学不好后悔一辈子:刨根问底之链表数据结构
[导读] 为啥取这么个题目,刨根问底?本文也未必刨到根了,也未必探到了底!但是笔者想要传达一个观点,一个态度!作为攻城狮而言,如果对某一个点感兴趣应尽量深入再深入,忌浅尝辄止!刨根问底有百利而无一害。另外撰写刨根问底学算法系列文章,也是因为笔者非计算机专业计算机学的非常肤浅,读书时老师讲课感觉更多是学以致考,而非学以致用。故梳理学习以记之。
如果读到本文的你刚好是在校学子,不妨扩散给你的同学们,希望能在读书的时候,不光学会会考,也尽量尝试学着去用!
啥是链表?
链表是计算机科学中一种链式线性表,数据域为节点的一部分,每个节点都指向下一个节点,从而在逻辑上形成一个链。
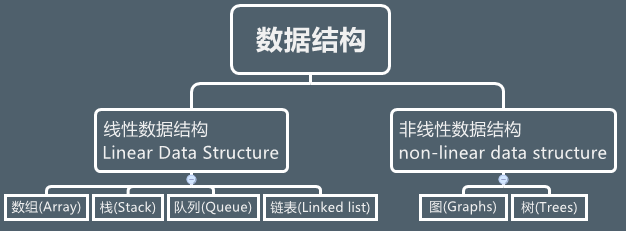
线性表 vs 非线性表
什么样的表是线性表?什么样的表又是非线性表呢?既然有线性表就必然有非线性表!
线性表:
- 逻辑存储角度:这里线性是指逻辑上的线性,除了首位元素,其他元素从逻辑上是一对一逻辑上连起来的
- 访问遍历角度:访问元素是朝着逻辑上一个方向即可遍历访问所有元素
那么概括起来说就是一种数据元素按顺序或线性排列的数据结构,其中元素与它的上一个和下一个相邻,称为线性数据结构。在线性数据结构中,只涉及单层数据。因此,只能在一次运行中遍历所有元素。由于计算机内存以线性方式排列,因此线性数据结构易于实现。那么满足上面这样特性的,常见的数组、队列、栈、链表即是线性表。
非线性表:
数据元素不是按逻辑顺序或线性排列的数据结构称为非线性数据结构。在非线性数据结构中,不涉及单个级别。因此不能在朝一个逻辑方向遍历所有元素。与线性数据结构相比,非线性数据结构不容易实现。与线性数据结构相比,它能有效地利用计算机内存,在逻辑上一对多或者多对多的关系,比如树、图。
| 线性数据结构 | 非线性数据结构 |
|---|---|
| 各元素都与它的上一个和下一个元素逻辑相连 | 数据元素是分层逻辑相连 |
| 仅单层结构 | 多层结构 |
| 易于实现 | 实现相对复杂 |
| 单循环遍历所有元素 | 单循环无法遍历所有元素 |
| 内存利用率较低 | 内存利用率较高 |
| 如数组、队列、栈、链表 | 如树、图 |
| 应用主要集中在应用软件开发方面 | 人工智能和图像处理方面有广泛的应用。 |
如何链?
Linked list(链表),从语义上理解,首先这玩意儿是一个表(list),是怎样的一个表呢?数据节点链接(Linked)起来的表!
怎么链起来的呢?
逻辑上链起来的,这里有两种办法:
- 动态存储方法:动态申请节点内存,然后利用节点中的指针指向下一个节点,实现链。优点是存储节点数理论上无限制,不需要提前分配内存,仅受限于物理可用内存。但不易于调试。
- 静态存储方法:比如用数组实现。这种方法比较易于调试,缺点是不能动态分配节点,需要提前分配内存,存储节点有限。
对于动态存储方法而言,易于理解,一想到链表很多盆友都立马想到,设计一个节点,没增加一个链节点,动态申请节点大小内存,再把节点插入进链表即可。对于静态方法,可能常常觉得并没啥用。事实上呢却不然。比如前面我写过一篇RT-Thread的小堆管理器的实现,即是采用了静态存储方法实现了链表。
可参阅:
为啥要链表?
探究计算机先辈为啥要发明这样一种数据结构呢?不妨拿最为普通的数组与链表做些对比,数组在存储信息的角度与链表从作用角度最为类型的一种线性数据,但是数组具有以下限制:
- 数组的大小是固定的:因此必须提前知道元素数量的上限。过小则应用时可能不够,过大则易浪费。
- 数组中插入新元素非常昂贵,因为必须为新元素创建空间,并且必须移动现有所有元素。CPU忙忙碌碌干了一堆无聊的搬运工工作。
而动态存储实现的链表则很好解决了这些缺陷:
- 动态申请、动态删除,高效利用内存,不易浪费
- 非常易于插入删除某一个元素
任何事物都具有两面性,不可能全是优点而无缺点,链表也一样:
- 不允许随机访问。必须从第一个节点开始顺序访问元素。因此无法使用其默认实现对链接列表进行有效的二进制搜索。
- 链表的每个节点都需要指向下一节点的指针的额外存储空间开销。
- 不适合缓存。由于数组元素是连续的位置,因此存在引用位置,可以实现缓存。而动态存储形式链表则地址是不连续的。
对于应用而言,必然是根据待解决的问题的特点进而选择合适的数据结构存储方式,不是说链表就高大上,从而鄙视最为普通的数组!
