Volley 原理解析
本文主要从源码的角度分析 Volley 的原理。
我们在使用Volley的时候,首先需要通过 Volley.newRequestQueue(mContext) 获取到RequestQueue的一个实例,我们就以此为入口,开始分析。看一下newRequestQueue的实现代码
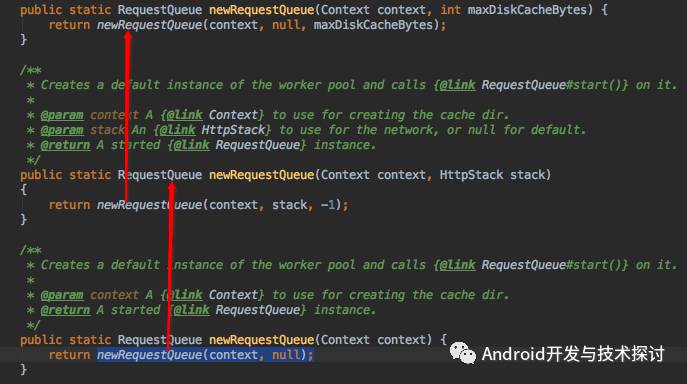
在Volley.newRequestQueue(mContext)方法中调用重载方法,一直调用到newRequestQueue(Context context,HttpStack stack, intmaxDiskCacheBytes) 方法。我们看一下这里的实现,代码如下:
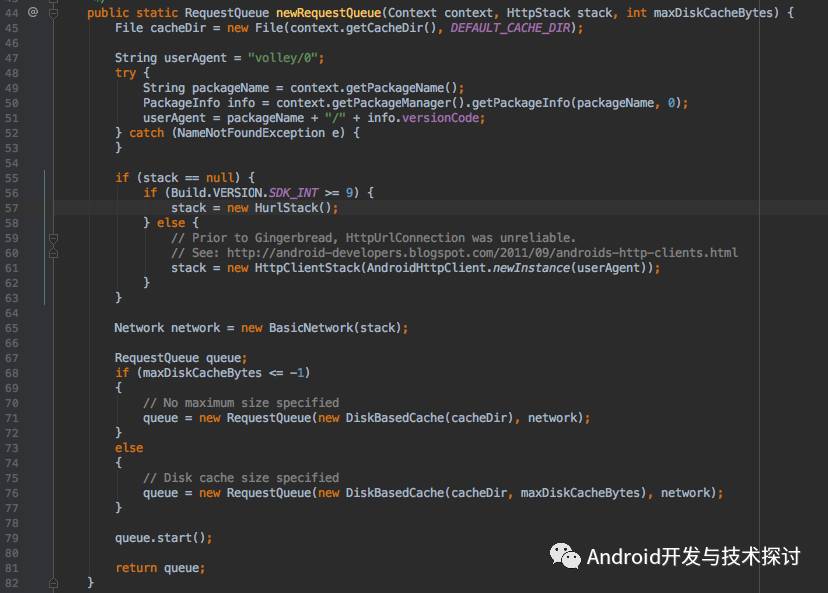
从第55开始,对stack进行了赋值操作,当sdk version 大于等于9 的是时候使用了HurlStack初始化,否则使用HttpClientStack初始化,这里其实就是根据系统版本选择了网络通讯的方式,当Android系统版本大于等于2.3时使用了 HurlStack(内部由HttpURLConnection实现),小于2.3版本使用HttpClientStack(内部由HttpClient实现)。
这里之所以这样实现,有三个原因:
1.HttpClient 的API 很多,稳定,易操作,但扩展性差。
2.HttpURLConnection 相比HttpClient API比较简单,扩展性很好。
3.HttpURLConnection在2.3版本之前存在严重bug
好了,回归正题,创建好之后stack之后,在第65行创建了Network的一个实例,Network是用于处理网络请求的,大家可以看下Network 源码中的performRequest方法,紧接着从67行开始,创建了RequestQueue对象,并调用了RequestQueue 的start方法,这里很重要,我们看下代码:
