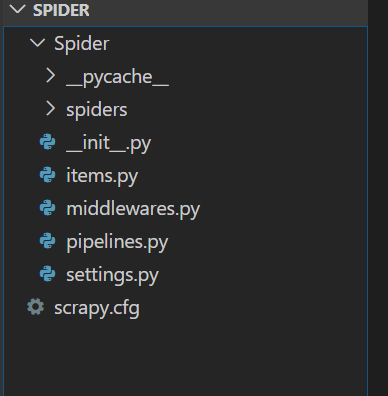
再一次介绍各文件的作用:
- scrapy.cfg:项目部署文件
- spiders:存放爬虫文件的文件夹
- items.py:保存爬取到的数据的容器
- middlewares.py:中间件
- pipelines.py:将爬取的数据进行持久化存储
- setting.py:配置文件
爬虫文件
在spiders目录下创建一个新的py文件,文件名为爬虫名,爬虫名必须是唯一的。
首先写一个爬取静态网页的爬虫。那么什么是静态网页,什么又是动态网页的?
- 静态网页,随着HTML代码的生成,页面的内容和显示效果就基本不会发生变化的网页,除非修改网页代码。
- 动态网页,虽然网页代码没有变,但是显示内容是随着时间、环境或者数据库操作的结果而发生改变的网页。
豆瓣的新书速递(url = 'https://book.douban.com/latest?icn=index-latestbook-all')就是一个静态网页。
在浏览器中打开开发者调试工具,进入NetWork,刷新网页,找到第一个也就是与目标url相同的请求。
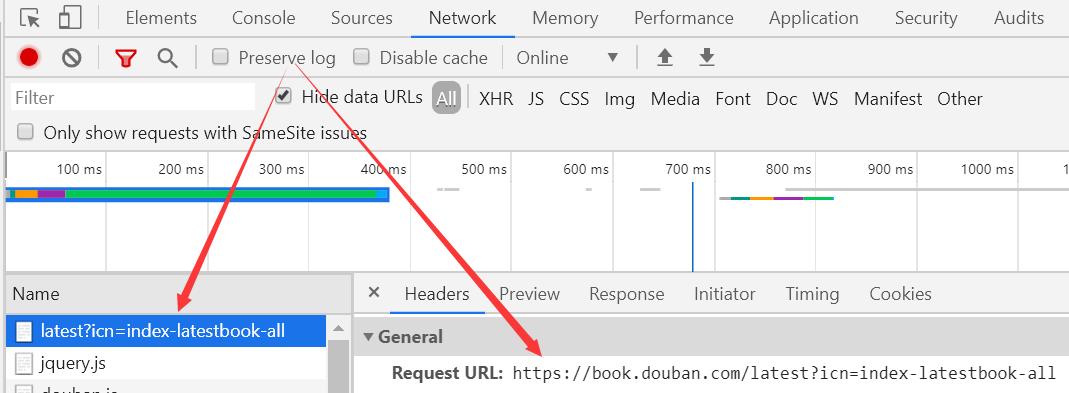
可以看到打开该网页时发生的网络请求与响应。选择预览,可以看到网页的预渲染。
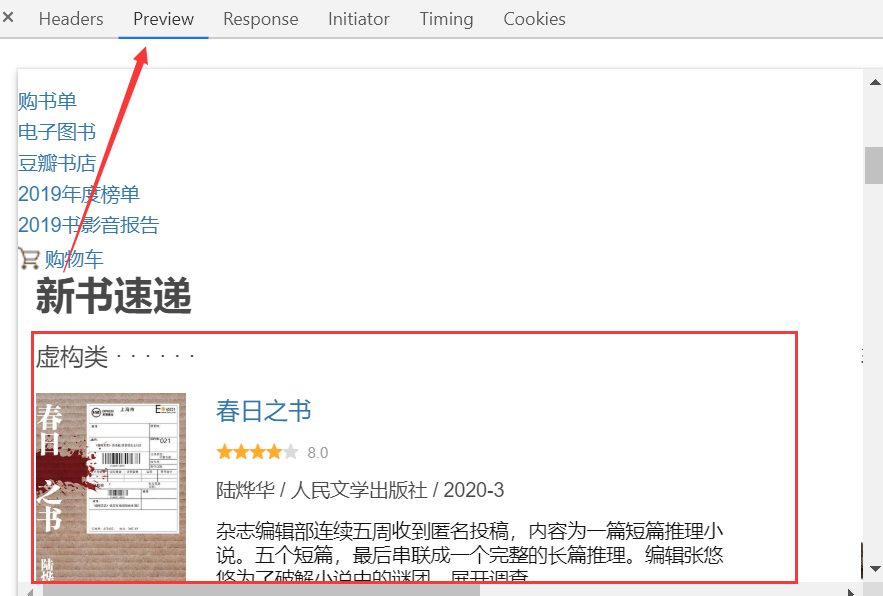
可以看到我们需要的数据已经在网页上了,这就说明是静态网页。
创建一个名为douban_book的py文件。
import scrapy
class tvSpider(scrapy.Spider):
# name是爬虫名称,它必须是唯一的
name = "douban_book"
allowed_domain = ["book.douban.com"]
# 初始化url
def __init__(self, *args, **kwargs):
super(DoubanBookSpider, self).__init__(*args, **kwargs)
self.start_urls = ["https://book.douban.com/latest?icn=index-latsetbook-all"]
# 解析函数
def parse(self, response):
pass确定了要爬取的目标网页,接下来就是要获取的自己想要的数据,这就要写解析函数parse。
parse负责处理响应并必须返回一个可迭代的Request和dists或Item对象。
选择器
Scrapy自己内置一套数据提取机制,成为选择器。它们通过特定的XPath或者CSS表达式来选择HTML文件中的某个部分,Scrapy选择器构建于lxml库上。
Selector对象有四个基本方法:
- xpath(query):传入XPath表达式query,返回该表达式所对应的所有节点的selector list列表。
- css(query):传入CSS表达式query,返回该表达式所对应的所有节点的selector list列表。
- extract():序列化该节点为Unicode字符串并返回list列表。
- re(regex):根据传入的正则表达式对数据进行提取,返回Unicode字符串列表。
这里使用XPath来提取数据。
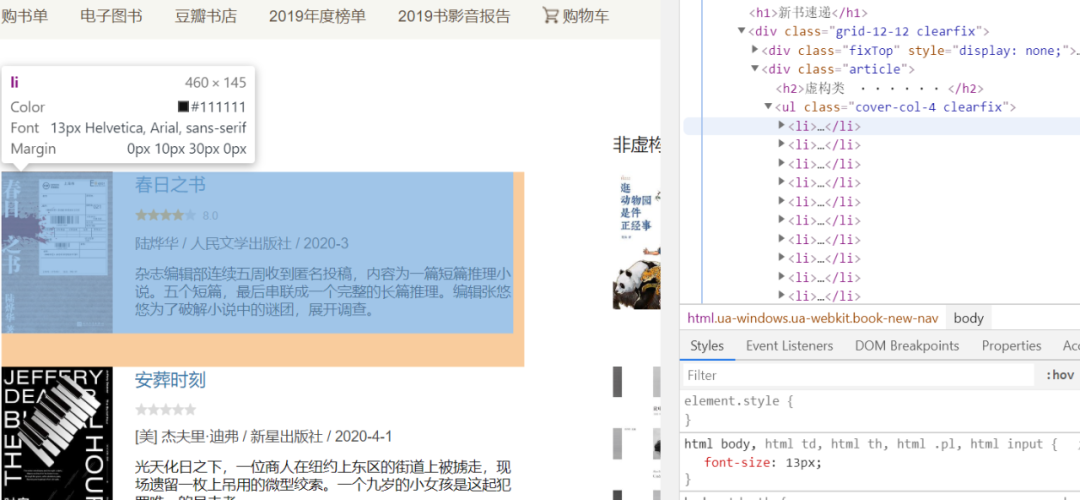
我们发现数据存储在li标签中。所以我们的思路就是先使用XPath表达式获取到所有的li标签,生成一个list,然后遍历这个list获取到每一项数据。
我们可以直接右键li标签copy到XPath表达式,但偶尔会出问题,所以我们自己写。
我们可以在代码区域按ctrl + f,然后输入自己XPath表达式验证是否正确。
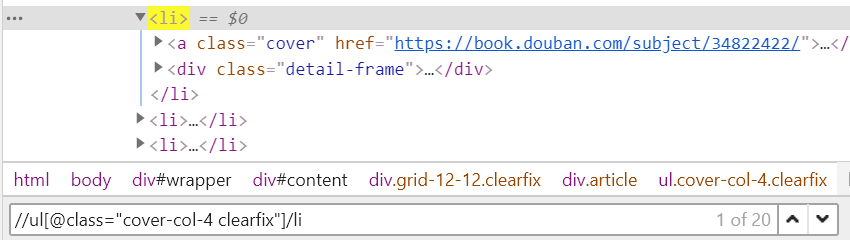
可以看到我们写的//ul[@class="cover-col-4 clearfix"]表达式,一共获取到了20条li标签,然后我们就要通过迭代的方式来提取出每一条li标签里的数据。
Parse
我们要获取的数据有:图片、链接、书名、作者、发布时间、书籍介绍、页数、价格。
其中页数和价格需要进入详情网页进行二次解析,其他数据则可以在该页直接获取到。
我们将整个逻辑写入到parse函数中:
def parse(self, response):
result = Selector(response)
book_list = result.xpath('//*[@class="cover-col-4 clearfix"]/li')
for book_ele in book_list:
# 图片
cover_url = book_ele.xpath('./a[@class="cover"]/img/@src').extract()[0]
