C 语言中的结构体和共用体(联合体)
在 C 语言中,结构体(struct)是一个或多个变量的集合,这些变量可能为不同的类型,为了处理的方便而将这些变量组织在一个名字之下。由于结构体将一组相关变量看作一个单元而不是各自独立的实体,因此结构体有助于组织复杂的数据,特别是在大型的程序中。
共用体(union),也称为联合体,是用于(在不同时刻)保存不同类型和长度的变量,它提供了一种方式,以在单块存储区中管理不同类型的数据。
今天,我们来介绍一下 C 语言中结构体和共用体的相关概念和使用。
结构体 / struct
结构体的定义
声明一个结构体类型的一般形式为:
struct 结构体名 {
成员列表
};其中,成员列表中对各成员都应进行类型声明,即:
类型名 成员名;
例如,我们需要在程序中记录一个学生(student)的数据,包括学号(num)、姓名(name)、性别(sex)、年龄(age)、成绩(score)、地址(addr)等,如下图所示:
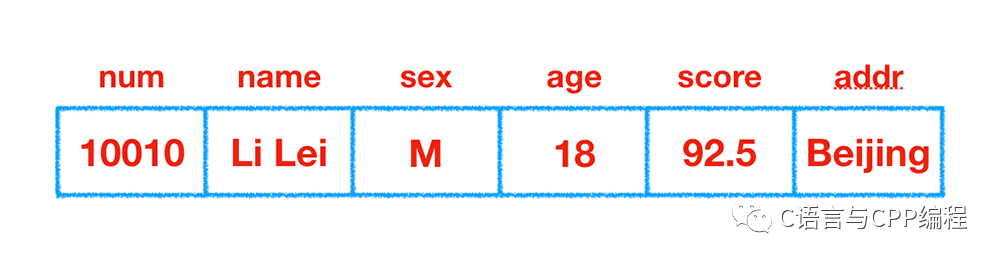
truct student {
int num;
char name[20];
char sex;
int age;
float score;
char addr[30];
};上述定义了一个新的结构体类型 struct student(注意,struct 是声明结构体类型时所必须使用的关键及,不能省略),它向编译系统声明,这是一个“结构体类型”,它包括 num、name、sex、age、score、addr 等不同类型的数据项。
应当说,这里的 struct student 是一个类型名,它与系统提供的标准类型(如 int、char、float、double 等)具有同样的作用,都可以用来定义变量的类型。
结构体变量
前面只是声明了一个结构体类型,它相当于一个模型,但其中并无具体的数据,编译系统对其也不分配实际的内存单元。为了能在程序中使用结构体类型的数据,我们应当定义结构体类型的变量,并在其中存放具体的数据。主要以下 3 中方式定义结构体类型变量:
- 先声明结构体类型,再定义变量名
结构体类型名 结构体变量名;
例如上面我们已经定义了一个结构体类型 struct student,就可以用它来声明变量:
struct student student1, student2;
定义了 student1 和 student2 为 struct student 类型的变量,它们具有 struct student 类型的结构,后续我们可以对它们进行初始化。
- 在声明类型的同时定义变量 例如:
struct student {
int num;
char name[20];
char sex;
int age;
float score;
char addr[30];
} student1, student2;它的作用与第一种方法相同,即定义了两个 struct student 类型的变量 student1、student2。这种形式的定义的一般形式为:
struct 结构体名 {
成员列表
} 变量名列表;- 直接定义结构体类型变量 其省略了结构体名,一般形式为:
struct {
成员列表
} 变量名列表;关于结构体类型,需要补充说明一点:
类型与变量是不同的概念,不要混淆。我们只能对变量赋值、存取或运算,而不能对一个类型进行赋值、存取或运算。在编译时,对类型是不分配空间的,只对变量分配空间。
简单地说,我们可以把“结构体类型”和“结构体变量”理解为是面向对象语言中“类”和“对象”的概念。
此外,结构体里的成员也可以是一个结构体变量。比如我们先声明了一个结构体 struct date:
struct date {
int month;
int day;
int year;
};然后把它应用于声明 struct student 中:
struct student {
int num;
char name[20];
char sex;
int age;
float score;
struct date birthday;
char addr[30];
} student1, student2;最后,解释一个在阅读大型开源代码(比如 Objective-C Runtime 源码)时容易产生疑问的点:如下两个结构体 SampleA 和 SampleB 声明的变量在内存上其实是完全一样的,原因是因为结构体本身并不带有任何额外的附加信息:
struct SampleA {
int a;
int b;
int c;
};
struct SampleB {
int a;
struct Part1 {
int b;
};
struct Part2 {
int c;
};
};结构体变量的引用
引用结构体变量中成员的方式为:
结构体变量名.成员名
例如,student1.num 表示 student1 变量中 num 成员,我们可以对结构体变量的成员进行赋值:student1.num = 10010;。
如果成员本身又属于一个结构体类型,则要用若干个成员运算符(点号 .),一级一级地找到最低一级的成员,例如:
student1.birthday.month = 9;
另外对结构体变量的成员可以像普通变量一样进行各种运算,也可以用取址运算符 & 引用结构体变量成员的地址,或者引用结构体变量的地址。
结构体变量的初始化
和其他类型变量一样,对结构体变量可以在定义时指定其初始值,用大括号括起来:
struct student {
int num;
char name[20];
char sex;
int age;
char addr[30];
} a = {10010, "Li Lei", 'M', 18, "Beijing Haidian"};结构体与数组
如果一个数组的元素为结构体类型,则称其为“结构体数组”。结构体数组与之前介绍的数值型数组的不同之处在于每个数组元素都是一个结构体类型的数据,它们都分别包括各个成员项。
- 定义结构体数组
和定义结构体变量的方法类似,只需声明其为数组即可,例如:
struct student {
int num;
char name[20];
char sex;
int age;
float score;
char addr[30];
};
struct student stu[3];以上定义了一个数组 stu,数组有 3 个元素,均为 struct student 类型数据,如下图:
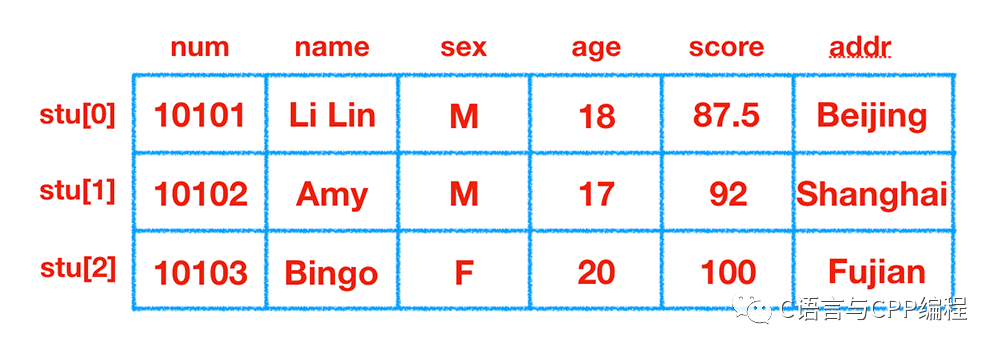
- 结构体数组的初始化
与其他类型的数组一样,对结构体数组可以初始化,例如:
struct student {
int num;
char name[20];
char sex;
int age;
float score;
char addr[30];
} stu[3] = {{10101, "Li Lin", 'M', 18, 87.5, "Beijing"},
{10102, "Amey", 'M', 17, 92, "Shanghai"},
{10103, "Bingo", 'F', 20, 100, "Fujian"}};从上面可以看到,结构体数组的初始化的一般形式是在定义数组的后面加上“={初值表列};”。
结构体数组中各元素在内存中也是连续存放的,如下图:
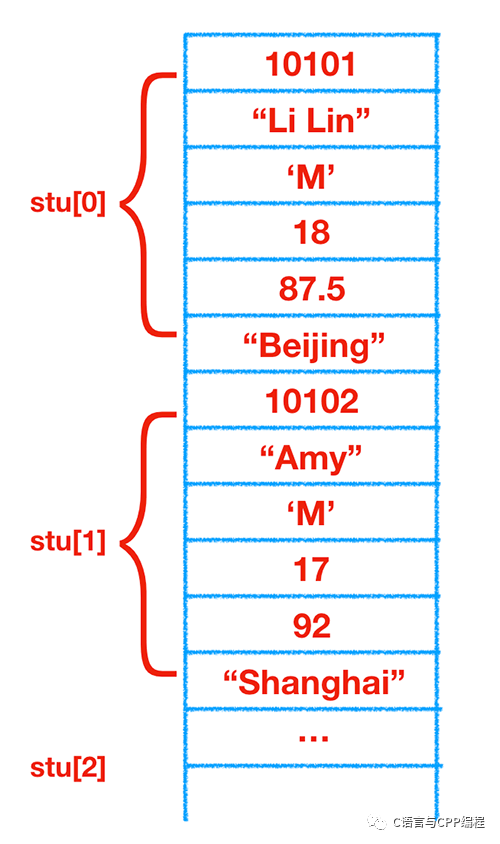
结构体与指针
一个结构体变量的指针就是该变量所占据的内存段的起始地址。可以设一个指针变量,用来指向一个结构体变量,此时该指针变量的值是结构体变量的起始地址。指针变量也可以用来指向结构体数组中的元素。
- 指向结构体变量的指针