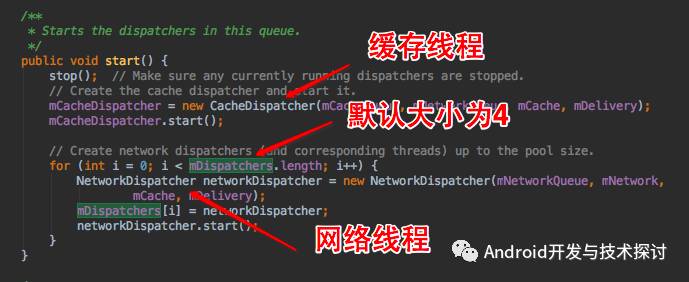
在这个方法中 有两个比较关键的类CacheDispatcher和NetworkDispatcher,CacheDispatcher和NetworkDispatcher都是继承自Thread。我们可以看到,这里实例化了一个CacheDispatcher线程和若干个NetworkDispatcher线程,并执行了start方法。
到这里我们知道,当初始化RequestQueue的时候会启动5个线程,1个缓存线程,默认4个网络线程。既然是线程我们看一下CacheDispatcher和NetworkDispatcher的run方法,首先看下NetworkDispatcher的run方法
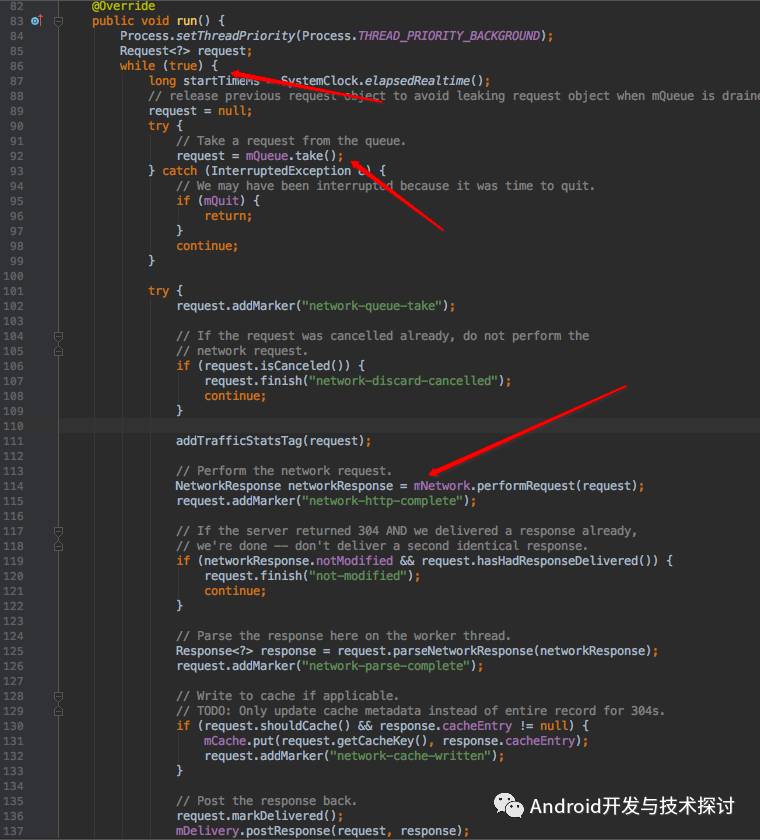
大家可以看到在86行的地方是while(true),死循环,说明这个线程会一直执行,有点意思,我们继续往下看,在第92行的地方,我们从队列中拿到一个request,并且在第114行的地方 调用mNetwork.performRequest(request);发起网络请求,到这里 就完成了从网络获取数据的操作。
之后在125行,调用了request.parseNetworkResponse 对数据进行解析,在130行处,写入缓存,然后在148行代码处调用了mDelivery.postResponse方法 回调数据。
Volley 提供的StringRequest,JsonRequest 包括我们自定义的request,都是继承自Request,Request中有两个方法是我们必须要重写的,一个是parseNetworkResponse解析数据,另一个是deliverResponse回调。
parseNetworkResponse
这个方法主要是用来解析数据的,在114行代码处拿到网络相应NetworkResponse后,在125行代码 ,调用了parseNetworkResponse方法,数据解析完成之后,返回了一个Response对象。

