揭秘腾讯会议背后的视频编码“神器”
作为一款实时音视频通信产品,腾讯会议里面有海量的音视频数据需要进行实时传输,比如我们的摄像头画面,屏幕分享的数据等。这些数据量非常庞大,通常需要经过编码压缩再进行传输,那么腾讯会议里有哪些视频编码方面的”神器”呢?本文将一一为大家揭晓。
一、时域SVC
在视频编码中,有三种帧类型:
- I帧:只能进行帧内预测,可以独立解码;
- P帧:单假设参考帧,也就是通常说的前向预测帧,只能使用它之前的帧进行预测;
- B帧:双假设参考帧, 一般为双向预测帧。
由于B帧会带来不可避免的延迟,因此在实时通信中通常只使用I帧和P帧这两种帧类型。
I帧只使用了本帧的信息进行预测,也就是说I帧的解码不依赖于其他帧,因此可以独立解码,但I帧的编码效率偏低,数据量较大。
P帧使用了帧间预测方法,可以参考之前的一些解码帧信息,能达到较高的压缩效率(帧大小比I帧小很多),但是解码时必须依赖于其他帧。
在实际的应用场景中,为了提升压缩效率,往往会使用IPPP的帧结构,即I帧之后编码N个P帧。但当网络情况不好时(如抖动,丢包,限速等),这种帧结构就会造成长时间的卡顿。
如下图所示,第0帧为I帧,后续7个帧均为P帧,且每个P帧只有一个参考帧(为其前一帧)。当网络发生丢包时,第3帧丢失,由于第4帧参考第3帧进行压缩,因此不能正确解码,5~7帧则类似。
这种情况下,即使丢包只造成个别帧的丢失,但由于接收端很多帧不能正确解码,会造成长时间的卡顿,只能通过申请I帧的机制进行恢复。
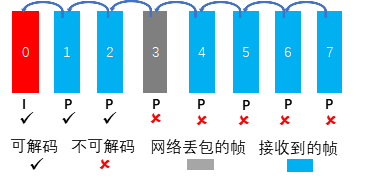
IPPP帧结构参考关系
为了解决这一问题,我们加入了时域SVC技术,对参考帧结构进行了调整。
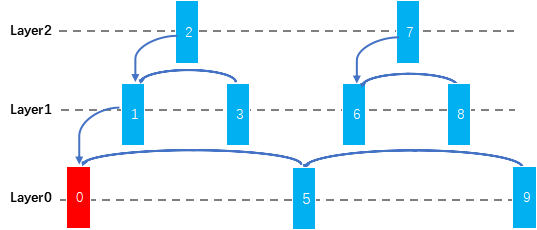
时域SVC帧结构参考关系
我们可以将视频帧分为若干层,上图以3层为例:
- Layer0的帧只能参考同样为Layer0的帧,不能参考Layer1和Layer2的帧;
- Layer1的帧可以参考Layer0和Layer1的帧,不能参考Layer2的帧;
- Layer2的帧可以参考Layer0~2的帧。
越低层级的帧被参考的可能性越大,因此重要性也越大。在网络发生丢包时,只要所丢的帧不是Layer0层,就不需要重新申请I帧,解码端就可以持续成功解码。如上图中第1帧丢失仅会影响2,3帧,其他帧不会受到影响。 此外还可以结合网络层的策略,对低层级的帧多加一些保护(如FEC),降低其丢失的概率,能有效地解决卡死的问题。在参会的下行人数很多时,可能会有小部分下行网络较差,如果采用传统的IPPP结构,则当某个下行损伤时就需要不断的申请I帧来恢复,这样就会影响到其他接收端的视频体验;如果采用时域SVC的结构,在能够保证少数的下行网络存在问题时,其他的下行端不会受到影响。
ROI检测以及基于ROI的编码
摄像头内容是腾讯会议中的一个主要视频场景。在此场景中,人眼往往比较关注人脸区域,对背景区域的关注度较低。因此,我们加入了人脸检测算法和基于感兴趣区域(Region of Interest, 简称ROI)的编码算法。
这类算法的主要思路是:实时地检测出当前视频中的ROI区域,将其传入到编码器内部,编码器进行单帧的码率重分配。对ROI区域,增大其码率,能使该区域编码的更好,提升主观质量;对于非ROI区域,降低其码率,则总的码率不会超出目标码率。
在ROI检测方面,因为腾讯会议是一个实时性要求很高的场景,对算法复杂度很敏感,我们使用一些传统的算法,结合编码器的一些预分析结果,确定最终的ROI-map,对于1080p的视频,单帧检测耗时在0.3ms以内,完全满足了实时性的要求。
基于ROI的检测和码率调整算法的优点在于:在低码率的情况下,能极大地提升主观质量;在高码率的场景下,可以保持主观质量基本不变,码率节省20%~30%,以下是一些对比效果:
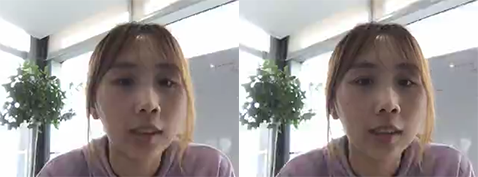
低码率效果对比 (左)关闭ROI (右)开启ROI
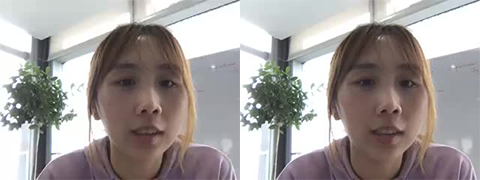
高码率效果对比 (左) 300kbps, 关闭ROI (右) 210kbps, 开启ROI
屏幕内容编码技术
屏幕分享/白板等屏幕类内容是腾讯会议中另一类视频场景。屏幕生成的视频与摄像头采集的视频存在很大的不同:屏幕视频通常没有噪声,色调离散,线条细腻,边缘锐利;相反的,摄像机拍摄的视频通常存在噪声,色调连续且丰富,纹理比较复杂。
传统的H.264和H.265编码器采用的是基于块的混合编码框架,包含预测,变换,量化以及熵编码。其中变换模块主要的目的是将残差信号从空域变换到频域,使信号能量更集中,也方便基于不同的频率分量做不同的处理,减小编码所需的比特数。
但是,对屏幕分享的内容,采用基于变换的编码方法,会损失其高频细节,导致用户观看的视频变得不清晰。
基于上述原因,我们在H.265编码器中加入了一些有效的屏幕内容编码技术(Screen Content Coding,简称SCC),包括帧内块拷贝和调色板编码。
我们在前面的介绍中也提到过,一般情况下I帧编码效率要比P帧差,主要原因是P帧可以利用时域上的信息进行预测,预测精确度往往很高,这样编码的信息量就变少了。
如下图所示,第N帧与第N-1帧之间只有很少量的运动,所以用第N-1帧的信息来预测第N帧相对来说会很准确。

