ELK日常使用基础篇
前言
在后端开发工程师的日常工作中,在遇到比如定位排查问题或是想要了解系统某些方面的情况时,会遇到以下的场景:
- 查询某个接口请求的日志。
- 查询某个服务的日志。
- 统计某些接口的每日调用数量以及时间分布。
- 统计某个或者某些接口每日的用户数量。
ELK(Elasticsearch+Logstash+Kibana)平台能很好的帮助我们完成上述工作,并且给我们提供了友好便利的用户界面,普遍应用于生产日志的查询分析中。所谓ELK用一句话概括就是:用Logstash收集日志或者数据到Elasticsearch存储起来并建立相关索引,再利用Kibana提供的查询界面到Elasticsearch上提供的索引进行查询和统计。
本文主旨是通过一个实际案例来讲述下ELK平台的日常操作方法,帮助我们的后台工程师能绕开枯燥的理论学习而直接收获实际应用的干货,进而帮助提高实际工作效率。
下面和大家说说如何利用Logstash收集日志(这里以nginx日志举例),其中会重点介绍filter模块中的grok插件,再会介绍工程师在实际工作中必须掌握的利用Kibana进行查询分析的几种典型场景。
示例代码中ELK使用的版本
- Logstash 6.6.2
- Kibana 6.6.2
- Elasticsearch 6.6.2
1Logstash收集日志
1.1Logstash脚本文件
构成和常用插件
Logstash的脚本由input,filter,output三个部分构成,同时这三个部分都支持众多的插件。
- input Logstash的数据来源,可以是文件、Kafka、RabbitMQ、socket等等。
- filter 从input接收到的数据经过filter进行数据类型转换、字段增减和修改、以及一些逻辑处理。虽然 filter模块是非必选的部分,但由于其可以将收集的日志格式化,合理的字段类型定义和辅助字段的创建可以使得以后的查询统计更加容易和高效。所以filter模块的配置是整个Logstash配置文件最重要的地方。
- output 将filter得到的结果输出,可以是文件,Elasticsearch,Kafka等等。
具体的Logstash插件官方文档连接如下:- input插件参考https://www.elastic.co/guide/en/logstash/6.6/input-plugins.html
- filter插件参考https://www.elastic.co/guide/en/logstash/6.6/filter-plugins.html
- output插件参考https://www.elastic.co/guide/en/logstash/6.6/output-plugins.html
下面通过一段简单的logstash配置文件,让我们对它有更加具体的认知。
Logstash三个主要组成部分的示例代码如下:
input:
input模块支持从多个源收集数据,下面的代码给出了常用的从文件、Kafka、RabbitMQ收集的样例。
input {
//input可以有多个插件用来处理不同的数据源;下面是一些常用的输入数据源
//从一个文件获取数据,可以支持单个或者多个文件
file {
path => "/opt/logs/app-*.log"
}
//从一个kafka的topic获取数据,同样支持多个topic
kafka {
#Kafka topic
topics => ["topic名字"]
#消费者组
group_id => "group名字"
bootstrap_servers => "kfk013218.heracles.sohuno.com:9092,..."
}
//从rabbitmq的一个队列获取数据
rabbitmq {
host => "rabbit host or ip"
port => 5672
queue => "queue名字"
vhost => "/vhost"
prefetch_count => 1
key => "routingkey.#"
exchange => "exchange名字"
codec => "json"
}
}filter:
filter模块是非必须的,如果input得到的数据不需要二次加工可以不使用filter,直接output到一个输出端。input接收到的数据如果需要类型转换、过滤判断、增减字段等操作就需要用到filter模块。
合理的拆分字段和字段的数据类型转换是制作统计图表的基础,后文提到的统计图表的制作直接依赖filter处理所产生的字段。强大的正则处理插件grok堪称Logstash中的神器组件,grok内置了丰富的预定义pattern,让我们能够更简单方便的使用复杂的正则匹配目标数据。
filter {
//filter模块内也提供了众多插件
//常用修改,字段拆分、连接、大小写、字段改名、类型变换
mutate {
split => ["message",","]#将读到的数据用’,‘ 拆分,后面会详细说
}
//日期类型的字段处理
//日期插件有区别于其他的插件,默认会改写当前数据记录所代表的时间(@timestamp这个字段),在通过kibana进行时间范围查询时会使用到@timestamp
date {
match => ["time", "yyyy-MM-dd HH:mm:ss.SSS"]
}
//强大的正则处理插件堪称Logstash中的神器组件
grok {
match => {
"params" => "Method:%{DATA:method},...TimeId:%{INT:timeId}"
}
}
//kv类型的字符串字段处理 params="key1=val1,key2=val2"
kv {
source => "params"
field_split => "="
value_split => ","
}
//处理json字符串字段 param="{a:1,b:2}"
json {
source => "param"
}
//丢弃接收到的数据
drop {}
}output:
一般我们在调试阶段时使用stdout{codec => rubydebug},这样可以直接在console看到Logstash处理完成输出的结果。注意,由于性能的关系,在生产环境上需要把stdout和rubydebug关掉。
output {
//debug 调试使用,生产环境禁止使用
stdout{codec => rubydebug}
//输出到Elasticsearch存储
elasticsearch {
hosts => ["ip:port",...]
index => "logstash-%{+YYYY.MM.dd}"//按天命名的index
}
file{
path => "/opt/logs/out-%{+YYYY-MM-dd}.log"//按天命名输出文件
}
}1.2利用logstash收集
nginx日志到Elasticsearch
下面让我通过一个实际的例子来了解怎样使用ELK。 input配置:
在下面的代码中我们要收集的是/opt/logs/nginx 目录下的 access.log 和 access2.log两个日志文件。
input{
//同时收集多组nginx日志文件
file {
type => "api1-nginx-access"
path => ["/opt/logs/nginx/access.log"]
}
file {
type => "api2-nginx-access"
path => ["/opt/logs/nginx/access2.log"]
}
}filter处理收集到的nginx日志:
收集到的日志能否发挥最大的价值就在filter这里,特别是以后需要统计的一些字段,比如用户id、设备信息、ip地址;
还有就是一些有必要转换成数字类型的字段最好在filter这里就转换完成,数字类型的字段可以在统计的时候使用数学运算,例如求均值、求90Line等。
grok:
解析nginx日志通常使用grok组件。表达式使用的基本语法是下面这样的:
%{SYNTAX:SEMANTIC}用%{} 扩起来的就表示一组正则匹配规则,SYNTAX是指grok里已经预定义好的正则表达式,SEMANTIC是指匹配之后要放的字段名字。
下面是NUMBER表达式的使用示例,NUMBER 表示在grok中该正则表达式匹配的别名。冒号后面的是准备输出的字段名称,duration将在检索时可以被分析到。
%{NUMBER:duration}在 grok-patterns 里面NUMBER是用下面的正则表达式定义的,它基于了BASE10NUM的定义。
BASE10NUM (?<![0-9.+-])(?>[+-]?(?:(?:[0-9]+(?:\.[0-9]+)?)|(?:\.[0-9]+)))
NUMBER (?:%{BASE10NUM})下面我们列举了一段极简的nginx日志片段:
55.3.244.1 GET /index.html 15824 0.043那么使用下面的正则匹配组合就能成功匹配上面的日志片段:-
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}grok给我们提供了很多实用的预定义的正则表达式,下面是截取的一小部分:
# Networking
MAC (?:%{CISCOMAC}|%{WINDOWSMAC}|%{COMMONMAC})
CISCOMAC (?:(?:[A-Fa-f0-9]{4}\.){2}[A-Fa-f0-9]{4})
WINDOWSMAC (?:(?:[A-Fa-f0-9]{2}-){5}[A-Fa-f0-9]{2})
COMMONMAC (?:(?:[A-Fa-f0-9]{2}:){5}[A-Fa-f0-9]{2})
IPV6 ((([0-9A-Fa-f]{1,4}:){7}([0-9A-Fa-f]{1,4}|:))|(([0-9A-Fa-f]{1,4}:){6}(:[0-9A-Fa-f]{1,4}|((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){5}(((:[0-9A-Fa-f]{1,4}){1,2})|:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){4}(((:[0-9A-Fa-f]{1,4}){1,3})|((:[0-9A-Fa-f]{1,4})?:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){3}(((:[0-9A-Fa-f]{1,4}){1,4})|((:[0-9A-Fa-f]{1,4}){0,2}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){2}(((:[0-9A-Fa-f]{1,4}){1,5})|((:[0-9A-Fa-f]{1,4}){0,3}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){1}(((:[0-9A-Fa-f]{1,4}){1,6})|((:[0-9A-Fa-f]{1,4}){0,4}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(:(((:[0-9A-Fa-f]{1,4}){1,7})|((:[0-9A-Fa-f]{1,4}){0,5}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:)))(%.+)?
