50行实现Node.js多进程分页爬虫
前言
Coding 应当是一生的事业,而不仅仅是 30 岁的青春
Node 用来写爬虫还是挺方便的,网上大部分文章都是单进程爬取,抽下班时间写了个多进程爬虫,源码在文末~
每篇文章都希望你能收获到东西,这篇是基于 Node.js 的多进程爬虫,希望你看完有这些收获:
- Node cluster 的简单用法、进程间通信
- 对于一些简单的分页爬虫,能够自己立马实现
- superagent 的简单使用
架构图

目标分析
怪怪我痴迷于日本动画,经常会去豆瓣看排行榜,然后一个人躲在家静静的欣赏,嘘~~

不知道上面的动画你看过多少,反正海贼王我是看完了!
目标锁定豆瓣日本动画排行榜前 10 页数据爬取。
我们先抓个包看看,豆瓣日本动画排行榜的请求逻辑是怎样滴?
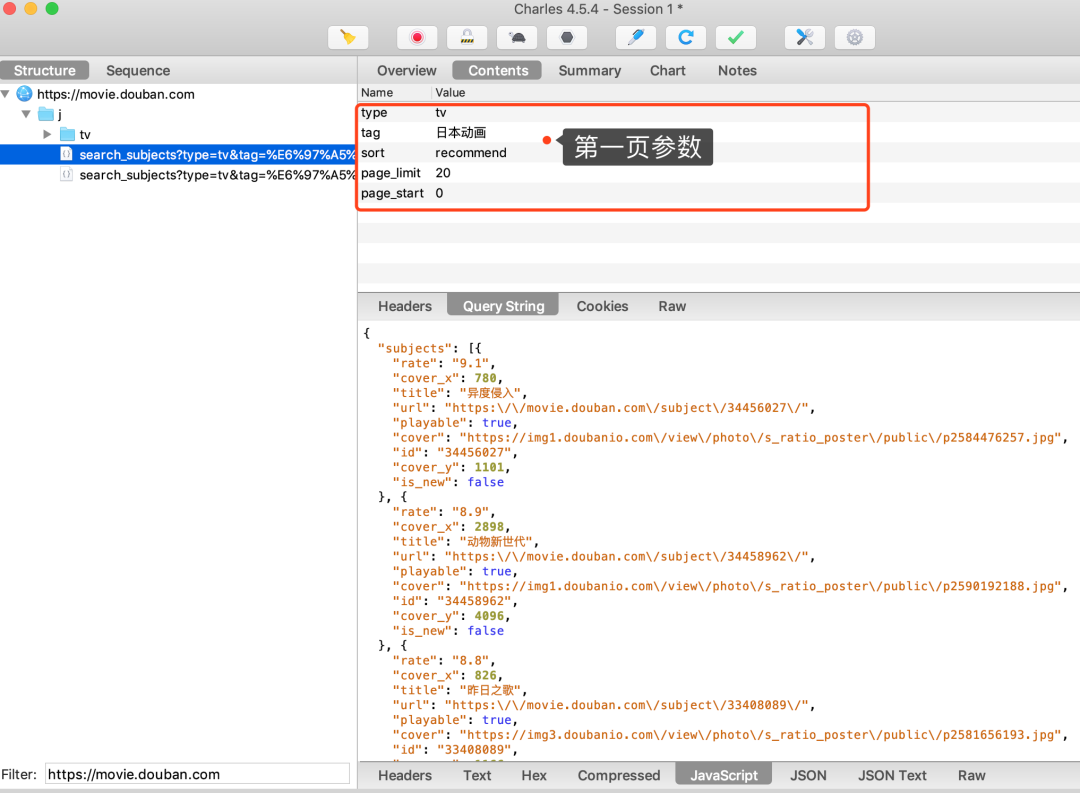
第一页抓包
第二页抓包
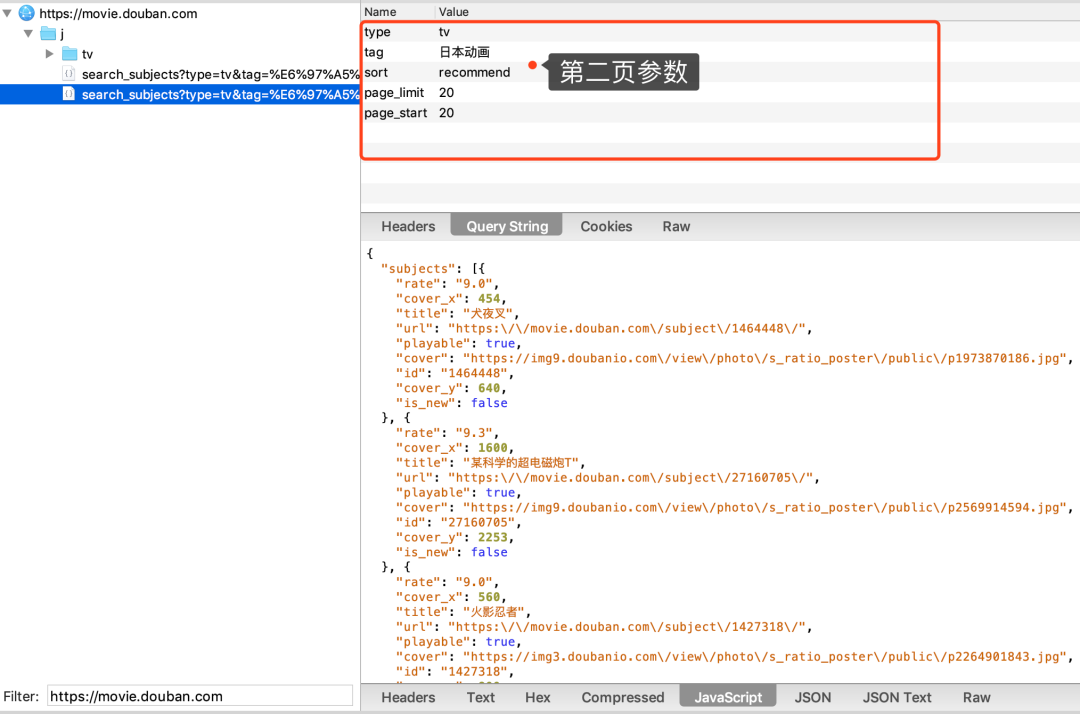
- 热榜日本动画 api 为 https://movie.douban.com/j/search_subjects
