用了这么多年的 Java 泛型,你对它到底有多了解?|原创
作为一个 Java 程序员,日常编程早就离不开泛型。泛型自从 JDK1.5 引进之后,真的非常提高生产力。一个简单的泛型 T,寥寥几行代码, 就可以让我们在使用过程中动态替换成任何想要的类型,再也不用实现繁琐的类型转换方法。
虽然我们每天都在用,但是还有很多同学可能并不了解其中的实现原理。今天这篇我们从以下几点聊聊 Java 泛型:
- Java 泛型实现方式
- 类型擦除带来的缺陷
- Java 泛型发展史
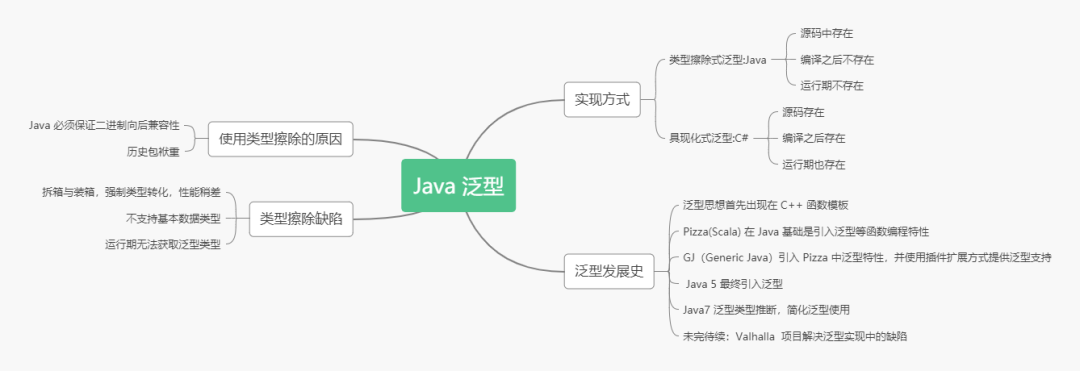
Java 泛型实现方式
Java 采用**类型擦除(Type erasure generics)**的方式实现泛型。用大白话讲就是这个泛型只存在源码中,编译器将源码编译成字节码之时,就会把泛型『擦除』,所以字节码中并不存在泛型。
对于下面这段代码,编译之后,我们使用 javap -s class 查看字节码。