IPV4 (?<![0-9])(?:(?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5]))(?![0-9])
IP (?:%{IPV6}|%{IPV4})
HOSTNAME \b(?:[0-9A-Za-z][0-9A-Za-z-]{0,62})(?:\.(?:[0-9A-Za-z][0-9A-Za-z-]{0,62}))*(\.?|\b)
IPORHOST (?:%{IP}|%{HOSTNAME})
HOSTPORT %{IPORHOST}:%{POSINT}想要了解更多的grok正则匹配请参考这里:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns 实际的nginx日志如下:
23/May/2019:14:40:10 +0800,1558593610.753,1660,0.028,"0.028",647,200,10.16.172.20-"123.126.70.235",POST /330000/v6/feeds/detail/query HTTP/1.1,"app_key_vs=2.6.0&appid=330000&feed_count=10&feed_id=507297347911306752&flyer=1558593610700&idfa=A6719238-5AF6-4B57-B4B6-676B0905704D&log_user_id=248137098937342464&query_type=6&sig=28d2c189144c5380113afff158ea257d&since_time_comment=3000-01-01%2001%3A01%3A01.000&since_time_pure=3000-01-01%2001%3A01%3A01.000",UPS/"10.18.76.18:8080","sns/2.6.0 (com.sohu.sns; build:3; iOS 12.1.4) Alamofire/1.0",-,cs-ol.sns.sohu.com,"01374622096363527552","248137098937342464","872289029629325312@sohu.com","110501"对应的nginx里配置的日志格式如下:
log_format nginx_nobody_log '$time_local,$msec,$request_length,$request_time,"$upstream_response_time",$body_bytes_sent,$status,$remote_addr-"$http_x_forwarded_for",$request,"$request_body",UPS/"$upstream_addr","$http_user_agent",$http_referer,$host,"$http_s_cid","$http_s_pid","$http_s_ppid","$http_p_appid"';使用Logstash解析nginx日志的关键就是编写匹配nginx日志格式的正则模式。grok组件可以将多组复杂的pattern放到一个文件中,方便我们修改和管理,比如放到/opt/conf/logstash-patter/nginx-pattern 文件。 SNS_NGINX_ACCESS 就是我们自定义的一个pattern的别名,包含如下内容:
SNS_NGINX_ACCESS %{HTTPDATE:time_local},%{NUMBER:msec},%{INT:request_length},%{BASE16FLOAT:request_time},"(?:-|%{BASE16FLOAT:upstream_response_time})(,%{NUMBER:upstream_response_time2})?",%{INT:body_bytes_sent},%{INT:status},%{IPORHOST:remote_addr}-"%{DATA:http_x_forwarded_for}(, %{DATA:http_x_forwarded_for2})?",%{WORD:method} %{URIPATH:interface}(?:%{DATA:uri_param})? HTTP/%{NUMBER:http_version},"%{DATA:request_body}",UPS/"%{DATA:upstream_addr}(, %{DATA:upstream_addr2})?","%{DATA:http_user_agent}",%{DATA:http_referer},%{IPORHOST:host},"%{DATA:http_s_cid}","%{DATA:http_s_pid}","%{DATA:http_s_ppid}","%{DATA:http_p_appid}"我们如果要使用这个定义好的pattern文件只需要向下面这样:
grok {
patterns_dir => "/opt/conf/logstash-pattern"
match => {
"message" => "%{SNS_NGINX_ACCESS}"
}
}Kibana 6.4.0以后的版本 在DevTools里面自带了grok调试工具(图1)
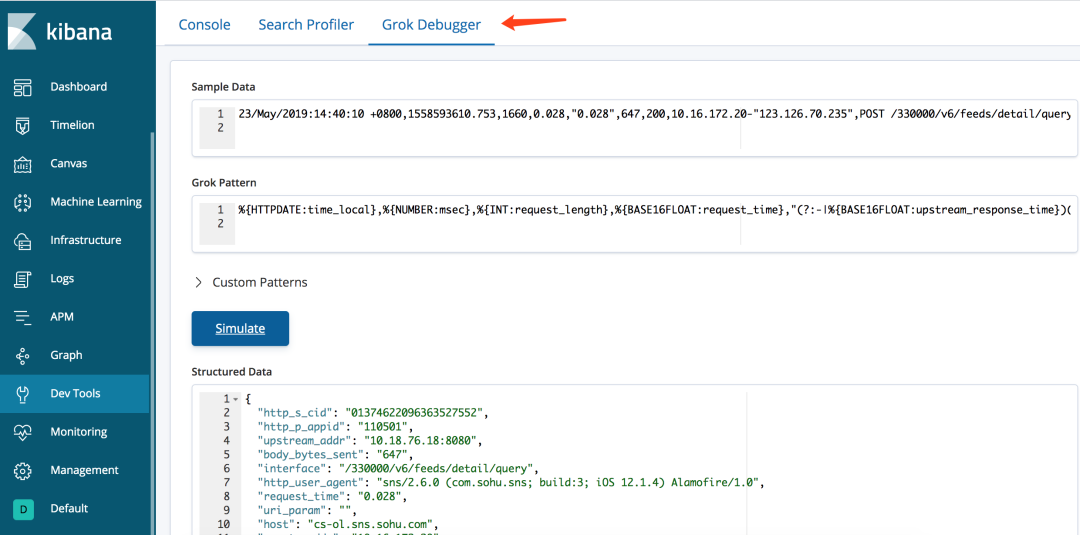
图1 Kibana内置的Grok Debugger
下面是完整的filter和output配置及介绍,供参考。
完整filter:
filter {
//if判断
if "form-data" in [message] {
drop {}
}
//正则匹配,patterns_dir 里面的文本文件都会读取出来
grok {
patterns_dir => "/opt/conf/logstash-pattern"
match => {
//message表示读取到的nginx一行日志,使用编辑好的pattern文件中名为SNS_NGINX_ACCESS进行正则匹配
"message" => "%{SNS_NGINX_ACCESS}"
}
//删除message字段,message字段是默认的字段记录的是原始nginx日志的一整行,删除后可以减少es的存储占用
remove_field => ["message"]
}
//将time_local日期类型的字符串转换成日期类型,并赋值给target指向的字段,默认是@timestamp字段
date {
match => ["time_local","dd/MMM/YYYY:HH:mm:ss Z"]
target => "@timestamp" //这句可以不写
}
if "-" not in [http_x_forwarded_for] {
//ip地址物理位置处理 GEO geographical location of IP addresses
//ip数据库参考这里 https://dev.maxmind.com/geoip/geoip2/geolite2
geoip {
source => "http_x_forwarded_for"
fields => ["ip","city_name", "country_code3", "country_name", "ip", "latitude", "longitude","location"]
}
}
//将所有字段进行urldecode
urldecode {
all_fields => true
}
//kv 类型的字段处理
//处理前 uri_param="?app_key_vs=2.6.0&appid=330000&feed_count=10&feed_id=xxx"
kv {
source => "uri_param"
field_split => "&?"
value_split => "="
include_keys => [ "appid", "user_id"]
}
//针对request_body字段同样使用kv处理
if [request_body] != '-' {
kv {
source => "request_body"
field_split => "&?"
value_split => "="
include_keys => [ "appid", "user_id" ]
}
}
mutate {
//字段重命名
rename => [ "appId", "appid" ]
//字段类型转换
convert => ["request_time", "float", "upstream_response_time", "float"]
//删除port字段
remove_field => ["port"]
//将host字段切分成hostname和http_port两个字段
split => ["host", ","]
add_field => {"hostname" => "%{[host][0]}"}
add_field => {"http_host" => "%{[host][1]}"}
}
}output配置:
//最后就是按天存储到Elasticsearch索引中
output {
//type 是input中file模块定义的type,这样就可以区分区是从哪个access日志读取的。
//将不同的access日志存储在不同的索引中
if [type] == "api1-nginx-access" {
elasticsearch {
hosts => ["es ip:port"...]
index => "logstash-nginx-access1-%{+YYYY.MM.dd}"
}
}
if [type] == "api2-nginx-access" {
elasticsearch {
hosts => ["es ip:port"...]
index => "logstash-nginx-access2-%{+YYYY.MM.dd}"
}
}
}2.Elasticsearch的RESTful API
在前面章节中介绍了logstash如何将nginx的日志数据写入Elasticsearch(后面简称es),那么写入到es中的数据我们如何查询呢?
2.1 RESTful API介绍
es的RESTful API提供了众多的api和丰富的功能;常用的API分为如下几类 Document APIs :es的文档的CRUD操作相关API
Search APIs:查询检索相关的API
Indices APIs:索引管理相关API
cat APIs:集群健康状态、索引信息、分片信息等等,输出的是在命令行界面下更友好的制表信息
Cluster APIs:es集群查看和管理配置相关API
限于篇幅本文只是针对几个查询场景介绍一些常用的API,想要系统性的了解请参考 https://www.elastic.co/guide/en/elasticsearch/reference/6.6/index.html
2.2 常用RESTful API使用
让我们借助Kibana的 Dev Tools工具来了解一下常用的API使用。
GET /可以查看es的简单信息包括版本号、集群名称、lucene版本号等。-
GET logstash-nginx-access*/可以查看到es对应的index的aliases,mappings,settings信息。其中重要的是mappings,mapping是es中定义文档和字段是如何被存储和索引的,例如定义哪些字符串字段应被视为全文字段;哪些字段包含数字、日期、地理位置;日期字段的日期格式以及对动态增加的字段的一些自定义规则。
mappings 返回数据片段举例
"mappings" : {
...
"properties" : { //mappings 都有哪些属性
"@timestamp" : { // @timestamp字段是日期类型
"type" : "date"
},
"@version" : {
"type" : "keyword" //keyword表示全文字段,查询时不分词检索
},
"body_bytes_sent" : {
"type" : "long"
},
"geoip" : { //嵌套的document类型
"dynamic" : "true", //动态 mapping ,表示geoip可能会有新的字段
"properties" : {
"city_name" : {
"type" : "text",
"norms" : false, //在查询的score不考虑city_name字段
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256 //city_name的keyword只保留256字节长度
}
}
},
......
"ip" : {
"type" : "ip"
},
"latitude" : {
"type" : "half_float" //16-bit 浮点数
},
"location" : {
"type" : "geo_point"
},
"longitude" : {
"type" : "half_float"
}
}
},
"request_time" : {
"type" : "float" //32-bit 浮点数
}......
}
}2.3 Search APIs的常见用法
GET logstash-nginx-access*/_search查询logstash-nginx-access为前缀的索引全部数据(默认只返回前10条数据),查询结果如下
{
"took" : 205, //查询所花费的毫秒数
"timed_out" : false,
"_shards" : {
"total" : 8, //查询了几个分片
"successful" : 8, //查询执行成功的分片数
"skipped" : 0,
"failed" : 0
},
"hits" : { //查询命中的数据
"total" : 96198672, //indexpattern下的查询命中的全部数据条数
"max_score" : 1.0,
"hits" : [
......]
