Javascript中的8种常见数据结构(建议收藏)

1.Stack(栈)
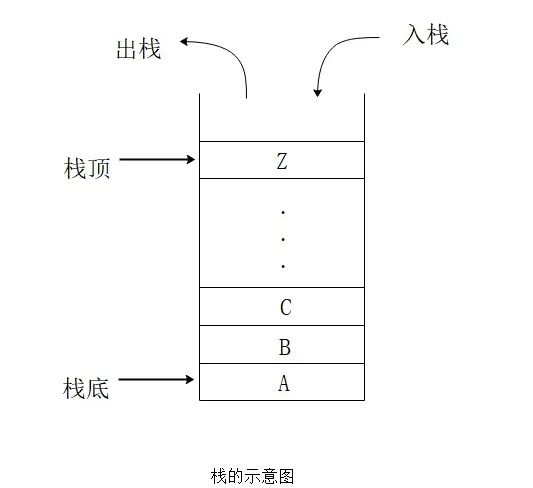
Stack具有以下常见方法:
push:输入一个新元素pop:删除顶部元素,返回删除的元素peek:返回顶部元素length:返回堆栈中元素的数量
Javascript中的数组具有Stack的属性,但是我们使用 function Stack() 从头开始构建Stack
function Stack() {
this.count = 0;
this.storage = {};
this.push = function (value) {
this.storage[this.count] = value;
this.count++;
}
this.pop = function () {
if (this.count === 0) {
return undefined;
}
this.count--;
var result = this.storage[this.count];
delete this.storage[this.count];
return result;
}
this.peek = function () {
return this.storage[this.count - 1];
}
this.size = function () {
return this.count;
}
}2.Queue(队列)
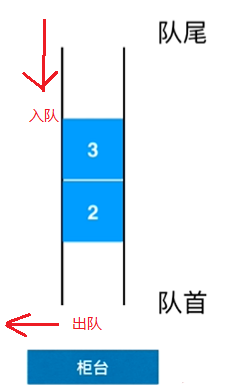
队列具有以下方法:
enqueue:输入队列,在最后添加一个元素dequeue:离开队列,删除前元素并返回front:得到第一个元素isEmpty:确定队列是否为空size:获取队列中元素的数量
JavaScript中的数组具有Queue的某些属性,因此我们可以使用数组来构造Queue的示例:
function Queue() {
var collection = [];
this.print = function () {
console.log(collection);
}
this.enqueue = function (element) {
collection.push(element);
}
this.dequeue = function () {
return collection.shift();
}
this.front = function () {
return collection[0];
}
this.isEmpty = function () {
return collection.length === 0;
}
this.size = function () {
return collection.length;
}
}优先队列
队列还有另一个高级版本。为每个元素分配优先级,并将根据优先级对它们进行排序:
function PriorityQueue() {
...
this.enqueue = function (element) {
if (this.isEmpty()) {
collection.push(element);
} else {
var added = false;
for (var i = 0; i < collection.length; i++) {
if (element[1] < collection[i][1]) {
collection.splice(i, 0, element);
added = true;
break;
}
}
if (!added) {
collection.push(element);
}
}
}
}测试一下:
var pQ = new PriorityQueue();
pQ.enqueue([ gannicus , 3]);
pQ.enqueue([ spartacus , 1]);
pQ.enqueue([ crixus , 2]);
pQ.enqueue([ oenomaus , 4]);
pQ.print();返回
[
[ spartacus , 1 ],
[ crixus , 2 ],
[ gannicus , 3 ],
[ oenomaus , 4 ]
]-
Linked List(链表)
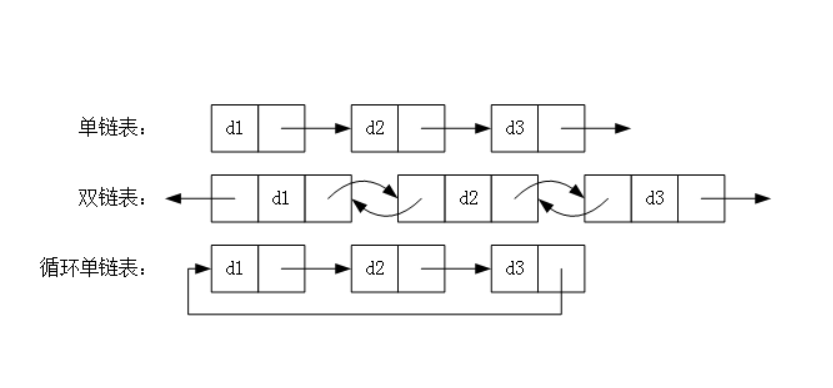
从字面上看,链表是一个链式数据结构,每个节点由两个信息组成:节点的数据和指向下一个节点的指针。链表和传统数组都是线性数据结构,具有序列化的存储方式。当然,它们也有差异:
| 比较 | Array | Linked List |
|---|---|---|
| 内存分配 | 静态内存分配,发生在编译和序列化过程中 | 动态内存分配,发生在运行过程中,非连续的。 |
| 获取元素 | 从索引中读取,速度更快 | 读取队列中的所有节点,直到得到特定的元素,速度较慢 |
| 添加/删除元素 | 由于是顺序记忆和静态记忆,速度较慢 | 由于是动态分配,只需要少量的内存开销,速度更快 |
| 空间结构 | 一维或多维 | 单边/双边,或循环链表 |
单边链表通常具有以下方法:
size:返回节点数head:返回头部的元素add:在尾部添加另一个节点remove:删除某些节点indexOf:返回节点的索引elementAt:返回索引的节点addAt:在特定索引处插入节点removeAt:删除特定索引处的节点
/** 链表中的节点 **/
function Node(element) {
// 节点中的数据
this.element = element;
// 指向下一个节点的指针
this.next = null;
}
function LinkedList() {
var length = 0;
var head = null;
