微信AI从识物到通用图像搜索的探索揭秘
微信识物是一款主打物品识别的 AI 产品,通过相机拍摄物品,更高效、更智能地获取信息。2020 年,微信识物拓展了更多识别场景,上线了微信版的图片搜索。本篇文章将与大家分享微信识物从识物拓展到通用图像搜索领域的发展过程。
微信识物
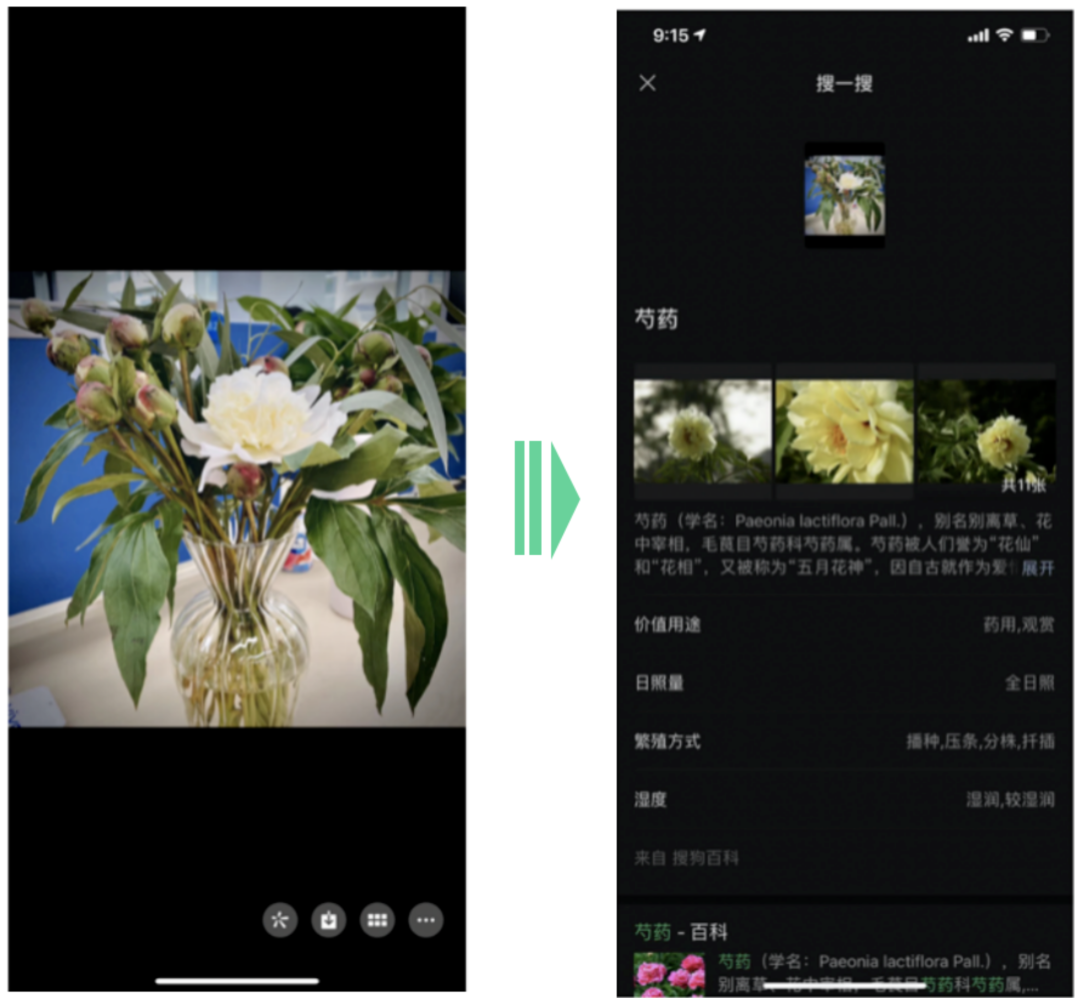
以上小视频简单介绍了识物的产品形态,它对微信扫一扫的扫封面能力进行了升级。打开微信扫一扫,左滑切换到“识物”功能,对准想要了解的物品正面,可以获取对应的物品信息,包括物品百科、相关资讯、相关商品。在微信识物发布不久,也快速地支持了像识花、识车这些实用的识别能力。

首先我们会对 query 的图片做目标检测,去除背景干扰。
然后以图像主体进行检索,拿到图像召回的列表。