# 链接
url = book_ele.xpath('./a[@class="cover"]/@href').extract()[0]
# 书名
book_name = book_ele.xpath('./div[@class="detail-frame"]/h2/a/text()').extract()[0]
# 作者
book_author_str = book_ele.xpath('./div[@class="detail-frame"]//p[@class="color-gray"]/text()').extract()[0]
book_author_array = book_author_str.split("/")
book_author = book_author_array[0].strip()
# 发布时间
publish_time = book_author_array[2].strip()
# 书籍介绍
book_detail = book_ele.xpath('./div[@class="detail-frame"]//p[@class="detail"]/text()').extract()[0]这就获取到了除了页数和价格的其他数据,而想要获取到这两条数据,我们只需要在写一个parse_detail函数,然后在前边的迭代中调用就可以了。
但是这里获取页数和价格有一个问题:并不是所有的书都有价格和页数。

所以我们在查看数据的时候就需要多看几条数据,否则很可能会导致爬取失败,在这里为了解决这个问题,我们加入一个小小的验证。
def parse_detail(self, response):
sel = Selector(response)
# 页数
book_page_num_str = result.xpath(u'//div[@id="info"]//span[text()="页数:"]').extract()
if book_page_num_str:
book_page_num = result.xpath(u'//div[@id="info"]//span[text()="页数:"]/following::text()[1]').extract()[0]
else:
book_page_num = ''
# 价格
book_price_str = result.xpath(u'//div[@id="info"]//span[text()="定价:"]').extract()
if book_price_str:
book_price = result.xpath(u'//div[@id="info"]//span[text()="定价:"]/following::text()[1]').extract()[0]
else:
book_price = ''然后只需要在parse函数的末尾加上调用即可:
yield scrapy.Request(url=url, callback=self.parse_detail)Item
Item是保存爬取到的数据的容器。所以我们定义一个Item类,将爬取到的数据写入到Item,也方便后边存入数据库。
# spiders/items.py
from scrapy.item import Item, Field
class BookListItem(Item):
# 封面图片
cover_url = Field()
# 地址
url = Field()
# 书名
book_name = Field()
# 作者
book_author = Field()
# 书籍介绍
book_detail = Field()
# 书籍页数
book_page_num = Field()
# 价格
book_price = Field()
# 发布时间
publish_time = Field()同时在parse函数中加入相应的代码,最后完整的代码是这样的。
import scrapy
from scrapy.selector import Selector
from Spider.items import BookListItem
class DoubanBookSpider(scrapy.Spider):
name = "douban_book"
allowed_domains = ["book.douban.com"]
def __init__(self, *args, **kwargs):
super(DoubanBookSpider, self).__init__(*args, **kwargs)
self.start_urls = ["https://book.douban.com/latest?icn=index-latsetbook-all"]
def parse(self, response):
