语音识别流程梳理
语音识别(speech recognition)技术,也被称为自动语音识别(英语:Automatic Speech Recognition, ASR)、电脑语音识别(英语:Computer Speech Recognition)或是语音转文本识别(英语:Speech To Text, STT),其目标是以电脑自动将人类的语音内容转换为相应的文字。
搜狗知音引擎是搜狗公司自主研发的一项专注于自然交互的智能语音技术,该技术集合了语音识别、语义理解、语音交互、以及提供服务等多项功能。最近小编参与了语音相关项目的测试工作,测试中对语音识别的相关概念和原理有了深入了解,本文将对语音识别的流程进行展开讲解。
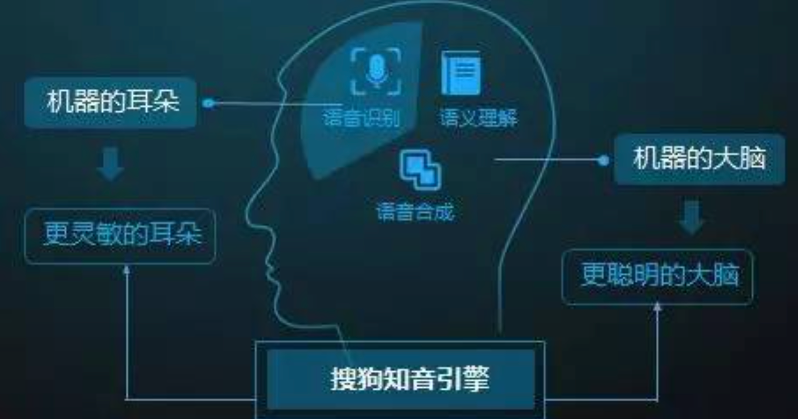
语音识别流程
语音识别流程,就是将一段语音信号转换成相对应的文本信息的过程,它主要包含语音输入、VAD端点检测、特征提取、声学模型、语言模型以及字典与解码几个部分。
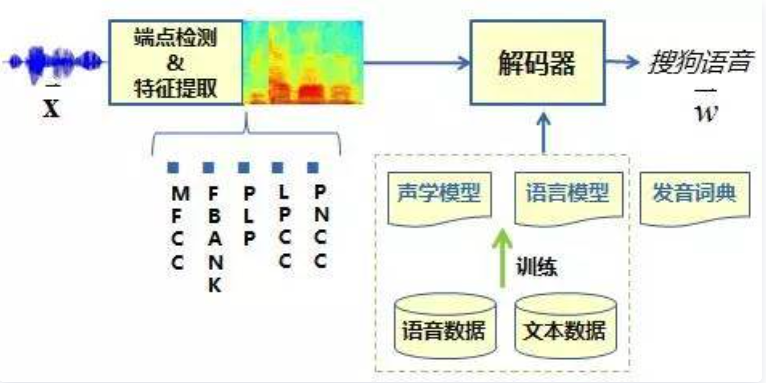
以搜狗语音识别技术流程为例,语音信号经过前端信号处理、端点检测等处理后,逐帧提取语音特征,传统的特征类型包括MFCC、PLP、FBANK等特征,提取好的特征送至解码器,在声学模型、语言模型以及发音词典的共同指导下,找到最为匹配的词序列作为识别结果输出,整体语音识别系统的流程如下:
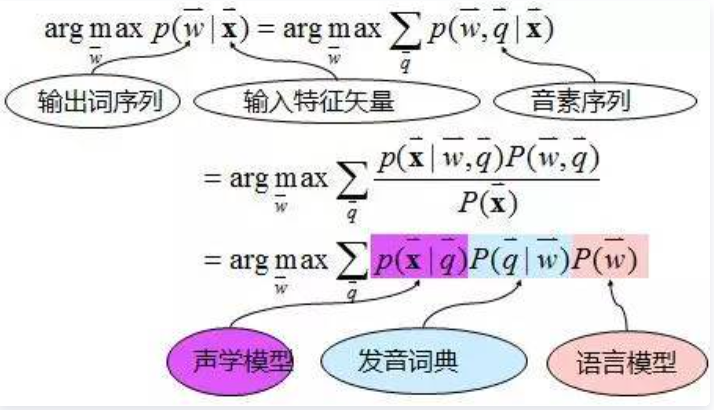
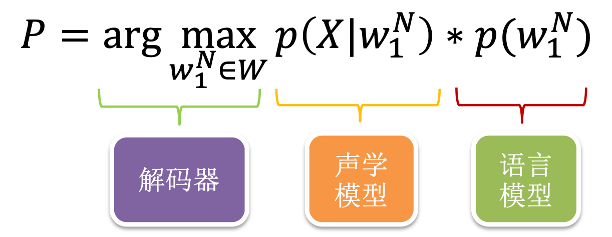
语音识别的核心公式为:
其中,声学模型主要描述发音模型下特征的似然概率,语言模型主要描述词间的连接概率;发音词典主要是完成词和音之间的转换。
接下来,将针对语音识别流程中的各个部分展开介绍。
VAD端点检测
语音识别开始之前,需要先对音频信息进行预处理,预处理过程主要包括端点检测和特征提取。
端点检测,也叫语音活动检测(Voice Activity Detection,VAD),它的目的是对语音和非语音的区域进行区分。端点就是静音和有效语音信号变化临界点,端点检测就是为了从带有噪声的语音中准确的定位出语音的开始点和结束点,去掉静音的部分,去掉噪声的部分,找到一段语音真正有效的内容。
VAD检测主要包括2个方面:特征参数与判决算法。
常用的特征参数有五类,分别是基于能量、频域、倒谱、谐波、长时特征;
其中基于能量的VAD是检测信号的强度,并且假设语音能量大于背景噪声能量,这样当能量大于某一门限时,可以认为有语音存在;
频域特征,通过STFT将时域信号变成频域信号,即使在SNR到0dB时,一些频带的长时包络还是可以区分语音和噪声;