最后一步是进行信息提炼,得到商品的标题,品牌,主体,主图等。

我们的识别效果究竟如何,我们也跟公司内外的识别引擎作了一些对比发现,基于微信自研的识物引擎和微信小程序商城海量的商品数据,我们取得了一流的识别效果。
跟业界同类产品相比,微信识图无论是在体验、识别效果、内容和商品上,都更具有微信的特色。
微信图像搜索
识物搜索的现状
那么讲起图像搜索,大家肯定马上想到 google、baidu。这些搜索引擎在 10 年前就上线了图像搜索,并且经过多年经营,已经成了一个很大的入口。 微信识图又是怎么样的,如何基于微信的场景做出差异化?这是我们首先思考的问题。
微信识图
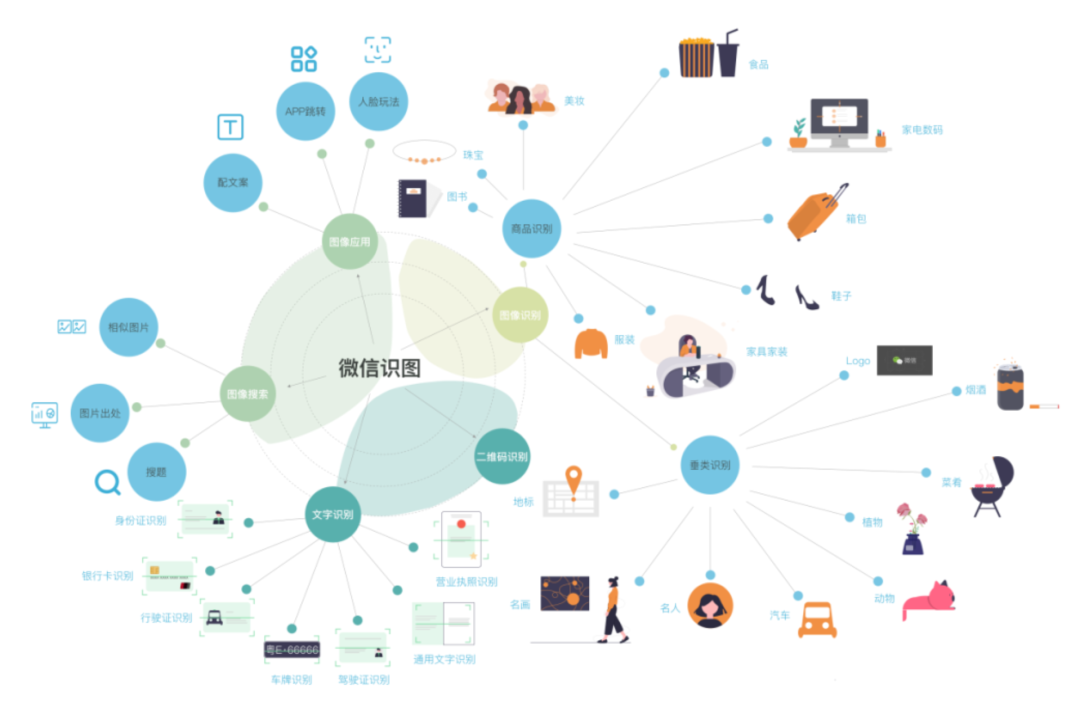
商品识别
细分类识别
