分布式锁(数据库、Redis、ZK)拍了拍你
前言
标题使用最近异常火热的微信拍一拍的方式命名,最近拍一拍的玩法被各位网友玩坏了,出现了各种版本的拍一拍。
比如:下面的这个版本是不是似曾相识的感觉,曾几何时你也曾有这种冲动的想法,但是奈于生活,你不得不把这股冲动埋在心底,毕竟冲动是魔鬼。


对于老板和一个公司来说,公司付出的每一个商品都是有商用价值的,老板不会把没有商用的价值功能和产品创造出来。
对于拍一拍这个功能,我想是一个引导性的战略思维,对于这个拍一拍新功能,很多网友都会跃跃欲试,不经意间就会尝试,双击别人的头像进行拍一拍。
那么这个双击的动作可能将来微信服务于某项功能而做的准备,待微信的用户习惯了双击操作,微信对于后面的这类操作的功能的推广会变得更加容易。
好了,不能再深究下去了,要是被小马哥看到,估计小马哥就要拍一拍我了,这个纯属个人观点,不代表官方的观点,下面开始我们的分布式锁的讲解。
分布式锁简介
分布式锁的实现方式有以下三种方式:「数据库分布式锁、Redis实现分布式锁、ZooKeeper实现分布式锁」。
为什么需要分布式锁呢?在很久以前,用户全体不大的时候,单体应用就可以足够满足用户的所有请求,当用户增加的时候,出现了一定的并发度,可以使用简单的锁机制来协调并发的共享资源的获取。
但是,随着业务的增大,用户数量的增加,为了满足业务的高效性,集群的出现,简单的锁机制已经不能够满足协调多个应用之间的共享资源了,于是就出现了分布式锁。
分布式锁是协调集群中多应用之间的共享资源的获取的一种方式,可以说它是一种约束、规则。
那么对于一个分布式系统中分布式锁应该满足什么条件呢?也就是它应该具备怎样的约束、规则,下面是我总结的分布式锁至少拥有的几个规则。
1.「锁的互斥性」:在分布式集群应用中,共享资源的锁在同一时间只能被一个对象获取。2. 「可重入」:为了避免死锁,这把锁是可以重入的,并且可以设置超时。3. 「高效的加锁和解锁」:能够高效的加锁和解锁,获取锁和释放锁的性能也好。4. 「阻塞、公平」:可以根据业务的需要,考虑是使用阻塞、还是非阻塞,公平还是非公平的锁。
一个分布式锁能够具备上面的几种条件,应该来说是比较好的分布式锁了,但是现实中没有十全十美的锁,对于不同的分布式锁,没有最好,只能说那种场景更加适合。
下面我们详细的聊一聊上面说的三种分布式锁的实现原理,先来看看数据库的分布式锁。
数据库分布式锁
在数据库的分布式锁的实现中,分为「悲观锁和乐观锁」,「悲观锁的实现依赖于数据库自身的锁机制实现」。
若是要测试数据库的悲观的分布式锁,可以执行下面的sql:select … where … for update (排他锁),注意:where 后面的查询条件要走索引,若是没有走索引,会使用全表扫描,锁全表。
当一个数据库表被加上了排它锁,其它的客户端是不能够再对加锁的数据行加任何的锁,只能等待当前持有锁的释放锁。
全表扫描对于测试就没有太大意义了,where后面的条件是否走索引,要注意自己的索引的使用方式是否正确,并且还取决于「mysql优化器」。
排它锁是基于InnoDB存储引擎的,在执行操作的时候,在sql中加入for update,可以给数据行加上排它锁。
在代码的代码的层面上使用connection.commit();,便可以释放锁,但是数据库复杂的加锁和解锁、事务等一系列消耗性能的操作,终归是无法抗高并发。
数据库乐观锁的方式实现分布式锁是基于「版本号控制」的方式实现,类似于「CAS的思想」,它认为操作的过程并不会存在并发的情况,只有在update version的时候才会去比较。
乐观锁的方式并没有锁的等待,不会因为所等待而消耗资源,下面来测试一下乐观锁的方式实现的分布式锁。
乐观锁的方式实现分布式锁要基于数据库表的方式进行实现,我们认为在数据库表中成功存储该某方法的线程获取到该方法的锁,才能操作该方法。
首先要创建一个表用于储存各个线程操作方法的对应该关系表LOCK:
CREATE TABLE `LOCK` (
`ID` int PRIMARY KEY NOT NULL AUTO_INCREMENT,
`METHODNAME` varchar(64) NOT NULL DEFAULT '',
`DESCRIPTION` varchar(1024) NOT NULL DEFAULT '',
`TIME` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
UNIQUE KEY `UNIQUEMETHODNAME` (`METHODNAME`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;该表是存储某个方法的是否已经被锁定的信息,若是被锁定则无法获取到该方法的锁,这里注意的是使用UNIQUE KEY唯一约束,表示该方法布恩那个够被第二个线程同时持有。
