RocketMQ中台化建设
一、RocketMQ简介
RocketMQ是一个高可用、高性能、高可靠的分布式消息队列,相对于kafka更适合处理业务系统之间的消息。
-
它具有很多特性,例如:
-
发布订阅
-
顺序、事务、定时消息
-
消息堆积、重试,回溯等等
-
它通过同步刷盘和同步双写等技术手段来实现高可靠,保证如下情况消息不丢:
-
可恢复性故障:broker或OS crash等
-
不可恢复性故障:磁盘损坏等
-
它采用多项技术优化来满足性能要求:
-
顺序IO
-
PageCache和mmap
-
内存预热和锁定
-
异步提交和刷盘
-
堆外内存缓冲等等
所以,它的本质决定的其架构一定是复杂的,参考RocketMQ官方架构图:
这里不再介绍各个组件的含义,可以参考RocketMQ架构设计。
RocketMQ经过阿里多年双十一的检验,其稳定性不言而喻。
可作为搜狐视频的消息中台,还需要很长一段路要走,为什么这么说呢?
二、运维之痛
早在2014年我们就引入了RocketMQ作为消息中间件,其附带了基本的命令行工具。
但是命令行运维此等庞然大物会让人感到力不从心,好在社区提供了一个web控制台:RocketMQ-Console。
在初期,简单的控制台已经能满足基本的需求。但是随着各个业务逐渐接入,需求也纷至沓来。
我们在RocketMQ-Console的修修补补已经无法满足了,主要体现在如下几点:
-
从业务方的角度:
-
偏重运维,一般业务用户不关心集群的数据和状态,无法聚焦。
-
使用起来繁琐,且直接操作集群,易误操作。
-
没有监控预警功能。
-
无法满足业务用户的需求,包括但不限于:
-
序列化
-
trace
-
流控,隔离降级
-
埋点统计监控等等
-
一些隐性问题无法解决。
-
从管理员维度:
-
无用户概念,任何人都能直接操作集群,易误操作且比较危险。
-
无集群管理功能,日常更新或机器替换需要手动部署,非常耗时、麻烦且易出错。
-
无相关数据统计,监控,预警等,往往有问题不能及时发现。
另外,RocketMQ有一些潜在约定、使用规范、最佳实践、bug或优化等等,用文档说明也无济于事。
所以与其写文档不如将经验和实践转换为产品,能够更好的服务于业务及运维集群,于是MQCloud应运而生。
三、MQCloud诞生
先看一下MQCloud的定位:
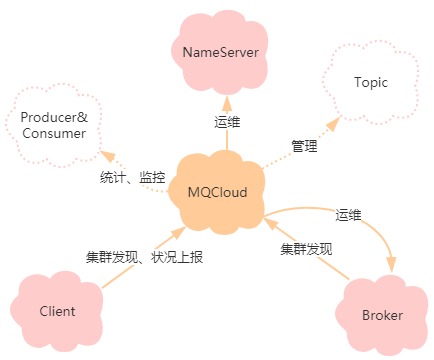
它是集客户端SDK,监控预警,集群运维于一体的一站式服务平台。
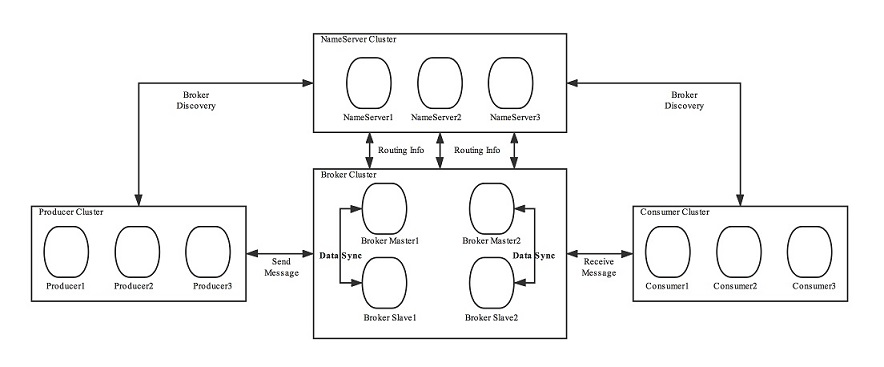
MQCloud的系统架构如下:
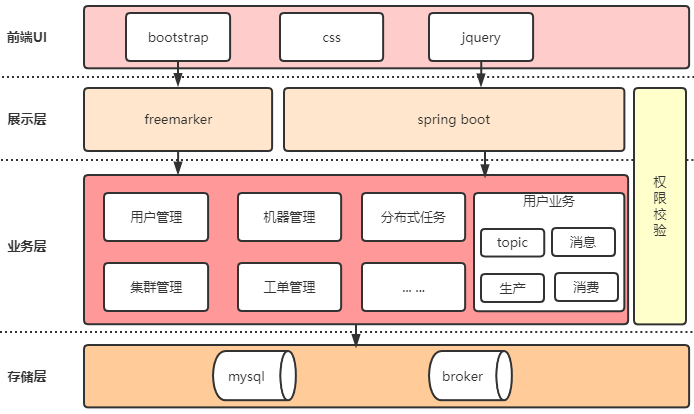
下面来分别说明一下MQCloud如何解决上面提到的痛点。
业务端和运维端分离,使业务用户只聚焦于业务数据。
为了实现这个目的,引入了用户,资源两大维度。
针对用户和资源加以控制,使不同的用户只聚焦于自己的数据。
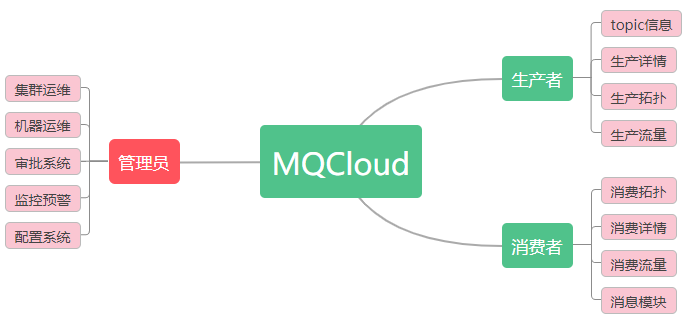
- 对于生产者来说,他关心的是topic配置,消息的发送数据,谁在消费等等问题,这样只对他展示相应的数据即可;
- 对于消费者来说,只关心消费状况,有没有堆积,消费失败等情况;
- 对于管理员来说,可以进行部署,监控,统一配置,审批等日常运维;
清晰明了的操作 通过对不同角色展示不同的视图,使用户可以进行的操作一目了然。