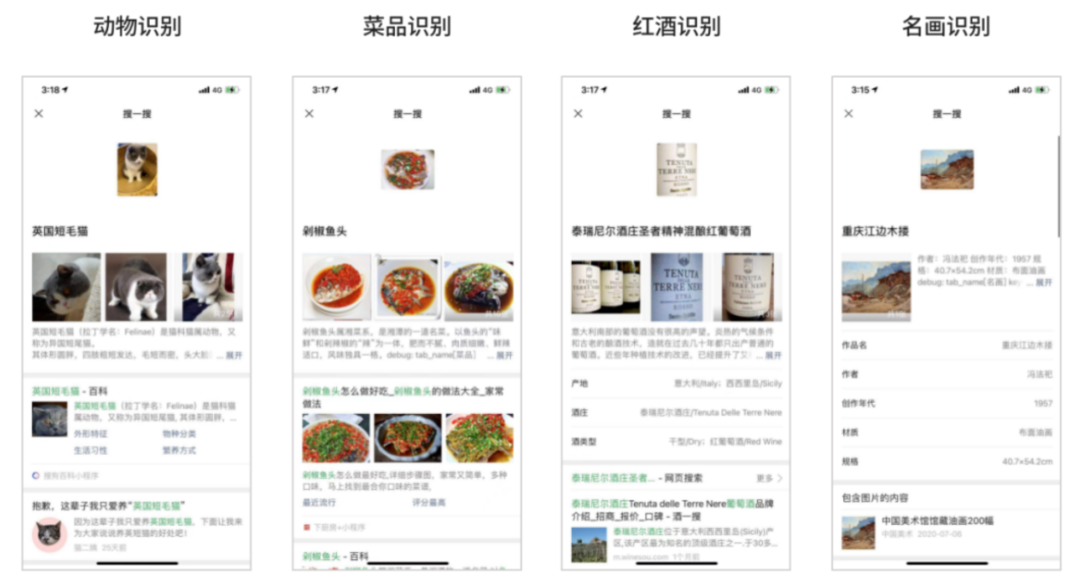
以图搜图的拓展

包含图片内容:溯源。当图片是某个电影里的截图,你想要知道它的出处。或者你想知道你的原创图片是否被他人转载或者盗用。又或者有一个长得很漂亮的美女主动加你微信,说头像是本人。这时候通过图片搜索,我们很容易一探究竟。 相似图片:找一些相同风格的图片。
搜索物料:通过识别 logo+ocr 的方法,可以实现内容提取并跳转的能力。
以图搜图的系统实现
前面是一些产品介绍,接下来我详细聊一下以图搜图的系统实现,核心讲三个东西:分类、检测、检索。
分类篇 | 图片内容标签体系
图像分类是 CV 的基础,为了更好地理解微信内图片的类型分布,我们构建了一套图片内容标签体系。从图上来源上,我们主要分为广告、拍照、手机截屏这三种。从图片的内容标签上,我们划分成 9 个一级类目,42 个二级类目。这是一个多标签、多任务的分类任务。
