面试问我,创建多少个线程合适?我该怎么说
- 你有一个思想,我有一个思想,我们交换后,一个人就有两个思想
- If you can NOT explain it simply, you do NOT understand it well enough
为什么要使用多线程?
防止并发编程出错最好的办法就是不写并发程序

A:那还用说,肯定在某些方面有特长呗,比如你知道的【它很快,非常快】
我也很赞同这个答案,但说的不够具体
并发编程适用于什么场景?
如果问你选择多线程的原因就是一个【快】字,面试也就不会出那么多幺蛾子了。你有没有问过你自己
- 并发编程在所有场景下都是快的吗?
- 知道它很快,何为快?怎样度量?
想知道这两个问题的答案,我们需要一个从【定性】到【定量】的分析过程
使用多线程就是在正确的场景下通过设置正确个数的线程来最大化程序的运行速度(我感觉你还是啥也没说)
将这句话翻译到硬件级别就是要充分的利用 CPU 和 I/O 的利用率

在聊具体场景的时候,我们必须要拿出我们的专业性来。送你两个名词 buff 加成
- CPU 密集型程序
- I/O 密集型程序
CPU 密集型程序
一个完整请求,I/O操作可以在很短时间内完成, CPU还有很多运算要处理,也就是说 CPU 计算的比例占很大一部分
假如我们要计算 1+2+....100亿 的总和,很明显,这就是一个 CPU 密集型程序
在【单核】CPU下,如果我们创建 4 个线程来分段计算,即:
- 线程1计算
[1,25亿) - ...... 以此类推
- 线程4计算
[75亿,100亿]
我们来看下图他们会发生什么?
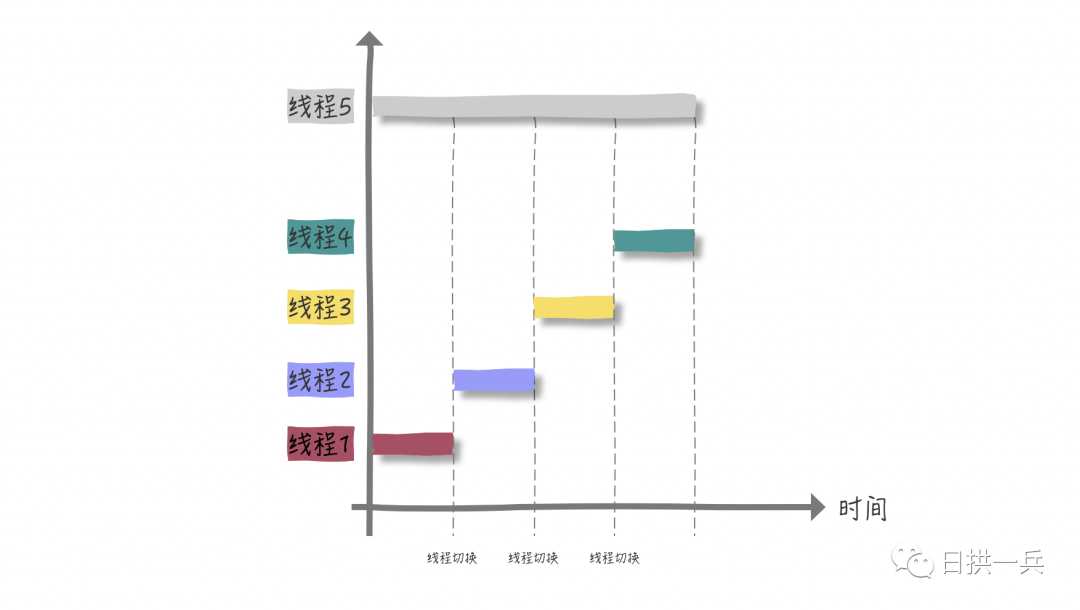
所以,单核CPU处理CPU密集型程序,这种情况并不太适合使用多线程
此时如果在 4 核CPU下,同样创建四个线程来分段计算,看看会发生什么?
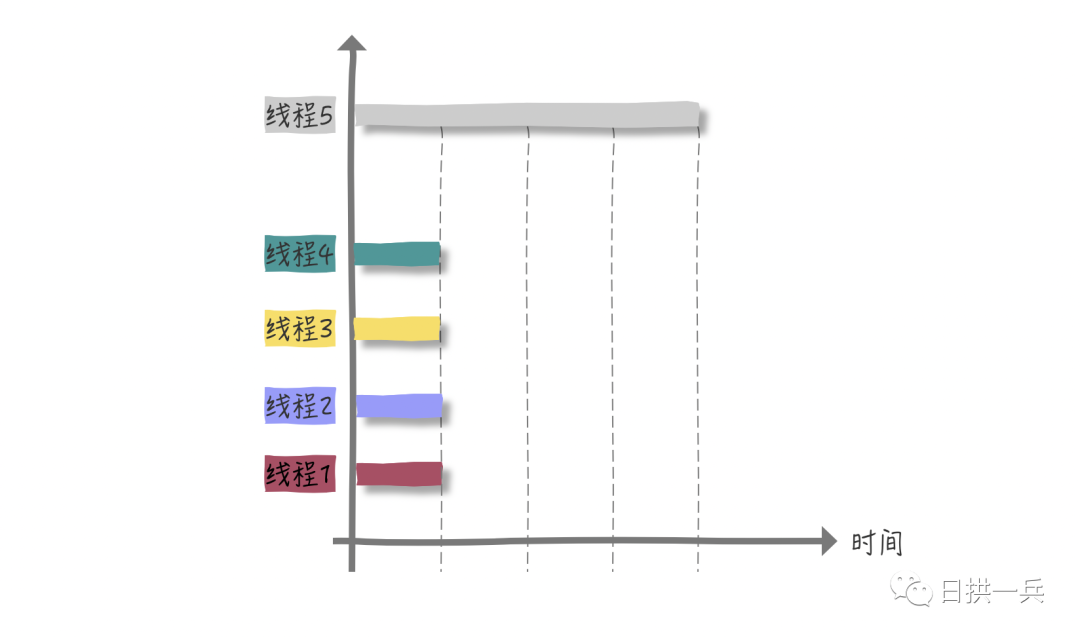