当你要获取锁的时候,通过执行下面的sql来尝试获取锁:insert into LOCK(METHODNAME,DESCRIPTION) values (‘getLock’,‘获取锁’) ;来获取锁。
这条sql执行的结果有两种成功和失败,成功说明该方法还没有被某个线程所持有,失败则表明数据库中已经存在该条数据,该方法的锁已经被某个线程所持有。
当你需要释放锁的时候,可以通过执行这条sql:delete from LOCK where METHODNAME='getLock';来释放锁。
乐观锁实现方式还是存在很多问题的,一个是「并发性能问题」,再者「不可重入」以及「没有自动失效的功能」、「非公平锁」,只要当前的库表中已经存在该信息,执行插入就会失败。
其实,对于上面的问题基于数据库也可以解决,比如:不可重复,你可以「增加字段保存当前线程的信息以及可重复的次数」,只要是再判断是当前线程,可重复的次数就会+1,每次执行释放锁就会-1,直到为0。
「没有失效的功能,可以增加一个字段存储最后的失效时间」,根据这个字段判断当前时间是否大于存储的失效时间,若是大于则表明,该方法的索索已经可以被释放。
「非公平锁可以增加一个中间表的形式,作为一个排队队列」,竞争的线程都会按照时间存储于这个中间表,当要某个线程尝试获取某个方法的锁的时候,检查中间表中是否已经存在等待的队列。
每次都只要获取中间表中最小的时间的锁,也实现公平的排队等候的效果,所有的问题总是有解决的思路。
上面就是两种基于数据库实现分布式锁的方式,但是,数据库实现分布式锁的方式只作为学习的例子,实际中不会使用它作为实现分布式锁,重要的是学习解决问题的思路和思想。
Redis实现的分布式锁
之前讲了一篇Redis事务的文章,很多读者Redis事务有啥用,主要是因为Redis的事务并没有Mysql的事务那么强大,所以一般的公司一般确实是用不到。[面试竟被问到Redis事务,触及知识盲区,脸都绿了]
这里就来说一说Redis事务的一个实际用途,它可以用来实现一个简单的秒杀系统的库存扣减,下面我们就来进行代码的实现。
(1)首先使用线程池初始化5000个客户端。
public static void intitClients() {
ExecutorService threadPool= Executors.newCachedThreadPool();
for (int i = 0; i < 5000; i++) {
threadPool.execute(new Client(i));
}
threadPool.shutdown();
while(true){
if(threadPool.isTerminated()){
break;
}
}
}(2)接着初始化商品的库存数为1000。
public static void initPrductNum() {
Jedis jedis = RedisUtil.getInstance().getJedis();
jedisUtils.set("produce", "1000");// 初始化商品库存数
RedisUtil.returnResource(jedis);// 返还数据库连接
}
}(3)最后是库存扣减的每条线程的处理逻辑。
/**
* 顾客线程
*
*
*/
class client implements Runnable {
Jedis jedis = null;
String key = "produce"; // 商品数量的主键
String name;
public ClientThread(int num) {
name= "编号=" + num;
}
public void run() {
while (true) {
jedis = RedisUtil.getInstance().getJedis();
try {
jedis.watch(key);
int num= Integer.parseInt(jedis.get(key));// 当前商品个数
if (num> 0) {
Transaction ts= jedis.multi(); // 开始事务
ts.set(key, String.valueOf(num - 1)); // 库存扣减
List<Object> result = ts.exec(); // 执行事务
if (result == null || result.isEmpty()) {
System.out.println("抱歉,您抢购失败,请再次重试");
} else {
System.out.println("恭喜您,抢购成功");
break;
}
} else {
System.out.println("抱歉,商品已经卖完");