struct student {
int num;
char name[20];
char sex;
int age;
float score;
char addr[30];
};
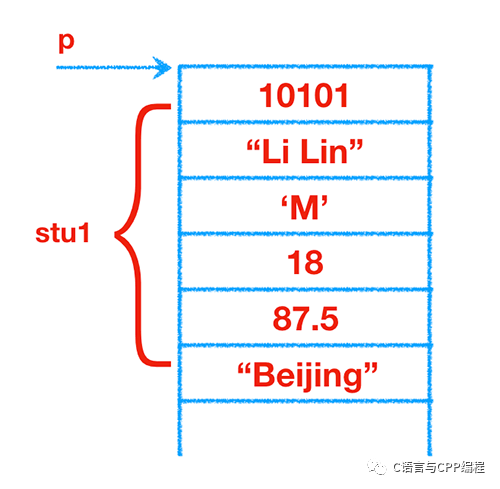
struct student stu1 = {...};
struct student * p;
p = &stu1;上述代码先声明了 struct student 结构体类型,然后定义一个 struct student 类型的变量 stu1,同时又定义了一个指针变量 p,它指向一个 struct student 类型的数据,最后把结构体变量 stu1 的起始地址赋给指针变量 p,如图所示:
*p 来访问结构体变量 stu1 的值,用 (*p).num来访问 stu 的成员变量。C 语言为了使用方便和直观,定义可以把 (*p).num 改用 p->num 来代替,它表示 p 所指向的结构体变量中的 num 成员。
也就是说,以下 3 种形式等价:
- 结构体变量.成员名:
stu1.num - (*指针变量名).成员名:
(*p).num - 指针变量名->成员名:
p->num - 指向结构体数组的指针 对于结构体数组及其元素也可以用指针变量来指向,例如:
struct student {
int num;
char name[20];
char sex;
int age;
float score;
char addr[30];
};
struct student stu[3] = {{10101, "Li Lin", 'M', 18, 87.5, "Beijing"},
{10102, "Amey", 'M', 17, 92, "Shanghai"},
{10103, "Bingo", 'F', 20, 100, "Fujian"}};
struct student *p = stu;此时,指针变量 p 指向数组首个元素的地址,即 &stu[0],也就是数组名 stu。
结构体指针使用场景
(1)函数参数:用指向结构体变量(或数组)的指针作实参,将结构体变量(或数组)的地址传给形参。
void printStudentInfo(struct student *p);
因为如果我们直接用结构体变量(不是结构体指针)作为实参时,由于采取的是“值传递”的方式,将结构体变量所占用的内存单元的内容全部顺序传递给形参,形参也必须是同类型的结构体变量。
在函数调用期间,形参也要占用内存单元,这种传递方式将带来较大的时间和空间开销,同时也不利于将在函数执行期间改变形参结构体的值(结果)返回给主调函数,因此一般比较少直接“用结构体变量做实参”,而是改用指针的形式。
(2)链表
链表是一种常见的且很重要的数据结构,一般用于动态地进行存储分配。常见的有单链表和双链表等,一般可以用结构体来表示链表的节点,如下为常见的“单链表”节点的声明:
struct ListNode {
int val;
struct ListNode *next;
};其中,val 表单链表节点的值,next 指针用于指向链表的下一个节点。
例如,面试比较常考察的“反转单链表”的题目:
struct ListNode *reverseList(struct ListNode *head) {
if (head == NULL) {
return NULL;
}
if (head->next == NULL) {
return head;
}
struct ListNode *reversedHead = NULL;
struct ListNode *prevNode = NULL;
struct ListNode *currentNode = head;
while (currentNode != NULL) {