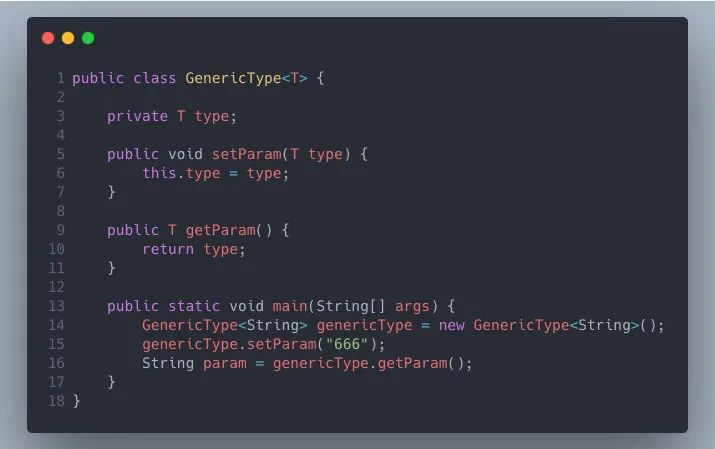
方法源码
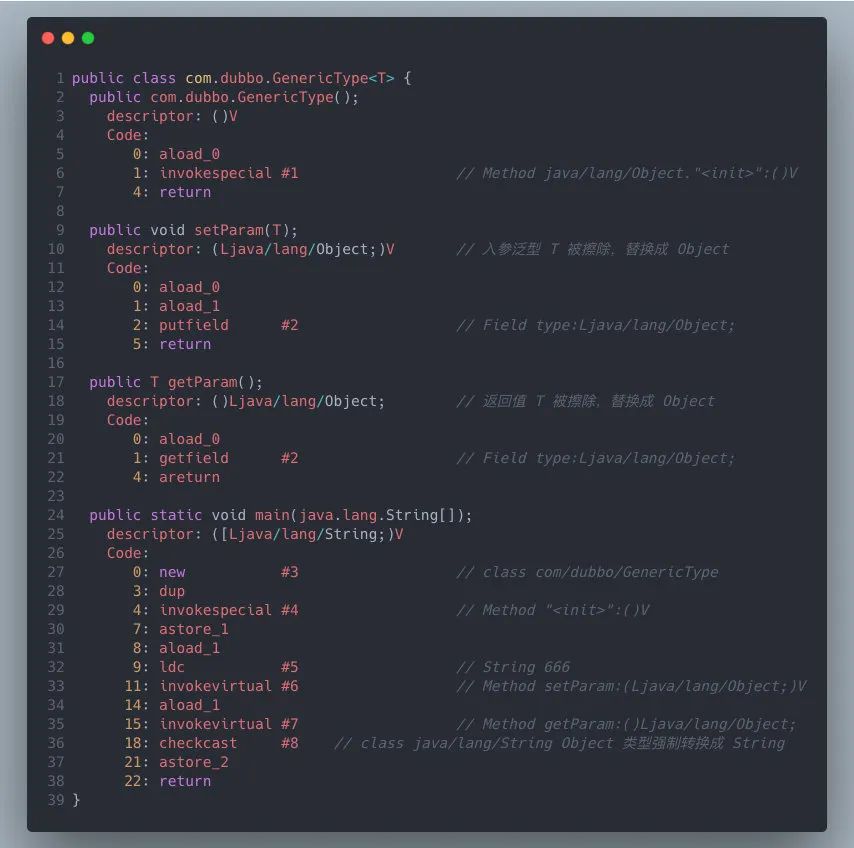
字节码
观察setParam 部分的字节码,从 descriptor 可以看到,泛型 T 已被擦除,最终替换成了 Object。
“ps:并不是每一个泛型参数被擦除类型后都会变成 Object 类,如果泛型类型为 T extends String 这种方式,最终泛型擦除之后将会变成 String。
同理getParam 方法,泛型返回值也被替换成了 Object。
为了保证 String param = genericType.getParam(); 代码的正确性,编译器还得在这里插入类型转换。
除此之外,编译器还会对泛型安全性防御,如果我们往 ArrayList<String> 添加 Integer,程序编译期间就会报错。
最终类型擦除后的代码等同与如下:
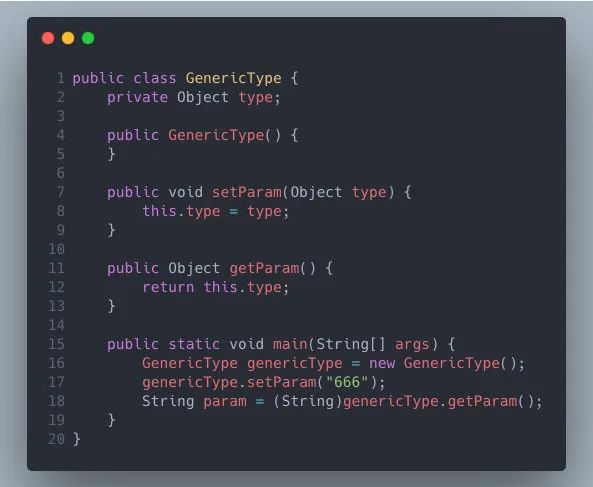
类型擦除带来的缺陷
作为对比,我们再来简单聊下 C# 泛型的实现方式。
**C#**泛型实现方式为「具现化式泛型(Reifiable generics)」,不熟悉的 C#小伙伴可以不用纠结具现化技术概念,我也不了解这些特性--!
简单点来讲,**C#**实现的泛型,无论是在程序源码,还是在编译之后的,甚至是运行期间都是切实存在的。
相对比与 C# 泛型,Java 泛型看起来就像是个「伪」泛型。Java 泛型只存在程序源码中,编译之后就被擦除,这种缺陷相应的会带来一些问题。
不支持基本数据类型
泛型参数被擦除之后,强制变成了 Object 类型。这么做对于引用类型来说没有什么问题,毕竟 Object 是所有类型的父类型。但是对于 int/long 等八个基本数据类型说,这就难办了。因为 Java 没办法做到int/long 与 Object 的强制转换。
如果要实现这种转换,需要进行一系列改造,改动难度还不小。所以当时 Java 给出一个简单粗暴的解决方案:既然没办法做到转换,那就索性不支持原始类型泛型了。
如果需要使用,那就规定使用相关包装类的泛型,比如 ArrayList<Integer>。另外为了开发人员方便,顺便增加了原生数据类型的自动拆箱/装箱的特性。
正是这种「偷懒」的做法,导致现在我们没办法使用原始类型泛型,又要忍受包装类装箱/拆箱带来的开销,从而又带来运行效率的问题。
运行效率
上面字节码例子我们已经看到,泛型擦除之后类型将会变成 Object。当泛型出现在方法输入位置的时候,由于 Java 是可以向上转型的,这里并不需要强制类型转换,所以没有什么问题。
但是当泛型参数出现在方法的输出位置(返回值)的时候,调用该方法的地方就需要进行向下转换,将 Object 强制转换成所需类型,所以编译器会插入一句 checkcast 字节码。
除了这个,上面我们还说到原始基本数据类型,编译器还需帮助我们进行装箱/拆箱。
所以对于下面这段代码来说:
List<Integer> list = new ArrayList<Integer>();
list.add(66); // 1
int num = list.get(0); // 2对于①处,编译器要做就是增加基本类型的装箱即可。但是对于第二步来说,编译器首先需要将 Object 强制转换成 Integer,接着编译器还需要进行拆箱。
类型擦除之后,上面代码等同于:
List list = new ArrayList();
list.add(Integer.valueOf(66));
int num = ((Integer) list.get(0)).intValue();如果上面泛型代码在 C# 实现,就不会有这么多额外步骤。所以 Java 这种类型擦除式泛型实现方式无论使用效果与运行效率,还是全面落后于 C# 的具现化式泛型。
运行期间无法获取泛型实际类型
由于编译之后,泛型就被擦除,所以在代码运行期间,Java 虚拟机无法获取泛型的实际类型。
下面这段代码,从源码上两个 List 看起来是不同类型的集合,但是经过泛型擦除之后,集合都变为 ArrayList。所以 if语句中代码将会被执行。
ArrayList<Integer> li = new ArrayList<Integer>();
ArrayList<Float> lf = new ArrayList<Float>();
if (li.getClass() == lf.getClass()) { // 泛型擦除,两个 List 类型是一样的
System.out.println("6666");
} 这样代码看起来就有点反直觉,这对新手来说不是很友好。
另外还会给我们在实际使用中带来一些限制,比如说我们没办法直接实现以下代码:

List 转换成数组的方法,我们就没办法直接从 List 去获取泛型实际类型,所以我们不得不额外再传入一个 Class 类型,指定数组的类型:
public static <E> E[] convert(List<E> list, Class<E> componentType) {
E[] array = (E[]) Array.newInstance(componentType, list.size());
....
}从上面的例子我们可以看到,Java 采用类型擦除式实现泛型,缺陷很多。那为什么 Java 不采用 C# 的那种泛型实现方式?或者说采用一种更好实现方式?
