0828-7.1.4-如何在CDP中通过Livy Thrift Server来提交Spark SQL作业
1.文档编写目的
为什么CDH甚至最新的CDP中对于Spark SQL CLI或者JDBC/ODBC没有提供基于Spark Thrift Server的支持,参考Fayson之前的文章《0827-7.1.4-如何在CDP中使用Spark SQL CLI》,在CDP中,Cloudera给出了新的解决方案Livy Thrift Server,它是对Spark Thrift Server的增强,支持JDBC/Thrift Server,安全与容错。通过Hive Warehouse Connector(HWC),支持Spark SQL访问Hive3的内表,同时然Spark SQL支持基于Ranger的细粒度授权。本文主要介绍如何在CDP中通过Livy Thrift Server来提交Spark SQL作业。
- 测试环境:
1.Redhat7.7
2.采用root用户操作
3.CM为7.1.4,CDP为7.1.4
2.操作步骤
2.1 安装并启用Livy服务
1.从CM界面点击添加服务,选择Livy服务进行添加
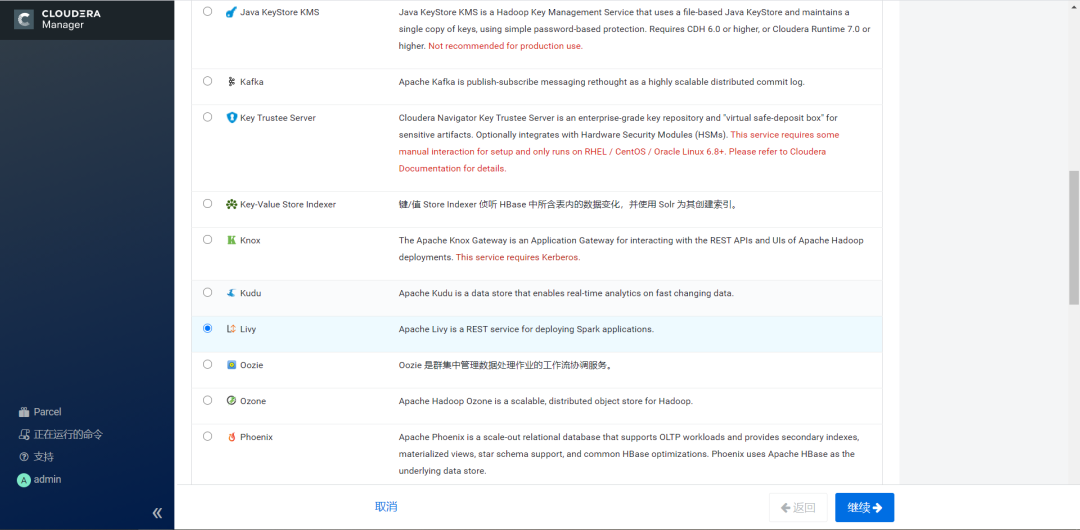
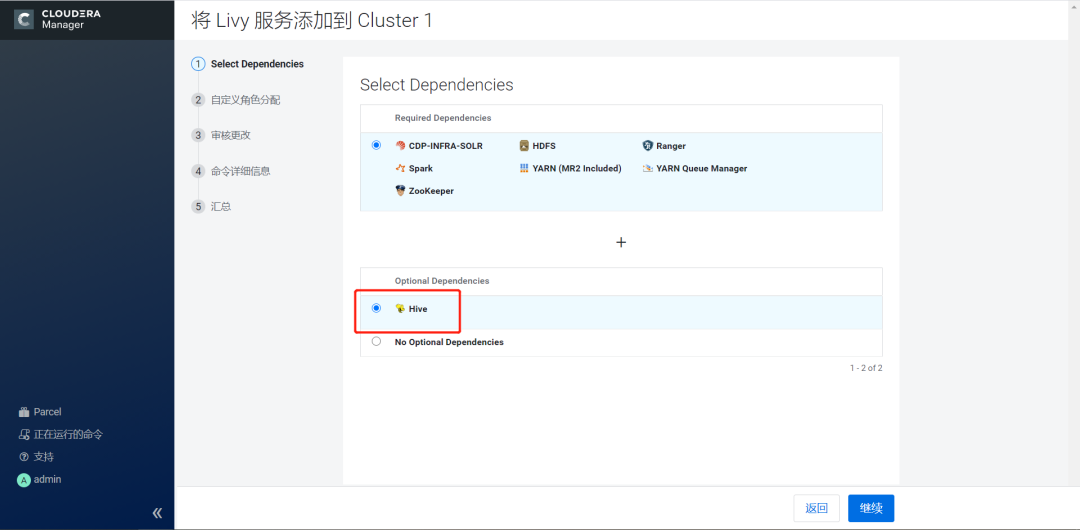
2.点击继续,选择需要依赖的组件
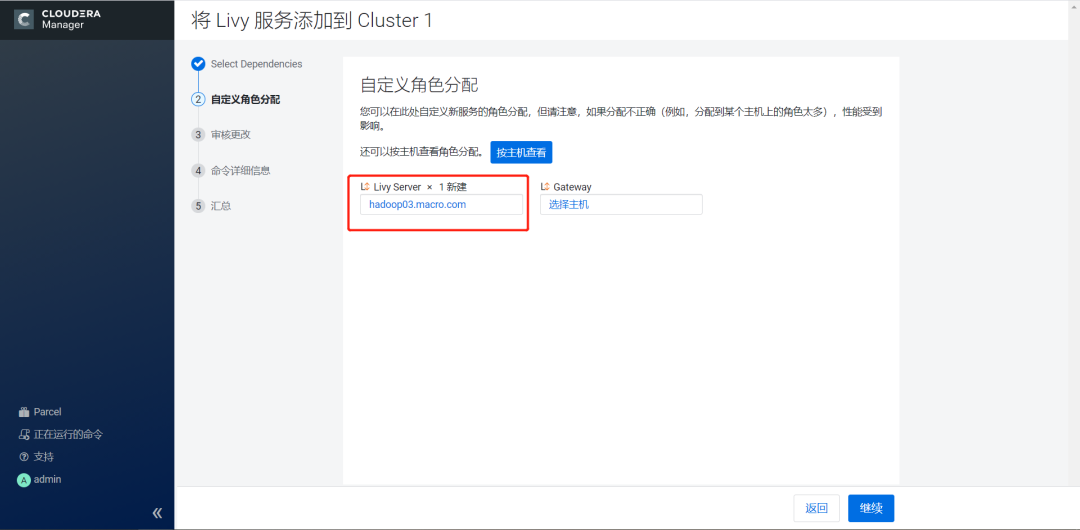
3.点击继续,选择Livy Server部署的节点
4.点击继续,等待服务添加
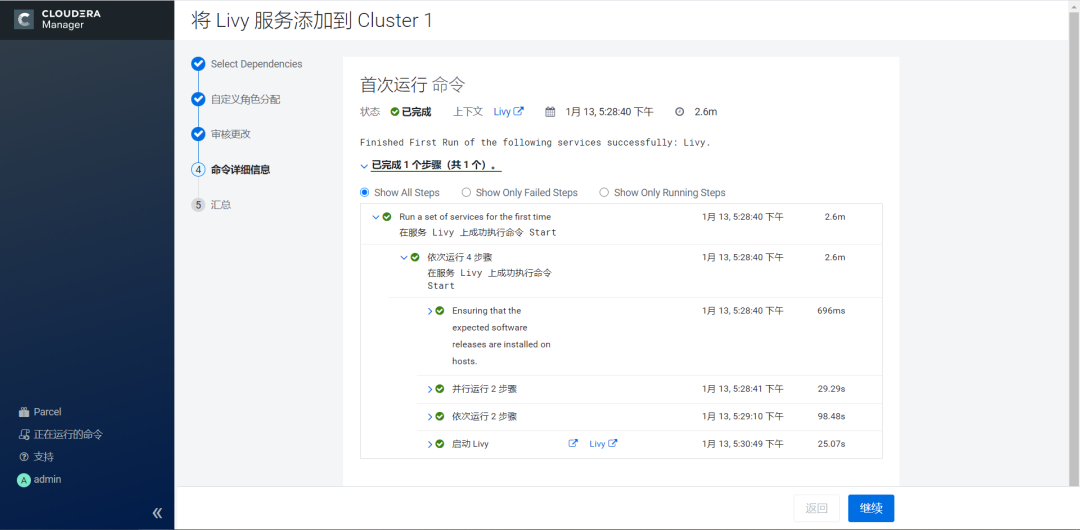
5.点击继续,安装完成
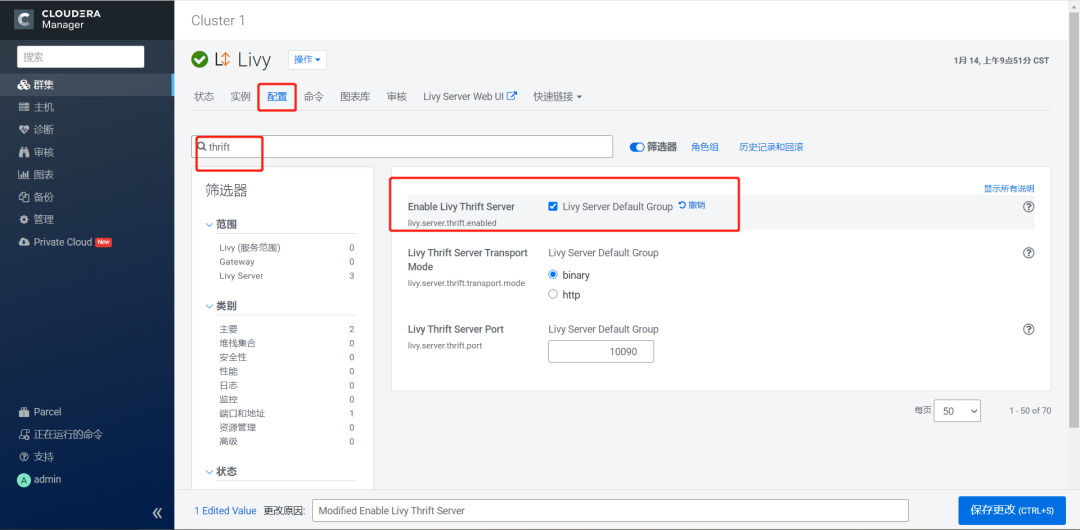
6.从CM进入Livy服务,在配置中搜索thrift,勾选Enable Livy Thrift Server选项。
2.2 修改Spark配置
1.在Spark组件的配置页面,搜索spark-conf/spark-defaults.conf 的 Spark 客户端高级配置代码段(安全阀),添加下面的参数然后保存修改。
spark.sql.extensions=com.qubole.spark.hiveacid.HiveAcidAutoConvertExtension
spark.kryo.registrator=com.qubole.spark.hiveacid.util.HiveAcidKyroRegistrator
