Git内部原理解析
越了解事物的本质就越接近真相。我发现学习Git内部是如何工作的以及Git的内部数据结构这部分内容,对于理解Git的用途和强大至关重要。若你理解了Git的思想和基本工作原理,用起来就会知其所以然,游刃有余。这是Git系列的第一篇,主要会介绍Git的特点以及内部数据结构设计,和完成一次完整提交流程的时候数据是如何变化的。
Git有什么特点?
-
fast,scalable,distributed revision control system(快速,可扩展的分布式版本控制系统)
-
几乎所有操作都是本地执行
-
每一个clone都是整个生命周期的完整副本
-
the stupid content tracker(只是一个内容追踪器)
-
Git追踪的是内容而不是文件
-
如果两个文件的内容相同,无论是否在相同的目录,Git在对象库里只保存一份blob对象
-
Immutable(不可变性)
-
Git版本库中存储的数据对象均为不可变的,一旦创建数据对象并放入了数据库中,它们便不可修改。这也意味着存储在版本数据库中的整个历史也是不可变的。
-
Porcelain(高层命令)
-
init, add, commit, branch, merge.
-
Plumbing(底层命令)
-
hash-object, update-index, write-tree.
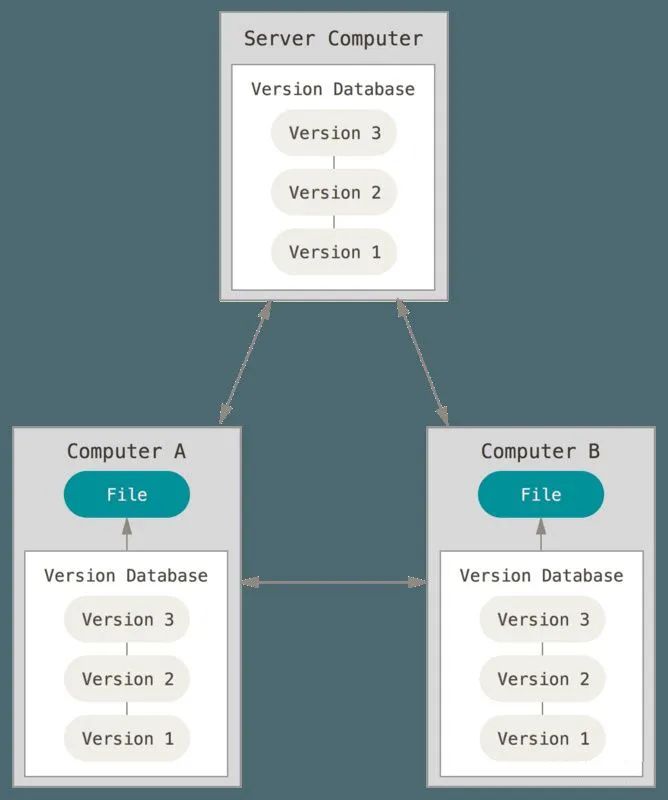
每一个Client端都可以是Server
Git Version Database是什么?
Git是一个内容寻址文件系统。这意味着,Git的核心部分是一个简单的键值对数据库(key-value data store)。你可以向该数据库插入任意类型的内容,它会返回一个键值,通过该键值可以在任意时刻再次检索该内容。而这些数据全部是存储在objects目录里。key是一个hash,hash前两个字符用于命名子目录,余下的38个字符则用作文件名。如果了解tree树的朋友应该会想明白之所以这样处理是因为检索优化策略,提高文件系统效率(如果把太多的文件放入同一个目录中,一些文件系统会变慢)。而这个hash的内容(即hash对应的Value)有四种对象类型,commit(提交),tree(目录树),blob(块),tag(标签)。 Git基本概念:
-
Content addressable filesystem(内容寻址文件系统)
-
Simple key-value data store(键值对数据)
-
Key:SHA-1散列(hash,哈希)
-
Everything is hash
-
这是一个由40个十六进制字符(0-9和a-f)组成字符串
-
Value:binary files
-
Commit:Actual git commits(提交)
-
Tree:Directoy(目录树)
-
Blob:file content(文件内容)
note:可以理解成Commit = Tree + Blob的snapshot
什么是SHA-1:SHA-1(安全散列函数),是一种密码散列函数,美国国家安全局设计,并由美国国家标准技术研究所发布为联邦数据处理标准。SHA-1可以生成一个被称为消息摘要的160位(20字节)散列值,散列值通常的呈现形式为40个十六进制数。用js来理解就是一个纯函数,输入一定输出也一定,相同的输入一定有相同的输出。不相同的输入一定有不同的输出(不考虑碰撞 ,比彗星撞击地球的概率还低)。
Git到底是如何工作呢?