this.size = function () {
return length;
}
this.head = function () {
return head;
}
this.add = function (element) {
var node = new Node(element);
if (head == null) {
head = node;
} else {
var currentNode = head;
while (currentNode.next) {
currentNode = currentNode.next;
}
currentNode.next = node;
}
length++;
}
this.remove = function (element) {
var currentNode = head;
var previousNode;
if (currentNode.element === element) {
head = currentNode.next;
} else {
while (currentNode.element !== element) {
previousNode = currentNode;
currentNode = currentNode.next;
}
previousNode.next = currentNode.next;
}
length--;
}
this.isEmpty = function () {
return length === 0;
}
this.indexOf = function (element) {
var currentNode = head;
var index = -1;
while (currentNode) {
index++;
if (currentNode.element === element) {
return index;
}
currentNode = currentNode.next;
}
return -1;
}
this.elementAt = function (index) {
var currentNode = head;
var count = 0;
while (count < index) {
count++;
currentNode = currentNode.next;
}
return currentNode.element;
}
this.addAt = function (index, element) {
var node = new Node(element);
var currentNode = head;
var previousNode;
var currentIndex = 0;
if (index > length) {
return false;
}
if (index === 0) {
node.next = currentNode;
head = node;
} else {
while (currentIndex < index) {
currentIndex++;
previousNode = currentNode;
currentNode = currentNode.next;
}
node.next = currentNode;
previousNode.next = node;
}
length++;
}
this.removeAt = function (index) {
var currentNode = head;
var previousNode;
var currentIndex = 0;
if (index < 0 || index >= length) {
return null;
}
if (index === 0) {
head = currentIndex.next;
} else {
while (currentIndex < index) {
currentIndex++;
previousNode = currentNode;
currentNode = currentNode.next;
}
previousNode.next = currentNode.next;
}
length--;
return currentNode.element;
}
}-
Set(集合)
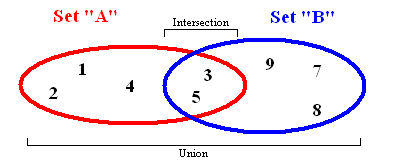
一个典型的集合具有以下方法:
values:返回集合中的所有元素size:返回元素个数has:确定元素是否存在add:将元素插入集合remove:从集合中删除元素union:返回两组交集difference:返回两组的差subset:确定某个集合是否是另一个集合的子集
为了区分ES6中的 set,我们在以下示例中声明为 MySet:
function MySet() {
var collection = [];
this.has = function (element) {
return (collection.indexOf(element) !== -1);
}
this.values = function () {
return collection;
}
this.size = function () {
return collection.length;
}
this.add = function (element) {
if (!this.has(element)) {
collection.push(element);
return true;
}
return false;
}
this.remove = function (element) {
if (this.has(element)) {
index = collection.indexOf(element);