break;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
jedis.unwatch(); // 解除被监视的key
RedisUtil.returnResource(jedis);
}
}
}
}在代码的实现中有一个重要的点就是「商品的数据量被watch了」,当前的客户端只要发现数量被改变就会抢购失败,然后不断的自旋进行抢购。
这个是基于Redis事务实现的简单的秒杀系统,Redis事务中的watch命令有点类似乐观锁的机制,只要发现商品数量被修改,就执行失败。
Redis实现分布式锁的第二种方式,可以使用setnx、getset、expire、del这四个命令来实现。
setnx:命令表示如果key不存在,就会执行set命令,若是key已经存在,不会执行任何操作。getset:将key设置为给定的value值,并返回原来的旧value值,若是key不存在就会返回返回nil 。expire:设置key生存时间,当当前时间超出了给定的时间,就会自动删除key。del:删除key,它可以删除多个key,语法如下:DEL key [key …],若是key不存在直接忽略。
下面通过一个代码案例是实现以下这个命令的操作方式:
public void redis(Produce produce) {
long timeout= 10000L; // 超时时间
Long result= RedisUtil.setnx(produce.getId(), String.valueOf(System.currentTimeMillis() + timeout));
if (result!= null && result.intValue() == 1) { // 返回1表示成功获取到锁
RedisUtil.expire(produce.getId(), 10);//有效期为5秒,防止死锁
//执行业务操作
......
//执行完业务后,释放锁
RedisUtil.del(produce.getId());
} else {
System.println.out("没有获取到锁")
}
}在线程A通过setnx方法尝试去获取到produce对象的锁,若是获取成功就会返回1,获取不成功,说明当前对象的锁已经被其它线程锁持有。
获取锁成功后并设置key的生存时间,能够有效的防止出现死锁,最后就是通过del来实现删除key,这样其它的线程就也可以获取到这个对象的锁。
执行的逻辑很简单,但是简单的同时也会出现问题,比如你在执行完setnx成功后设置生存时间不生效,此时服务器宕机,那么key就会一直存在Redis中。
当然解决的办法,你可以在服务器destroy函数里面再次执行:
RedisUtil.del(produce.getId());或者通过「定时任务检查是否有设置生存时间」,没有的话都会统一进行设置生存时间。
还有比较好的解决方案就是,在上面的执行逻辑里面,若是没有获取到锁再次进行key的生存时间:
public void redis(Produce produce) {
long timeout= 10000L; // 超时时间
Long result= RedisUtil.setnx(produce.getId(), String.valueOf(System.currentTimeMillis() + timeout));
if (result!= null && result.intValue() == 1) { // 返回1表示成功获取到锁
RedisUtil.expire(produce.getId(), 10);//有效期为10秒,防止死锁
//执行业务操作
......
//执行完业务后,释放锁
RedisUtil.del(produce.getId());
} else {
String value= RedisUtil.get(produce.getId());
// 存在该key,并且已经超时
if (value!= null && System.currentTimeMillis() > Long.parseLong(value)) {
String result = RedisUtil.getSet(produce.getId(), String.valueOf(System.currentTimeMillis() + timeout));
if (result == null || (result != null && StringUtils.equals(value, result))) {
RedisUtil.expire(produce.getId(), 10);//有效期为10秒,防止死锁
//执行业务操作
......