我们知道最简单的git flow主要有三步:
- 在工作目录中修改文件。
- 暂存文件,将文件的快照放入暂存区域。
- 提交更新,找到暂存区域的文件,将快照永久性存储到Git仓库目录。
对应高层命令是这样的:
$ git init
$ git add .
$ git commit在我们看这三个命令到底做了什么之前,先来了解一下几个概念:
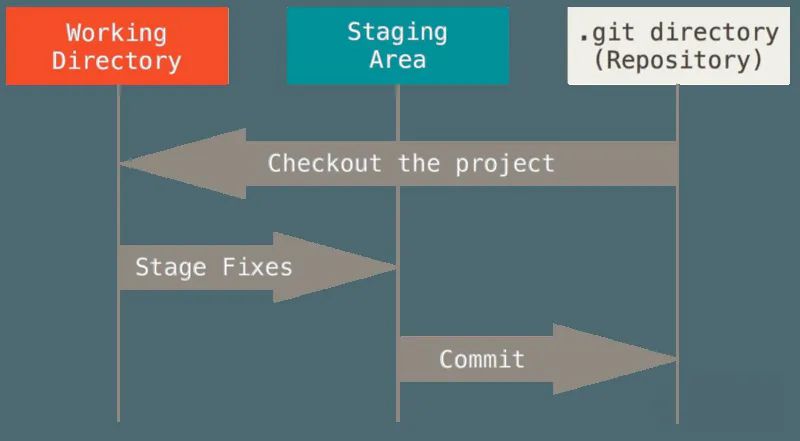
- Working Directory:工作区(工作目录)
- Stageing Area (Index):暂存区
- Repository:仓库区(本地仓库)
Git init
我们先用Git init来初始化一个项目,并查看项目的目录结构。
$ git init demo1 && cd demo1
$ tree .git
.git
├── HEAD
├── config
├── description
├── hooks
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── fsmonitor-watchman.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ ├── pre-receive.sample
│ ├── prepare-commit-msg.sample
│ └── update.sample
├── info
│ └── exclude
├── objects
│ ├── info
│ └── pack
└── refs
├── heads
└── tagsdescription文件仅供GitWeb程序使用。config文件包含项目特有的配置选项。info目录包含一个全局性排除文件,用以放置那些不希望被记录在.gitignore文件中的忽略模式。hooks目录包含客户端或服务端的钩子脚本,这些我们暂时都无需关心。最重要的是:HEAD文件、(尚待创建的)index文件,和objects目录、refs目录。这些条目是Git的核心组成部分。objects目录存储所有数据内容(hash);refs目录存储指向数据(分支)的提交对象的指针(commit hash);HEAD文件指示目前被检出的分支(refs目录内的分支名);index 文件保存暂存区信息(git ls-files --stage命令查看当前暂存区信息)。
下面我们就用底层命令来实现git init指令(另创建一个demo2目录)。
mkdir -p参数是能直接创建一个不存在的目录下的子目录:
$ mkdir -p .git/refs/heads .git/refs/tags .git/objects
$ echo 'ref: refs/heads/master' > .git/HEAD
可以看到已经成功初始化了一个Git项目。
git add
$ echo 'hello git' > index.txt
