Node.js 异步延续模型
异步执行在 Node.js 中是非常基本的操作,但是一个 Uncaught Exception 的报错就可能让我们摸不着头脑,是什么地址的 TLS 访问 ECONNRESET 了?
[node:12345] Uncaught Exception: Error: read ECONNRESET
at TLSWrap.onStreamRead (internal/stream_base_commons.js:111:27)
// 真的没了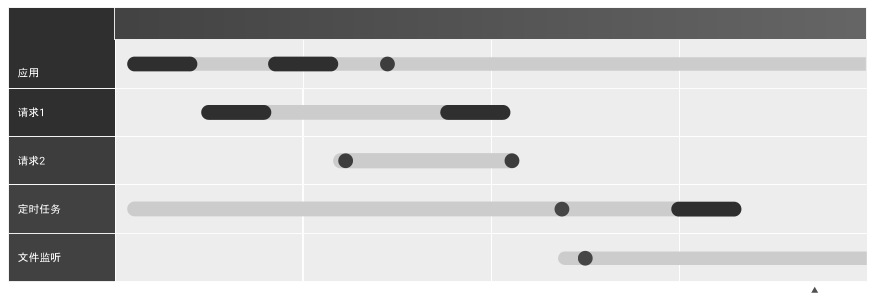
异步延续模型
Node.js 使用的 JavaScript 单线程执行模型简化了非常多的问题。而为了防止 IO 阻塞 JavaScript 执行线程,IO 操作在关联了 JavaScript 回调函数后就被放入了后台处理。当 IO 操作完成后,与其关联的 JavaScript 回调会被放入事件队列等待在 JavaScript 线程调用,可以在这里[链接1]了解更多 Node.js 事件循环的详情。
这个模型有很多好处,但是也有一个关键的挑战:异步资源与操作的上下文管理。什么是异步操作上下文?异步操作的上下文就是给定一个异步操作,我们能够通过异步上下文知道这个异步操作是因为什么触发执行的,接下来可以触发其他什么异步操作。Semantics of Asynchronous JavaScript [链接2] 通过非常精确的描述方法描述了异步资源的“上下文”,但是我们只想回答一个问题,在程序的任意一个执行时间点,“我们是通过什么样的异步函数执行路径执行到现在这个代码位置的”?
为了回答这个问题,我们先明确几个关键点:
- 执行桢 (Execution Frame) - 执行桢是程序中后继函数的一次执行过程。可以把执行桢当作从一个特定的函数执行桢被推入执行栈开始,直到这个执行桢执行结束被弹出调用栈,这样一段时间片段。不是所有的函数都是后继函数 (Continuation),一个特定的后继函数可以被调用多次,每一次执行都对应一个独立的执行桢。
- 后继函数 (Continuation) - 后继函数是在执行桢中创建的 JavaScript 函数,并且会在后续被作为异步回调执行。当被调用时,后继函数会创建一个独立的执行桢。比如当我们调用
setTimeout(function c() {}, 1000),setTimeout是在一个执行桢里被调用的,并且以一个后继函数c作为参数。当c在计时到时后被执行时,会创建一个新的执行桢;当c执行结束时,即意味着这个新创建的执行桢执行结束。 - 后继点 (Continuration Point) - 后继点是接受一个后继函数作为参数的函数。通常在 JavaScript 中后继点都是宿主环境定义的(ECMAScript 规范中中不存在与 IO 相关的操作的定义)。比如
setTimeout,也包括Promise.then。值得注意的是,不是所有接收函数作为参数的函数都是后继点,作为后继点,这些函数参数需要被异步调用,即不在当前执行桢被调用执行。比如Array.prototype.forEach就不算后继点。 - 链接点 (Link Point) - 程序运行中,当一个后继点被调用时,我们称为链接点。这个时候需要在当前执行桢与被作为参数传入的后继函数之间创建一个逻辑连接,作为上下文绑定。
- 就绪点 (Ready Point) - 就绪点是程序运行中之前链接过的后继函数被标记为“准备就绪”,准备被执行。这个过程会在后继函数与当前执行桢之间建立逻辑连接,这个逻辑连接可以称为因果关系。通常就绪点都需要在链接点后才能产生,但是 Promise 在这里的处理不太一样,promise 可以在他的 Promise 链中的前置的 promise 被 resolve 时产生一个就绪点,而此时不一定需要已经生成链接点(绑定回调函数),如
new Promise(res => res())立刻创建了一个已经 resolve 的 Promise,此时已经触发了就绪点,但是我们还未通过.then链接上下一个 Promise。
而上述几个关键点可以总结为以下几个事件:
- 执行开始 (
executionBegin): 表示一个执行桢开始执行; - 链接 (
link): 表示一个后继点被调用,一个后继函数被放入等待队列等待就绪; - 就绪 (
ready): 表示一个就绪点被触发; - 执行结束 (
executionEnd): 表示一个执行桢执行完毕。