//执行完业务后,释放锁
RedisUtil.del(produce.getId());
} else {
System.println("没有获取到锁")
}
} else {
System.println("没有获取到锁")
}
}
}这里对上面的代码进行了改进,在获取setnx失败的时候,再次重新判断该key的锁时间是否失效或者不存在,并重新设置生存的时间,避免出现死锁的情况。
第三种Redis实现分布式锁,可以使用Redisson来实现,它的实现简单,已经帮我们封装好了,屏蔽了底层复杂的实现逻辑。
先来一个Redisson的原理图,后面会对这个原理图进行详细的介绍:
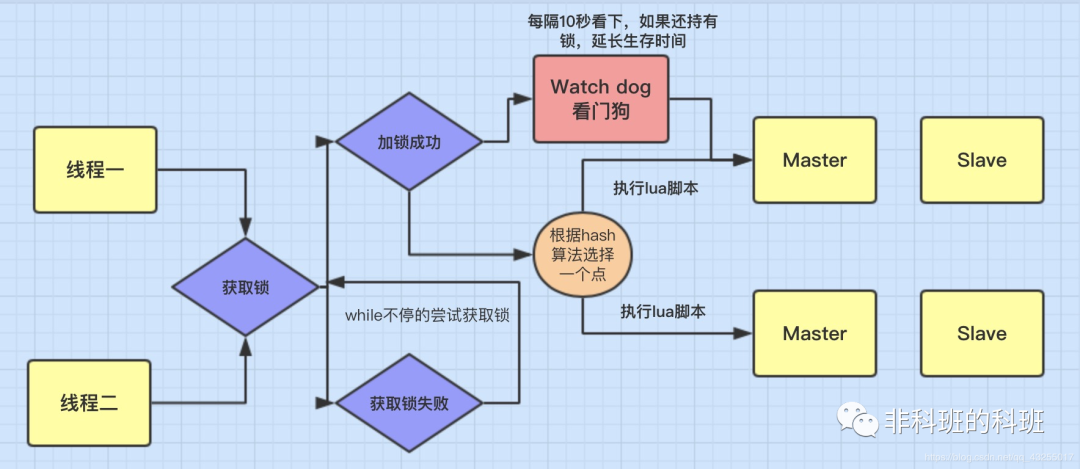
图片来源于网络
我们在实际的项目中要使用它,只需要引入它的依赖,然后执行下面的代码:
RLock lock = redisson.getLock("lockName");
lock.locl();
lock.unlock();并且它还支持「Redis单实例、Redis哨兵、redis cluster、redis master-slave」等各种部署架构,都给你完美的实现,不用自己再次拧螺丝。
但是,crud的同时还是要学习一下它的底层的实现原理,下面我们来了解下一下,对于一个分布式的锁的框架主要的学习分为下面的5个点:
- 加锁机制
- 解锁机制
- 生存时间延长机制
- 可重入加锁机制
- 锁释放机制
只要掌握一个框架的这五个大点,基本这个框架的核心思想就已经掌握了,若是要你去实现一个锁机制框架,就会有大体的一个思路。
Redisson中的加锁机制是通过lua脚本进行实现,Redisson首先会通过「hash算法」,选择redis cluster集群中的一个节点,接着会把一个lua脚本发送到Redis中。
它底层实现的lua脚本如下:
returncommandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));「redis.call()的第一个参数表示要执行的命令,KEYS[1]表示要加锁的key值,ARGV[1]表示key的生存时间,默认时30秒,ARGV[2]表示加锁的客户端的ID。」