$ git add index.txt执行完这两句指令后我们再来看.git文件夹发生了什么变化(为了显示效果,简化目录结构,之后tree 都忽略hooks文件夹)
.git
├── HEAD
├── config
├── description
├── index
├── info
│ └── exclude
├── objects
│ ├── 8d
│ │ └── 0e41234f24b6da002d962a26c2495ea16a425f
│ ├── info
│ └── pack
└── refs
├── heads
└── tags可以看到多了一个index文件,并且objects目录里面多了一个8d的文件夹,里面有一个0e41开头的文件、那这个8d0e4这个是什么呢?其实这个就是index.txt文件内容的hash。还记得嘛,刚才写入文件内容是hello git,我们来手动输出这个内容的hash。
$ echo 'hello git' | git hash-object --stdin
$ 8d0e41234f24b6da002d962a26c2495ea16a425f可以通过cat-file命令从Git那里取回数据。为cat-file指定-p选项可指示该命令自动判断内容的类型,并为我们显示格式友好的内容:
$ git cat-file -p 8d0e
$ hello git为cat-file指定-t选项可以查看文件的类型:
$ git cat-file -t 8d0e
$ blobgit add做了两件事情:
- 文件内容做一个hash存成blob object
- 把index放入到Staging Area
当为index.txt创建一个对象的时候,git并不关心index.txt的文件名,git 只关心文件里面的内容。
按照这个思路,我们用底层命令来实现一下git add指令。
$ echo 'hello git' | git hash-object -w --stdin
$ git update-index --add --cacheinfo 100644 8d0e41234f24b6da002d962a26c2495ea16a425f index.txt-w选项指示hash-object命令存储数据对象;若不指定此选项,则该命令仅返回对应的键值。
我们指定的文件模式为100644,表明这是一个普通文件。其他选择包括:100755,表示一个可执行文件;120000,表示一个符号链接。
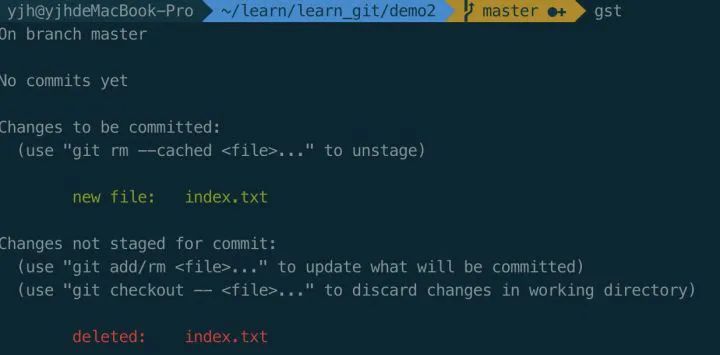
因为并没有去创建这个index.txt文件, 所以这边提示已经删除了,执行git checkout -- index.txt取出文件。
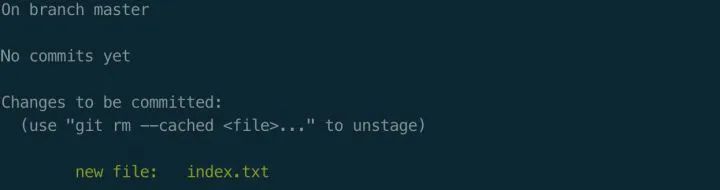
可以看到已经成功用底层命名实现了git add的功能。
到这里,我们自然就会有个疑问了,那文件名怎么办?
