从敲下一行JS代码到这行代码被执行,中间发生了什么?
前言
我们每天都在写JS,你是否想过,计算机是怎么识别你的这一行代码,并且执行相应指令?本篇文章为你讲述从敲下一行JS代码到这行代码可以被执行算出正确的结果,都经历了什么。
编译
学过计算器基础的,即使学的不好,大概都知道计算机跟人能读懂的语言是不一样的,它只认识0101的二进制数。也就是机器指令码(machine instruction code )。一开始,人们都是用它来写程序,可以想到最早的程序员有多痛苦。这种二进制码不易被人类理解和记忆, 估计出错太多,最后终于聪明的人类终于发明了适合自己学习记忆各种高级计算机语言,也包括JS。
但是机器并不能直接理解JS语言,所以这里就需要一个中介帮忙程序解释并且将其编译成机器指令码给计算机执行。这个过程就叫编译。
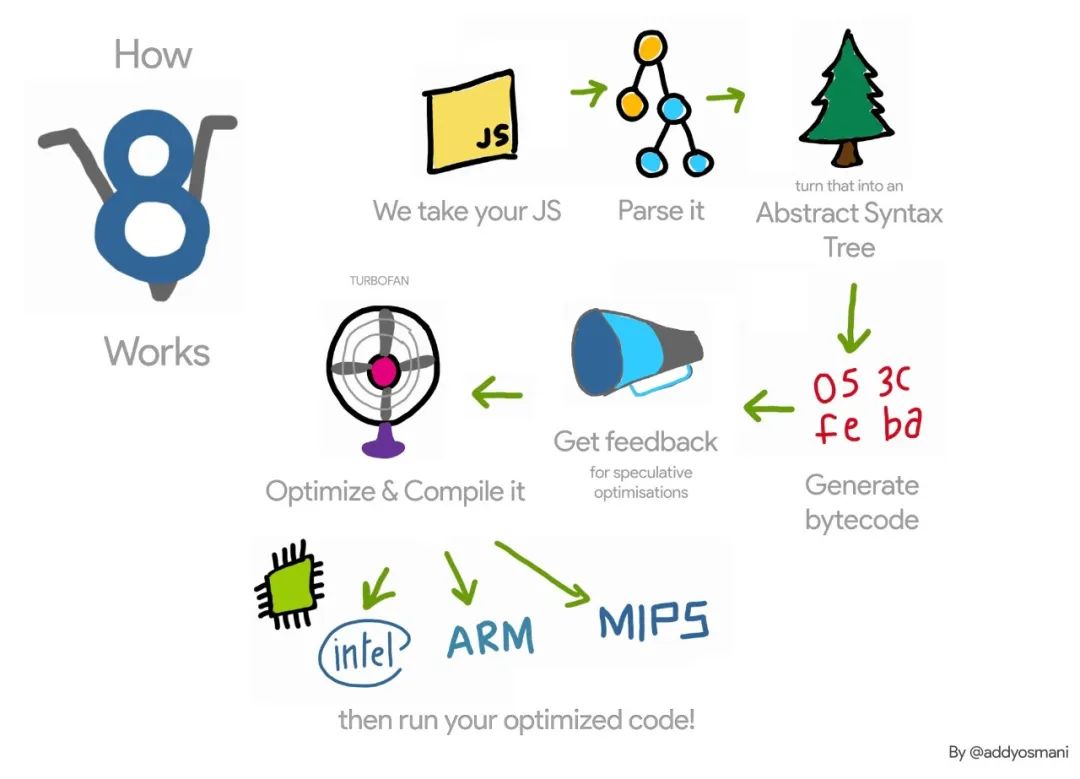
而我们chrome浏览器里的V8引擎就是帮我们做这个事情的中介。但是并不是只有google一家在做浏览器啊,所以市面上还有很多 JS引擎。下面是从网上趴的图:

所以终极解决兼容问题的方法就是:全部浏览器都用一种JS引擎,目前v8大有一统天下的趋势,不过这个东西最终能不能实现今天就不讨论了。
编译原理
无论是哪种编译器,原理都差不多。所以我们直接来看看编译原理,就知道V8大概是如何工作的了。
编译一般分为三个步骤:
- 词法分析(laxical Analysis) 词法分析的意思就是,将代码块切分成最小的单位。这些最小单位称为token。比如 var a = 2;可以切分成var,a,=,2。
- 语法分析(Syntactic Analysis) 将词法单元转换成一个有层级,代表程序语法结构的树,这就是我们经常说的AST,抽象语法树。
注意:词法分析跟语法分析不是完全独立的,而是交错运行的。也就是说,并不是等所有的token都生成之后,才用语法分析器来处理。一般都是每取得一个token,就开始用语法分析器来处理了。
下面我们来看看一个add函数会生成怎样的语法树:
function add (a, b) {
return a + b
}
可以看到这就是这段函数的树形展示,如果你没看懂,可以看这篇文章。这里就不具体解释每个FunctionDeclaration Identifier BlockStatement的意思了。
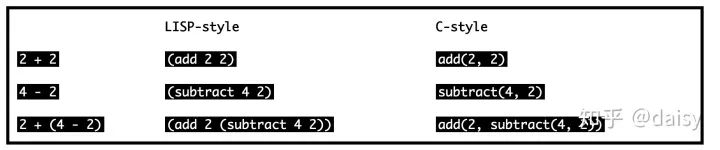
AST可是所有编译器以及转换器的基础核心,我们常用的babel转码过程就是先将ES6的代码编成AST,然后转换成ES5的AST,最后由这个AST还原出ES5代码。有兴趣的可以看这篇文章,这篇文章是将LISP-style代码的转成C-style代码,不过原理都一样。
构建语法树,还有一层作用,就是发现语法错误。当JS解析器发现无法构造这个抽象语法树的时候,就会报语法错误,并结束整个代码块的解析。而对于一些强类型语言(也就是一开始就要定义这个变量是什么类型,后面都不能改变),在构建出语法树之后,还会有类型检查。但是对于JS这种弱类型语言,就没有这一步。当然TypeScipt为我们提供了类型检查,并且可以将我们的typeScript代码编译成JS。
- 代码生成(Code Genaration)
最后一步就是将AST转成计算机可以识别的机器指令码。