规范和安全 为了保障集群操作的安全性和规范性,所有的操作都会以申请单的形式进入后台审批系统,管理员来进行相关审批,安全性大大提升。
多维的数据统计和监控预警 MQCloud核心功能之一就是监控,要想做监控,必须先做统计,为了更好的知道RocketMQ集群的运行状况,MQCloud做了大量的统计工作,主要包括如下几项:
- 每分钟topic的生产流量:用于绘制topic生产流量图及监控预警。
- 每分钟消费者流量:用于绘制消费流量图及监控预警。
- 每10分钟topic生产流量:用于按照流量展示topic排序。
- 每分钟broker生产、消费流量:用于绘制broker生产消费流量图。
- 每分钟broker集群生产、消费流量:用于绘制broker集群的生产流量图。
- 每分钟生产者百分位耗时、异常统计:以ip维度绘制每个生产者的耗时流量图及监控预警。
- 机器的cpu,内存,io,网络流量,网络连接等统计:用于服务器的状况图和监控预警。
下面来分别介绍每项统计是如何收集的: 每分钟topic的生产流量 此数据来自于RocketMQ broker端BrokerStatsManager,其提供了统计功能,统计项如下:
- TOPIC_PUT_NUMS:某topic消息生产条数,向某个topic写入消息成功才算
写入成功包括四种状态:PUT_OK,FLUSH_DISK_TIMEOUT,FLUSH_SLAVE_TIMEOUT,SLAVE_NOT_AVAILABLE 2. TOPIC_PUT_SIZE:某topic消息生产大小,向某个topic写入消息成功才算
RocketMQ实现的统计逻辑较为精巧,这里做简单描述,首先介绍几个对象:
- StatsItemSet主要字段及方法如下:
ConcurrentMap<String/* statsKey */, StatsItem> statsItemTable; // statsKey<->StatsItem
// 针对某个数据项进行记录
public void addValue(final String statsKey, final int incValue, final int incTimes) {
StatsItem statsItem = this.getAndCreateStatsItem(statsKey);
statsItem.getValue().addAndGet(incValue);
statsItem.getTimes().addAndGet(incTimes);
}
// 获取并创建StatsItem
public StatsItem getAndCreateStatsItem(final String statsKey) {
StatsItem statsItem = this.statsItemTable.get(statsKey);
if (null == statsItem) {
statsItem = new StatsItem(this.statsName, statsKey);
this.statsItemTable.put(statsKey, statsItem);
}
return statsItem;
}- StatsItem主要字段及方法如下:
AtomicLong value; // 统计数据:比如消息条数,消息大小
AtomicLong times; // 次数
LinkedList<CallSnapshot> csListMinute; // 每分钟快照数据
LinkedList<CallSnapshot> csListHour; // 每小时快照数据