谈谈节点
实际应用中的数据节点,可能是一个基本类型数据,也可能是一个结构体,泛言之是一个广义抽象数据类型,比如:
typedef struct _T_ELEMENT{
int cmd;
float value;
int status;
}T_ELEMENT;
struct Node {
T_ELEMENT data;
struct Node* next;
}; 如果你刚好在学习链表,准备用C语言撸一遍代码,建议用typedef定义一下抽象数据结构为节点数据域,这样代码将很容易变成一个可实用的轮子。
有哪些链表形式?
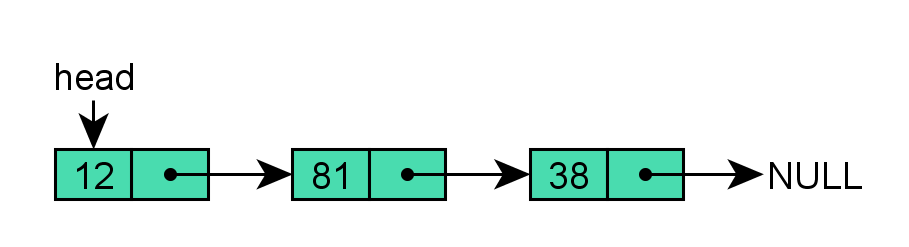
单向链表
单链表包含两个域:
- 数据信息域,存储有用信息。
- next指针域,“next”字段指向节点行中的下一个节点。
链表最基本的结构是在每个节点保存有用数据及下一个节点的地址,在最后一个节点保存一个特殊的结束标记,另外在一个固定的位置保存指向首节点的指针,应用中有时候也会储存指向最后一个节点的指针。一般查找一个节点的时候需要从第一个节点开始每次访问下一个节点,一直访问到需要的位置。但是也可以提前把一个节点的位置另外保存起来,然后直接访问。可以在单链表上执行的操作包括插入、删除和遍历。
双向链表
与单向链表相比,双向链表多了一个指向前一节点的指针:
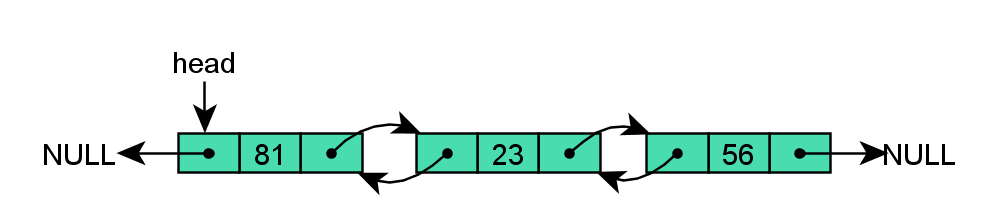
双向链表也叫双链表。双向链表中不仅有指向后一个节点的指针,还有指向前一个节点的指针。这样可以从任何一个节点访问前一个节点,当然也可以访问后一个节点,以至整个链表。一般是在需要大批量的另外储存数据在链表中的位置的时候用。双向链表也可以配合下面的其他链表的扩展使用。这样做好处显而易见,可以从任意节点遍历整个链表,但是需要额外为每个节点申请一个指针的存储空间开销。
循环链表
循环链表中, 首节点和末节点被链接在一起。这种数据结构在单向和双向链表中都可以实现。要遍历一个循环链表,可以从任意一个节点沿着列表的任一方向直到返回开始的节点。循环链表可以被视为“无头无尾”。这种结构利于节约内存空间。
单向循环链表:

双向循环链表:
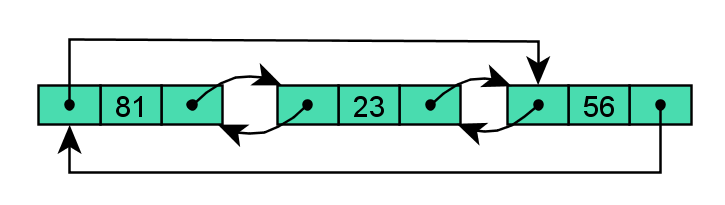
循环链表中第一个节点的前一个节点就是最后一个节点,反之亦然。循环链表的无边界
使得在这样的链表设计算法方面会比普通链表具有更大的自由度,带来更多的便利性。
总结一下
单向之优势:虽然双向链表和循环链表相比单链表具有一些优点,但是单向链表也有一些优点,在某些情况下更受欢迎。单链线性列表是一种递归数据结构,因为它包含一个指向同一类型的较小对象的指针。由于这个原因,对单向链表的许多操作(比如合并两个列表,或者以相反的顺序枚举元素)通常具有非常简单的递归算法,比使用迭代命令的解决方案都要简单。虽然这些递归解决方案可以适用于双重链表和循环链表,但这些过程通常需要额外的参数和更复杂的基本操作。
双向vs单向:双向链表每个节点需要额外的指针存储空间,而且其基本操作开销更大,所以这种易用性是有代价的,易用性体现在允许从两个方向对列表进行快速而简单的顺序访问。在双链表中,只要给定一个节点的地址,就可以在简单几步操作中插入或删除该节点。要在单链表中执行同样的操作,必须从首节点先遍历找到该节点的前一个节点。
应用而言:在Linux内核以及RTOS的任务调度管理中链表都有应用,实际编程中什么时候用,只需要明白数据结构的优势及劣势即可做出灵活的取舍。