collection.splice(index, 1);
return true;
}
return false;
}
this.union = function (otherSet) {
var unionSet = new MySet();
var firstSet = this.values();
var secondSet = otherSet.values();
firstSet.forEach(function (e) {
unionSet.add(e);
});
secondSet.forEach(function (e) {
unionSet.add(e);
});
return unionSet; }
this.intersection = function (otherSet) {
var intersectionSet = new MySet();
var firstSet = this.values();
firstSet.forEach(function (e) {
if (otherSet.has(e)) {
intersectionSet.add(e);
}
});
return intersectionSet;
}
this.difference = function (otherSet) {
var differenceSet = new MySet();
var firstSet = this.values();
firstSet.forEach(function (e) {
if (!otherSet.has(e)) {
differenceSet.add(e);
}
});
return differenceSet;
}
this.subset = function (otherSet) {
var firstSet = this.values();
return firstSet.every(function (value) {
return otherSet.has(value);
});
}
}-
Hast table(哈希表)
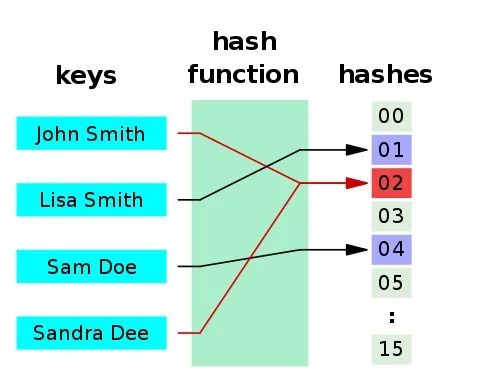
hash function)将键转换为数字列表,这些数字作为对应键的值。要快速使用键获取价值,时间复杂度可以达到O(1)。相同的键必须返回相同的值——这是哈希函数的基础。
哈希表具有以下方法:
add:添加键值对remove:删除键值对lookup:使用键查找对应的值
一个Javascript中简化的哈希表的例子:
function hash(string, max) {
var hash = 0;
for (var i = 0; i < string.length; i++) {
hash += string.charCodeAt(i);
}
return hash % max;
}
function HashTable() {
let storage = [];
const storageLimit = 4;
this.add = function (key, value) {
var index = hash(key, storageLimit);
if (storage[index] === undefined) {
storage[index] = [
[key, value]
];
} else {
var inserted = false;
for (var i = 0; i < storage[index].length; i++) {
if (storage[index][i][0] === key) {
storage[index][i][1] = value;
inserted = true;
}
}
if (inserted === false) {
storage[index].push([key, value]);
}
}
}
this.remove = function (key) {
var index = hash(key, storageLimit);
if (storage[index].length === 1 && storage[index][0][0] === key) {
delete storage[index];
} else {
for (var i = 0; i < storage[index]; i++) {
if (storage[index][i][0] === key) {
delete storage[index][i];
}
}
}
}
this.lookup = function (key) {
var index = hash(key, storageLimit);
if (storage[index] === undefined) {
return undefined;
} else {
for (var i = 0; i < storage[index].length; i++) {
if (storage[index][i][0] === key) {
return storage[index][i][1];
}
}
}
}
}-
Tree(树)
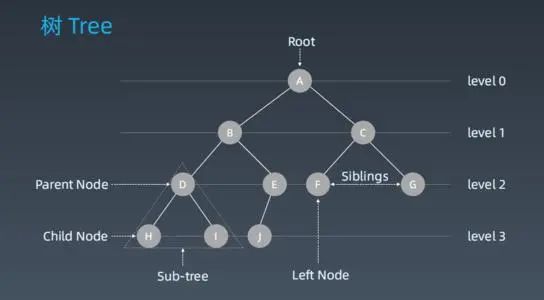
root:树的根节点,无父节点parent node:上层的直接节点,只有一个child node:下层的直接节点可以有多个siblings:共享同一个父节点leaf:没有孩子的节点Edge:节点之间的分支或链接path:从起始节点到目标节点的边Height of Nod:特定节点到叶节点的最长路径的边数Height of Tree:根节点到叶节点的最长路径的边数Depth of Node:从根节点到特定节点的边数Degree of Node:子节点数
