腾讯天籁:音频联合信源信道编码技术白皮书
前言
2020年疫情的突如其来,让数字通信成为了人与人沟通的重要手段;同时也对实时音视频通信(RTC)的稳定性和通讯效果提供了极大考验。由于业务量激增,在保障用户体验方面,RTC业务面临着诸多困难,包括但不限于通话质量、最小化卡顿、端到端延时、带宽成本等。在网络传输过程中,RTC方案,需要面对用户体验、运营成本的双重约束,挑战巨大。本白皮书,将聚焦RTC业务中网络抗性下的体验保障这一命题展开讨论。本文首先对相关技术的特点进行描述。然后,本文重点介绍腾讯天籁推出的音频联合信源信道编码方案。该方案已经在腾讯会议、TRTC等产品推广和部署;在保障用户体验同时,显著降低带宽和延时。
1.背景介绍

图1. 端到端视角下音频通话体验的影响因素
VoIP是一个复杂的链式系统,以单侧的发送端到接收端通信为例,要经过采集、前处理、编码、传输、解码、增强、回放等多个阶段。每个阶段都会影响最终体验。从端到端到角度,影响通话体验的因素,可以分成信源和信道(链路)两个部分。信源部分,主要干扰因素是声学侧的噪声、回声等物理特征;一般地,通过优化音频信号处理方案(包括结合深度学习技术等)进行质量保证。如果说,信源决定最终体验的上界,信道则决定了体验“打折”后的上界。

图2. 语音丢包
RTC业务中,一个重要的挑战就是传输过程中出现丢包;丢包导致接收端解码声音不连续或卡顿,影响体验(图2)。因此,网络抗性提升是RTC业务绕不开的话题。然而,任何一种抗性提升手段,避免不了增加带宽冗余、CPU消耗等。同时,任何一种单一手段,并不能很完美解决上述问题。因此,打造一个好的RTC通话体验,需要联合信源和信道,自顶向下地设计系统。本文将重点讨论如何提升RTC系统中的网络抗性。
2.相关技术概述
1)WebRTC
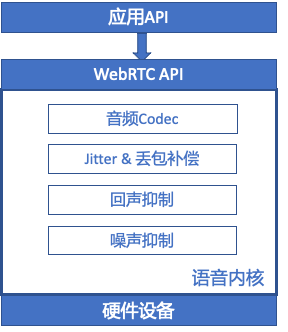
图3. WebRTC引擎
RTC主流商用方案,始于开源。目前的开源体系中,WebRTC使用得最为广泛[1]。WebRTC实现了基于网页的RTC视频会议能力,核心技术包括音视频的采集、编解码、网络传输、显示等功能,并且还支持跨平台:Windows,Linux,Mac,Android。相对全面的平台能力,使得RTC公司优选其作为开发平台,搭建自主品牌的SDK。
因此,相当一部分RTC厂商采用的策略,是完全基于WebRTC,不做底层的改动;针对应用场景,发力于易用性等方面的改进。 然而,在疫情这一特殊背景下,用户对实时音视频通信的稳定性和通讯效果提出了更高要求。简单地基于开源平台改动,并不能从根本上,将通话体验提升一个档次。因此,具备更多核心能力、底层技术的方案,将在市场上更具竞争力。
2)嵌入式编码技术(分层编码)
嵌入式编码,也叫分层编码,通过对信源中不同成份,进行分层处理,以适应网络抗性方面的要求(图4)。原理可以概述为:
- 通过带通滤波器,将输入的语音信号分离成窄带和宽带部分。
- 对窄带部分使用更多码率进行压缩,减少失真。如果还有带宽资源,会先花少量码率对高频进行高效率的参数编码,恢复出质量可接受的高频。进一步,如果还有更多带宽资源,对高频做更为精细编码,恢复出高质量的高频。