拿到Response对象之后 在137行代码调用了ExecutorDelivery的postResponse方法回调数据,我们看下这里的实现
ExecutorDelivery
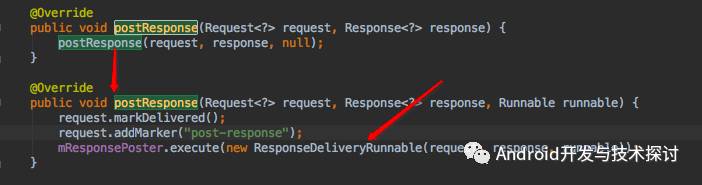
这里在postResponse方法中调用了mResponsePoster的execute 方法并传入了一个ResponseDeliveryRunnable对象,我们先看下mResponsePoster的实现,代码如下:
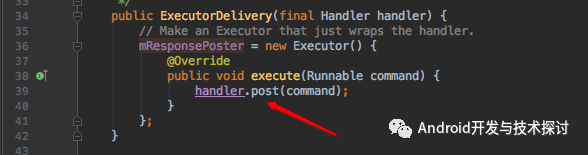
看到这里我想大家都应该明白了,handler.post 使上文传进去的Runnable对象中的run方法 在主线程中执行。
我们继续看ResponseDeliveryRunnable的实现,代码如下:
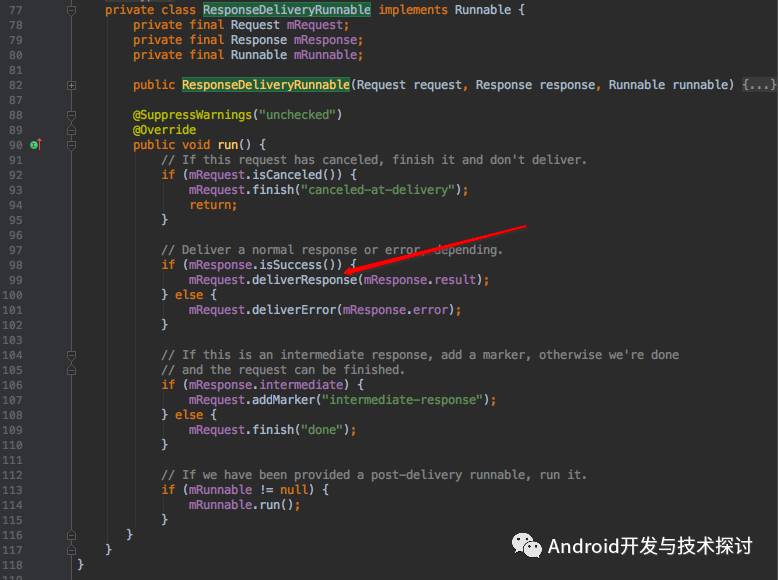
我们只看核心代码,第99行调用了mRequest.deliverResponse方法,这样最终回调到了request的deliverResponse方法,我们可以在这里将数据回调到Response.Listener中的onResponse()方法。代码如下:

现在我再看下CacheDispatcher的run方法,代码如下:

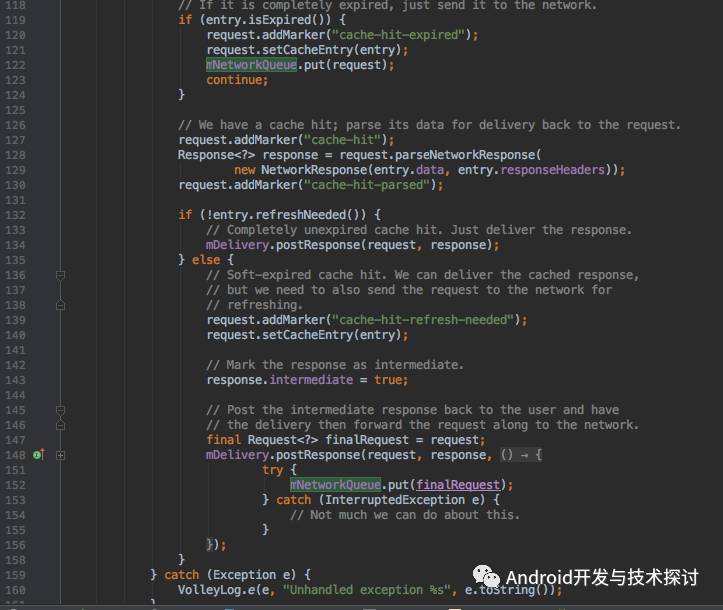
和NetworkDispatcher一样 CacheDispatcher 也启动了一个死循环,代码92行,从缓存队列中获取request,在100行通过mCache.get(request.getCacheKey());从缓存中获取结果,如果为空或者已过期则将请求加入网络队列中,在代码132处,判断了代码的新鲜度,如果数据不需要刷新则回调数据,如果需要刷新,则回调缓存数据之后将请求加入网络队列中。
wait...好像漏了点什么,队列中的请求哪里来?