- 入参除了 page_start 递增 20,其它入参保持不变
- 请求方式为 get
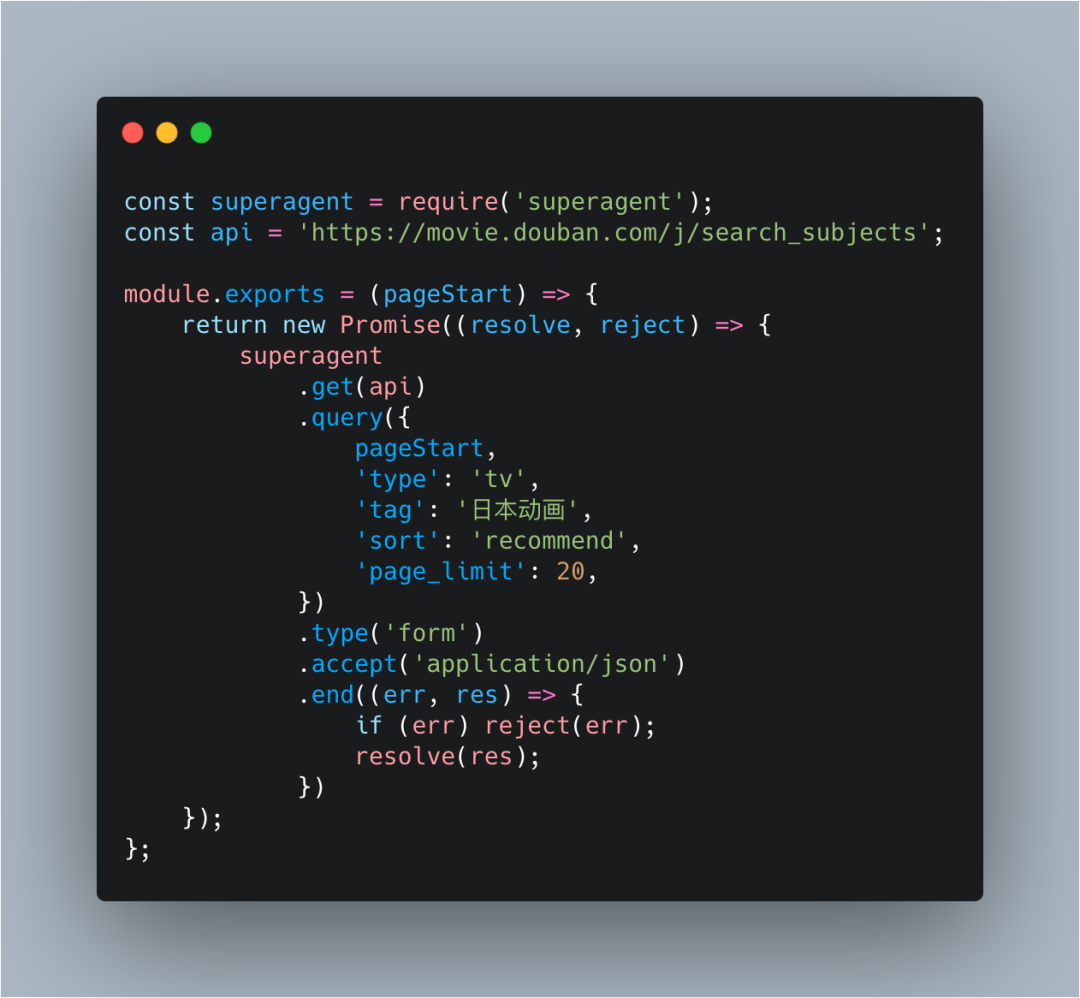
构建 get 请求
superagent 是 Node.js 里面一个蛮方便的客户端请求代理模块,用来打请求非常方便。
根据上面分析得出的小结,配合 superagent,我们可以轻松的构建出请求。
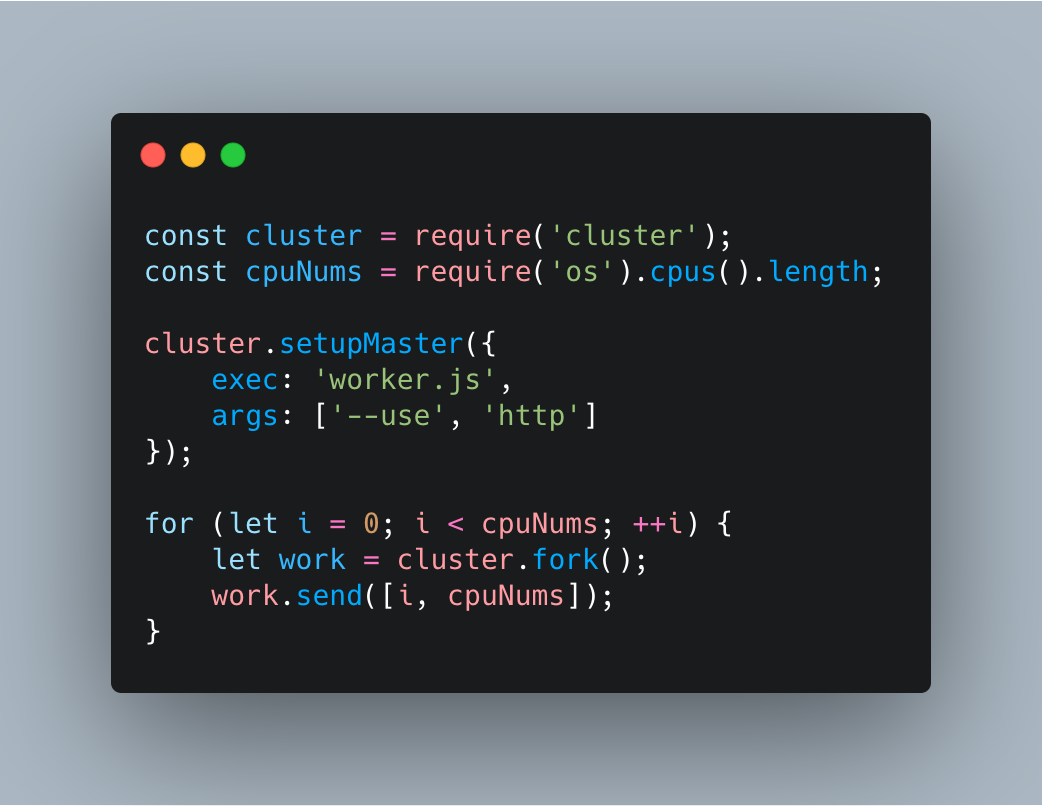
多进程创建
关于 Node 多进程架构底层原理,可以参考我的另外一篇《大前端进阶 Node.js》系列 多进程模型底层实现。