这里我们以下面这段代码举个例子:
console.log('starting');
Promise p = new Promise((reject, resolve) => {
setTimeout(function f1() {
console.log('resolving promise');
resolve();
}, 100);
});
p.then(function f2() {
console.log('in then');
}这段代码可以通过以下的事件流描述整个异步执行过程:
{ "event": "executionBegin", "executeID": 0 } // 程序开始执行
// starting
{ "event": "link", "executeID": 0, "linkID": 1} // `f1()` 已经被链接到了 "setTimeout()" 的调用上
{ "event": "link", "executeID": 0, "linkID": 2} // `f2()` 已经被链接到了 "p.then()" 的调用上
{ "event": "executionEnd", "executeID": 0 } // 程序外层代码执行完毕
{ "event": "ready", "executeID": 0, "linkID": 1, "readyID": 3 } // 100ms 计时到时,执行就绪
{ "event": "executionBegin", "executeID": 4, "readyID": 3 } // f1() 回调开始执行
// resolving promise
{ "event": "ready", "executeID": 4, "linkID": 2, "readyID": 5 } // promise p 被 resolve,标记了 "then(function f2()..." 就绪
{ "event": "executionEnd", "executeID": 4 } // f1() 回调执行完毕
{ "event": "executionBegin", "executeID": 6, "readyID": 5 } // f2() 回调开始执行
// in then
{ "event": "executionEnd", "executeID": 6 } // f2() 回调执行完毕现有技术
async_hooks
async_hooks 即是 Node.js 对上述模型的实现。其中 async_hooks API 提供了几个异步阶段的钩子回调可以注册:
[init(asyncId, type, triggerAsyncId, resource): void](https://nodejs.org/api/async_hooks.html#async_hooks_init_asyncid_type_triggerasyncid_resource)- 表示 asyncId 对应的异步资源(可以理解为上文中的异步上下文)初始化完成,后续这个资源可以触发异步回调(不绝对会触发,比如一个 HTTP Server 启动后没人来请求);[before(asyncId): void](https://nodejs.org/api/async_hooks.html#async_hooks_before_asyncid)- 表示准备开始执行异步回调函数,而在这个异步回调函数的执行桢中,生成的任意异步资源(相当于上文中的后继函数)都会与 asyncId 参数对应的异步资源链接,作为触发原因;[after(asyncId): void](https://nodejs.org/api/async_hooks.html#async_hooks_after_asyncid)- 表示异步回调函数执行完毕,停止将asyncId 参数关联的异步资源与当前执行桢新创建的异步资源链接;[destroy(asyncId): void](https://nodejs.org/api/async_hooks.html#async_hooks_destroy_asyncid)- 表示 asyncId 参数对应的 异步资源被回收,后续不可能再通过这个异步资源触发回调。
与 domain 的区别
部分了解、使用过 domain 模块的同学可能会有一个疑问,async_hooks API 与被废弃的 domain 有什么区别?