分类篇 | 多标签分类
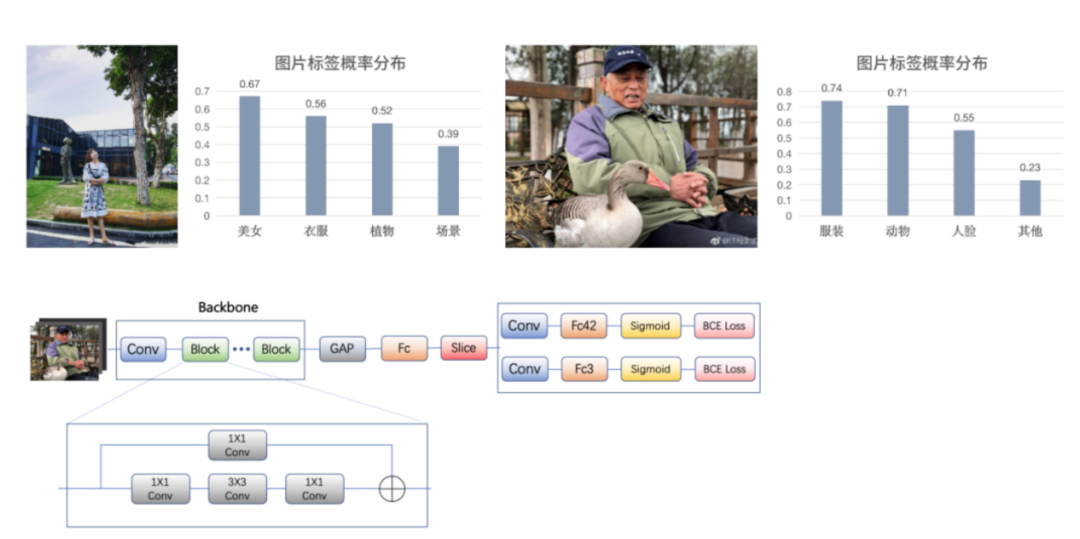

分类篇 | 细分类的应用

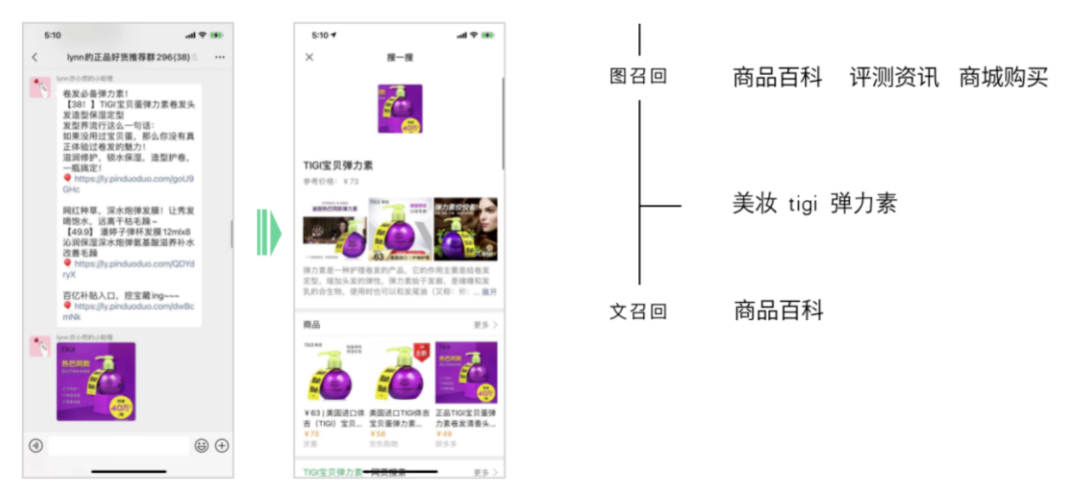
电商场景:我们要识别的集合是无限大的,而且还是动态的。所以我们是通过动态图像召回。从召回的结果上推断出商品的具体款式。
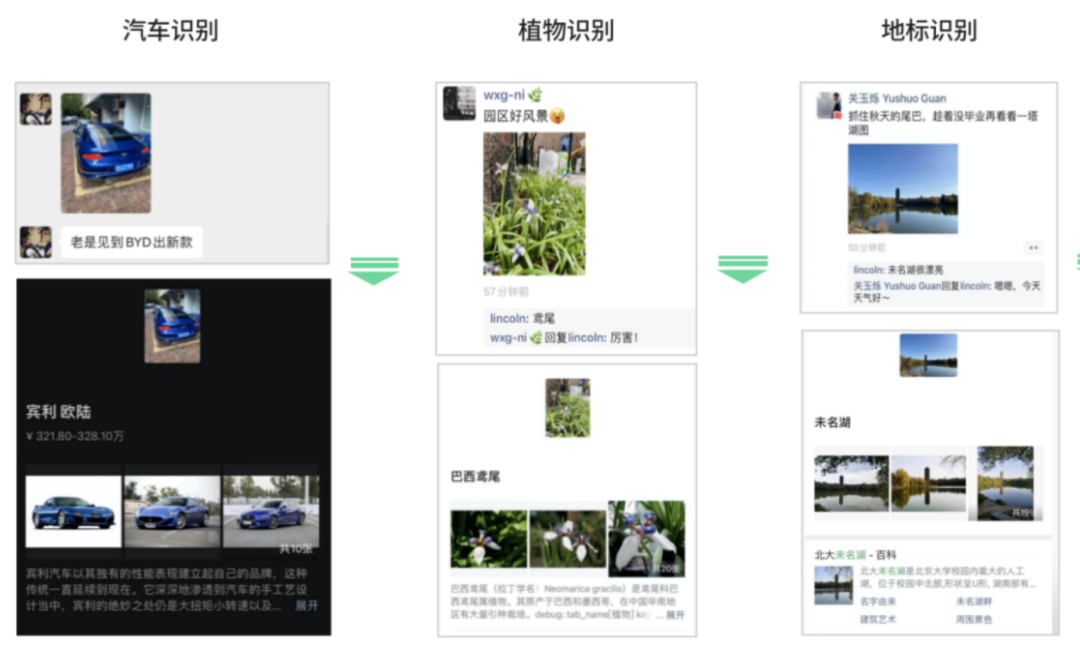
动植物汽车这种场景:集合是相对固定的。而且需要一些专业的数据库。我们采用分类+检索的方法,在具体的处理逻辑上,也依据具体的场景不同而不同。目前我们支持了动物/植物/菜品/地标/汽车/名画/红酒识别。