比如第一行中redis.call('exists', KEYS[1]) == 0) 表示执行exists命令判断Redis中是否含有KEYS[1],这个还是比较好理解的。
lua脚本中封装了要执行的业务逻辑代码,它能够保证执行业务代码的原子性,它通过hset lockName命令完成加锁。
若是第一个客户端已经通过hset命令成功加锁,当第二个客户端继续执行lua脚本时,会发现锁已经被占用,就会通过pttl myLock返回第一个客户端的持锁生存时间。
若是还有生存时间,表示第一个客户端会继续持有锁,那么第二个客户端就会不停的自旋尝试去获取锁。
假如第一个客户端持有锁的时间快到期了,想继续持有锁,可以给它启动一个watch dog看门狗,他是一个后台线程会每隔10秒检查一次,可以不断的延长持有锁的时间。
Redisson中可重入锁的实现是通过incrby lockName来实现,「重入一个计数就会+1,释放一次锁计数就会-1」。
最后,使用完锁后执行del lockName就可以直接「释放锁」,这样其它的客户端就可以争抢到该锁了。
这就是分布式锁的开源Redisson框架底层锁机制的实现原理,我们可以在生产中实现该框架实现分布式锁的高效使用。
下面通过一个多窗口抢票的例子代码来实现:
public class SellTicket implements Runnable {
private int ticketNum = 1000;
RLock lock = getLock();
// 获取锁
private RLock getLock() {
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
Redisson redisson = (Redisson) Redisson.create(config);
RLock lock = redisson.getLock("keyName");
return lock;
}
@Override
public void run() {
while (ticketNum>0) {
// 获取锁,并设置超时时间
lock.lock(1, TimeUnit.MINUTES);
try {
if (ticketNum> 0) {