async_hooks 作为上述异步模型中将各个异步资源链接起来的黏合剂,其本身并不提供任何错误处理相关的 API,他的 API 语义也非常清晰,只是对于异步资源的执行事件的描述。而 domain 的主要用途是异步错误的处理,但是因为在 domain 提出的时候还不存在 async_hooks,并且对于异步资源、异步执行的语义定义并不清晰,从而导致实际生产中 domain 的使用非常容易导致错误并且难以排查(多个 domain 的使用方其中如果使用了不是那么正确的方法,会将 domain 的状态搅得一团糟)。
而在 async_hooks 实现了明确的异步资源与执行的语义后,domain 的实现也进行了迁移、使用 async_hooks 来实现对于异步资源回调的追踪(实现详情可以了解 PR[链接3])。
Node.js Add-on 的兼容性
虽然 Node.js 提供的 IO 操作的异步回调都已经被妥善地封装了异步调用的上下文切换,但是 Node.js 还提供了 C/C++ Add-on 的 API,这些 Add-on 普通的 napi_call_function 调用并不会被当成是一个新的执行桢,就如同一个 JavaScript 函数中调用另一个 JavaScript 函数。但是如果 Add-on 在异步回调中也简单地使用 napi_call_function 就有可能导致 async_hooks 所提供的异步资源 API 出现漏洞。所以 Add-on 需要按照 async_hooks 提供的钩子的语义,在各个关键时间点通过异步资源 API 注册上,即可完善整个异步调用链路。但是这样会给 Add-on 开发过程造成了一定的负担,而为了降低 Add-on 开发过程出现纰漏的可能。N-API 提供了线程安全的回调 JavaScript 线程的 napi_threadsafe_function 机制,并且已经与异步资源绑定,不需要我们再关心异步资源的事件管理。
#include <assert.h>
#include <node_api.h>
void async_call_js(napi_env env,
napi_value js_callback,
void* context,
void* data)
{
napi_status status;
// 将 data 转换成 JavaScript 值
napi_value value = transform(env, data);
napi_value recv;
status = napi_get_null(env, &recv);
assert(status == napi_ok);
// N-API 已经为我们绑定了异步资源,这里可以安全地使用 `napi_call_function`
napi_value ret;
status = napi_call_function(env, recv, js_callback, 1, &value, &ret);
assert(status == napi_ok);
}
// 会在工作线程被调用的工作函数
void do_work(napi_threadsafe_function tsfn)
{
/** work, work. */
napi_status status = napi_call_threadsafe_function(tsfn, data, napi_tsfn_nonblocking);
assert(status == napi_ok);
}
napi_value some_module_method(napi_env env, napi_callback_info info)
{
napi_status status;
// 创建与 AsyncResource 绑定的 ThreadSafe Function
napi_threadsafe_function tsfn;
status = napi_create_threadsafe_function(env,
func,
async_resource,
async_resource_name,
max_queue_size,
initial_thread_count,
finalize_data,
finalize_cb,
context,
call_js_cb,
&tsfn);
assert(status == napi_ok);
// 创建工作线程
create_worker(tsfn, /** 其他参数 */);
// 返回 JavaScript 值..
napi_value ret;
status = napi_get_null(env, &ret);
assert(status == napi_ok);
return ret;
}使用场景
异步任务调度
在单元测试中,如果我们使用了异步任务,一个可能比较常见的场景就是这个异步任务可能会泄漏出我们的测试函数执行桢导致我们后续无法追踪、或者影响了后续的测试结果。
我们来看一个例子:
it('should wait for async test', () => {
setTimeout(() => {
Promise.resolve(0).then(() => {
// only after this code executes will the test complete.
console.log('wait for me'));
}
}, 0);
});在这个例子中,我们可以看到其中 setTimeout 逃逸出了测试执行桢,从而导致测试提早结束,并且可能影响后续测试任务的运行(比如在 setTimeout 中抛出了异常)。现在我们可以通过将全部的方法都使用 callback、promise 给串起来,但是这毕竟需要开发者自行去完成,并且可能出现疏漏,还是会出现例子中的情况。那么我们有没有可能从语言运行时层面提供一个“完美”的方案来跟踪所有的异步任务呢?通过 async_hooks 的异步资源追踪能力,我们就可以标记所有在测试执行过程中创建的异步资源,如果在测试执行结束后,还存在未销毁的异步资源,就可以更早地将问题暴露。
如我们有下面这个例子:
const assert = require('assert');
const {createHook, AsyncLocalStorage} = require('async_hooks');
const als = new AsyncLocalStorage();
const backlog = new Map();
createHook({
init (asyncId, type, triggerAsyncId, resource) {
const test = als.getStore();
if (test == null) {
return;
}
backlog.set(asyncId, { type, triggerAsyncId, resource });
},
destroy (asyncId) {
backlog.delete(asyncId);
},
promiseResolve (asyncId) {
backlog.delete(asyncId);
}
}).enable();
const queue = []
function test(name, callback) {
queue.push({ name, callback });
}
function run() {
if (queue.length === 0) {
return;
}
const { name, callback } = queue.pop();
als.run(name, async () => {
try {
await callback();
} finally {
als.exit(() => {
setImmediate(() => {
assert(backlog.size === 0, `'${name}' ended with dangling async tasks.`);
run();
});
});
}
});
}
process.nextTick(run);
/** 测试声明开始 */
test('foo', async () => {
await new Promise(res => setTimeout(res, 100));
// Pass.