LinkedList<CallSnapshot> csListDay; // 每天快照数据
// 分钟采样
public void samplingInSeconds() {
synchronized (csListMinute) {
csListMinute.add(new CallSnapshot(System.currentTimeMillis(), times.get(), value.get()));
if (csListMinute.size() > 7) {
csListMinute.removeFirst();
}
}
}
// 小时采样
public void samplingInMinutes() {
// ...代码省略
}
// 天采样
public void samplingInHour() {
// ...代码省略
}- CallSnapshot主要字段如下:
long times; // 次数快照
long value; // 统计数据快照
long timestamp; //快照时间戳上面三个对象如何配合进行数据统计呢?举个例子,比如统计topic名字为test_topic的消息生产大小:
只要进行类似如下调用即可:
StatsItemSet.addValue("test_topic", 123125123, 1)即表示发送了1次消息到test_topic,消息大小为123125123。
那如何进行数据采样呢?StatsItemSet内置了定时任务,比如其每10秒调用一次StatsItem.samplingInSeconds()。这样StatsItem就会持有60秒的数据,类似如下结构:
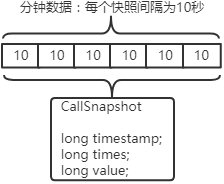
那么,最后一个10秒的快照 - 第一个10秒的快照 = 当前60秒的数据,根据时间戳差值可以得到耗时。
类似,小时数据每10分钟进行一次快照,类似如下结构:
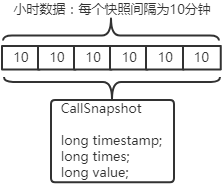
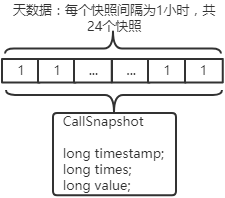
天数据每1小时进行一次快照,类似如下结构:
每分钟消费者流量 与每分钟topic的生产流量一样,也采用RocketMQ统计好的数据。
每10分钟topic生产流量
采用数据库已经统计好的每分钟topic流量进行累加,统计出10分钟流量。
每分钟broker生产、消费流量
由于统计1.每分钟topic的生产流量和2.每分钟消费者流量时是跟broker交互获取的,所以知道broker ip,故直接按照broker维度存储一份数据即可。
每分钟broker集群生产、消费流量
采用4.每分钟broker生产、消费流量数据,按照集群求和即可。
每分钟生产者百分位耗时、异常统计
由于RocketMQ并没有提供生产者的流量统计(只提供了topic,但是并不知道每个生产者的情况),所以MQCloud实现了对生产者数据进行统计(通过RocketMQ的回调钩子实现):
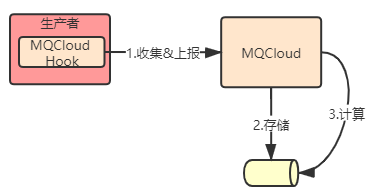
- 客户端ip->broker ip
- 发送消息耗时
- 消息数量
- 发送异常
统计完成后,定时发送到MQCloud进行存储,并做实时监控和展示。