sel = Selector(response)
book_list = sel.xpath('//*[@class="cover-col-4 clearfix"]/li')
for book_ele in book_list:
book_item = BookListItem()
# 图片
cover_url = book_ele.xpath('./a[@class="cover"]/img/@src').extract()[0]
# 链接
url = book_ele.xpath('./a[@class="cover"]/@href').extract()[0]
# 书名
book_name = book_ele.xpath('./div[@class="detail-frame"]/h2/a/text()').extract()[0]
# 作者
book_author_str = book_ele.xpath('./div[@class="detail-frame"]//p[@class="color-gray"]/text()').extract()[0]
book_author_array = book_author_str.split("/")
book_author = book_author_array[0].strip()
# 发布时间
publish_time = book_author_array[2].strip()
# 书籍介绍
book_detail = book_ele.xpath('./div[@class="detail-frame"]//p[@class="detail"]/text()').extract()[0]
book_item["cover_url"] = cover_url.strip()
book_item["url"] = url.strip()
book_item["book_name"] = book_name.strip()
book_item["book_author"] = book_author.strip()
book_item["publish_time"] = publish_time.strip()
book_item["book_detail"] = book_detail.strip()
# 进入书籍详情页获取书籍页数和价格
yield scrapy.Request(url=url, meta={'book_item': book_item}, callback=self.parse_detail)
def parse_detail(self, response):
book_item = response.meta['book_item']
sel = Selector(response)
# 页数
book_page_num_str = sel.xpath(u'//div[@id="info"]//span[text()="页数:"]').extract()
if book_page_num_str:
book_page_num = sel.xpath(u'//div[@id="info"]//span[text()="页数:"]/following::text()[1]').extract()[0]
else:
book_page_num = ''
# 价格
book_price_str = sel.xpath(u'//div[@id="info"]//span[text()="定价:"]').extract()
if book_price_str:
book_price = sel.xpath(u'//div[@id="info"]//span[text()="定价:"]/following::text()[1]').extract()[0]
else:
book_price = ''
book_item["book_page_num"] = book_page_num.strip()
book_item["book_price"] = book_price.strip()
print('书籍信息>>>>>>>>>>')
print(book_item["cover_url"])
print(book_item["url"])
print(book_item["book_name"])
print(book_item["book_author"])
print(book_item["publish_time"])
print(book_item["book_detail"])
print(book_item["book_page_num"])
print(book_item["book_price"])
yield book_item然后再命令行中运行scrapy crawl douban_book,然后就可以看到结果打印出来。