#spark.hadoop.hive.metastore.uris=thrift://hadoop01.macro.com:9083
spark.datasource.hive.warehouse.read.jdbc.mode=client
spark.sql.hive.hiveserver2.jdbc.url=jdbc:hive2://hadoop01.macro.com:2181,hadoop02.macro.com:2181,hadoop03.macro.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
spark.sql.hive.hiveserver2.jdbc.url.principal=hive/_HOST@MACRO.COM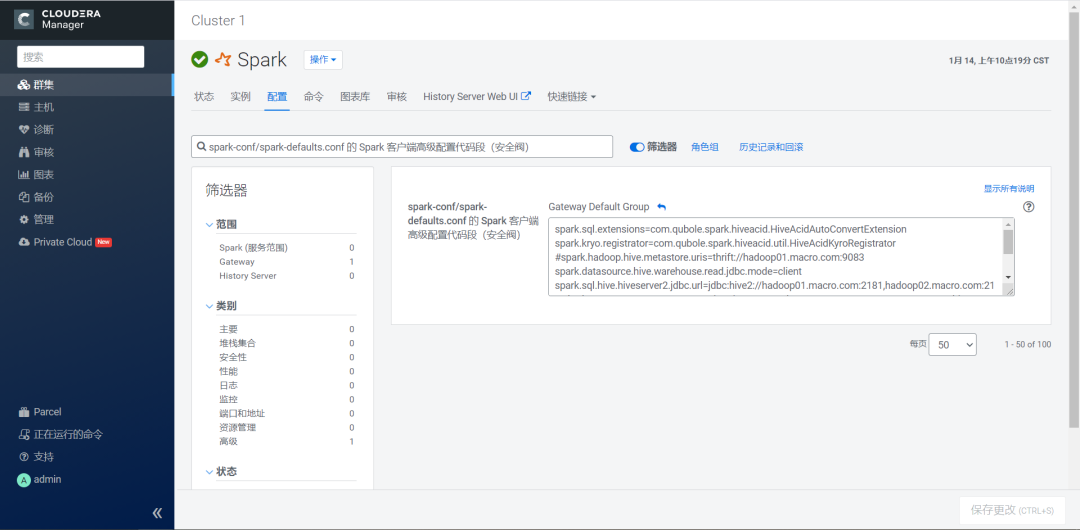
2.在Spark组件的配置页面,搜索spark-conf/spark-env.sh 的 Spark 客户端高级配置代码段(安全阀),添加下面的参数然后保存修改。