关于统计部分有一点说明,一般耗时统计有最大,最小和平均值,而通常99%(即99%的请求耗时都低于此数值)的请求的耗时情况才能反映真实响应情况。99%请求耗时统计最大的问题是如何控制内存占用,因为需要对某段时间内所有的耗时做排序后才能统计出这段时间的99%的耗时状况。而对于流式数据做这样的统计是有一些算法和数据结构的,例如t-digest,但是MQCloud采用了非精确的但是较为简单的分段统计的方法,具体如下:
1.创建一个按照最大耗时预哈希的时间跨度不同的耗时分段数组:
优点:此种分段方法占用内存是固定的,比如最大耗时如果为3500ms,那么只需要空间大小为96的数组即可
缺点:分段精度需要提前设定好,且不可更改 A.第一段:耗时范围0ms~10ms,时间跨度为1ms。
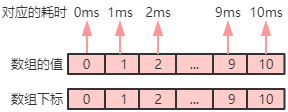


优点:此种分段方法占用内存是固定的,比如最大耗时如果为3500ms,那么只需要空间大小为96的数组即可
缺点:分段精度需要提前设定好,且不可更
2.针对上面的分段数组,创建一个大小对应的AtomicLong的计数数组,支持并发统计:

这样,从计数数组就可以得到实时耗时统计,类似如下:
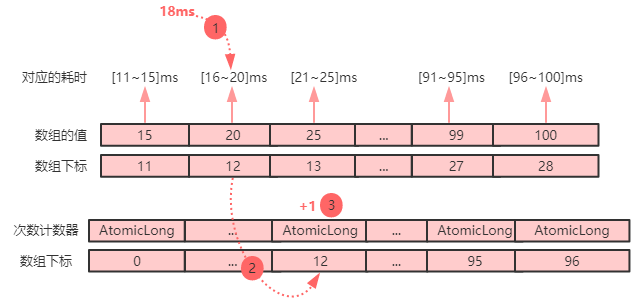
这样,从计数数组就可以得到实时耗时统计,类似如下:
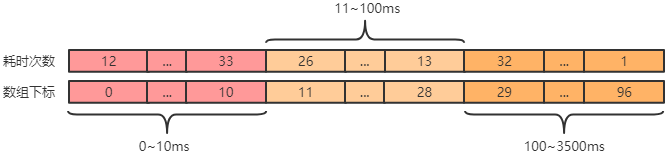
4.然后定时采样任务会每分钟对计数数组进行快照,产生如下耗时数据:

*另外提一点,由于RocketMQ 4.4.0新增的trace功能也使用hook来实现,与MQCloud的统计有冲突,MQCloud已经做了兼容。
*Trace和统计是两种维度,trace反映的是消息从生产->存储->消费的流程,而MQCloud做的是针对生产者状况的统计,有了这些统计数据,才可以做到生产耗时情况展示,生产异常情况预警等功能。
机器统计
关于集群状况收集主要采用了将nmon自动放置到/tmp目录,定时采用ssh连接到机器执行nmon命令,解析返回的数据,然后进行存储。
上面这些工作就为监控和预警奠定了坚实的数据基础。
单独定制的客户端
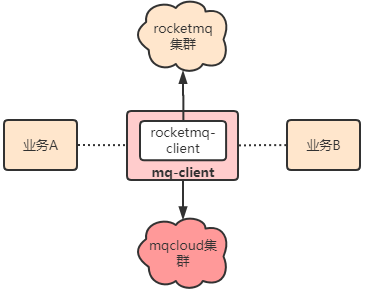
针对客户端的一些需求,mq-client在rocketmq-client的基础上进行了开发定制:
- 多集群支持
MQCloud储存了生产者、消费者和集群的关系,通过路由适配,客户端可以自动路由到目标集群上,使客户端对多集群透明。 2. trace
通过搭建单独的trace集群和定制客户端,使trace数据能够发往独立的集群,防止影响主集群。 3. 序列化
通过集成不同的序列化机制,配合MQCloud,客户端无需关心序列化问题。
目前支持的序列化为protobuf和json,并且通过类型检测支持在线修改序列化方式。 4. 流控
通过提供令牌桶和漏桶限流机制,自动开启流控机制,防止消息洪峰冲垮业务端。 5. 隔离降级
使用hystrix提供隔离降级策略,使业务端在broker故障时可以避免拖累。 6. 埋点监控
通过对客户端数据进行统计,收集,在MQCloud里进行监控,使客户端任何风吹草动都能及时得知。 7. 规范问题
通过编码保障,使某些约定,规范和最佳实践得以实现。包括但不限于:
- 命名规范
- 消费组全局唯一,防止重复导致消费问题
- 重试消息跳过
- 安全关闭等等
- 更完善的重试机制
自动化运维
- 部署
手动部署一台broker实例没什么问题,但是当实例变多时,手动部署极易出错且耗时耗力。
MQCloud提供了一套自动化部署机制,并支持配置模板功能,支持一键部署。 2. 机器运维