倒谱特征,对于VAD,能量倒谱峰值确定了语音信号的基频(pitch),也有使用MFCC做为特征的;
基于谐波的特征:语音的一个明显特征是包含了基频 F0 及其多个谐波频率,即使在强噪声场景,谐波这一特征也是存在的。可以使用自相关的方法找到基频;
长时特征:语音是非稳态信号。普通语速通常每秒发出10~15个音素,音素见的谱分布是不一样的,这就导致了随着时间变化语音统计特性也是变化的。另一方面,日常的绝大多数噪声是稳态的(变化比较慢的),如白噪声/机器噪声。
VAD的判决算法也多种多样,如门限算法、统计模型方法、机器学习方法等。
实际上,一方面需要对每个语音帧的帧内信息进行判决;另一方面由于语音帧之间有很强的相关性,相邻帧的信息对当前帧的影响也应该被关注。
VAD 作为整个流程的最前端,端点检测处理得好,不仅将处理的时间序列变小,还能消除无声段道噪声。
特征提取
特征提取是通过将语音波形以相对最小的数据速率转换为参数表示形式进行后续处理和分析来实现的,MFCC(Mel Frequency Cepstral Coefficents)是一种在自动语音和说话人识别中广泛使用的特征。
下图是MFCC特征提取的整个过程,下面将一一介绍特征提取过程每一步的作用:
预加重
在音频录制过程中,高频信号更容易衰减,而像元音等一些因素的发音包含了较多的高频信号的成分,高频信号的丢失,可能会导致音素的共振峰并不明显,使得声学模型对这些音素的建模能力不强。预加重是个一阶高通滤波器,可以提高信号高频部分的能量
分帧
语音信号是一个非稳态的、时变的信号。但在短时间范围内可以认为语音信号是稳态的、时不变的。这个短时间一般取10-30ms,因此在进行语音信号处理时,为减少语音信号整体的非稳态、时变的影响,从而对语音信号进行分段处理,其中每一段称为一帧,帧长一般取25ms。为了使帧与帧之间平滑过渡,保持其连续性,分帧一般采用交叠分段的方法,保证相邻两帧相互重叠一部分。相邻两帧的起始位置的时间差称为帧移,我们一般在使用中帧移取值为10ms。
加窗
因为后面会对信号做FFT,而FFT变换的要求为:信号要么从-∞到+∞,要么为周期信号。现实世界中,不可能采集时间从 -∞ 到 +∞ 的信号,只能是有限时间长度的信号。由于分帧后的信号是非周期的,进行 FFT 变换之后会有频率泄露的问题发生,为了将这个泄漏误差减少到最小程度(注意我说是的减少,而不是消除),我们需要使用加权函数,也叫窗函数。加窗主要是为了使时域信号似乎更好地满足 FFT 处理的周期性要求,减少泄漏。
DFT
离散傅里叶变换(Discrete Fourier Transform,缩写为 DFT),将每个窗口内的数据从时域信号转为频域信号。