- 上述编码的码流,将使用不同优先级传输保障策略,发给接收端。特别地,网络非常差情况下,只发送窄带部分的码流。
- 如果接收端至少收到低频部分,可恢复出窄带语音,基础质量可以保障。根据收到不同编码精度的高频,输出不同质量水平的宽带语音。
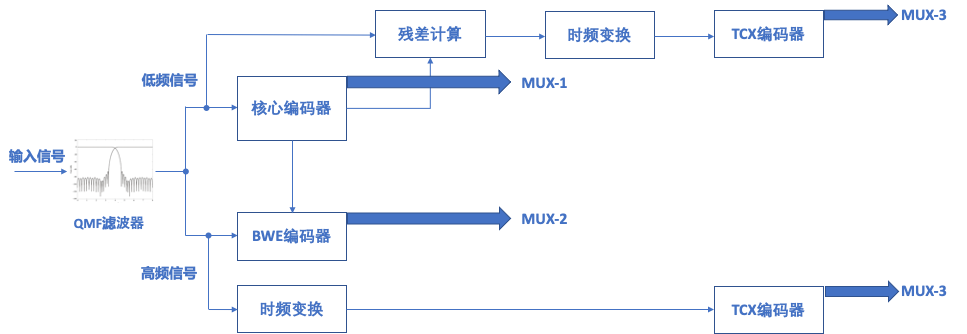
图4. 嵌入式编码基本架构
嵌入式编码,在视频编码系统中被普遍采纳;语音编领域,在2000-2010年这个区间,流行过一段时间,比如ITU-T G729.1和G.718 ,以及相关标准的超宽带演进版本[2, 3]。
然而,嵌入式编码,对于语音业务,存在效率不高的问题。究其原因,语音业务的基础码率偏低,比如20kbps;如果引入嵌入式编码,为了2kbps的分层编码,系统需要做复杂的分层逻辑,在QoE综合质量上不见得是最优策略。因此,2010年之后的主流标准,如IETF OPUS[4],并没有采用嵌入式编码。一般地,即使未采用嵌入编码,相关的编码标准也会采纳多速率编码技术,即支持多种编码码率,用户根据业务特点进行合理配置。
3)多描述编码技术(MDC)
多描述编码(MDC)是一种码流分离技术,具体说,就是将一段音频信号,分离成不同子部分(称之为“描述”);每个部分分别组包,并使用不同的传输路径进行传输。接收端如果收到部分的描述,可以恢复出低质量的音频;如果收到全部描述,可以恢复出高质量的音频[5]。
一个最简单的MDC实施方式是,对一段音频信号进行奇偶抽样;奇数抽样和偶数抽样分别组包传输;接收端即使只收到奇数或者偶数抽样相关的数据包,通过解码和插值,即可恢复出低质量的音频。更为复杂的MDC,包括对奇偶帧进行反复残差分析,确定失真最小的组合变量进行编码和传输。一般地,MDC编码器包含了多个描述的编码器和描述残差关系的编码器,编码器复杂度很高。 MDC的设计理念,假设了网络状态一定不好。MDC的代价,是牺牲(同等码率)天花板质量。一般地,在理想信道下,需要额外消耗20-30%带宽完成MDC。因此,MDC并不会降低带宽的使用量;并且,MDC主要用于窄带部分,宽带部分还是结合了结合了嵌入式编码、频带扩展等技术,提升带宽利用率;否则,带宽使用量会增加。
4)RED机制
RED机制,即IETF RTP Payload for Redundant Audio Data[6]。这个机制提出,跟上文提到的音频码率偏低有关。比如说,每20ms语音帧进行打包操作,包头假设是10kbps、有效载荷是20kbps;这样一种分配,码率浪费严重。因此,RED的建议是,将相邻两个20ms的有效载荷合并成一个数据包。这样,一个数据包中有效载荷比例可达80%。OPUS就沿用了RED机制,甚至将相邻60ms数据合并成一个数据包,共享一个包头。然而,RED机制并没有任何包内抗性;如果没有其它抗性保障,一旦包丢失,影响连续40-60ms数据。
5)带外FEC
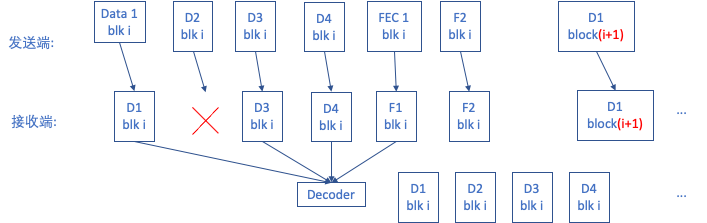
图5. 带外FEC示意图