这里以二叉树为例。每个节点最多有两个节点,左边节点比当前节点小,右边节点比当前节点大。
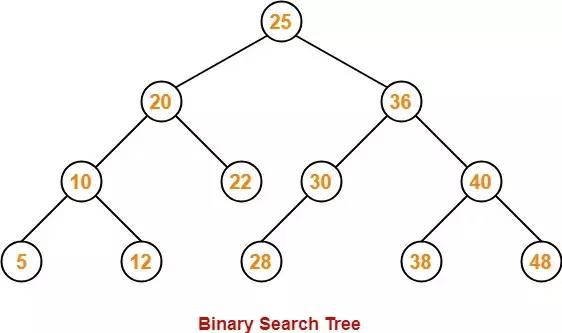
add:将节点插入树findMin:获取最小节点findMax:获取最大节点find:搜索特定节点isPresent:确定某个节点的存在remove:从树中删除节点
JavaScript中的示例:
class Node {
constructor(data, left = null, right = null) {
this.data = data;
this.left = left;
this.right = right;
}
}
class BST {
constructor() {
this.root = null;
}
add(data) {
const node = this.root;
if (node === null) {
this.root = new Node(data);
return;
} else {
const searchTree = function (node) {
if (data < node.data) {
if (node.left === null) {
node.left = new Node(data);
return;
} else if (node.left !== null) {
return searchTree(node.left);
}
} else if (data > node.data) {
if (node.right === null) {
node.right = new Node(data);
return;
} else if (node.right !== null) {
return searchTree(node.right);
}
} else {
return null;
}
};
return searchTree(node);
}
}
findMin() {
let current = this.root;
while (current.left !== null) {
current = current.left;
}
return current.data;
}
findMax() {
let current = this.root;
while (current.right !== null) {
current = current.right;
}
return current.data;
}
find(data) {
let current = this.root;
while (current.data !== data) {
if (data < current.data) {
current = current.left
} else {
current = current.right;
}
if (current === null) {
return null;
}
}
return current;
}
isPresent(data) {
let current = this.root;
while (current) {
if (data === current.data) {
return true;
}
if (data < current.data) {
current = current.left;
} else {
current = current.right;
}
}
return false;
}
remove(data) {
const removeNode = function (node, data) {
if (node == null) {
return null;
}
if (data == node.data) {
// no child node
if (node.left == null && node.right == null) {
return null;
}
// no left node
if (node.left == null) {
return node.right;
}
// no right node
if (node.right == null) {
return node.left;
}
// has 2 child nodes
var tempNode = node.right;
while (tempNode.left !== null) {
tempNode = tempNode.left;
}
node.data = tempNode.data;
node.right = removeNode(node.right, tempNode.data);
return node;
} else if (data < node.data) {
node.left = removeNode(node.left, data);
return node;
} else {
node.right = removeNode(node.right, data);
return node;
}
}
this.root = removeNode(this.root, data);
}
}测试一下:
const bst = new BST();
bst.add(4);
bst.add(2);
bst.add(6);
bst.add(1);
bst.add(3);
bst.add(5);
bst.add(7);
bst.remove(4);
console.log(bst.findMin());
console.log(bst.findMax());
bst.remove(7);
console.log(bst.findMax());
console.log(bst.isPresent(4));
1
7
6