}
}图2是hits中的内容,是查询到的数据,_index表示数据来自哪个索引,_source表示原始数据。

图2 his中的内容
如果想要查询status=200的最近15条数据应该怎么写呢?我们可以分别使用URI search和Request body两种查询方式。
使用URI search的查询方式,更多内容请参考https://www.elastic.co/guide/en/elasticsearch/reference/6.6/search-uri-request.html
GET logstash-nginx-access*/_search?q=status:200&size=15&sort=@timestamp:desc加上参数q=status:200 表示查询status字段值为200的数据,size=15表示只返回前15条数据,sort=@timestamp:desc表示使用@timestamp字段倒序排序
使用request body 的查询方式,更多内容请参考https://www.elastic.co/guide/en/elasticsearch/reference/6.6/search-request-body.html
GET logstash-nginx-access*/_search
{
"size":15,
"query":{
"term":{
"status":200
}
},
"sort": [
{
"@timestamp": {
"order": "desc"
}
}
]
}上面request body中的 query部分es提供了Query DSL查询语法,更多内容请参考https://www.elastic.co/guide/en/elasticsearch/reference/6.6/query-dsl.html
如果我们只想查询_source中的某些字段,而不想要全部字段时,可以加上_source:[“字段1”,”字段2”]进行过滤
{
"size":15,
"_source": [ "interface", "remote_addr" ],
"query":{
"term":{
"status":200
}
},
"sort": [
{
"@timestamp": {
"order": "desc"
}
}
]
}_source还可以有如下用法
"_source": {
"includes": [ "http*", "geoip.*" ], //包含的字段,http开头的字段,geoip的嵌套类型字段
"excludes": [ "xxx" ] //排除哪些字段
}"_source": false, //不显示_source内容如果我们只想要统计数量而不需要查询数据,可以使用 Count API
GET logstash-nginx-access*/_count
{
"query":{
"term":{
"status":200
}
}
}上面的查询会返回如下内容,count表示查询命中的数量
{
"count" : 3807,
"_shards" : {
"total" : 8,
"successful" : 8,
"skipped" : 0,
"failed" : 0
}
}如果我们想要查询的数据比较多,我们可以利用scroll来进行游标查询;scroll=5m表示游标查询窗口会保持5分钟
GET logstash-nginx-access*/_search?scroll=5m
{
"size":15,
"_source": [ "interface", "remote_addr" ],
"query":{
"term":{
"status":200
}
},
"sort": [
{
"@timestamp": {
"order": "desc"
}
}
]
}上面的查询会得到如下结果
{