带外FEC,即在包层进行数据冗余操作的技术[7]。举个例子:如果分组是4,那么在网络传输过程中任意丢掉一个,在接收端任意收到任何顺序的4个属于本分组的数据包,那就可以把丢失的包恢复。具体包括,发送端:将数据包按照参数下发,对数据包进行分组(block),对分组数据加冗余。接收端:收齐分组后即可恢复数据(丢失不超过冗余包数),因为要等分组到齐,存在FEC恢复算法上的延时, FecDelay = Block * 帧长。
6)ARQ重传
所谓ARQ重传,即包确定丢失且无法恢复时,通过请求重传,以增加延时的方式,提升网络抗性[8]。音频快速重传ARQ是“选择重传”算法作为基本的请求策略,算法的关键特色在于重传请求与Jitter Buffer的紧密配合上。几个基本准则包括:
- 请求重传模块记录并缓存所有重传数据包的重传成功所消耗的时间,并将重传延时ArqDelay告知JitterBuffer模块,提高了数据的缓冲等待时长的高可控性。
- 接收端通过ARQ请求,在数据缓冲队列的数据帧被播放之前,当还未重传成功的数据帧在已经达到播放时间时,接收端通过ACK通知取消请求重传,减少无用请求。
3.联合信源信道编码架构
1)方案的设计理念
如前文所述,针对网络抗性问题,主流的RTC解决方案还是围绕信道侧方法进行;特别地,通过加网络冗余,维护一个高的抗性水平。然而,如果完全依赖信道侧方法,实际应用中又面临其它问题:
- 如果网络抗性完全来自于带外,带宽成本激增。
- 重传等操作,带来了包的组合、解析等迭代操作,增加时延。
因此,腾讯天籁的解决方案优先从信源入手,优化带内FEC。所谓带内FEC,最直观的解释就是在第T个包中除了包头和第T帧以外,还包含第T-1帧的信息。事实上,OPUS已经支持上述带内FEC的功能。经过测算,OPUS带内FEC帧的有效载荷约为普通帧的70-80%;然而,只能提供20%丢包率的抗性;投入产出比偏低。 综合上述考虑,腾讯天籁提出下列的联合信源信道编码策略:
- 首先,提升信源侧方法的能力上界。相对于标准带内FEC,新的信源侧FEC,需要更强的单独抗性;比如,支持40%丢包率。
- 其二,灵活调用带外和带内抗性。以期在抗性稳定性和带宽消耗上有一个更为灵活的折衷。相关的控制参数,依赖于测试平台提供的经验数据,进行迭代升级。
- 第三,前向兼容性问题,要保证新旧两种协议无互通问题。
2)方案框架
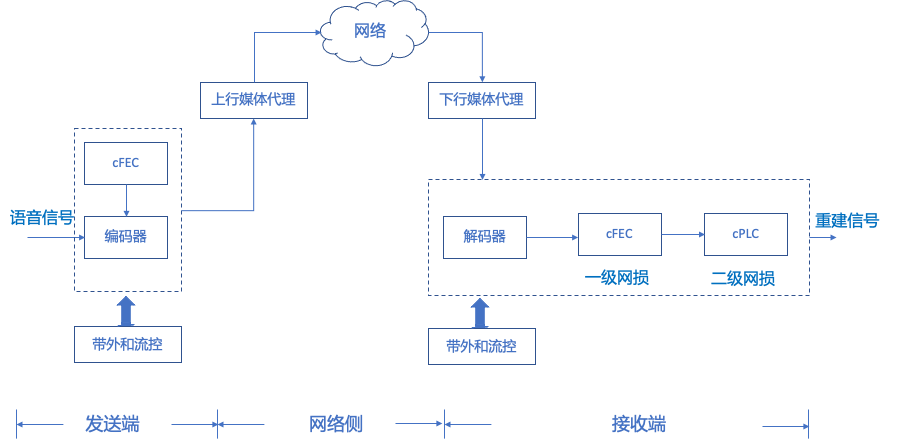
图6. 联合信源信道编码基本框架
腾讯天籁联合信源信道编码的基本框架进行介绍:
- 系统可以分解为发送端、网络侧、接收端。
- 发送端将新方案的码流发往上行媒体代理。其中,cFEC提供了信源侧抗性,带外和流控,根据实际的网络状态,下发具体配置,确保最小带宽和延时成本下的QoE保障。
- 上行媒体代理处,将新方案对应的协议,转换成标准协议。
- 下行媒体代理处,将标准协议转换成新方案的协议,并发给接收端。