所以,如果是多核CPU 处理 CPU 密集型程序,我们完全可以最大化的利用 CPU 核心数,应用并发编程来提高效率
I/O密集型程序
与 CPU 密集型程序相对,一个完整请求,CPU运算操作完成之后还有很多 I/O 操作要做,也就是说 I/O 操作占比很大部分
我们都知道在进行 I/O 操作时,CPU是空闲状态,所以我们要最大化的利用 CPU,不能让其是空闲状态
同样在单核 CPU 的情况下:
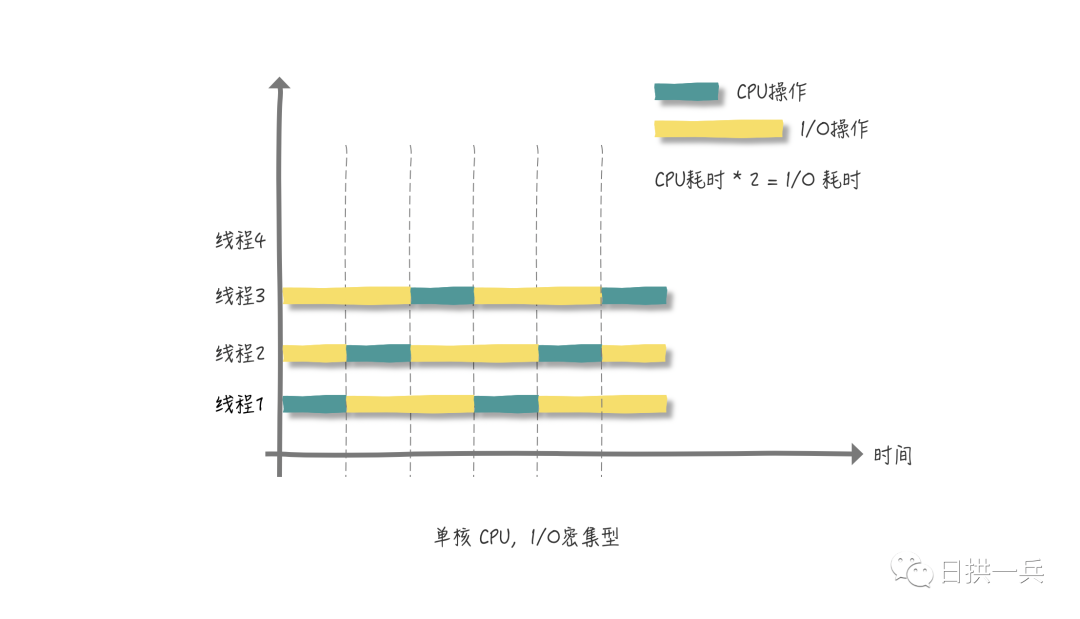
综上两种情况我们可以做出这样的总结:
线程等待时间所占比例越高,需要越多线程;线程CPU时间所占比例越高,需要越少线程。
到这里,相信你已经知道第一个【正确】使用多线程的场景了,那创建多少个线程是正确的呢?
创建多少个线程合适?
面试如果问到这个问题,这可是对你理论和实践的统考。想完全答对,你必须要【精通/精通/精通】小学算术
从上面知道,我们有 CPU 密集型和 I/O 密集型两个场景,不同的场景当然需要的线程数也就不一样了
CPU 密集型程序创建多少个线程合适?
有些同学早已经发现,对于 CPU 密集型来说,理论上 线程数量 = CPU 核数(逻辑) 就可以了,但是实际上,数量一般会设置为 CPU 核数(逻辑)+ 1, 为什么呢?
《Java并发编程实战》这么说:
计算(CPU)密集型的线程恰好在某时因为发生一个页错误或者因其他原因而暂停,刚好有一个“额外”的线程,可以确保在这种情况下CPU周期不会中断工作。
所以对于CPU密集型程序, CPU 核数(逻辑)+ 1 个线程数是比较好的经验值的原因了
I/O密集型程序创建多少个线程合适?
上面已经让大家按照图多画几个周期(你可以动手将I/O耗时与CPU耗时比例调大,比如6倍或7倍),这样你就会得到一个结论,对于 I/O 密集型程序:
最佳线程数 =
(1/CPU利用率)=1 + (I/O耗时/CPU耗时)
我这么体贴,当然担心有些同学不理解这个公式,我们将上图的比例手动带入到上面的公式中:

最佳线程数 =
CPU核心数*(1/CPU利用率)=CPU核心数*(1 + (I/O耗时/CPU耗时))
说到这,有些同学可能有疑问了,要计算 I/O 密集型程序,是要知道 CPU 利用率的,如果我不知道这些,那要怎样给出一个初始值呢?
按照上面公式,假如几乎全是 I/O耗时,所以纯理论你就可以说是 2N(N=CPU核数),当然也有说 2N + 1的,(我猜这个 1 也是 backup),没有找到具体的推倒过程,在【并发编程实战-8.2章节】截图在此,大家有兴趣的可以自己看看

如果理论都好用,那就用不着实践了,也就更不会有调优的事出现了。不过在初始阶段,我们确实可以按照这个理论之作为伪标准, 毕竟差也可能不会差太多,这样调优也会更好一些
谈完理论,咱们说点实际的,公式我看懂了(定性阶段结束),但是我有两个疑问:
- 我怎么知道具体的 I/O耗时和CPU耗时呢?
- 怎么查看CPU利用率?
没错,我们需要定量分析了
幸运的是,我们并不是第一个吃螃蟹的仔儿,其实有很多 APM (Application Performance Manager)工具可以帮我们得到准确的数据,学会使用这类工具,也就可以结合理论,在调优的过程得到更优的线程个数了。我这里简单列举几个,具体使用哪一个,具体应用还需要你自己去调研选择,受篇幅限制,暂不展开讨论了
- SkyWalking
- CAT
- zipkin
上面了解了基本的理论知识,那面试有可能问什么?又可能会以怎样的方式提问呢?
面试小问
小问一
假设要求一个系统的 TPS(Transaction Per Second 或者 Task Per Second)至少为20,然后假设每个Transaction由一个线程完成,继续假设平均每个线程处理一个Transaction的时间为4s
如何设计线程个数,使得可以在1s内处理完20个Transaction?