struct ListNode *nextNode = currentNode->next;
if (nextNode == NULL) {
reversedHead = currentNode;
}
currentNode->next = prevNode;
prevNode = currentNode;
currentNode = nextNode;
}
return reversedHead;
}(3)二叉树
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
};其中 val 表示二叉树叶子节点的值,left 指向节点的左子树,right 指向右子树。
例如,之前闹得沸沸扬扬的 Google 面试“翻转二叉树”的题目:
struct TreeNode *invertTree(struct TreeNode *root) {
if (root == NULL) {
return NULL;
}
root->left = invertTree(root->left);
root->right = invertTree(root->right);
struct TreeNode *temp = root->left;
root->left = root->right;
root->right = temp;
return root;
}动态开辟和释放内存空间
前面介绍,链表结构是动态地分配存储的,即在需要时才开辟一个节点的存储单元。那么,怎样动态地开辟和释放存储单元呢?C 语言编译系统的库函数提供了以下相关函数。
- malloc 函数
void * malloc(unsigned size);
其作用是在内存的动态存储区(堆)中分配一个长度为 size 的连续空间,此函数的返回值是一个指向分配域起始地址的指针(类型为 void *,即空指针类型,使用时可转换为其他指针数据类型)。如果此函数未能成功地执行(例如内存空间不足时),则返回空指针 NULL。
使用示例:
int *result = malloc(2 * sizeof(int));
struct ListNode *node = malloc(sizeof(struct ListNode));上述 result 是一个分配在堆上的长度为 2 的数组,它与 int result[2]; 的区别是后者分配在内存栈区。而 node 是指向一个 struct ListNode 类型的数据(同样已分配在堆上)的起始地址的指针变量。
- calloc 函数
void * calloc(unsigned n, unsigned size);
其作用是在内存的动态存储区中分配 n 个长度为 size 的连续空间,函数返回一个指向分配域起始地址的指针,如果分配不成功,返回 NULL。
- realloc 函数
void * realloc(void *p, unsigned size);
其作用是将 p 所指向的已分配的动态内存区域的大小重新改为 size,size 可以比原来分配的空间大或小。该函数返回指向所分配的内存区起始地址的指针,同样,如果分配不成功,返回 NULL。
如果传入的 p 为 NULL,则它的效果和 malloc 函数相同,即分配 size 字节的内存空间。
如果传入 size 的值为 0,那么 p 指向的内存空间就会被释放,但是由于没有开辟新的内存空间,所以会返回空指针 NULL,类似于调用 free 函数。
- free 函数
void free(void *p);
其作用是释放 p 所指向的内存区,使这部分内存区能被其他变量使用,p 一般为调用上述几个函数返回的值。free 函数无返回值。
共用体 / union
有时,我们需要使几种不同类型的变量存放到同一段内存单元中。例如,可以把一个整型变量(2 个字节)、一个字符型变量(1 个字节)、一个实型变量(4 个字节)放在同一开始地址的内存单元中,如下图所示:
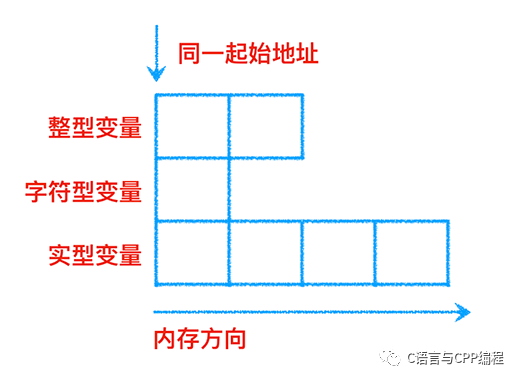
共用体变量的定义
定义共用体类型变量的一般形式为:
union 共用体名 {
成员列表
} 变量列表; 例如:
union data {
int i;
char c;
float f;
} a, b, c;也可以将类型声明与变量的定义分开:
union data {
int i;
char c;
float f;
};
union data a, b, c;即先声明一个 union data 类型,再将 a, b, c 定义为 union data 类型。此外,也可以省略共用体名直接定义共用体变量:
union {
int i;
char c;
float f;
} a, b, c;可以看到,“共用体”与“结构体”的定义形式相似,但它们的含义是不同的:
- 结构体变量所占的内存长度(字节总数)是各成员占的内存长度之和,每个成员都分别独占其自己的内存单元。
- 共用体变量所占的内存长度等于最长的成员的长度。例如上述定义的共用体变量 a, b, c 各占 4 个字节(因为其中最长的实型变量占 4 个字节),而不是各占 2+1+4=7 个字节。
共用体变量的引用
与结构体类似,共用体变量中成员的引用方式为:
共用体变量名.成员名
只有先定义了共用体变量才能引用它,而且不能直接引用共用体变量,只能引用共用体变量中的成员。例如,前面定义了共用体变量 a,则:
a.i表示引用共用体变量中的整型变量 ia.c表示引用共用体变量中的字符型变量 ca.f表示引用共用体变量中的实型变量 f
但不能只引用共用体变量,例如 printf("%d", a); 是错误的,因为 a 的存储区有好几种类型,分别占不同长度的字节,仅写共用体变量名 a,难以使系统确定究竟输出的哪一个成员的值。
共用体类型数据的特点
在使用共用体类型数据时,应当注意以下一些特点:
- 同一个内存段可以用来存放几种不同类型的成员,但在每一瞬时只能存放其中一种,而不是同时存放几种。也就是说,每一瞬时只有一个成员起作用,其它的成员不起作用,即:共用体中的成员不是同时都存在和起作用的。
- 共用体变量中起作用的成员是最后一次存放的成员,在存入一个新的成员后,原有的成员就失去作用了。例如有如下赋值语句:
a.i = 1;
a.c = 'F';
a.f = 2.5;在执行完以上 3 条赋值语句后,此时只有 a.f 是有效的,而 a.i 和a.c 已经无意义了。因此在引用共用体变量的成员时,程序员自己必须十分清楚当前存放在共用体变量中的究竟是哪个成员。
- 共用体变量的地址和它的各成员的地址都是同一地址,例如 &a、&a.i、&a.c、&a.f 都是同一个地址值,其原因是显然的。
- 不能直接对共用体变量名赋值,也不能企图引用变量名来得到一个值,同时也不能在定义共用体变量时对它初始化。例如,以下这些都是不对的:
union {
int i;
char c;
float f;
} a = {1, 'a', 1.5}; // 不能对共用体初始化
a = 1; // 不能对共用体变量赋值
m = a; // 不能引用共用体变量名以得到一个值- 不能把共用体变量作为函数参数,也不能使函数返回共同体类型的变量,但可以使用指向共用体变量的指针(与结构体变量的指针用法类似,不再赘述)。
- 共用体类型可以出现在结构体类型定义中,也可以定义共用体数组。反之,结构体也可以出现在共用体类型定义中,数组也可以作为共用体的成员。
共用体总感觉像是计算机发展早期,内存寸土寸金的遗留产物。
总结
本文简要介绍了 C 语言中结构体和共用体的概念及其应用,如有不当之处,欢迎指出,
https://kangzubin.com/c-pointer-array/