"_scroll_id" : "DnF1ZXJ5VGhlbkZldGNoCAAAAAACICIZFl9CUWJJdWVDUzVTdldDQjNYN3ZEU3cAAAAABkXxNxZSbDRKeE9hLVNqdTVnVlUtc2h3MElBAAAAAAqefhsWR2R3NVNhel9RNU8tN0dNTm16dzE0QQAAAAAA2LfBFnJsckEyWVkzUUNhb2JHOUZTQ0IzQlEAAAAAAiAiGhZfQlFiSXVlQ1M1U3ZXQ0IzWDd2RFN3AAAAAADYt8IWcmxyQTJZWTNRQ2FvYkc5RlNDQjNCUQAAAAACICIbFl9CUWJJdWVDUzVTdldDQjNYN3ZEU3cAAAAADd5U1hZ3djgxRnFRMVFZZWdwSE1BZU1oOWp3",
"took" : 249,
"timed_out" : false,
"_shards" : {
"total" : 8,
"successful" : 8,
"skipped" : 0,
"failed" : 0
},
"hits" : {......上面的返回结果中有一个 _scroll_id 字段,要基于这个游标继续遍历数据只需要像下面这样,调用 /_search/scroll 接口,将前面返回结果的_scroll_id作为scroll_id参数值;scroll:5m表示将当前的scroll_id查询窗口再次延长5分钟。
这样就可以一直查询,直到数据为空。
GET /_search/scroll
{
"scroll":"5m",
"scroll_id":"DnF1ZXJ5VGhlbkZldGNoCAAAAAACICIZFl9CUWJJdWVDUzVTdldDQjNYN3ZEU3cAAAAABkXxNxZSbDRKeE9hLVNqdTVnVlUtc2h3MElBAAAAAAqefhsWR2R3NVNhel9RNU8tN0dNTm16dzE0QQAAAAAA2LfBFnJsckEyWVkzUUNhb2JHOUZTQ0IzQlEAAAAAAiAiGhZfQlFiSXVlQ1M1U3ZXQ0IzWDd2RFN3AAAAAADYt8IWcmxyQTJZWTNRQ2FvYkc5RlNDQjNCUQAAAAACICIbFl9CUWJJdWVDUzVTdldDQjNYN3ZEU3cAAAAADd5U1hZ3djgxRnFRMVFZZWdwSE1BZU1oOWp3"
}游标超过时间窗口会自动清理,也可以通过 DELETE /_search/scroll 来清理一个游标
DELETE /_search/scroll
{
"scroll_id" : "DnF1ZXJ5VGhlbkZldGNoCAAAAAACICIZFl9CUWJJdWVDUzVTdldDQjNYN3ZEU3cAAAAABkXxNxZSbDRKeE9hLVNqdTVnVlUtc2h3MElBAAAAAAqefhsWR2R3NVNhel9RNU8tN0dNTm16dzE0QQAAAAAA2LfBFnJsckEyWVkzUUNhb2JHOUZTQ0IzQlEAAAAAAiAiGhZfQlFiSXVlQ1M1U3ZXQ0IzWDd2RFN3AAAAAADYt8IWcmxyQTJZWTNRQ2FvYkc5RlNDQjNCUQAAAAACICIbFl9CUWJJdWVDUzVTdldDQjNYN3ZEU3cAAAAADd5U1hZ3djgxRnFRMVFZZWdwSE1BZU1oOWp3"
}查询结果高亮,更多内容请参考 https://www.elastic.co/guide/en/elasticsearch/reference/6.6/search-request-highlighting.html
GET logstash-nginx-access*/_search
{
"size":15,
"_source": [ "interface", "remote_addr","status" ],
"query":{
"term":{
"status":200
}
},
"highlight": {
"fields": {"status":{}}
},
"sort": [
{
"@timestamp": {
"order": "desc"
}
}
]
}图3中highlight部分就是高亮的内容
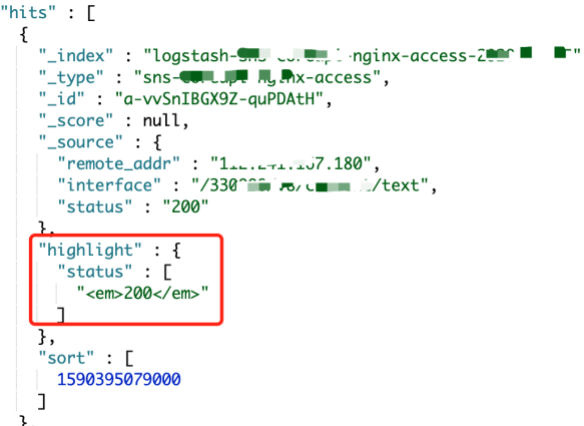
图3 高亮的内容