Volley.newRequestQueue(mContext).add(request)
当我们发起一个请求的时候,是需要RequestQueue.add 方法添加一个request,我们看一下add方法的实现:
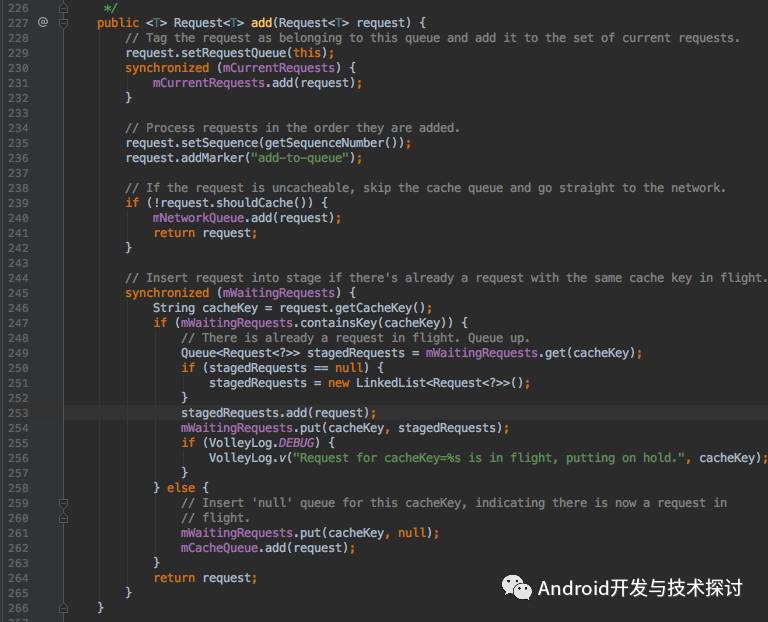
在代码第239行,判断了该request是否需要缓存,不需要则将请求加入网络队列中,否则249行代码,判断该请求是否在等待请求集合中,没有则将其加入缓存队列中。
上文我们已经提到NetworkDispatcher和CacheDispatcher 里面都是死循环,一直在等待request,这样我们add一个请求之后,相应的线程就会开始处理改请求。
基本到这里已经结束了。说几个关键点。
缓存空间大小不足
默认情况Volley提供的缓存文件大小是5M,如果超过5M怎么办?当然Volley给了解决办法,我们看下源码,在DiskBasedCache 中pruneIfNeeded方法
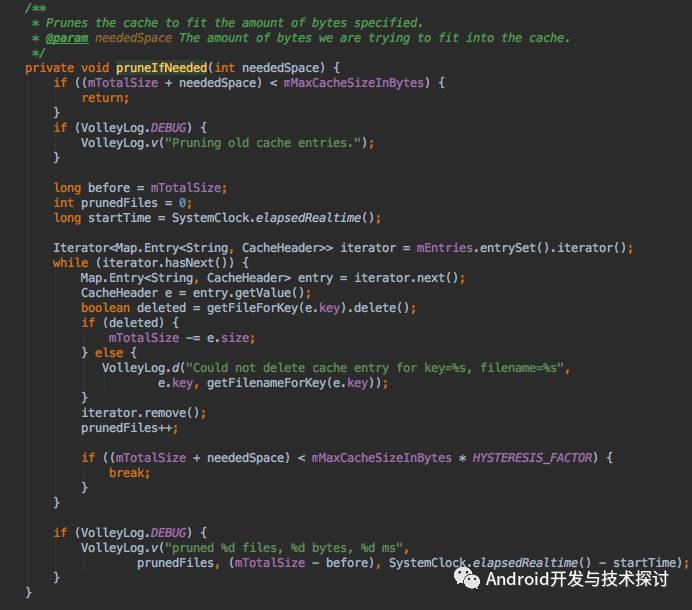
neededSpace 是本次申请的空间大小,首先 判断 neededSpace 和目前已经占用的空间总和 是否小于最大空间,如果小于则不处理,否则会遍历 本地的缓存文件,并进行删除,直到已占用空间(包括本次申请的neededSpace)小于最大空间*HYSTERESIS_FACTOR,HYSTERESIS_FACTOR的值是0.9,之所以这样做是容错处理。
另外,这里的删除算法,存在优化空间,Volley 是对Map进行遍历,然后依次删除,可能这一秒我刚缓存的数据,下一秒就被删除掉了,一些未过期的数据被删除,已过期的数据还依然保留的情况。其实可以先删除已过期的数据,在删除最久未使用的数据(LRU)