利用 Node 提供的 cluster 模块,可以轻松创建多个子进程。
一般来讲,cpu 是几核的,就创建几个子进程,但是真正的服务端,其实考虑得会更多~
子进程分页抓取
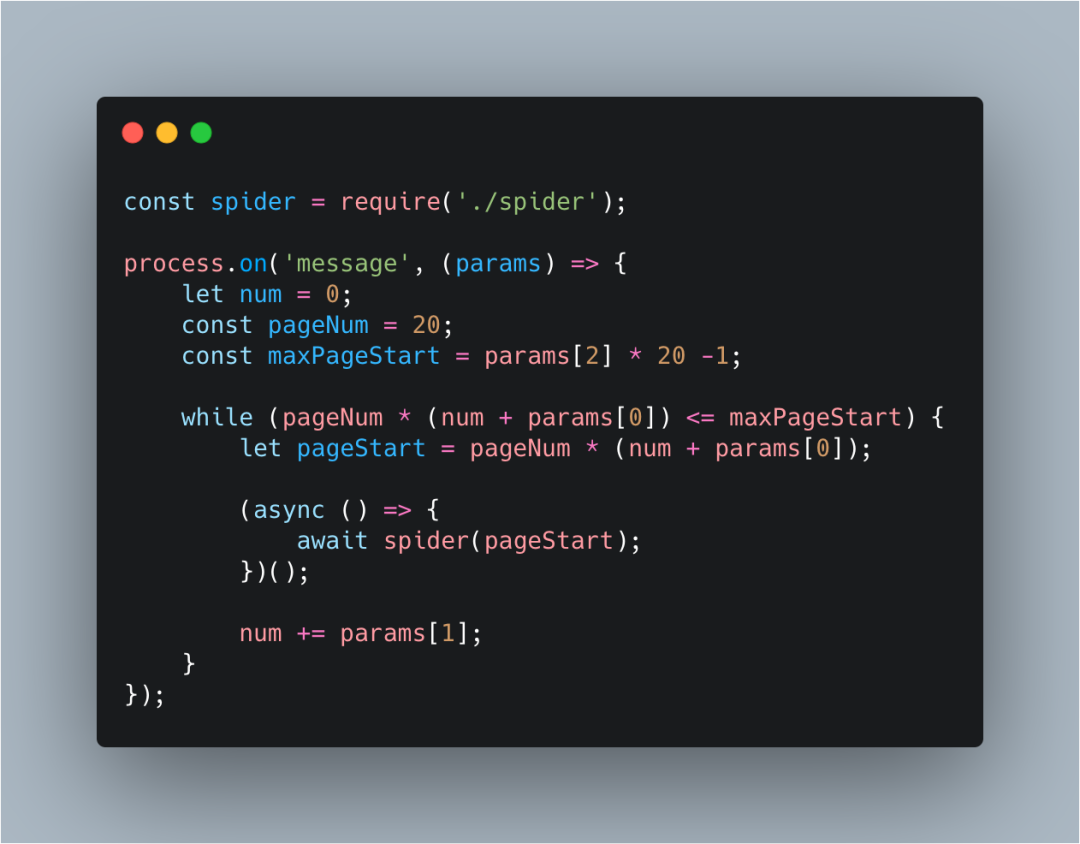
这里涉及到一丢丢的小算法逻辑,其实也很简单啦~
最终就是实现,比如我的 mac 是 4 核的,那么我会开 4 个子进程来进行爬取,下面的小算法就是实现如何让 4 个子进程尽量的均分掉爬取的网络请求数。