帧间预测示例图
所谓的帧内块拷贝,是指借鉴了帧间预测的方法,在I帧中引入基于运动矢量(Motion Vector, 简称MV)的预测,提升其预测精确度,极大地提升了I帧的压缩效率。
该方法之所以在屏幕类场景效果显著,是由于屏幕序列相比于摄像头采集序列有很多重复性的图案,用这个方法效果更好。
屏幕序列重复图案示例
在屏幕内容中,像素点的选择通常集中在某一些色彩上,所以我们引入了调色板模式。该模式彻底抛弃了传统的变换编码的方法,直接依据像素点的“颜色值”生成调色板。 对每个像素点,传输其在调色板中的“索引”(“index”)即可。该算法可以达到很高的编码效率提升,同时这种方法由于不使用变换,且大多数的点可以在颜色表中找到对应的项,主观质量也有明显的提升。
YUV444编码
在视频编码中,基本的数据格式为YUV,根据采样格式的不同可以分为YUV444, YUV422以及YUV420,这三种格式的区别见下图(O表示Y分量,X表示U/V分量):

YUV采样格式 (左)YUV444 (中)YUV422 (右)YUV420
YUV444采样格式中Y、U、V 三个分量的比例相同,每个像素的三个分量信息完整,都是一个字节。YUV422采样格式中Y 分量和 UV 分量则按照 2 : 1 的比例采样。如图所示,水平方向有4个像素点,那么就采样4个Y分量,2个UV 分量。
YUV420采样格式中,每一行扫描时只扫描一种色度分量(U 或者 V)且该色度分量与Y分量按照 2 : 1 的方式采样。如图所示,为了直观的理解,我们认为4个Y分量对应1个UV分量,因此将X放在了四个O中间。
一般来说,大多数的视频类应用都采样YUV420的格式进行编码,一方面这种格式数据量较少,另一方面色度分量的重要程度明显低于亮度分量,对色度降采样后人眼主观感受降低不明显。
然而,在屏幕分享场景中,相比于摄像头采集序列,U/V分量信息更丰富,下采样会严重的丢失这部分信息,且在后续的后处理等环节无法补回,所以我们加入了YUV444编码的支持。
大家可以看下下面这两张图,我们人为生成了一张U/V分量信息很丰富的图片,在发送端可以看到是有色彩的,但是经过YUV420采集编码传输后,到接收端看到的却是一幅灰度图像,失真非常严重。