2.4 Aggregation聚合查询 如果想要统计某索引每天(每小时)的数量、按照某个字段计数等类似的查询就要用到aggregation聚合查询 例如我们想要知道每天的请求数量,可像下面这样写:
- aggs表示聚合查询;
- “day_count”是我们自定义的一个聚合的名称(aggs可以有多个和多层所以需要指定一个名称);
- date_histogram表示是一个日期分布器,是按照“@timestamp”这个日期字段按照1d(1天)的时间间隔进行分布的;
- size:0 表示不返回具体的记录,hits部分是空数组
GET logstash-nginx-access*/_search
{
"aggs": {
"day_count": {
"date_histogram": {
"field": "@timestamp",
"interval": "1d"
}
}
},
"size": 0
}返回数据会出现一个aggreations部分,如图4;day_count就是我们自定义的聚合名称,buckets表示按照日期分布到了那几个“桶”里。
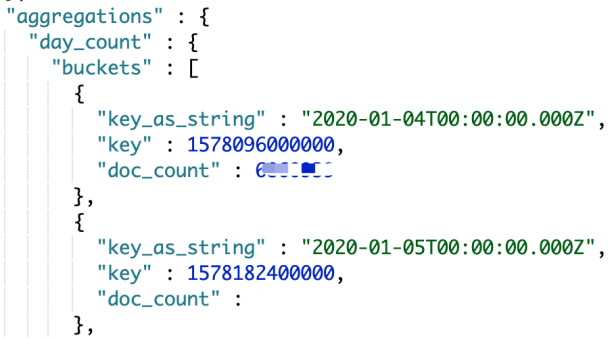
图4 aggreations 返回结果
如果我们想要固定查询的日期范围,并且只查询status=200的数量,可以在查询增加query部分,如下
GET logstash-nginx-access*/_search
{
"aggs": {
"day_count": {
"date_histogram": {
"field": "@timestamp",
"interval": "1d"
}
}
},
"size": 0,
"query": {
"bool": {
"must": [
{"range": { //一个range查询
"@timestamp": { //查询1月20到1月25时间范围
"gte": "2020-01-20",
"lte": "2020-01-25",
"format": "yyyy-MM-dd"
}
}
},{
"match": { //只匹配status=200的记录
"status": 200
}
}
]
}
}
}我们也可以按照terms进行聚合,比如统计一天内接口调用次数,只需要将aggs部分修改成如下,interface.keyword 就是interface的全文字段,size:5 表示只展示前面5个(默认是按照doc_count倒序排序)
{
"aggs": {
"interface_count": {
"terms": {
"field": "interface.keyword",
"size": 5
}
}
},
"size": 0,
"query": {
"bool": {
"must": [
{"range": {
"@timestamp": {
"gte": "2020-05-20",
"lte": "2020-05-21",
"format": "yyyy-MM-dd"
}
}
},{
"match": {
"status": 200
}
}
]
}
}
}返回结果是接口数量最多的前5个,如图5

图5 接口调用数量聚合查询结果
那么,如果我们想要看每个接口一天内每个小时的调用数量改怎么办呢?
只需要在上面的interface_count aggs基础上再嵌套一个date_histogram类型的聚合。
"aggs": {
"interface_count": {
"terms": {
"field": "interface.keyword",
"size": 5
}
,
"aggs" :{
"hours" : {
"date_histogram": {
"field": "@timestamp",
"interval": "1h" //按照1小时间隔分布
}
}
}
}返回结果中在interface_count里面有增加了一层“hours”的聚合如图6,展示了“key”(即接口名)按照每个小时的分布计数结果。

图6 每个接口按小时的聚合查询数量
3.利用kibana进行日志查询与分析
3.1基础过滤查询