检测篇 | 移动端主体检测
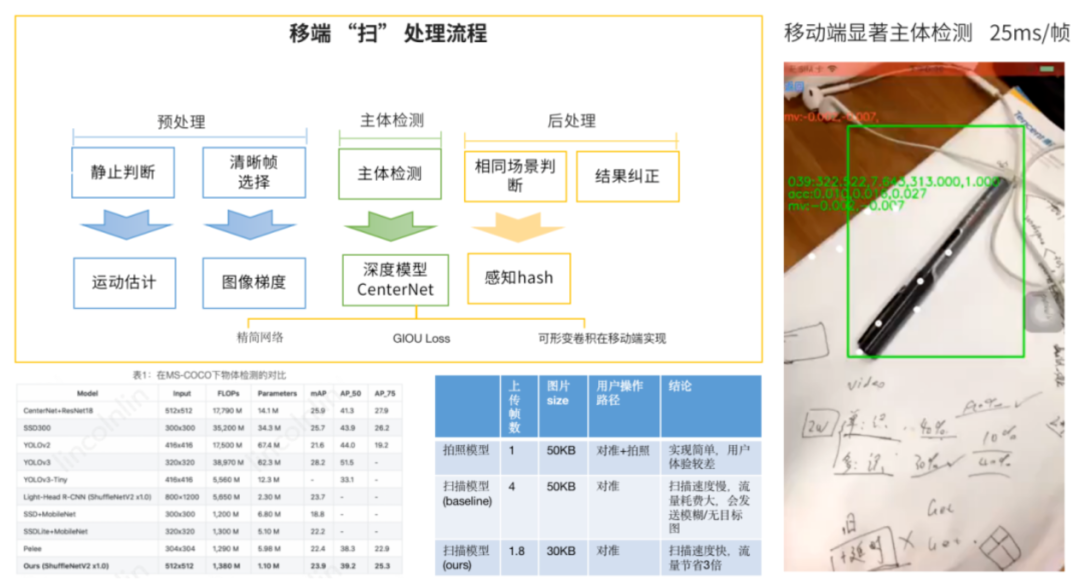
我们基于 centernet 的方法,并基于移动端的场景进行专项优化,如大感受野、轻检测头、改进可形变卷积在移动端的实现等。最终我们的方法与主流方法在 ms-coco 上对比,在 MAP 相当的情况下,参数量只有 1M,大大降低。在 iphone 下测试,每帧只需 25ms.。从上图可以看出,扫描模型改进版,有效提高了扫描速度,节省 3 倍流量。
检测篇 | 服务端物品检测
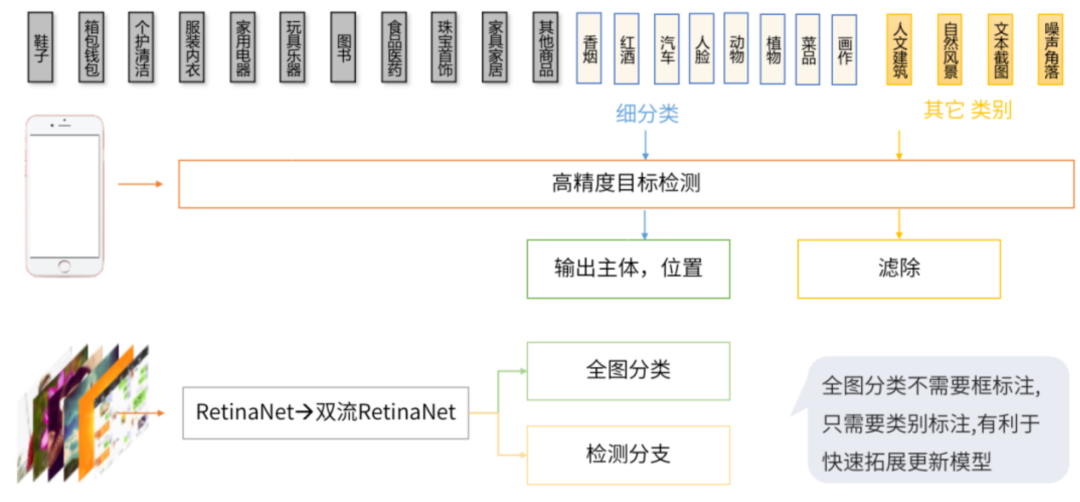
检测篇 | 目标检测的应用

目标检测算法对于 Query 理解,去除背景干扰,理解多主体,还有压缩源数据的基础算法能力。