测试图片
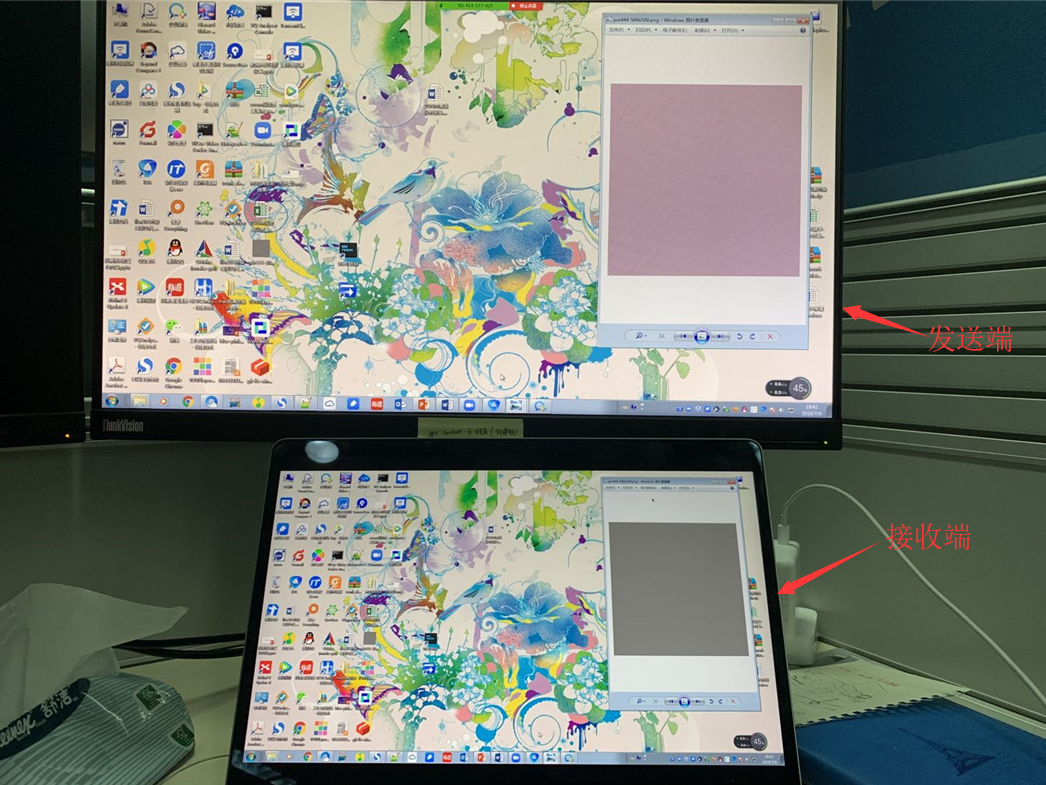
YUV420传输效果(U/V分量严重失真)
在屏幕分享场景下,有些时候可能会对色彩的保真度/还原度要求较高,如一些设计图像等,那么加入YUV444的支持就是为了在这些场景下达到不错的用户体验。下面是我们实际测试到的YUV420/YUV444编码下的对比图:

原图

YUV420编码图像

YUV444编码图像
五、业界领先的编码器
我们对H.264和H.265编码器进行了深度优化,一方面加入了很多快速算法,提升其编码速度;另一方面加入了一些新的编码工具集,提升其压缩效率。
与业界最著名的x264开源编码器相比,我们的H.264编码器针对屏幕分享内容做了大量的优化,达到了40%以上压缩效率的提升,编码速度仅损失11%左右。
我们的H.265编码器无论在屏幕分享场景还是摄像头场景,都远远优于开源的x265编码器。与x265相比,在屏幕分享场景下,压缩效率提升多达83.7%,速度提升210%;在摄像头场景下,压缩效率提升24.7%的同时速度可以提升140%左右。
结语
本文较为详细的介绍了一些腾讯会议中的视频编码“神器”,为了不断地提升产品体验,我们会根据不同的场景持续优化我们的编码器,增加适合的编码技术,欢迎大家咨询体验!