对于在上面通过grok匹配存储在Elasticsearch中的字段都是可以使用Kibana的 Discover菜单的中 “Add a filter” 进行查询。
“字段名” 和 “字段名.keyword” 两种过滤方式
这里注意,在查询里,有 “字段名” 和 “字段名.keyword” 两种过滤方式,这两者的区别是:使用“字段名”可以进行分词查询比如图8中interface字段存储的
是“/330003/v7/feeds/profile/template”的内容,那么每一个"/"之间的字符串都可以单独查询,因为"/"是一个默认的分词符号,
而interface.keyword意思是使用interface整体进行查询不支持分词,使用时Kibana时也会弹出下拉列表。
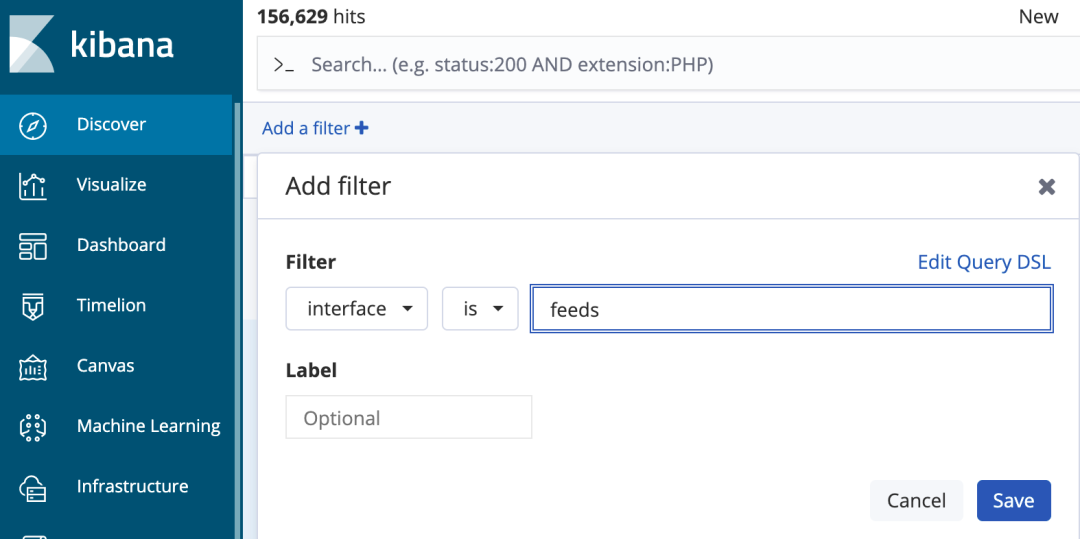
图7 字段直接过滤查询
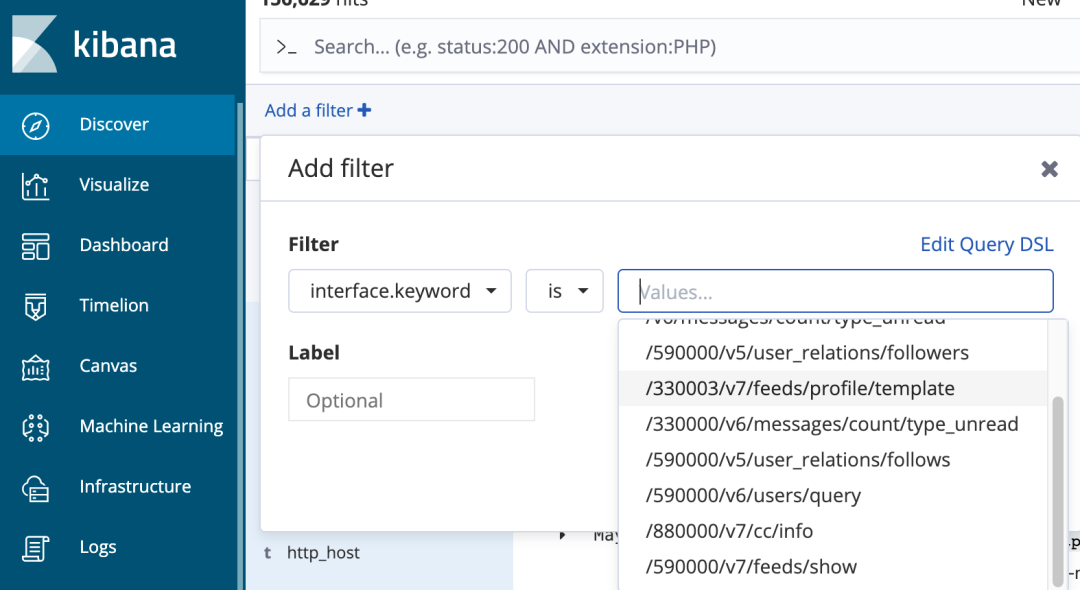
图8 使用keyword查询
单字段多词查询
当想要查询一个字段的多个值可以使用 “is one of” (图9)或者 “is not one of” ,用来表示要查询的分词在其中或者不在其中:
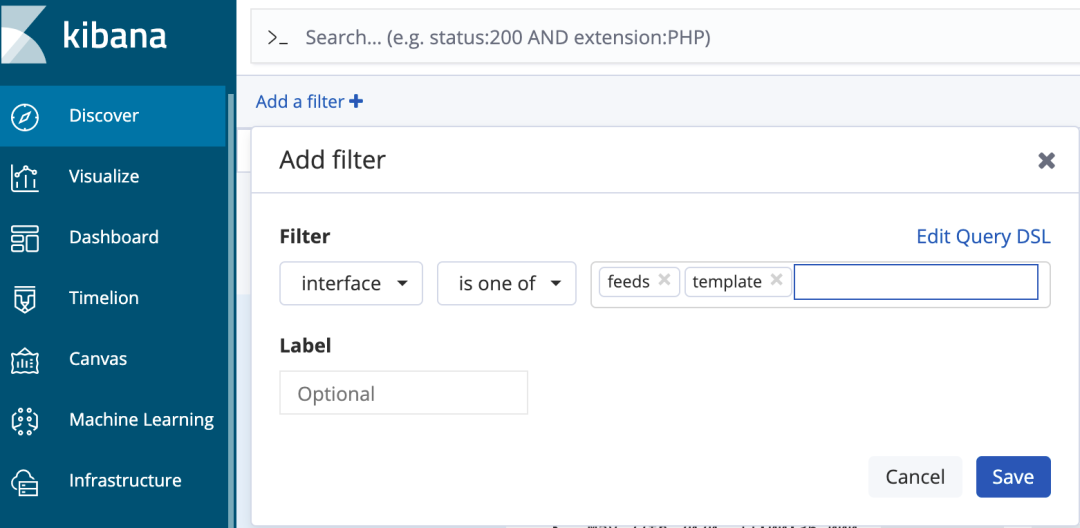
图9 is one of 多词查询
多过滤条件查询
当然可以进行多个字段查讯,它们之间的关系是 and 关系,例如 图10 查询的是“interface包含feeds关键字的并且 appid=330000 并且 status是200的 ”
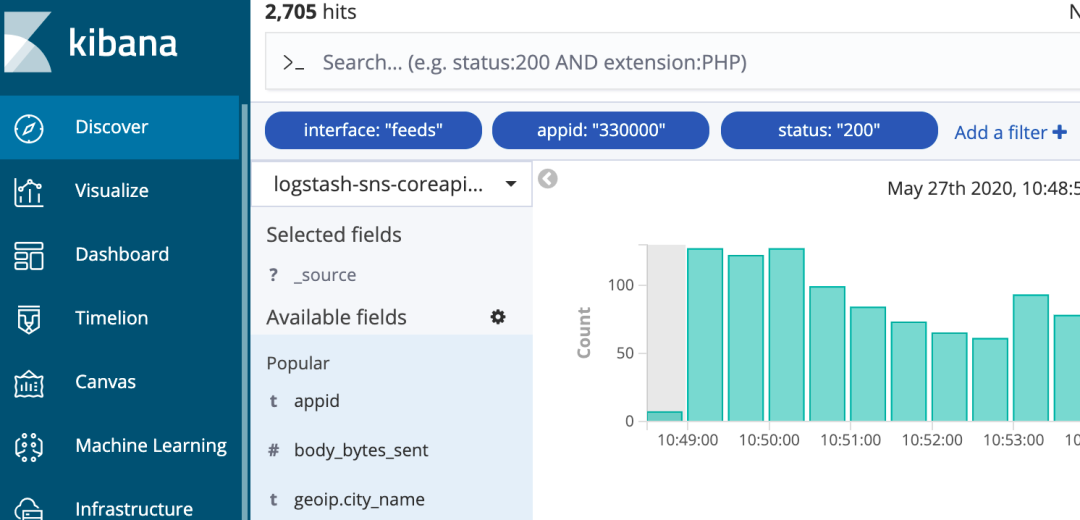
图10 多过滤条件查询
查询过程中的过滤条件快速修改
可以使用查询filter上的 + - 号按钮来进行 "and is" (图11)和 “and is not”(图12)逻辑的修改,达到快速进行不同过滤条件变更查询的目的。

图11

图12
3.2 在Kibana中使用
kuery-query和Lucene进行高阶查询
上面介绍了简单的过滤查询。而在实际日常查询分析中,往往需要较为复杂的查询,比如模糊搜索、范围搜索等。由于Kibana使用的查询语法既包括Lucene的查询语法,也包括其kibana自身的查询语言增强kuery-query,这样在应用在相对复杂查询时,在kibana查询框内的自定义内容查询。
下面了解下简单的Lucene查询语法,通过几个不同的示例,帮助我们在日常工作中更好的使用Kibana的进行日志和数据查询。
参考文档: https://www.elastic.co/guide/en/kibana/6.6/lucene-query.htmlhttps://www.elastic.co/guide/en/kibana/6.6/kuery-query.htmlhttps://www.elastic.co/guide/en/elasticsearch/reference/6.6/query-dsl-query-string-query.html#query-string-syntax
全文搜索:
直接在搜索框输入想查询的内容:${content} 或者 "${content}"
<span style="color: rgb(51,51,51);">引号在这里起到的作用是对搜索内容的限制,如果不写引号,那么搜索内容将按照分词处理,不区分内容顺序,比如你可能得到"quick fox brown"这样的结果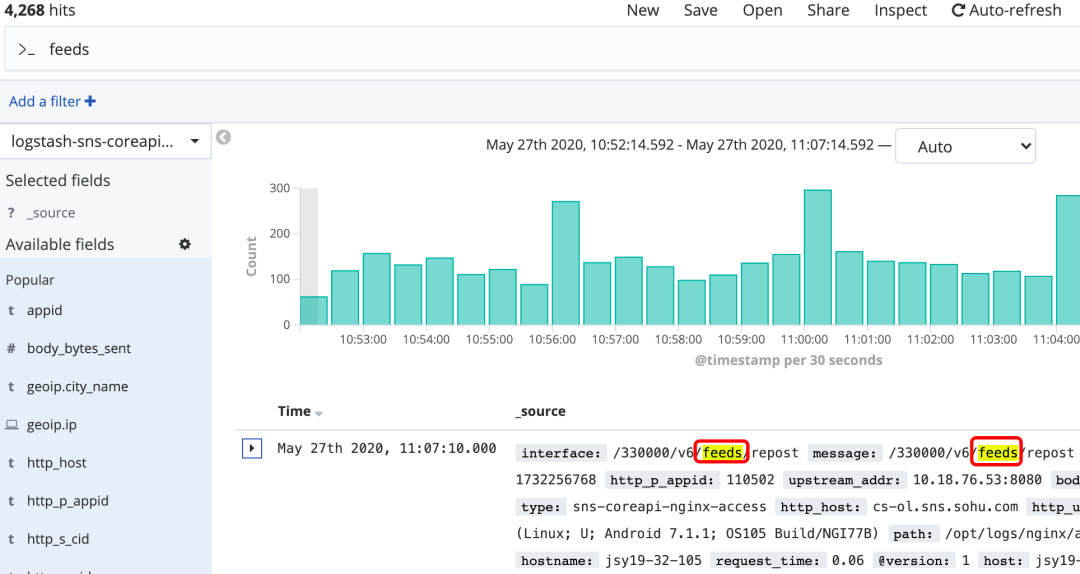
图13 全文搜索-针对所有内容
字段搜索:
field:value 或者field:"value"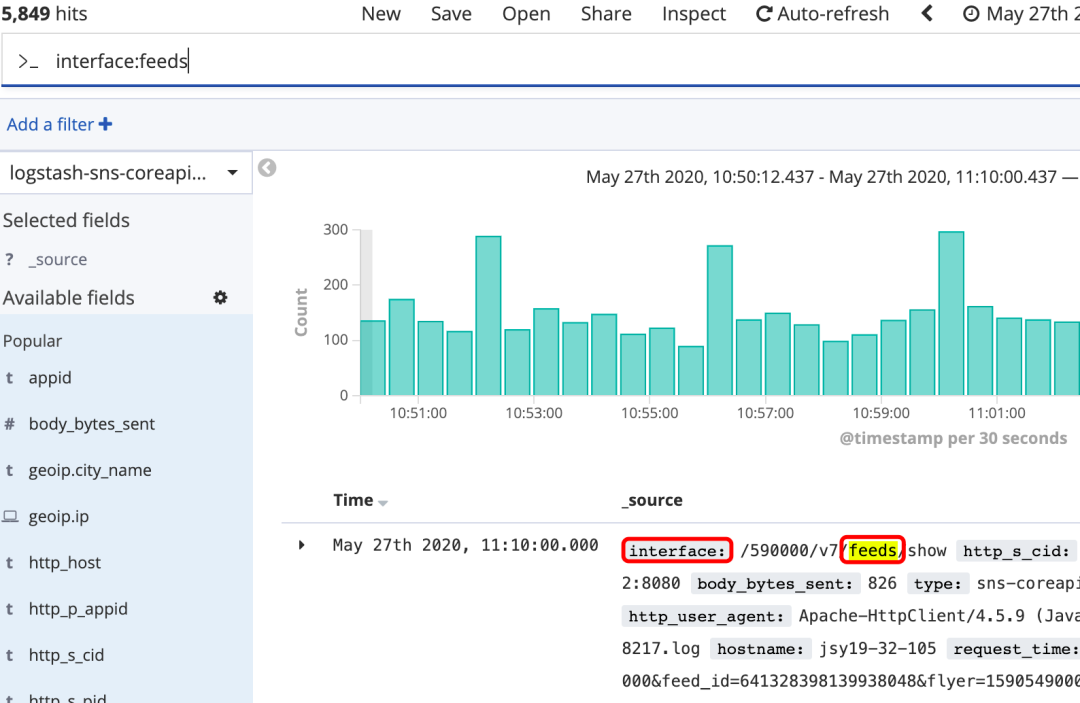
图14 字段搜索-只针对指定的字段
通配符:
? 匹配单个字符,如app?d
* 匹配0到多个字符,如searc*h
注意通配符都不可用作表示第一个字符,如*test,?test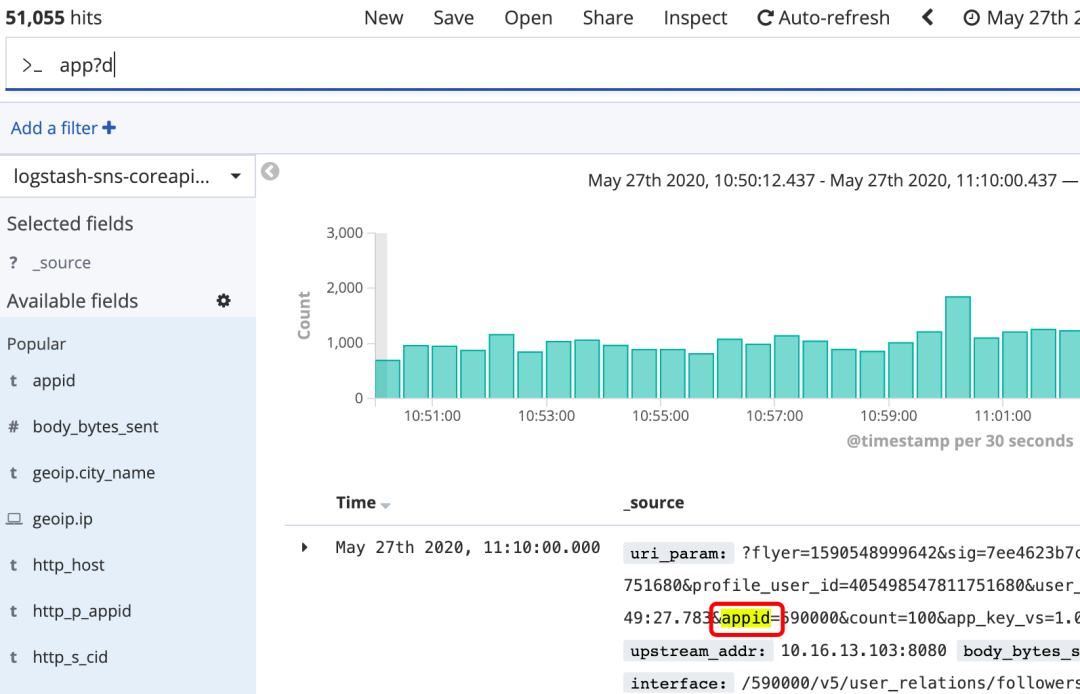
图15 通配符搜索
正则搜索:
支持简单的正则搜索,但效率很低,不推荐使用,使用时用"/"引用