- 接收端接收新方案的协议,具备了联合信源信道的能力;以更少的带宽和延时,获得稳定可靠的网络抗性能力。此外,接收端也集成cPLC丢包补偿模块处理突发丢包状态。实时策略,由带外和流控模块控制。在网络有损的情况下,带外FEC或者ARQ重传,最大程度保障数据包可以完整发送到接收端。如果仍然有丢包发生,首先基于cFEC的带内抗性进行质量保障;如果有更多连续数据包丢失,则启动cPLC进行丢包补偿。
3)核心模块
a.信源侧FEC(cFEC)腾讯天籁的cFEC方案,充分借鉴了语音信号的时间上相关性建模,提升带宽利用率。因此,在带宽有限情况下,大幅度提升抗性。图7是cFEC与OPUS原生FEC的效果比较。除了纯净网络外, cFEC相对OPUS原生FEC,可以提升0.1-1.1MOS。特别地,在40%这种比较大丢包率下,采用cFEC技术仍然将MOS分保持在3.0以上。信源侧单独抗性提升,为联合信源信道编码实施提供了足够保障。
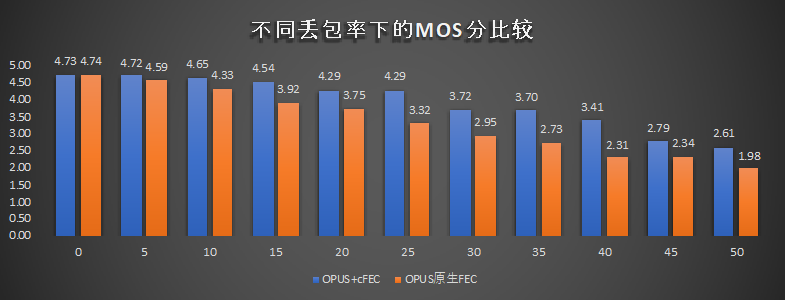
图7. cFEC技术与OPUS原生FEC的抗性能力对比
我们以40%丢包率为例,展示自研cFEC技术,相对现有技术,在抗性提升方面的能力。每个文件的前一段为OPUS原生技术处理结果,后一段为cFEC处理结果。从主观体验看,cFEC处理后的语音质量和连续性非常显著。40%丢包率下,OPUS与cFEC原生技术效果对比(上为女生,下为男生)
b.自适应带外控制策略 首先一个概念就是“流控”。我们可以从三种不同维度去描述“流控”。第一,它是一个配置系统,无论双人或多人通话,系统所需要的基础配置参数,做到云端可控。第二,“流控”是把源端到目标端的传输行为,进行动态的能力交换。第三,基于网络拥塞控制(Congestion control),进行自适应控制;这样,就实现了丢包的时候怎样去抗丢包,抖动的时候怎么样去抗抖动,所有流程进行动态控制。拥塞控制,通过实时监控端到端延时的变化量(Jitter),从而判断当前这个网络是否趋于达到网络拥塞的情况,并给出当前一个合理的带宽预测值。基于带宽预测值,系统会动态配置带外FEC和ARQ策略,从而实现自适应带外控制策略。
c.媒体代理与前向兼容问题的解决 联合信源信道编码应用挑战,是与线上老版本的协议兼容问题、或者说,新旧客户端之间的互联互通问题。如果不进行全面考量,客户端接收到不兼容的码流,解码错误后会引起杂音等问题。如图6所示,我们通过媒体代理处部署相关的协议转录器,进行各种标准或者非标准协议之间的转换,对特定的客户端,接收或者发送对应的协议数据包。 d.基于上下文的连续丢包补偿(cPLC)
丢包补偿技术部署在解码端。它是在带外和带内FEC均失效情况下,根据已经恢复的语音帧,去预测丢失帧。这项技术无需额外带宽,兼容性好。主流PLC只能恢复约20ms的丢失内容,效果十分有限。随着深度学习的发展,工业界和学术界均在尝试引入深度学习,解决连续丢包补偿的问题[9]。这些方案,包括基于谱回归或者生成模型等方式,预测出相关的频谱或者信号。一般地,上述方案可以最多补偿120ms连续丢包数据。但模型大、复杂度高。
腾讯天籁提出的cPLC方案,通过加大了信号处理在算法建模过程中的权重,提取上下文关系进行参数建模,并调用深度学习网络,重建丢失语音。cPLC方案不仅复杂度低,还有着零延时、部署难度低和兼容性好等优势。