Git是通过tree对象来跟踪文件的路径名的。当使用git add命令时,git会给添加的文件内容创建一个blob对象,但是这个时候并不会创建tree对象。而只是更新索引,索引在.git/index中,它跟踪文件的路径名和相对应blob,每次执行git add 、git rm 、 git mv 的时候,git都会更新索引,我们可以通过命令git ls-files --stage来查看当前的索引信息。
$ git ls-files --s
$ 100644 8d0e41234f24b6da002d962a26c2495ea16a425f 0 index.txtgit commit
执行git commit -m 'init-1'后,查看tree结构,发现object 多出了两个文件:
.git
├── COMMIT_EDITMSG
├── HEAD
├── config
├── description
├── index
├── info
│ └── exclude
├── logs
│ ├── HEAD
│ └── refs
│ └── heads
│ └── master
├── objects
│ ├── 75
│ │ └── 0d7c0f7f998d3e2ce2d71ec801902f69bf6a39
│ ├── 88
│ │ └── bc066ebf3d864e34297f7051a0ded16e49813a
│ ├── 8d
│ │ └── 0e41234f24b6da002d962a26c2495ea16a425f
│ ├── info
│ └── pack
└── refs
├── heads
│ └── master
└── tags
$ git log
$ commit 750d7c0f7f998d3e2ce2d71ec801902f69bf6a39 (HEAD -> master)查看这个commit 的文件类型,可以看到这是一个commit:
$ git cat-file -t 750d
$ commit
$ git cat-file -p 750d
$ tree 88bc066ebf3d864e34297f7051a0ded16e49813a但是多出来的88bc是什么呢,其实就是当前目录的tree对象,所以Git是在commit的时候才创建tree对象的(其实是把索引转化成tree对象)。
$ git cat-file -t 88bc
$ tree
$ git cat-file -p 88bc
$ 100644 blob 8d0e41234f24b6da002d962a26c2495ea16a425f index.txt这个时候再看HEAD:
$ cat .git/HEAD
$ ref: refs/heads/master继续查看refs/heads/master:
$ cat .git/refs/heads/master
$ 750d7c0f7f998d3e2ce2d71ec801902f69bf6a39所以整个指向关系就是:HEAD里面的内容是当前的ref,而当前ref的内容是commit hash,commit对象内容是tree hash,tree对象的内容是文件夹/文件信息,而blob对象存储着文件的具体内容。这样当完成一次提交的时候,整个状态的对应关系也是确定的,所以说commit对象就是当前系统的snapshot。
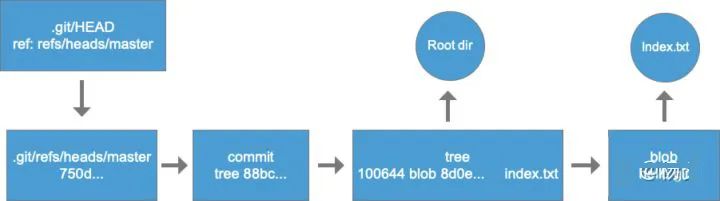
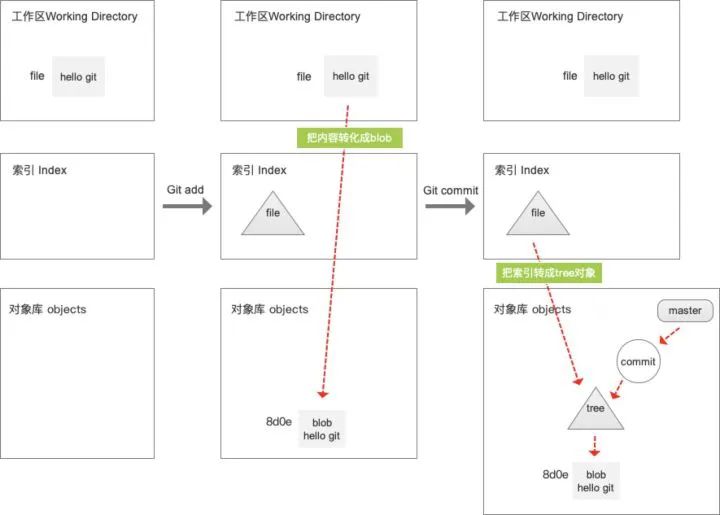
再来回顾下一次完整的提交流程:
原文链接:https://zhuanlan.zhihu.com/p/53750883