[name:/joh?n(ath[oa]n)/](http://name/joh?n(ath[oa]n)/)模糊搜索:
quikc~ brwn~ foks~
~:在一个单词后面加上~启用模糊搜索,可以搜到一些拼写错误的单词
first~ 这种也能匹配到 frist
还可以设置编辑距离(整数),指定需要多少相似度
cromm~1 会匹配到 from 和 chrome
默认2,越大越接近搜索的原始值,设置为1基本能搜到80%拼写错误的单词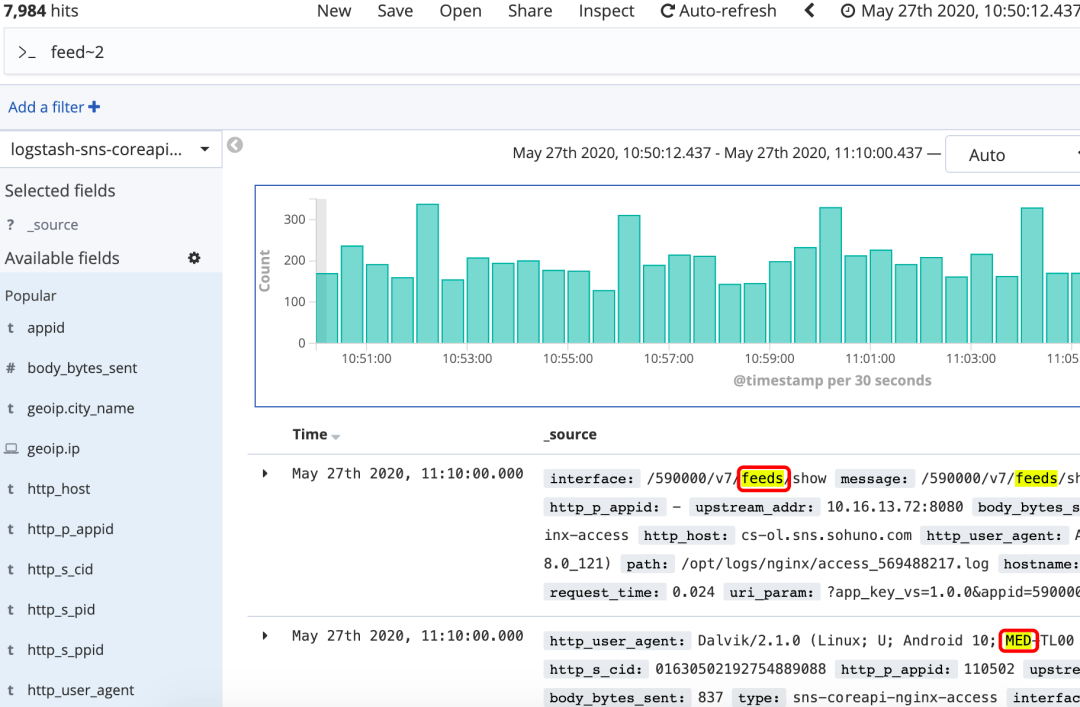
图16 模糊搜索
近似搜索:
在短语后加上~,可以搜到被隔开或顺序不同的单词
"fox quick"~5,表示fox和quick中间可以隔5个单词,可以搜索到"quick brown fox"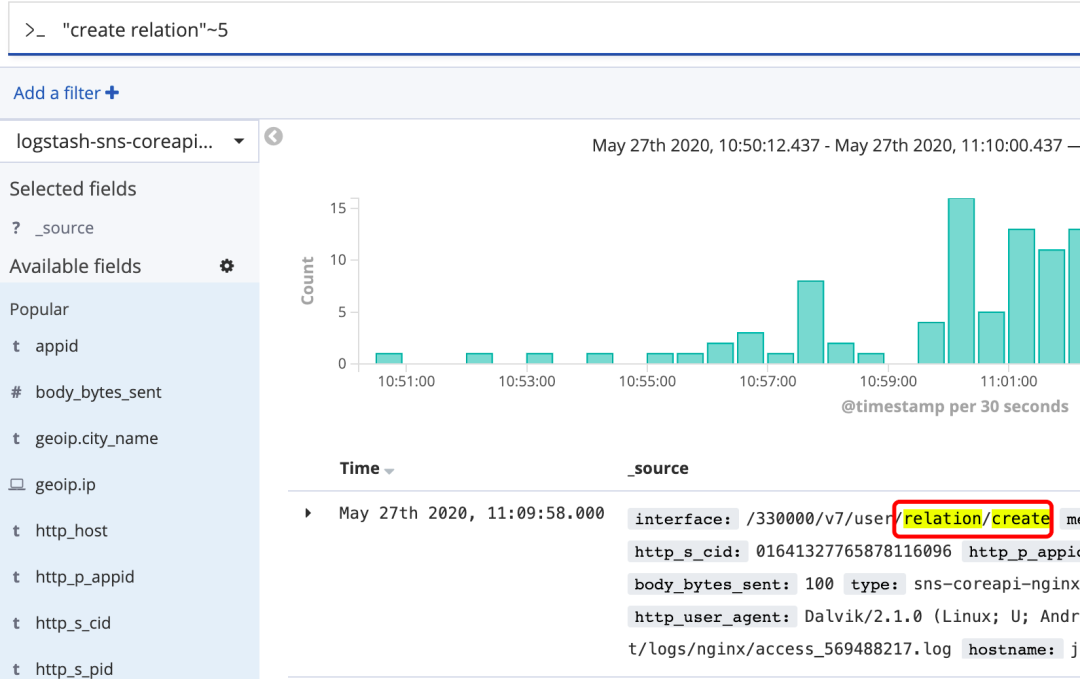
图17 近似搜索
范围搜索:
All days in 2012:
date:[2012-01-01 TO 2012-12-31]
Numbers 1..5
count:[1 TO 5]
Tags between alpha and omega, excluding alpha and omega:
tag:{alpha TO omega}
Numbers from 10 upwards
count:[10 TO *]
Dates before 2012
date:{* TO 2012-01-01}
1~5,但不包括5
[1,5}
可以简化成以下写法:
age:>10
age:<=10
age:(>=10 AND <20)
age:(+>=10 +<20)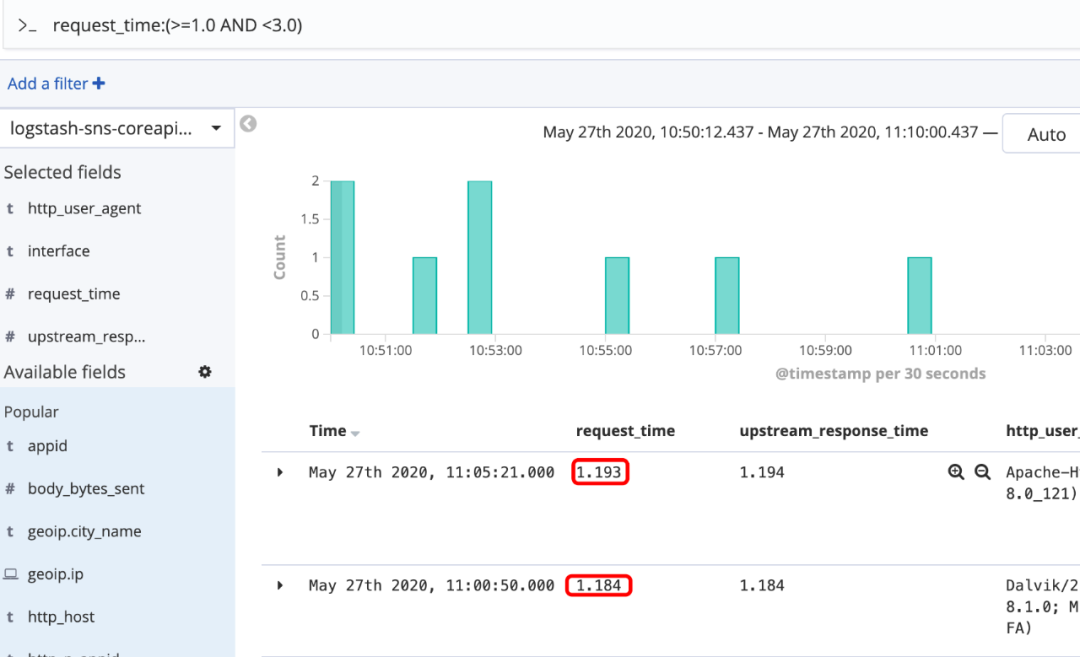
图18 范围搜索
优先级:
使用^表示,使一个词语比另一个搜索优先级更高,默认为1,可以为0~1之间的浮点数,来降低优先级
quick^2 fox逻辑操作:
AND OR + -
+:搜索结果中必须包含此项
-:不能含有此项
+appid -s-ppid aaa bbb ccc:结果中必须存在appid,不能有s-ppid,剩余部分尽量都匹配到
逻辑操作符kibana6也支持写为 && ,|| ,!,但不推荐使用
逻辑组合示例:((quick AND fox) OR (brown AND fox) OR fox) AND NOT news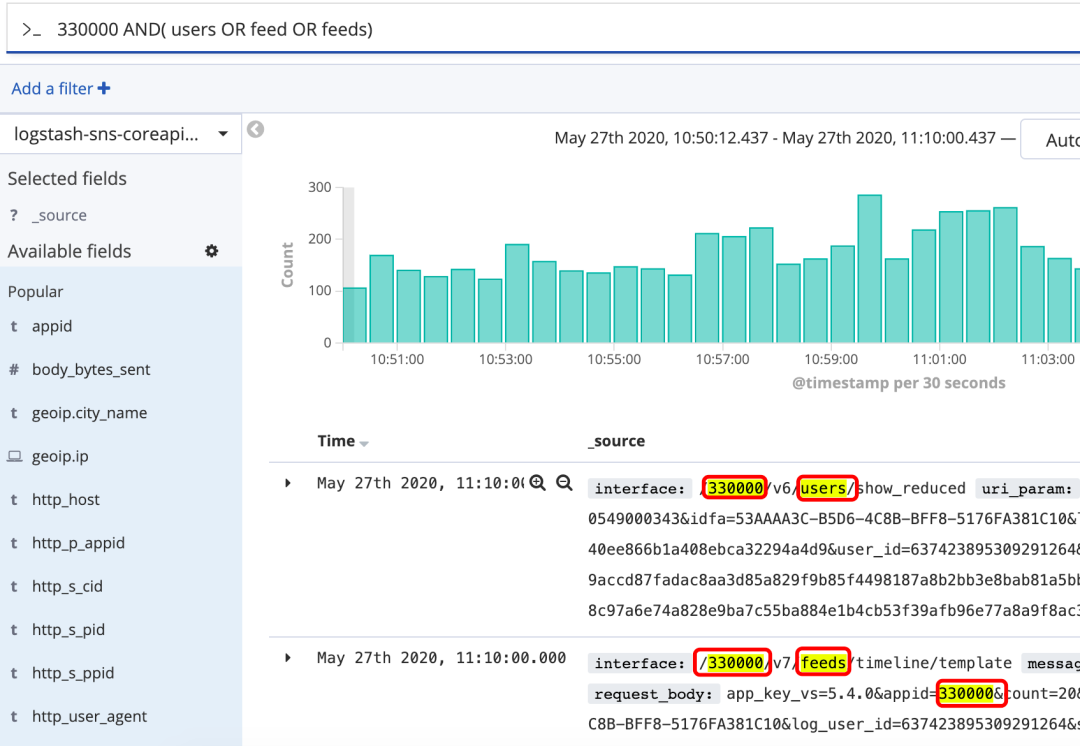
图19 逻辑操作符
转义特殊字符:
+ - = && || > < ! ( ) { } [ ] ^ " ~ * ? : \ /
以上字符当作值搜索的时候需要用\转义,其中< 和 > 根本无法规避,如果包含这两个字符只能另寻他法
\(1\+1\)\=2用来查询(1+1)=23.3数据统计
比如想要知道某个接口最近1小时都有哪些用户和他们的ip都来自哪些城市。这里就用到了kibana Visualize,点击Visualize + 按钮(图20),新增一个视图。
图20
如果想要统计一些字段并有可能需要在别的地方使用这些字段,应该使用 Data Table (图21)数据表视图,它可以下载成csv格式的文件。
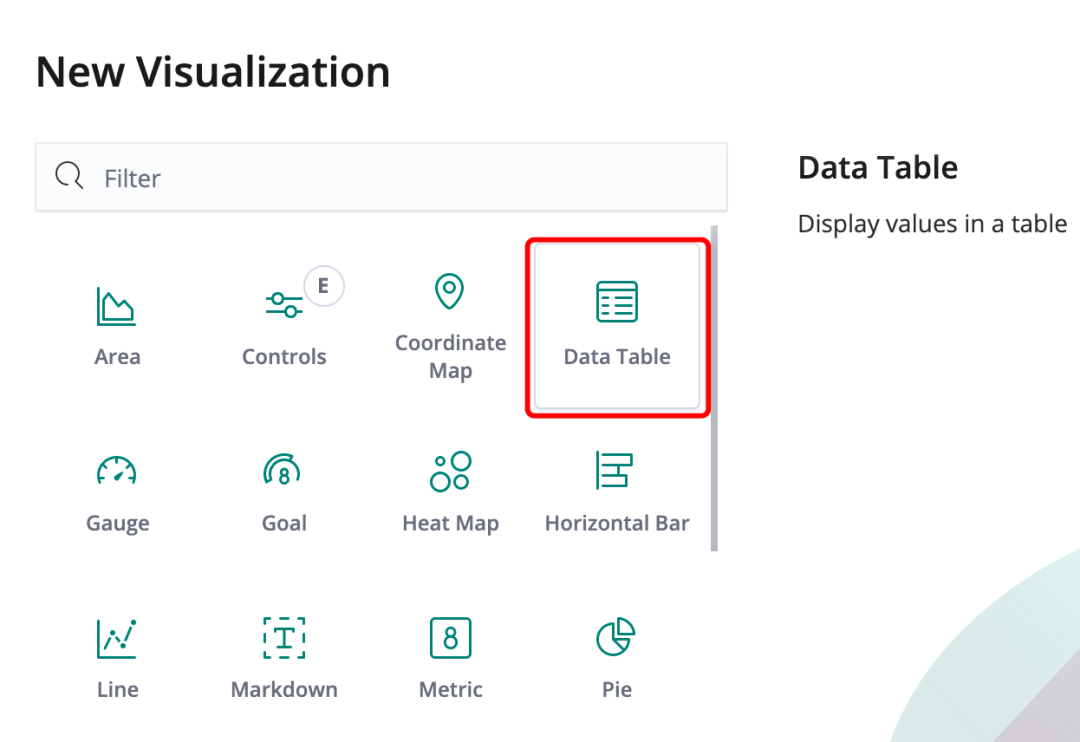
图21
选择Data Table后选择我们想要查询的索引 (图22)
图22
Kibana大多数的图标和数据表都分为 Metrics和Buckets两部分,Buckets里面配置的是“都有哪些值”;Metrics里面配置的是“对Buckets里面的这些值做什么统计操作”
例如(图23)制作出来的DataTable就是查询 interface包含“repost” 最近15分钟内 的 前10个调用最多的用户id。
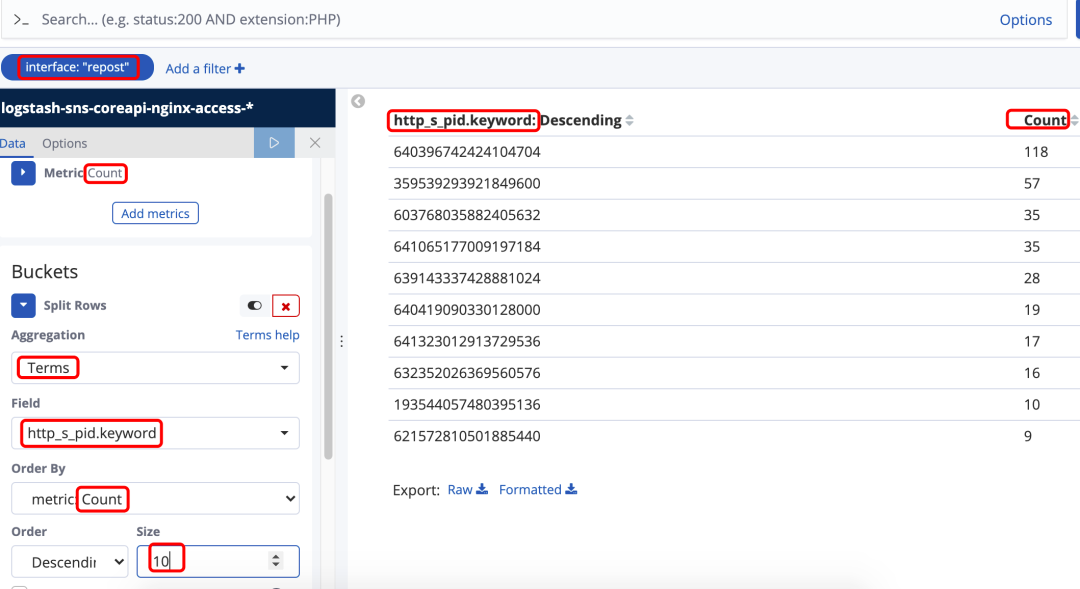
图23
在这个基础之上我们在增加一个Bucket(图24)
图24
我们在http_s_pid.keyword基础上增加一个新的 bucket(图25),使用的是geoip.city_name,图25中 数据表 2 所在列就是在 1 的前提下查询出来的城市名称