以图搜图本质上是寻找度量图像之间距离的方法,这个距离的表示有很多维度。

关于 CNN 特征学习的探索,在《微信扫一扫识物技术的从 0 到 1》一文中已有全面的论述。我们的另一块核心工作,是解决大规模数据下带来的挑战。
检索篇 | 大规模检索系统之分库实现

检索篇 | 识物引擎系统框架
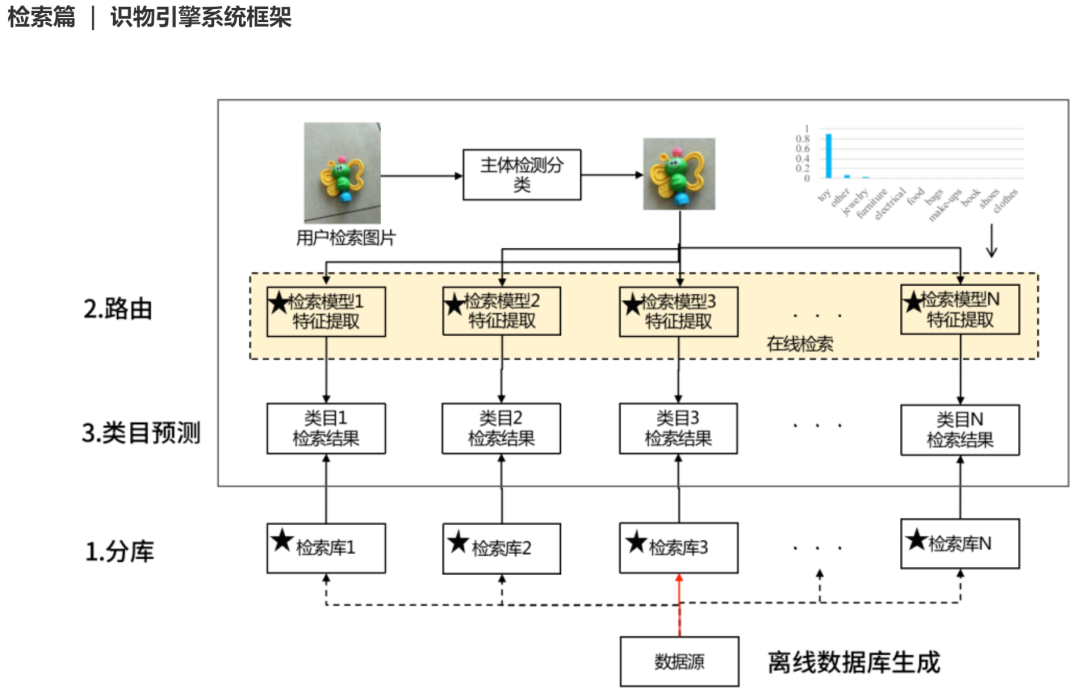
检索篇 | 识物引擎之分库路由
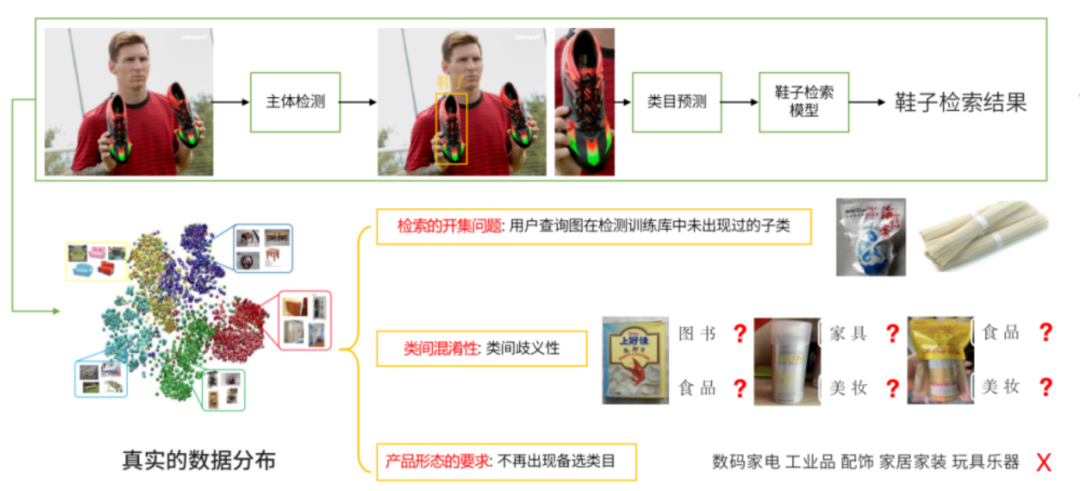
前面提到服务端的检测是带有类别的,比如图中输出鞋子,那么我们就走鞋子的专用检索模型提取特征,再到鞋子库中检索。这是最朴素的版本。然而现实场景中的真实的数据分布往往是离散,且存在较大交叉边界的,这会导致以下问题。