小问二
计算操作需要5ms,DB操作需要 100ms,对于一台 8个CPU的服务器,怎么设置线程数呢?
如果不知道请拿三年级期末考试题重新做(今天晚自习留下来),答案是:
线程数 = 8 * (1 + 100/5) = 168 (个)
那如果DB的 QPS(Query Per Second)上限是1000,此时这个线程数又该设置为多大呢?

因为一次请求不仅仅包括 CPU 和 I/O操作,具体的调优过程还要考虑内存资源,网络等具体内容
增加 CPU 核数一定能解决问题吗?
看到这,有些同学可能会认为,即便我算出了理论线程数,但实际CPU核数不够,会带来线程上下文切换的开销,所以下一步就需要增加 CPU 核数,那我们盲目的增加 CPU 核数就一定能解决问题吗?
在讲互斥锁的内容是,我故意遗留了一个知识:
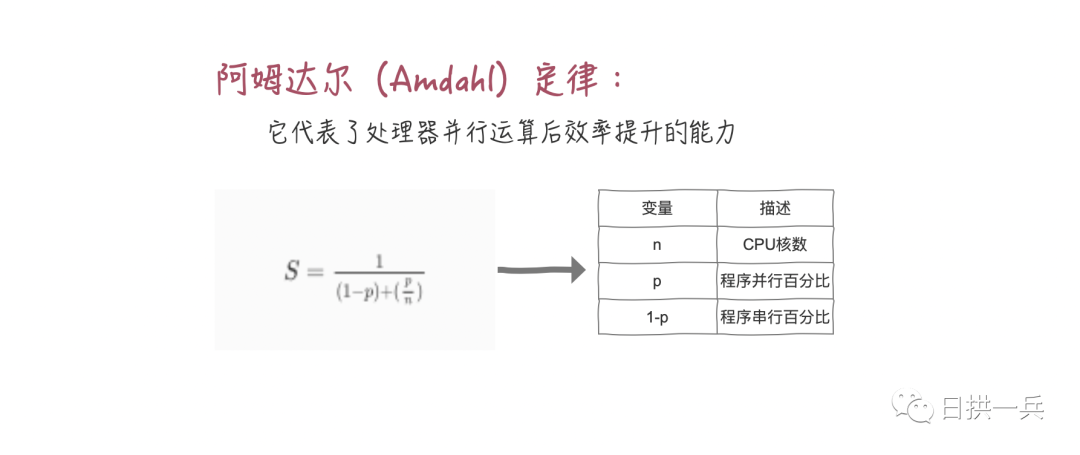

如何简单粗暴的理解串行百分比(其实都可以通过工具得出这个结果的)呢?来看个小 Tips:
Tips: 临界区都是串行的,非临界区都是并行的,用单线程执行临界区的时间/用单线程执行(临界区+非临界区)的时间就是串行百分比
现在你应该理解我在讲解 synchronized 关键字时所说的:
最小化临界区范围,因为临界区的大小往往就是瓶颈问题的所在,不要像乱用try catch那样一锅端
总结
多线程不一定就比单线程高效,比如大名鼎鼎的 Redis (后面会分析),因为它是基于内存操作,这种情况下,单线程可以很高效的利用CPU。而多线程的使用场景一般时存在相当比例的I/O或网络操作
另外,结合小学数学题,我们已经了解了如何从定性到定量的分析的过程,在开始没有任何数据之前,我们可以使用上文提到的经验值作为一个伪标准,其次就是结合实际来逐步的调优(综合 CPU,内存,硬盘读写速度,网络状况等)了
最后,盲目的增加 CPU 核数也不一定能解决我们的问题,这就要求我们严格的编写并发程序代码了
灵魂追问
- 我们已经知道创建多少个线程合适了,为什么还要搞一个线程池出来?
- 创建一个线程都要做哪些事情?为什么说频繁的创建线程开销很大?
- 多线程通常要注意共享变量问题,为什么局部变量就没有线程安全问题呢?
- ......