梅尔滤波器组
从 FFT 出来的结果是每个频带上面的幅值,然而人类对不同频率语音有不同的感知能力:对1kHz以下,与频率成线性关系,对1kHz以上,与频率成对数关系。频率越高,感知能力就越差。在Mel频域内,人的感知能力为线性关系,如果两段语音的Mel频率差两倍,则人在感知上也差两倍。
梅尔滤波器组将梅尔域上每个三角滤波器的起始、中间和截止频率转换线性频率域,并对 DFT 之后的谱特征进行滤波,再进行 log 操作,得到Fbank(Filter Bank)特征。
IDFT
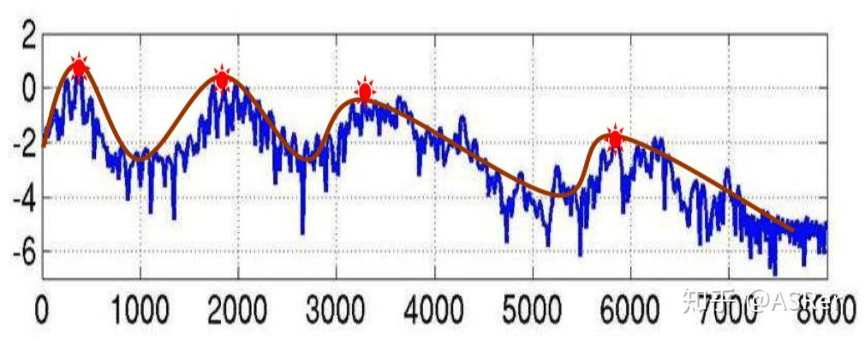
FBank 特征的频谱图如下图所示,图中四个红点表示的是共振峰,是频谱图的主要频率,在语音识别中,根据共振峰来区分不同的音素(phone),所以我们可以把图中红线表示的特征提取出来就行,移除蓝色的影响部分。其中红色平滑曲线将各个共振峰连接起来,这条红线,称为谱包络(Spectral Envelope),蓝色上下震荡比较多的线条称为谱细节(Spectral details)。这个过程是通过逆离散傅里叶变换(IDFT,Inverse Discrete Fourier Transform)实现的。
声学模型
声学模型(Acoustic model)是语音识别系统中最为重要的部分之一,利用了声学、语音学、环境特性以及说话人性别口音等信息,对语音进行建模。
声学模型可以理解为是对发声的建模,它能够把语音输入转换成声学表示的输出,更准确的说是给出语音属于某个声学符号的概率。在英文中这个声学符号可以是音节或者更小的颗粒度音素(phone),在中文中这个声学符号可以是声韵母或者是颗粒度同英文一样小的音素。
比较经典的声学建模模型为隐马尔科夫模型(Hidden Markov Model,HMM)。隐马尔可夫模型是一个离散时域有限状态自动机,这一马尔可夫模型的内部状态外界不可见,外界只能看到各个时刻的输出值。对语音识别系统,输出值通常就是从各个帧计算而得的声学特征。
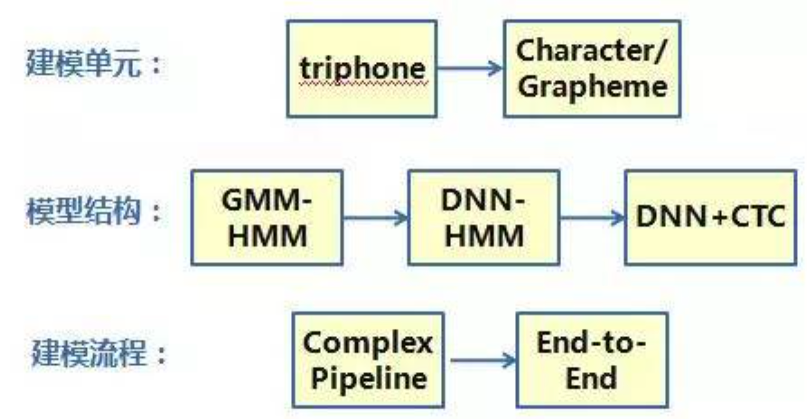
近年来,随着深度学习的兴起,使用了接近30年的语音识别声学模型HMM(隐马尔科夫模型)逐渐被DNN(泛指深度神经网络)所替代,模型精度也有了突飞猛进的变化,整体来看声学建模技术从建模单元、模型结构、建模流程等三个维度都有了比较明显的变化,如图所示:
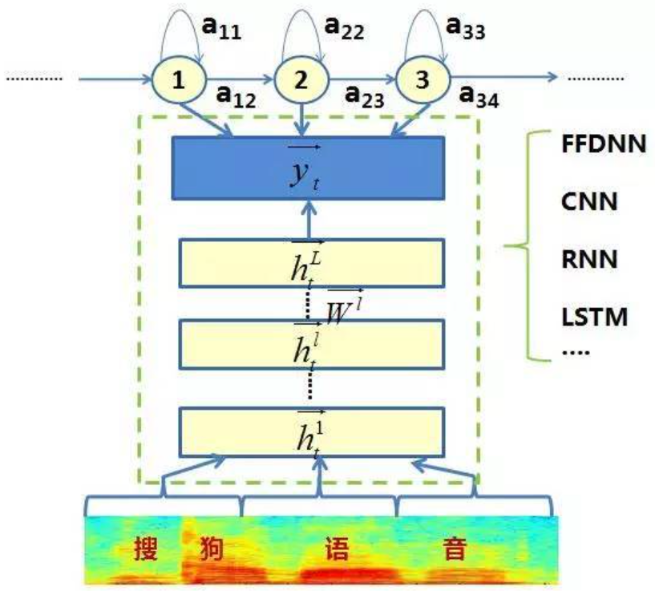