false7. Trie (发音为 “try”)
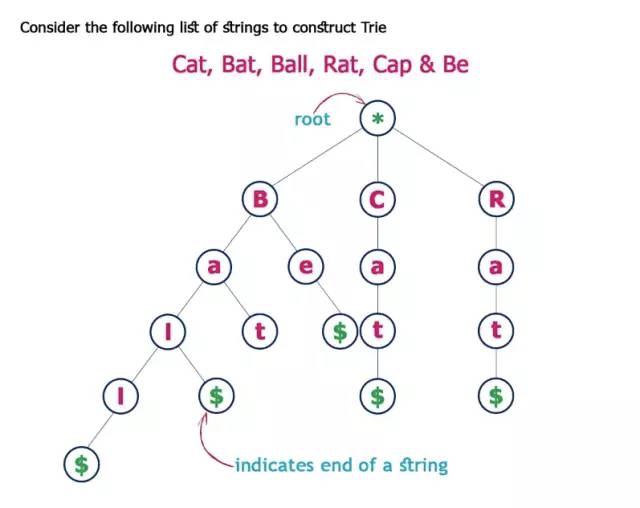
Trie中的每个节点都有一个字母——分支之后可以组成一个完整的单词。它还包括一个布尔指示符,以显示这是否是最后一个字母。
Trie具有以下方法:
add:在字典树中插入一个单词isWord:确定树是否由某些单词组成print:返回树中的所有单词
/** Node in Trie **/
function Node() {
this.keys = new Map();
this.end = false;
this.setEnd = function () {
this.end = true;
};
this.isEnd = function () {
return this.end;
}
}
function Trie() {
this.root = new Node();
this.add = function (input, node = this.root) {
if (input.length === 0) {
node.setEnd();
return;
} else if (!node.keys.has(input[0])) {
node.keys.set(input[0], new Node());
return this.add(input.substr(1), node.keys.get(input[0]));
} else {
return this.add(input.substr(1), node.keys.get(input[0]));
}
}
this.isWord = function (word) {
let node = this.root;
while (word.length > 1) {
if (!node.keys.has(word[0])) {
return false;
} else {
node = node.keys.get(word[0]);
word = word.substr(1);
}
}
return (node.keys.has(word) && node.keys.get(word).isEnd()) ? true : false;
}
this.print = function () {
let words = new Array();
let search = function (node = this.root, string) {
if (node.keys.size != 0) {
for (let letter of node.keys.keys()) {
search(node.keys.get(letter), string.concat(letter));
}
if (node.isEnd()) {
words.push(string);
}
} else {
string.length > 0 ? words.push(string) : undefined;
return;
}
};
search(this.root, new String());
return words.length > 0 ? words : null;
}
}-
Graph(图)
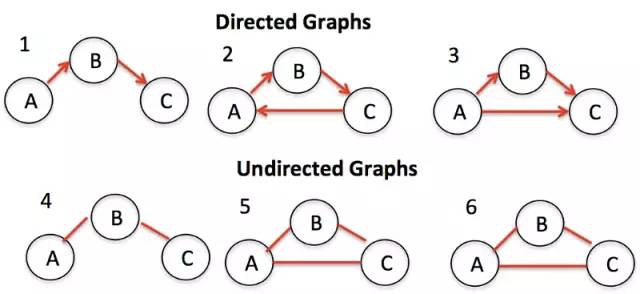
图有两种表示形式:
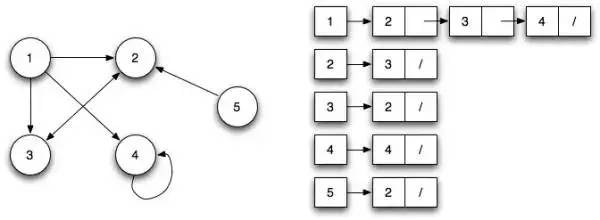
邻接清单
在此方法中,我们在左侧列出所有可能的节点,并在右侧显示已连接的节点。
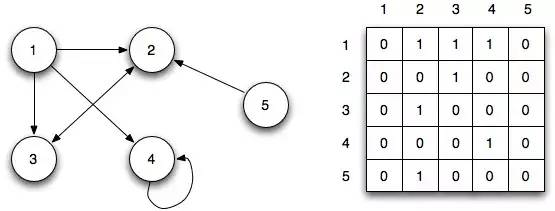
相邻矩阵以行和列的形式显示节点,行和列的交点诠释了节点之间的关系,0表示没有联系,1表示有联系,>1表示权重不同。
让我们看一个例子的BFS在Javascript:
function bfs(graph, root) {
var nodesLen = {};
for (var i = 0; i < graph.length; i++) {
nodesLen[i] = Infinity;
}
nodesLen[root] = 0;
var queue = [root];
var current;
while (queue.length != 0) {
current = queue.shift();
var curConnected = graph[current];
var neighborIdx = [];
var idx = curConnected.indexOf(1);
while (idx != -1) {
neighborIdx.push(idx);
idx = curConnected.indexOf(1, idx + 1);
}
for (var j = 0; j < neighborIdx.length; j++) {
if (nodesLen[neighborIdx[j]] == Infinity) {
nodesLen[neighborIdx[j]] = nodesLen[current] + 1;
queue.push(neighborIdx[j]);
}
}
}
return nodesLen;
}测试一下:
var graph = [
[0, 1, 1, 1, 0],
[0, 0, 1, 0, 0],
[1, 1, 0, 0, 0],
[0, 0, 0, 1, 0],
[0, 1, 0, 0, 0]
];
console.log(bfs(graph, 1));
// 结果
{
0: 2,
1: 0,
2: 1,
3: 3,
4: Infinity
}就是这样——我们已经介绍了所有常见的数据结构,并给出了JavaScript中的例子。这应该能让你更好地了解数据结构在计算机中的工作原理。祝你编码愉快!