这个问题等我们了解 Java 泛型机制的历史,以及当时 Java 语言的现状,我们才能切身体会到当时 Java 采用这种泛型实现方式的原因。
Java 泛型历史背景
Java 泛型最早是在 JDK5 的时候才被引入,但是泛型思想最早来自来自 C++ 模板(template)。1996 年 Martin Odersky(Scala 语言缔造者) 在刚发布的 Java 的基础上扩展了泛型、函数式编程等功能,形成一门新的语言-「Pizza」。
后来,Java 核心开发团队对 Pizza 的泛型设计深感兴趣,与 Martin 合作,一起合作开发的一个新的项目「Generic Java」。这个项目的目的是为了给 Java 增加泛型支持,但是不引入函数式编程等功能。最终成功在 Java5 中正式引入泛型支持。

但是由于 Java 自身特性,自带严格的约束,让 Martin 在Generic Java 开发过程中,不得不放弃了 Pizza 中泛型设计。
这个特性就是,Java 需要做到严格的向后兼容性。也就是说一个在 JDK1.2 编译出来 Class 文件,不仅能在 JDK 1.2 能正常运行,还得必须保证在后续 JDK,比如 JDK12 中也能保证正常的运行。
这种特性是明确写入 Java 语言规范的,这是一个对 Java 使用者的一个严肃承诺。
“这里强调一下,这里的向后兼容性指的是二进制兼容性,并不是源码兼容性。也不保证高版本的 Class 文件能够运行在低版本的 JDK 上。
现在困难点在于,Java 1.4.2 之前都没有支持泛型,而 Java5 之后突然要支持泛型,还要让 JDK1.4 之前编译的程序能在新版本中正常运行,这就意味着以前没有的限制,就不能突然增加。
举个例子:
ArrayList arrayList=new ArrayList();
arrayList.add("6666");
arrayList.add(Integer.valueOf(666));没有泛型之前, List 集合是可以存储不同类型的数据,那么引入泛型之后,这段代码必须的能正确运行。
为了保证这些旧的 Clas 文件能在 Java5 之后正常运行,设计者基本有两条路:
- 需要泛型化的容器(主要是容器类型),以前有的保持不变,平行增加一套新的泛型化的版本。
- 直接把已有的类型原地泛型化,不增加任何新的已有类型的泛型版本。
如果 Java 采用第一条路实现方式,那么现在我们可能就会有两套集合类型。以 ArrayList 为例,一套为普通的 java.util.ArrayList,一套可能为 java.util.generic.ArrayList<T>。
采用这种方案之后,如果开发中需要使用泛型特性,那么直接使用新的类型。另外旧的代码不改动,也可以直接运行在新版本 JDK 中。
这套方案看起来没什么问题,实际上C# 就是采用这套方案。但是为什么 Java 却没有使用这套方案那?
这是因为当时 C# 才发布两年,历史代码并不多,如果旧代码需要使用泛型特性,改造起来也很快。但是 Java 不一样,当时 Java 已经发布十年了,已经有很多程序已经运行部署在生产环境,可以想象历史代码非常多。
如果这些应用在新版本 Java 需要使用泛型,那就需要做大量源码改动,可以想象这个开发工作量。
另外 Java 5 之前,其实我们就已经有了两套集合容器,一套为 Vector/Hashtable 等容器,一套为 ArrayList/ HashMap。这两套容器的存在,其实已经引来一些不便,对于新接触的 Java 的开发人员来说,还得学习这两者的区别。
如果此时为了泛型再引入新类型,那么就会有四套容器同时并存。想想这个画面,一个新接触开发人员,面对四套容器,完全不知道如何下手选择。如何 Java 真的这么实现了,想必会有更多人吐槽 Java。
所以 Java 选择第二条路,采用类型擦除,只需要改动 Javac 编译器,不需要改动字节码,不需要改动虚拟机,也保证了之前历史没有泛型的代码还可以在新的 JDK 中运行。
但是第二条路,并不代表一定需要使用类型擦除实现,如果有足够时间好好设计,也许会有更好的方案。
当年留下的技术债,现在只能靠 Valhalla 项目来还了。这个项目从2014 年开始立项,原本计划在 JDK10 中解决现有语言的各种缺陷。但是结果我们也知道了,现在都 JDK14 了,还只是完成少部分目标,并没有解决核心目标,可见这个改动的难度啊。
总结
本文我们先从 Java 泛型底层实现方式开始聊起,接着举了几个例子,让大家了解现在泛型实现方式存在一些缺陷。
然后我们带入 Java 泛型历史背景,站在 Java 核心开发者的角度,才能了解 Java 泛型这么现实无奈原因。
最后作为 Java 开发者,让我们对于现在 Java 一些不足,少些抱怨,多一些理解吧。相信之后 Java 核心开发人员肯定会解决泛型现有的缺陷,让我们拭目以待。
帮助资料
- https://www.zhihu.com/question/38940308
- https://www.zhihu.com/question/28665443
- https://hllvm-group.iteye.com/group/topic/25910
- http://blog.zhaojie.me/2010/05/why-java-sucks-and-csharp-rocks-4-generics.html
- http://blog.zhaojie.me/2010/04/why-java-sucks-and-csharp-rocks-2-primitive-types-and-object-orientation.html
- https://en.wikipedia.org/wiki/Generics_in_Java
- https://www.zhihu.com/question/34621277/answer/59440954
- https://www.artima.com/scalazine/articles/origins_of_scala.html