下图为DNN-HMM混合建模框架,DNN的输入是传统的语音波形经过加窗、分帧,然后提取出来的频谱特征,如MFCC、PLP或更底层的滤波器组(filter bank,FBK)声学特征等。输入特征使用了在当前帧左右拼帧的方式来实现模型对时序信号长时相关性的建模,可以更好地利用上下文的信息;模型输出则保持了GMM-HMM经常使用的trihone共享状态(senone)。
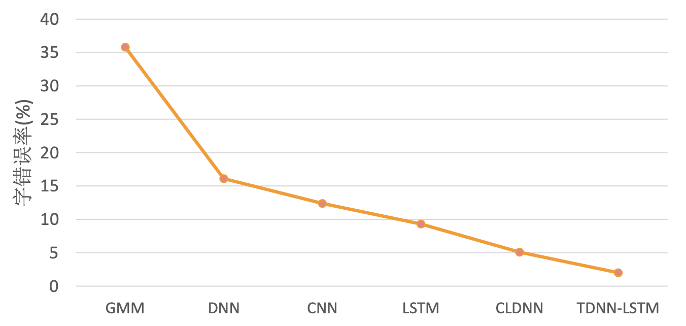
如下图为各种声学模型对识别结果(字错率)的影响,选择合适的声学模型是语音识别最核心的关键之一。
语言模型
语言模型表示某一字序列发生的概率,是对一组字序列构成的知识表示。它的作用之一为消解多音字的问题,在声学模型给出发音序列之后,从候选的文字序列中找出概率最大的字符串序列。
语音识别中常用的语言模型是N元文法(N-Gram),即统计前后N个字出现的概率。N 元文法假定某一个字出现的概率仅与前面 N-1 个字出现的概率有关系。N-Gram模型中的N越大,需要的训练数据就越多。一般的语音识别系统可以做到trigram(N=3)。
语言模型还会对声学的解码作约束和重打分,让最终识别结果符合语法规则。目前最常见的是N-Gram语言模型和基于RNN的语言模型。
字典
语音识别中的字典,就是发音字典,是字词对应的音素index集合,是字词和音素之间的映射。中文中就是拼音与汉字的对应,英文中就是音标与单词的对应,其目的是根据声学模型识别出来的音素,来找到对应的汉字(词)或者单词,用来在声学模型和语言模型建立桥梁,将两者联系起来。
发音字典的形式举例如下:

解码器
解码器模块主要完成的工作是,给定输入特征序列的情况下,在由声学模型、发音词典和语言模型等知识源组成的搜索空间(Search Space)中,通过一定的搜索算法,寻找使概率最大的词序列。
它的核心公式:
在解码过程中,各种解码器的具体实现可以是不同的。按搜索空间的构成方式来分,有动态编译和静态编译两种方式。根据应用场景不同,可以分为在线解码器(在服务器端解码) 、离线解码器(在设备端解码)、二遍解码器、唤醒解码器、固定句式解码器。根据技术分类,可以分为基于lexicon tree的解码器、基于WFST的解码器、基于lattice rescore的解码器等。
总结
以上是小编对语音识别整个流程的初步调研分享,如有不足之处请大家多指教,待后续更深入了解后再分享给大家。
文章参考:
- 主流声学模型对比https://cloud.tencent.com/developer/article/1451421
- 语音识别之特征提取https://zhuanlan.zhihu.com/p/147386972
- 语音识别之解码器技术简介https://zhuanlan.zhihu.com/p/23648888