检索的开集问题,比如未出现过的子类容易分错;
类间混淆性,从视觉上存在歧义。
检索篇 | 识物引擎之类目预测
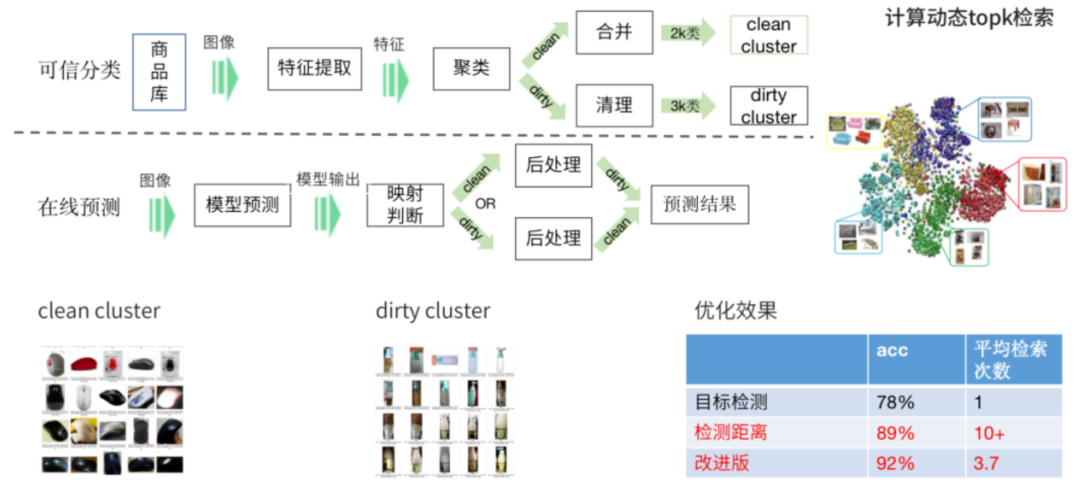
3.类目预测:由于每个库都是专有模型,特征之间是可以度量的。于是我们引入了一个精排模型,可以度量所有商品图片的距离,统一对多库召回的结果作归一化。最后我们会结合 query 图的分类检测结果,召回结果的图像精排特征,以及相关的结果图像及结果一致性,通过一个 MLP 网络进行类目预测,同款归纳等后处理。
检索篇 | 通用以图搜图之无监督的分库
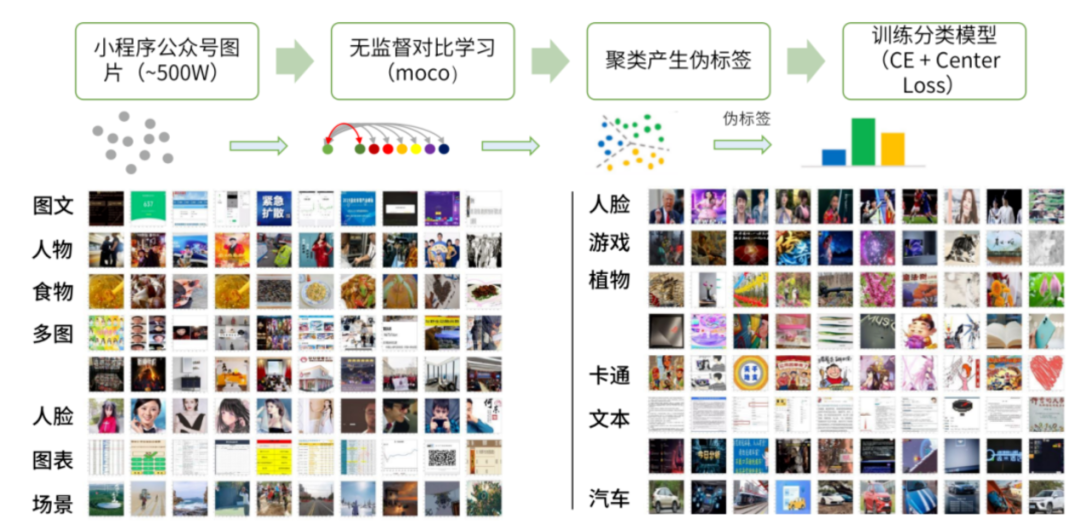
1.分库:基于 moco 这种无监督的对比学习方法,得到图片一个向量表示。再通过聚类的方法产生伪标签,如下面的 16 个标签。可以看出,相同 topic 的图片,会被尽量分到同一个库中。
检索篇 | 图搜流程框架
2.路由:在离线流程中,我们把所有的图片通过上述的分库方法,分成了 16 个库。在线检索的时候,路由层会预测 query 图的标签,只走 top3 的分库。最后通过一个统一多库精排模型,把召回结果融合到一起。
结语
从识物到识图,我们不断扩大计算机视觉所能感知的范围。从技术上我们日趋完善,逐渐搭建起从数据采集->半自动化清洗->训练->上线->反馈优化的 pipeline,从基础的分类检测到各类应用层的算法,从移动端部署到大规模 GPU 集群。另一方面,基于微信的图片应用场景,我们开拓出了微信识物、长按识图等新的尝试入口。相信紧贴用户场景,通过技术的不断沉淀积累,一定可以孕育出更多的智能产品。