V8引擎的编译过程基本就是上面这个过程,但是它多了一步生成字节码的过程。首先用解析器生成AST,然后用解释器Ignition根据语法树生成字节码,最后再用TurboFan将字节码生成机器指令码。
为什么要先转成字节码?是因为直接生成机器指令码太占内存了。
整个过程就是这么简单了。
V8 为什么那么快
因为JS是解释型语言,支持动态类型,弱类型,那就没办法先编译找到变量的地址跟类型,所以JS的编译过程发生在执行前的那段时间,对JS引擎的性能要求特别高。
1、脚本流(script streaming)
以前的chrome里,网络拿到数据之后,必须经过chrome主线程转发到流解析器。但是,当网络数据到达之后,主线程有可能被其他事情占住,比如HTML解析,布局,其他JS执行。这样这些数据就没办法被即使解析。
从Chrome 75开始,V8可以将脚本直接从网络流传输到流解析器中,而无需等待chrome主线程。
这意味着脚本一旦开始加载,V8就会在单独的线程上解析。这样下载脚本完成后几乎立即完成解析,从而缩短页面加载时间。
2、字节码缓存
首次访问页面的时候,JS代码会被编译成字节码。当再次访问同一个页面的时候,会直接复用首次解析出来的字节码。这样就省去了下载,解析,编译的步骤,可以使chrome节省大约40%的时间。
3、内联
如果一个函数内部调用其他函数,那么编译器会直接函数中将要执行的内容放到主函数里。
function add(a, b) {
return a + b;
}
function calculateTwoPlusFive() {
var sum;
for (var i = 0; i <= 1000000000; i++) {
sum =add(2+5);
}
}
var start = new Date();
calculateTwoPlusFive();
var end = new Date();
var timeTaken = end.valueOf() - start.valueOf();
console.log("Took " + timeTaken + "ms");内联属性会将这个代码编译成
function add(a, b) {
return a + b;
}
function calculateTwoPlusFive() {
var sum;
for (var i=0;i<=1000000000;i++){
sum = 2 + 5;
}
}
var start = new Date();
calculateTwoPlusFive();
var end = new Date();
var timeTaken = end.valueOf() - start.valueOf();
console.log("Took " + timeTaken + "ms");复制代码我把这段代码放在safari上跑需要1454ms,而chrome只需要453ms,基本只有三分之一。
4、隐藏类
对于C++/Java,访问指令可以在编译阶段生成。
因为它们的每一个变量都有指定的类型。所以一个对象包含什么成员,这些成员是什么类型,在对象中的偏移量都可以在编译阶段就确定了。那么在CPU执行的时候就轻松了,要访问这个对象中的某个变量的时候,直接用对象的首地址加偏移量就可以访问到。
但是JS是动态语言,运行的时候不仅可以随意换类型,还可以动态添加删除属性。所以访问对象属性完全得运行的时候才能决定。