SPARK_DIST_CLASSPATH=$SPARK_DIST_CLASSPATH:/opt/cloudera/parcels/CDH/lib/hive_warehouse_connector/hive-warehouse-connector-assembly-1.0.0.7.1.3.0-100.jar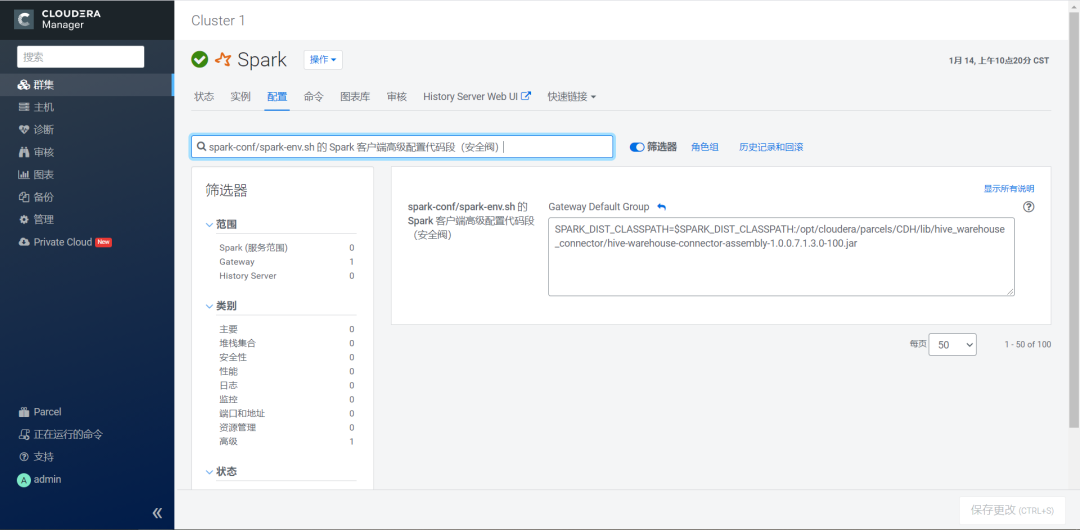
3.全部修改完后,回到主页,根据提示进行重启相关服务。
2.3 测试使用
1.通过beeline客户端进行连接
beeline -u "jdbc:hive2://hadoop03.macro.com:10090/;principal=livy/hadoop03.macro.com@MACRO.COM"
2.提交SQL进行测试
show tables;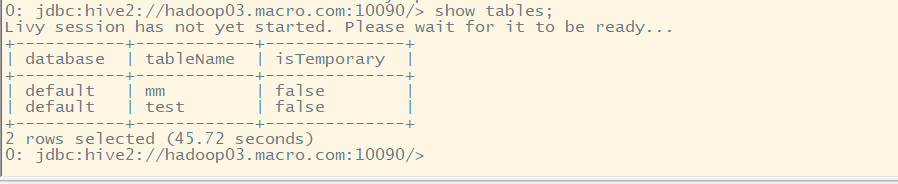
select * from test;
3.总结
1.在Livy中, Thrift Server默认是禁用的,可以使用Cloudera Manager来启用Thrift Server。
2.Livy通过HWC connector来进行管理表的访问。需要配置好相关环境和hwc的jar包。