MQCloud提供了一整套机器的运维机制,包括上下线,机器状况收集、监控、预警等等,大大提升了生产力。
安全性加固
一、开启管理员权限
RocketMQ从4.4.0开始支持ACL,但是默认没有开启,也就是任何人使用管理工具或API就可以直接操纵线上集群。但是开启ACL对现有业务影响太大,针对这种情况MQCloud进行专门定制。
借鉴RocketMQ ACL机制,只针对RocketMQ管理员操作加固权限校验:
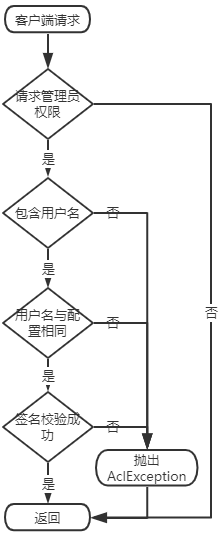
并且支持自定义和热加载管理员请求码,使得非法操作RocketMQ集群成为不可能,安全性大大提升。
二、broker通信加固
broker同步数据代码由于没有校验,存在安全隐患,只要连接master监听的slave通信端口,发送数据大于8个字节,就可能导致同步偏移量错误,代码如下:
if ((this.byteBufferRead.position() - this.processPostion) >= 8) {
int pos = this.byteBufferRead.position() - (this.byteBufferRead.position() % 8);
long readOffset = this.byteBufferRead.getLong(pos - 8);
this.processPostion = pos;
HAConnection.this.slaveAckOffset = readOffset;
if (HAConnection.this.slaveRequestOffset < 0) {
HAConnection.this.slaveRequestOffset = readOffset;
log.info("slave[" + HAConnection.this.clientAddr + "] request offset " + readOffset);
}
HAConnection.this.haService.notifyTransferSome(HAConnection.this.slaveAckOffset);
}MQCloud通过验证数据首包的策略,保障了通信的安全性。
目前MQCloud运维规模如下:
- 服务器:50台+
- 集群:5个+
- topic:700个+
- 生产消费消息量/日:4亿条+
- 生产消费消息大小/日:400G+
MQCloud在充分考虑和吸收实际业务的需求后,以各个角色聚焦为核心,以全面监控为目标,
以满足各业务端需求为己任,在不断地发展和完善。
在MQCloud逐渐成熟之后,秉承着服务于社区和吸收更多经验的理念,我们开放了源代码。
四、开源之路
开放源代码说不难也不难,说难也难。为什么这么说?
不难就是因为代码已经有了,只是换个仓库而已。
而难点就是需要进行抽象设计,剥离不能开源的代码(内部模块,代码,地址等等)。
经过设计和拆分,MQCloud于18年开源了,从第一个版本release到现在已经过去两年了,
期间随着更新迭代大大小小一共release了20多个版本。
其中不但包含功能更新、bug修复、wiki说明等,而且每个大版本都经过详细的测试和内部的运行。
之后很多小伙伴跃跃欲试,来试用它,并提出一些建议和意见,我们根据反馈来进一步完善它。
我们将一直遵循我们的目标,坚定的走自己的开源之路:
- 为业务提供可监控,可预警,可满足其各种需求的稳定的MQ服务。
- 积累MQ领域经验,将经验转化为产品,更好的服务业务。