});
test('bar', async () => {
setTimeout(res, 100);
// Assert Failed => 'bar' ended with dangling async tasks.
});在这个例子中,每一次测试开始执行前,我们都会在为测试运行注册一个异步特有数据存储,然后再开始执行测试,这样在测试中发起的所有异步资源都会被 async_hooks 捕捉到并被测试模块标记,直到这个异步资源被销毁(或者是 Promise Resolve)。随后在测试结束后,我们再检查当前测试是否有遗留的异步资源,即可确认我们的测试是干净无残留的。
异步调用栈/性能诊断
这也是我们开头的问题。
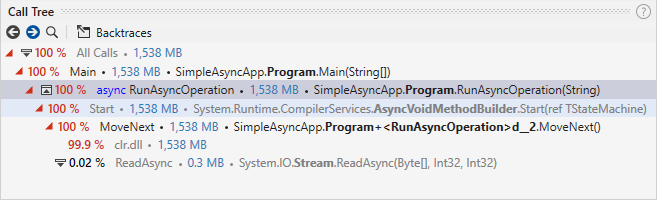
在越来越多大型的项目使用 Node.js 作为研发技术栈后,开发者们也会越来越关注问题的诊断便捷性。除了异常错误排查,现在我们也可以通过 Chrome DevTools 的 CPU Profiler 亦或者是生成火焰图来诊断我们的 Node.js 应用性能表现,但是这些工具现在更多的是只能查看某一个函数在单个同步执行桢中的调用链路与时间占用比例,并没有能力将一个异步链路上每一个异步操作所花费的时间与百分比描绘出来。
而在能够串联异步链路中的异步调用栈之后,后续我们也可以在开发中使用更加直观的性能剖析工具:
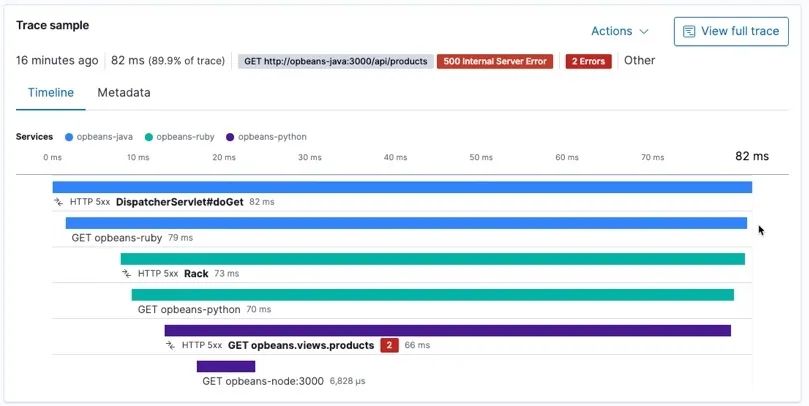
或者是提供线上的请求链路追踪能力,就如同现在各种成熟 APM 提供的应用间 RPC 调用链路一样,我们同样也可以绘制出应用内一个请求到底经历了什么流程,每一步分别花费了多少时间:
AsyncLocalStorage
使用线程作为处理单元的模型中,我们可以使用 ThreadLocal 来存储对于当前线程特有的数据信息,那么在 Node.js 的异步模型中,我们有什么办法可以方便地存储对于当前异步任务来说特有的数据信息呢?
Node.js 在 3 月 4 日发行的 v13.10.0 版本第一次发布了 async_hooks.AsyncLocalStorage,可以在异步回调或者 Promise 中获取异步调用的状态信息,比如 HTTP 服务器在处理请求的异步链路中的任意一步都可以访问对于这个请求而言专有的数据。
后续
除了在 Node.js 中我们需要清晰的异步执行模型的定义之外,同样提供了 JavaScript 执行环境的浏览器中在 JavaScript 项目日渐复杂之后同样也需要更能描写异步时间线的诊断能力。除此之外,其实 Node.js 的 async_hooks 接口本身并不容易被更多的用户所使用,他暴露了异步资源非常底层的属性,虽然这些接口能够准确描述我们的异步资源,但是想要利用好这些接口并不简单。
链接
Node.js 事件循环:https://nodejs.org/en/docs/guides/event-loop-timers-and-nexttick/
Semantics of Asynchronous JavaScript:https://www.microsoft.com/en-us/research/wp-content/uploads/2017/08/NodeAsyncContext.pdf
domain: re-implement domain over async_hook:https://github.com/nodejs/node/pull/16222