专业点来说就是请求的负载均衡,如果你全部的请求都压在一个子进程上面,那么你开这么多子进程,岂不是失去了意义?
关闭子进程
爬取结束后,不用一直开着进程,可以关闭掉,节约资源。
cluster.disconnect(); 多进程无序问题
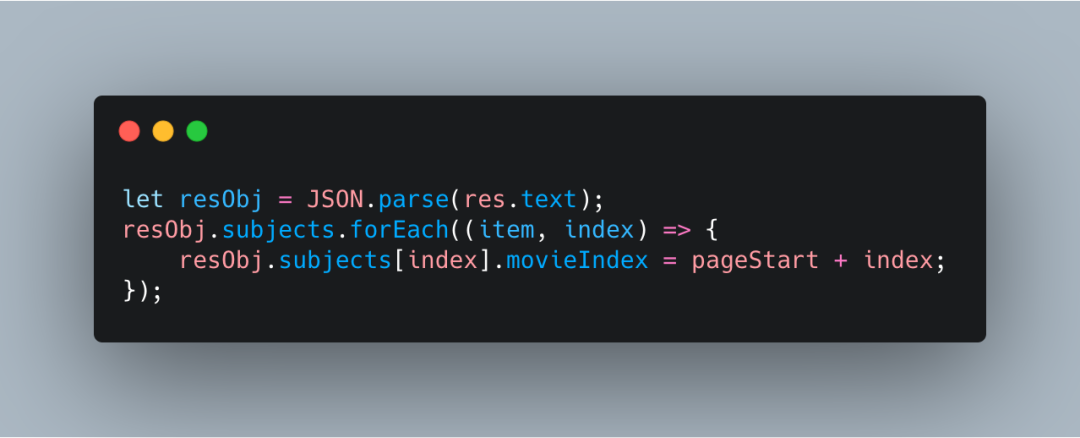
多进程爬取的时候,是 cpu 来进行各个子进程之间的调度的,所以爬取的数据实际上是无序的。比如一共需要爬取前 20 页的数据,最先爬取到的不一定是第 1 页。
我们可以加一个 movieIndex 字段,来标识爬取的顺序。