System.out.println(Thread.currentThread().getName() + "出售第 " + ticketNum-- + " 张票");
}
} finally {
lock.unlock(); // 释放锁
}
}
}
}测试的代码如下:
public class Test {
public static void main(String[] args) {
SellTicket sellTick= new SellTicket();
// 开启5五条线程,模拟5个窗口
for (int i=1; i<=5; i++) {
new Thread(sellTick, "窗口" + i).start();
}
}
}是不是感觉很简单,因为多线程竞争共享资源的复杂的过程它在底层都帮你实现了,屏蔽了这些复杂的过程,而你也就成为了优秀的API调用者。
上面就是Redis三种方式实现分布式锁的方式,基于Redis的实现方式基本都会选择Redisson的方式进行实现,因为简单命令,不用自己拧螺丝,开箱即用。
ZK实现的分布式锁
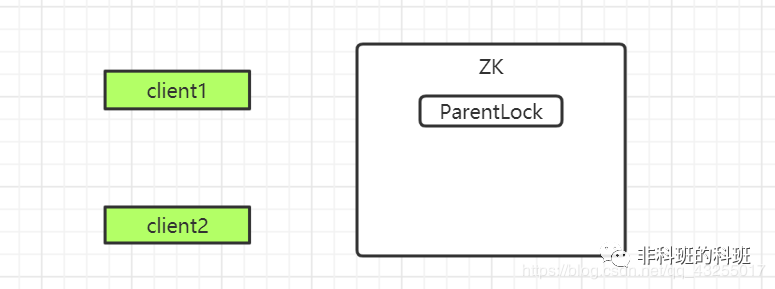
ZK实现的分布式锁的原理是基于一个「临时顺序节点」实现的,开始的时候,首先会在ZK中创建一个ParentLock持久化节点。
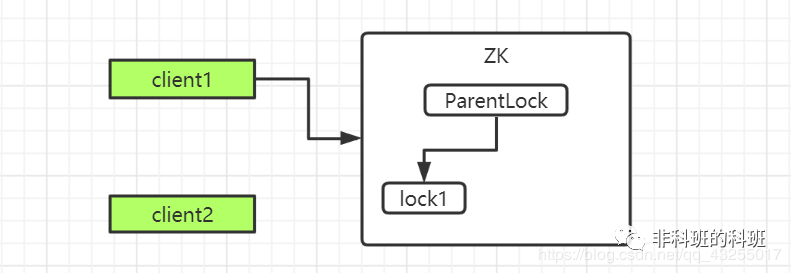
当client1创建完临时顺序节点后,就会检查ParentLock下面的所有的子节点,会判断自己前面是否还有节点,此时明显是没有的,所以获取锁成功。
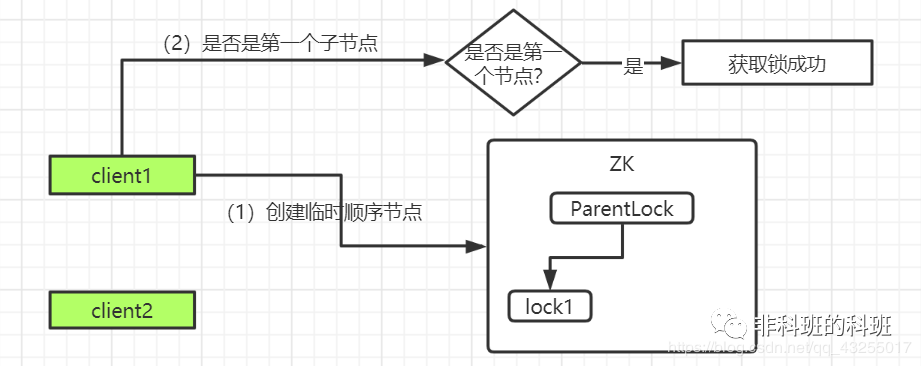
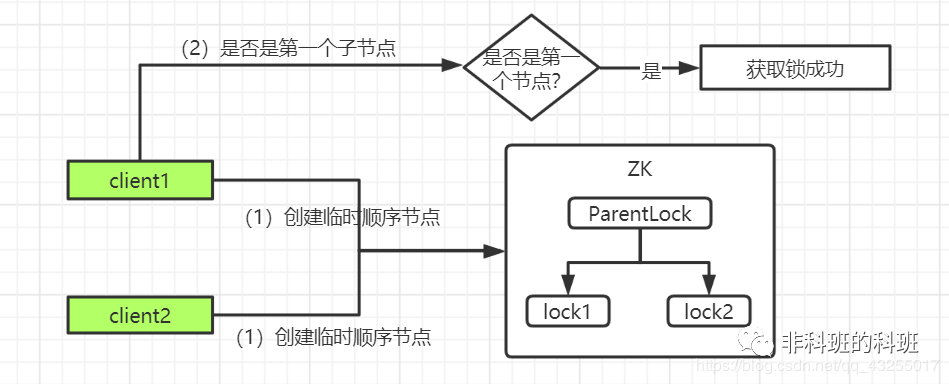
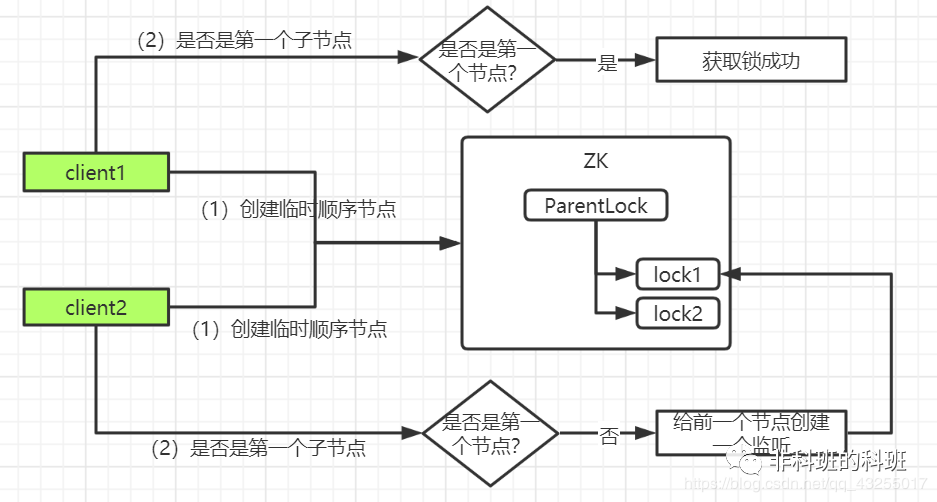
那么此时client2会创建一个对client1的lock1的监听(Watcher),用于监听lock1是否存在,同时client2会进入等待状态:


总结
三种方案的比较,从不同的角度看这三种实现方式,比较的结果也不一样:
- 性能:缓存 > Zookeeper >= 数据库。
- 可靠性:Zookeeper > 缓存 > 数据库