图8展示了离散丢包和突发丢包场景下,cPLC与OPUS原生PLC的补偿效果。实验结果表明,在所有测试条件下,cPLC在质量上均优于OPUS原生PLC技术。特别地,在突发丢包场景下,cPLC的优势更为明显。
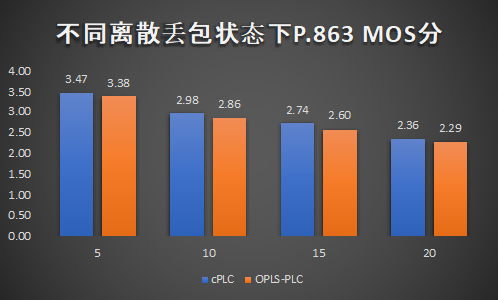
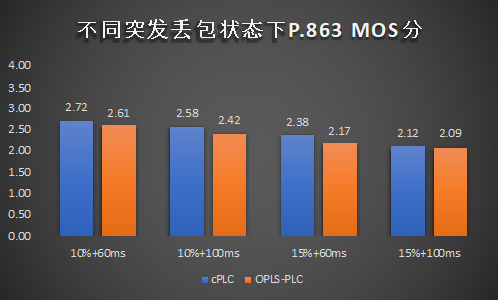
图8. cPLC技术与OPUS原生PLC的能力对比
4.实验结果
目前,腾讯天籁联合信源信道编码方案已经在腾讯会议上线。经过测试,可以降低带宽30%;同时,进一步降低延时40-60ms,进一步提升用户体验。
5.结论
RTC场景下,抗性提升是决定用户体验的重要因素。本文分析了几种典型的机制,并对每种机制的特点进行了描述。然而,疫情背景下,RTC产品的稳定性和通讯效果面临更多挑战,对新方案的需求更为强烈。腾讯天籁联合信源信道编码方案,通过有效地组合信源和信道侧的抗性策略,保证用户体验的同时,有效降低带宽和延时成本。从效果上看,结合了信源、信道的联合优化策略、结合经典信号处理和深度学习的新技术,将成为未来RTC解决方案中的关注点。
参考资料
[1] https://webrtc.org/ [2] ITU-T G.729.1 : G.729-based embedded variable bit-rate coder: An 8-32 kbit/s scalable wideband coder bitstream interoperable with G.729 [3] ITU-T G.718 : Frame error robust narrow-band and wideband embedded variable bit-rate coding of speech and audio from 8-32 kbit/s [4] https://opus-codec.org/ [5] V. K. Goyal, "Multiple Description Coding: Compression Meets the Network," IEEE Signal Processing Magazine, vol. 18, no. 5, pp. 74–94, Sept. 2001. [6] IETF RFC6354: RTP Payload for Redundant Audio Data. [7] J. Bolot, etc. The Case for FEC-based Error Control for Packet Audio in the Internet. 1997. [8] H. Seferoglu, etc. Rate Distortion Optimized Joint ARQ-FEC Scheme for Real-Time Wireless Multimedia. In ICC 2005. [9] https://ai.googleblog.com/2020/04/improving-audio-quality-in-duo-with.html