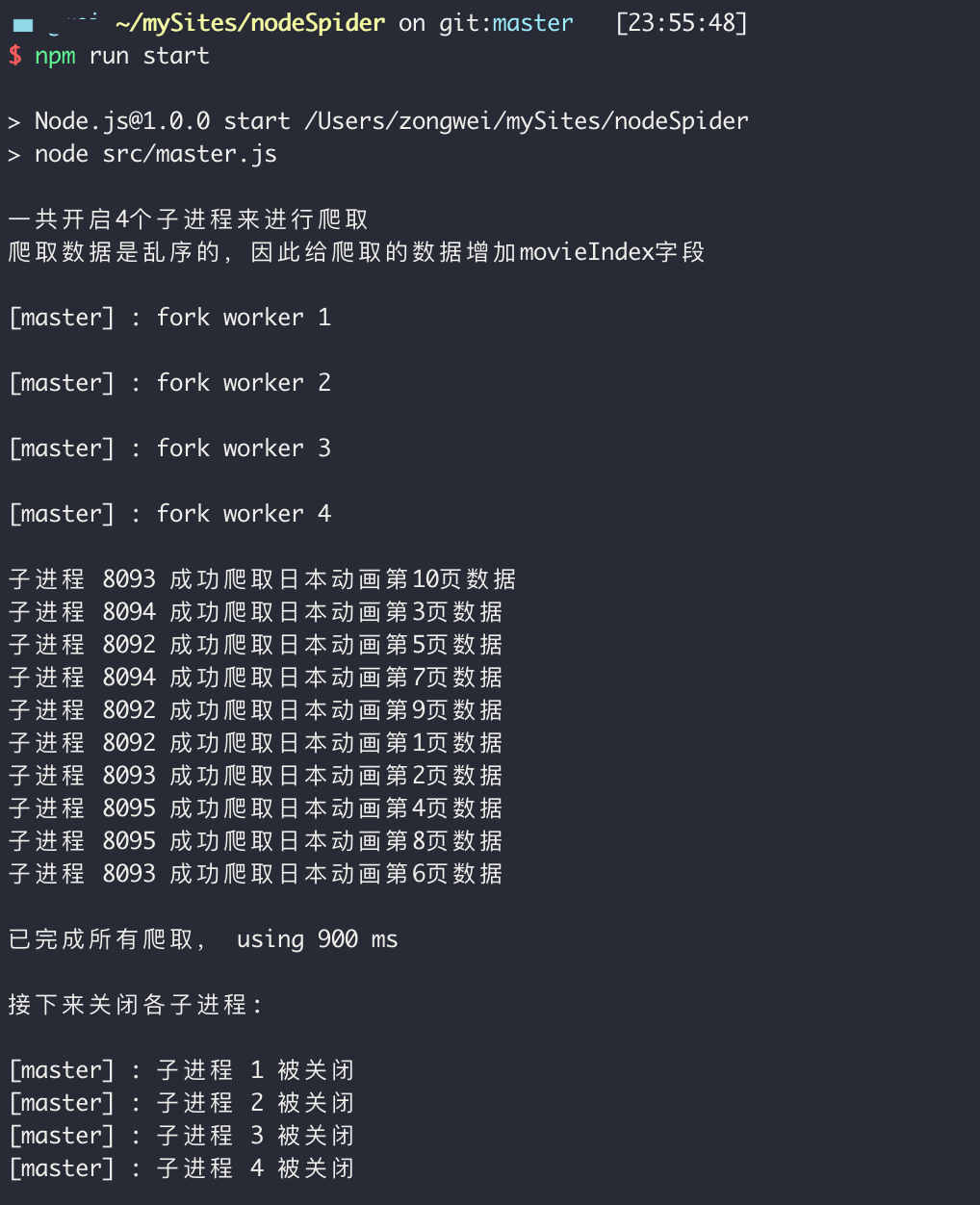
效果
看一下爬取前 10 页的效果。

总结
Node 多进程架构,缓解了 cpu 资源利用问题,在一些耗时的操作上,可以尝试多进程的方式来解决。
在使用多进程的时候,数据同步是一个非常重要的问题,处理不好,容易引发一系列的坑,例如怪怪之前写的《大前端进阶 Node.js》系列 双十一秒杀系统(进阶必看),其中提到的超卖问题,就是多进程数据同步的问题。
本文只是一个非常简单的小爬虫,入门贴,后面会写一些比较深入的 Node 多进程实战帖~