如果JS引擎每次都需要进行动态查询,会造成大量的性能损耗。所以V8引入了隐藏类机制。在初始化对象时候,会给他创建一个隐藏类,而后增删属性都会在创建一个隐藏类或者查找之前已经创建好的类。
那么这些隐藏类里的成员对于这个类来说就是固定的。所以他们的偏移量对于这个类来说也是固定的,那么在后续再次调用的时候就能很快的定位到他的位置。下面来看个例子:
function Person(name, age) {
this.name = name;
this.age = age;
}
var daisy = new Person("daisy", 32);
var alice = new Person("alice", 20);
daisy.email = "daisy@qq.com";
daisy.job = "engineer";
alice.job = "engineer";
alice.email = "alice@qq.com";对于这段代码,它的隐藏类的生成过程如下:
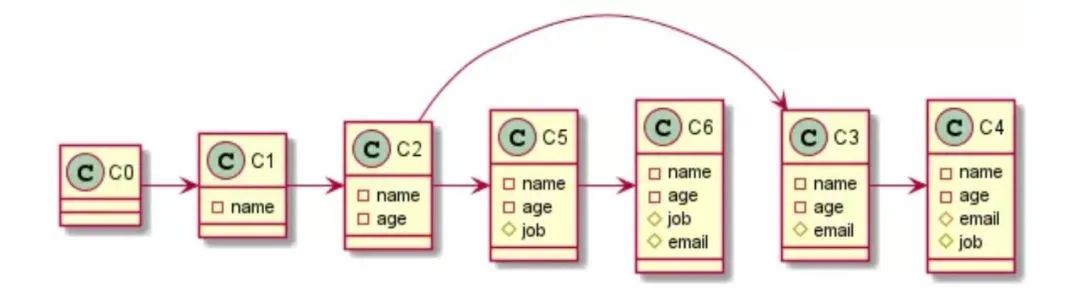
但是后面由于动态添加属性的顺序不同,就造成了属性在类中的偏移量不同,也会生成不同的隐藏类。这样就没办法共享隐藏类,导致浪费资源生成新的隐藏类。
所以我们动态赋值的时候,尽量保证顺序也是一致的。
5、热点函数会被直接编译成机器码
v8在运行的时候,会采集JS代码运行数据。当发现某个函数被频繁调用,那么就会将它标记成热点函数,并且认为他是一个类型稳定的函数。这时候会将它生成更为高效的机器码。
但是在后面的运行中,万一类型发生变化,V8又要回退到字节码。
比如:
function add(a, b){
return a + b
}
// 这里使用add的时候一直传入number类型
for(var i=0; i<10000; ++i){
add(i, i);
}
// 最后却传了string,会退回到字节码,会使得性能受损
add('a', 'b');同理,下面两段代码可以猜猜谁的执行效率高?
// 片段 1
var person = {
add: function(a, b){
return a + b;
} };
obj.name = 'li';
// 片段 2
var person = {
add: function(a, b){
return a + b;}
name: 'li'
};答案是2。结合前面知识,我们可以知道,方法一中动态添加属性会生成一个新的隐藏类。如果add函数此时已经被转成机器码,那么对于方法一来说,就没办法复用了。因为类都是新的了。
所以函数参数类型越稳定,对象内部属性越稳定,V8的效率越高。
总结
从敲下一段JS代码到它最终被计算机理解并执行,中间经历了词法分析,语法分析,生成机器码,执行机器码的过程。
当然这个编译的过程是很复杂的,尤其js还是动态语言,对于js引擎的性能要求就很高了。V8做了很多事情来提升浏览器的性能,其中包括但不限于:
- 脚本流
下载的同时就已经在解析,节省时间
2.字节码缓存
访问同一个页面的时候直接复用之前的字节码,不在重新编译生成
3.内联
将主函数中调用的函数,直接换成将要执行的语句
4.隐藏类
通过隐藏类快速定位到动态加入的属性 注意:动态加入的属性顺序不一样,会造成生成不同的隐藏类,我们动态赋值同一个构造函数对象的时候,尽量保证顺序也是一致的。
5.热点函数编译成机器码
将常用的函数直接一步到位编成机器码。注意:常用的函数传入的类型保持固定。并且对象的属性越稳定,越有利于性能。