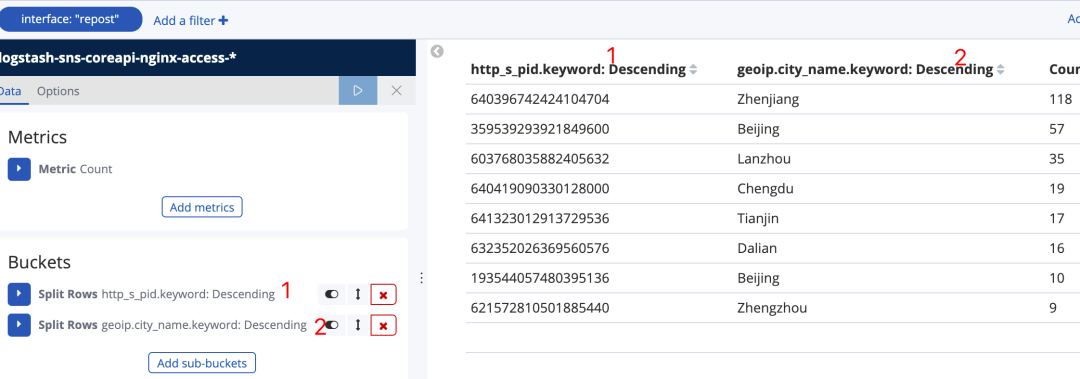
图25
我们可以给每个metric和bucket起别名(图26),然后点击 Raw或者 Formatted将查询到的数据下载成csv文件(图27)
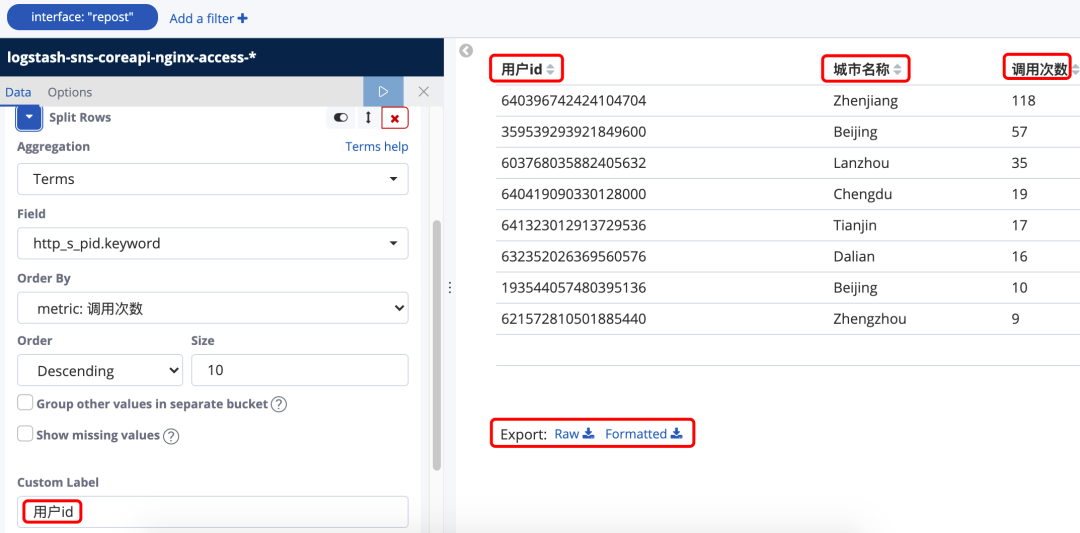
图26
图27
3.4 趋势图绘制
比如我们想要了解某些接口平均响应时间和50%,75%,95%的响应时间走向。就可以用折线图展示,使用Line视图(图28)
图28如图29我们统计的是最近1小时包含timeline/template的接口的调用数量折线图。想要统计响应时间,就要先修改Metric的统计方式。
这里重点说明一下想要进行均值,最大,最小,百分比分布等这些统计必须得有Number类型的字段,如果前期logstash没有进行合适的数据类型转换就需要增加 在kibana 对应的索引下增加 Script Field来实现基于某个字段的类型转换
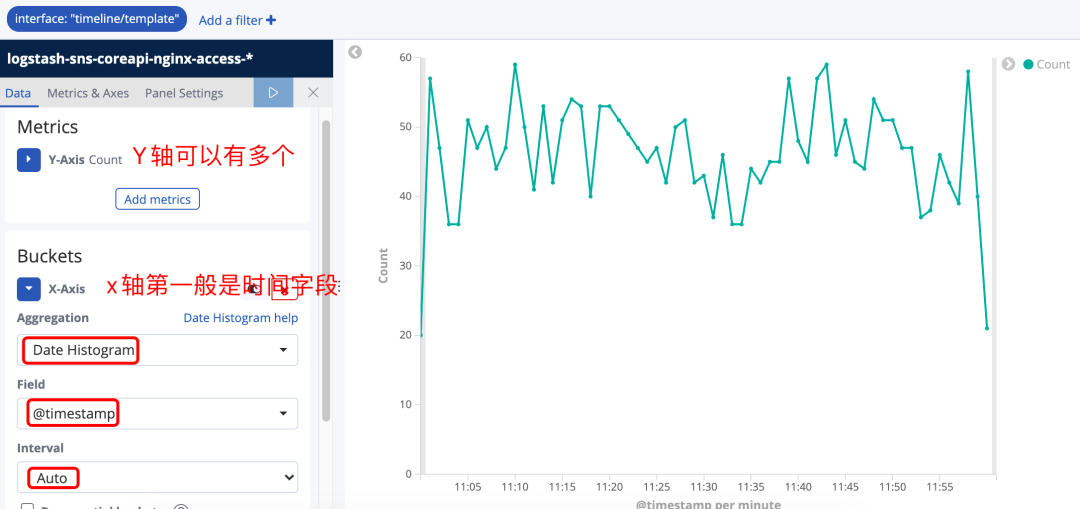
图29
我们增加两个Y-Axis的metric,分别是 对 request_time 求均值(图30)和对 request_time 求百分比分布(图30)
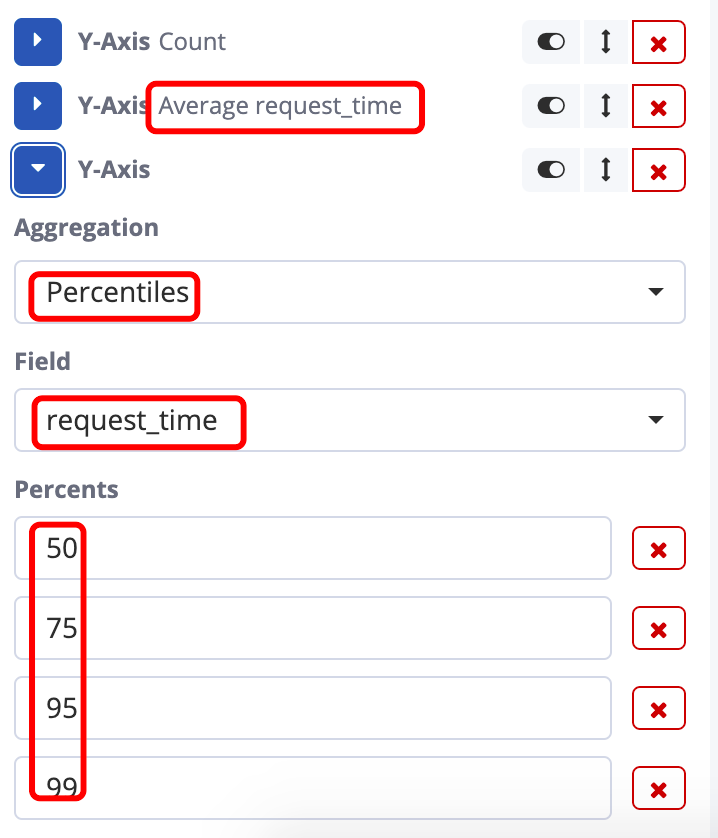
图30
最终的效果如下: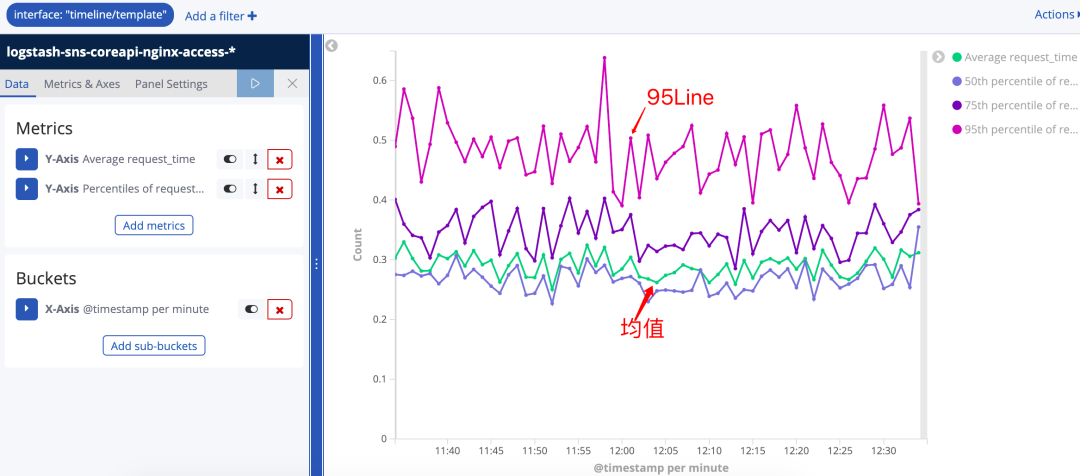
看下面两个图,首先在Metrics&Axes里面Y-Axes区域增加一个axis,然后再把上图中 “Percentiles of request_time” Value Axis选成 RightAxis-1
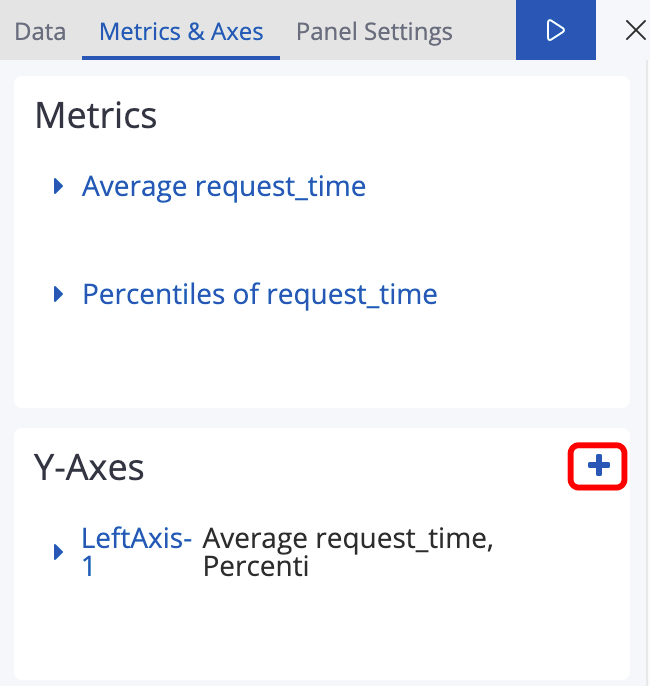
图32
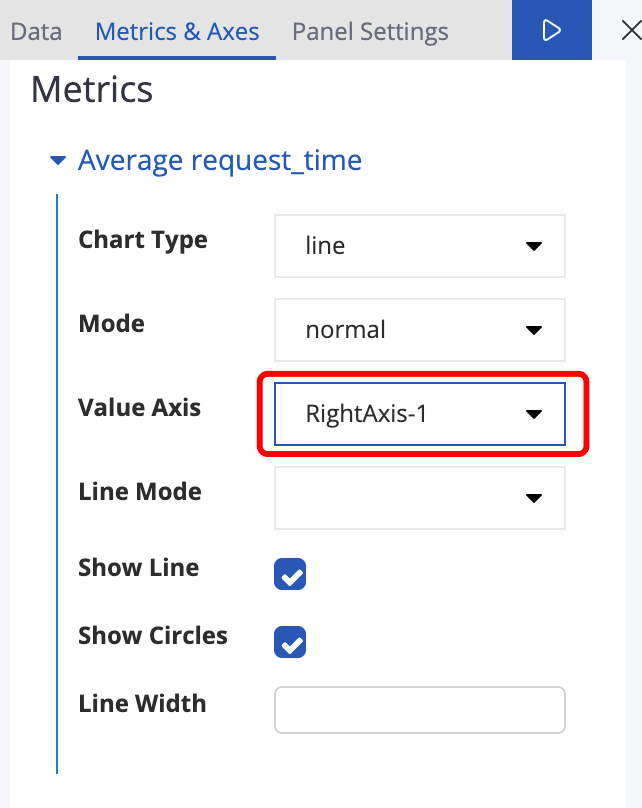
图33
这样经过坐标轴的分离就产生了(图34)效果,这样绿色的 1号metric的变化趋势就更明显了。
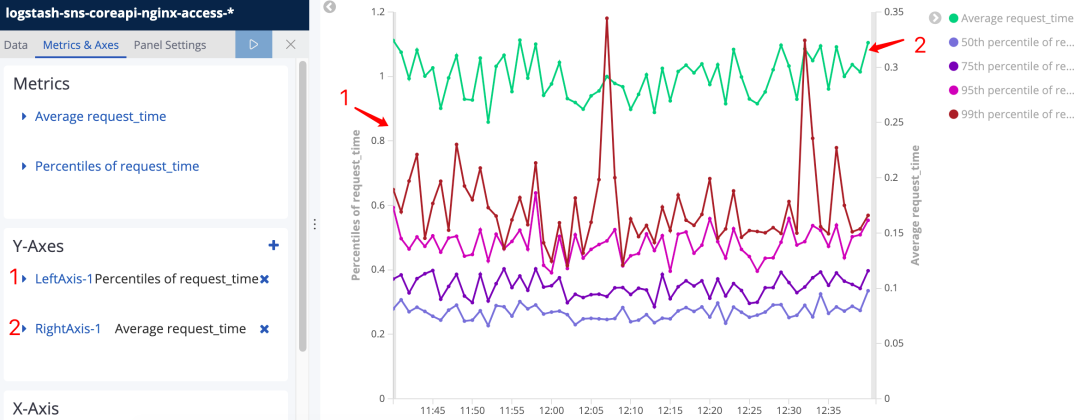
图34
我们还可以调整图表中的线模式和meterc图表类型,line mode 使用smoothed时可以使图表中的折线变得平滑;而chart type使用area就是将折线图变成面积图。
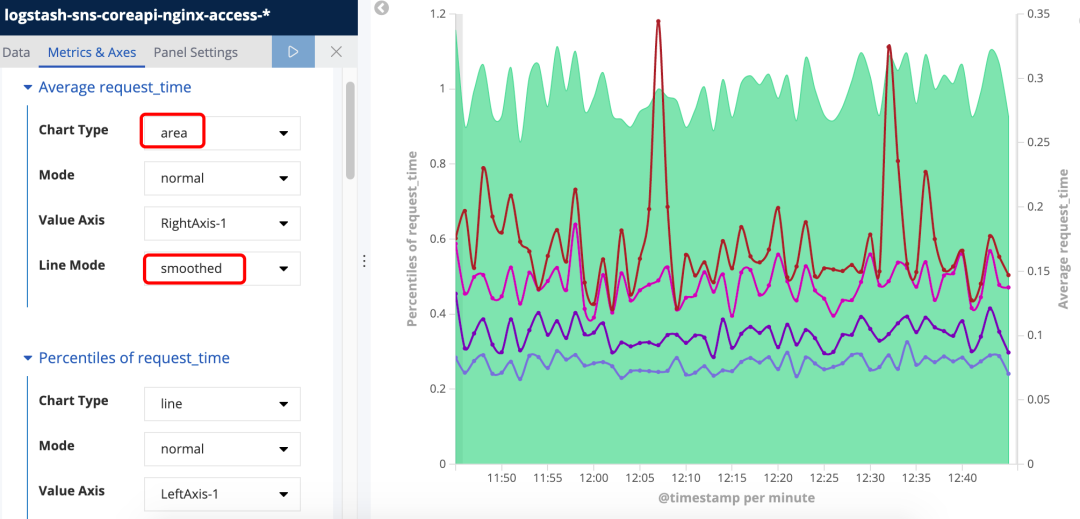
图35
PS:如何在Kibana增加索引
在上面的统计图表制作过程中,我们都要选择使用哪个索引。这个索引可以是Elasticsearch中某一个索引,也可以是某一组索引,比如按天建立的索引(logstash-index-yyyy.MM.dd)。
Kibana中的索引在建立的时候我们通常使用 "索引前缀"来表示一组索引,这也是Elasticsearch的api所支持的,在查询某个时间范围时Elasticsearch会根据给出的索引前缀选择合适的索引文件进行检索。
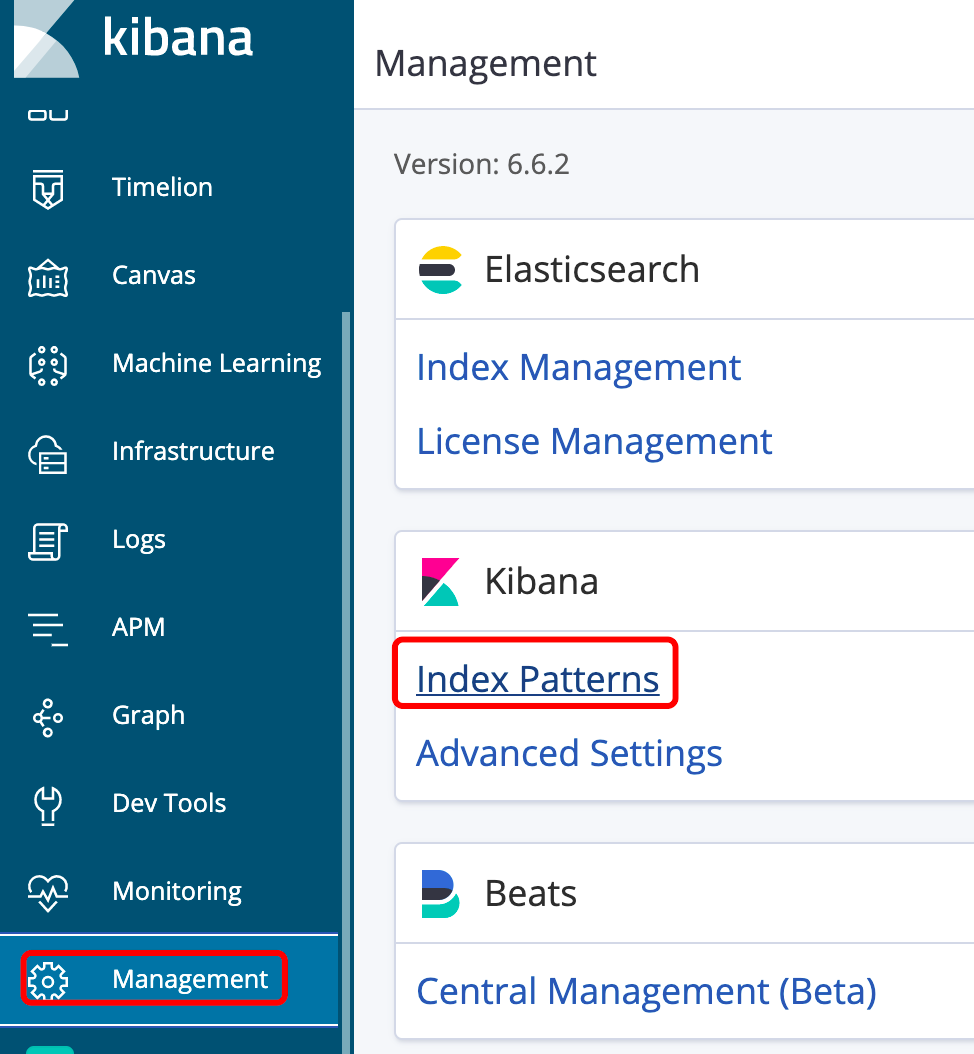
图36
首先在 Management菜单点击 IndexPatterns按钮 (图36),然后再(图37)位置点击“create index pattern” 按钮。
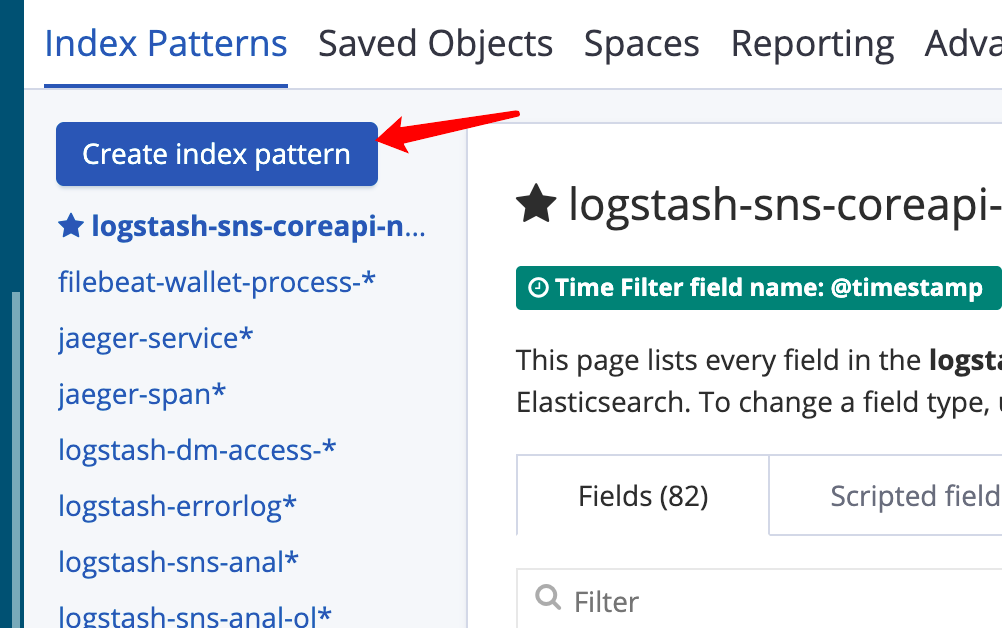
图37
之后我们在输入想要查询的索引前缀(图38),前提是Elasticsearch中已经建立好的索引
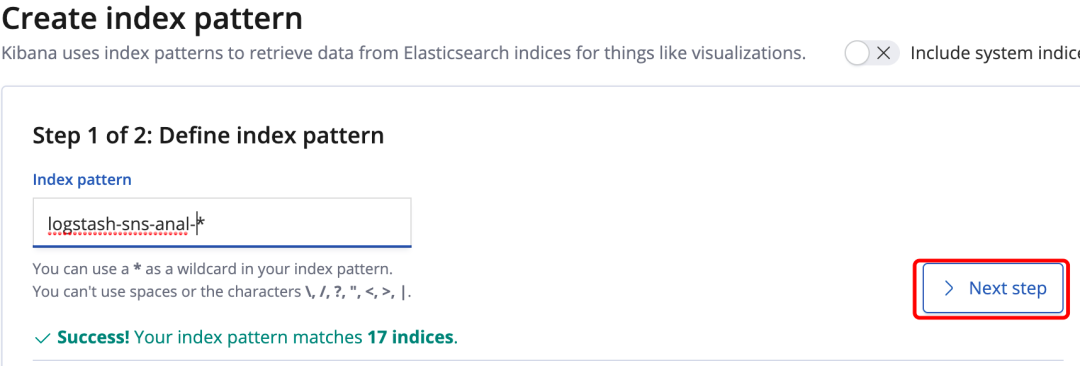
图38
最后选择使用哪个字段作为时间过滤字段(图39),我们在选择时间范围时是需要匹配到这个字段的。默认是@timestamp。点击“create index pattern”(图39)之后就完成了Kibana上的索引的增加操作。
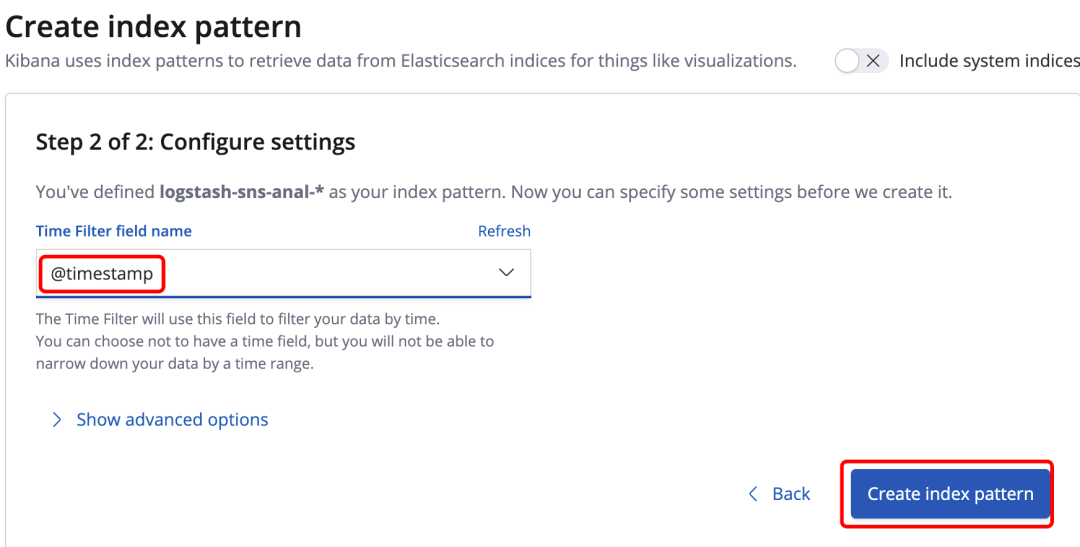
图39
至此,关于ELK平台的基础应用篇就介绍完了,希望工程师们学习掌握此项技能,并且能运用到日常工作中,进而能帮助大家提高工作效率。