一文搞懂 | Linux 同步管理(上)
因为现代操作系统是多处理器计算的架构,必然更容易遇到多个进程,多个线程访问共享数据的情况,如下图所示:

- 进程与进程之间:单核上的抢占,多核上的SMP;
- 进程与中断之间:中断又包含了上半部与下半部,中断总是能打断进程的执行流;
- 中断与中断之间:外设的中断可以路由到不同的CPU上,它们之间也可能带来竞态;
这时候就需要一种同步机制来保护并发访问的内存数据。本系列文章分为两部分,这一章主要讨论原子操作,自旋锁,信号量和互斥锁
原子操作
原子操作是在执行结束前不可打断的操作,也是最小的执行单位。以 arm 平台为例,原子操作的 API 包括如下:
| API | 说明 |
|---|---|
| int atomic_read(atomic_t *v) | 读操作 |
| void atomic_set(atomic_t *v, int i) | 设置变量 |
| void atomic_add(int i, atomic_t *v) | 增加 i |
| void atomic_sub(int i, atomic_t *v) | 减少 i |
| void atomic_inc(atomic_t *v) | 增加 1 |
| void atomic_dec(atomic_t *v) | 减少 1 |
| void atomic_inc_and_test(atomic_t *v) | 加 1 是否为 0 |
| void atomic_dec_and_test(atomic_t *v) | 减 1 是否为 0 |
| void atomic_add_negative(int i, atomic_t *v) | 加 i 是否为负 |
| void atomic_add_return(int i, atomic_t *v) | 增加 i 返回结果 |
| void atomic_sub_return(int i, atomic_t *v) | void atomic_sub_return(int i, atomic_t *v) |
| void atomic_inc_return(int i, atomic_t *v) | 加 1 返回 |
| void atomic_dec_return(int i, atomic_t *v) | 减 1 返回 |
原子操作通常是内联函数,往往是通过内嵌汇编指令来实现的,如果某个函数本身就是原子的,它往往被定义成一个宏,以下为例。
#define ATOMIC_OP(op, c_op, asm_op) \
static inline void atomic_##op(int i, atomic_t *v) \
{ \
unsigned long tmp; \
int result; \
\
prefetchw(&v->counter); \
__asm__ __volatile__("@ atomic_" #op "\n" \
"1: ldrex %0, [%3]\n" \
" " #asm_op " %0, %0, %4\n" \
" strex %1, %0, [%3]\n" \
" teq %1, #0\n" \
" bne 1b" \
: "=&r" (result), "=&r" (tmp), "+Qo" (v->counter) \
: "r" (&v->counter), "Ir" (i) \
: "cc"); \
} 可见原子操作的原子性依赖于 ldrex 与 strex 实现,ldrex 读取数据时会进行独占标记,防止其他内核路径访问,直至调用 strex 完成写入后清除标记。
ldrex 和 strex 指令,是将单纯的更新内存的原子操作分成了两个独立的步骤:
1 . ldrex 用来读取内存中的值,并标记对该段内存的独占访问:
ldrex Rx, [Ry]
读取寄存器 Ry 指向的4字节内存值,将其保存到 Rx 寄存器中,同时标记对 Ry 指向内存区域的独占访问。如果执行 ldrex 指令的时候发现已经被标记为独占访问了,并不会对指令的执行产生影响。
2 . strex 在更新内存数值时,会检查该段内存是否已经被标记为独占访问,并以此来决定是否更新内存中的值:
strex Rx, Ry, [Rz]
如果执行这条指令的时候发现已经被标记为独占访问了,则将寄存器 Ry 中的值更新到寄存器 Rz 指向的内存,并将寄存器 Rx 设置成 0。指令执行成功后,会将独占访问标记位清除。如果执行这条指令的时候发现没有设置独占标记,则不会更新内存,且将寄存器 Rx 的值设置成 1。
ARM 内部的实现如下所示,这里不再赘述。
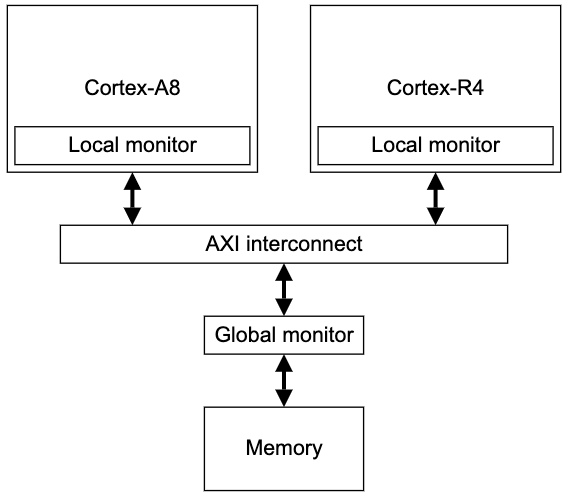
自旋锁 spin_lock
Linux内核中最常见的锁是自旋锁,自旋锁最多只能被一个可执行线程持有。如果一个线程试图获取一个已被持有的自旋锁,这个线程会进行忙循环——旋转等待(会浪费处理器时间)锁重新可用。自旋锁持有期间不可被抢占。
另一种处理锁争用的方式:让等待线程睡眠,直到锁重新可用时再唤醒它,这样处理器不必循环等待,可以去执行其他代码,但是这会有两次明显的上下文切换的开销,信号量便提供了这种锁机制。
自旋锁的使用接口如下:
| API | 说明 |
|---|---|
| spin_lock() | 获取指定的自旋锁 |
| spin_lock_irq() | 禁止本地中断并获取指定的锁 |
| spin_lock_irqsave() | 保存本地中断当前状态,禁止本地中断,获取指定的锁 |
| spin_unlock() | 释放指定的锁 |
| spin_unlock_irq() | 释放指定的锁,并激活本地中断 |
| spin_unlock_irqrestore() | 释放指定的锁,并让本地中断恢复以前状态 |
| spin_lock_init() | 动态初始化指定的锁 |
| spin_trylock() | 试图获取指定的锁,成功返回0,否则返回非0 |
| spin_is_locked() | 测试指定的锁是否已被占用,已被占用返回非0,否则返回0 |
以 spin_lock 为例看下它的用法:
DEFINE_SPINLOCK(mr_lock);
spin_lock(&mr_lock);
/* 临界区 */
spin_unlock(&mr_lock);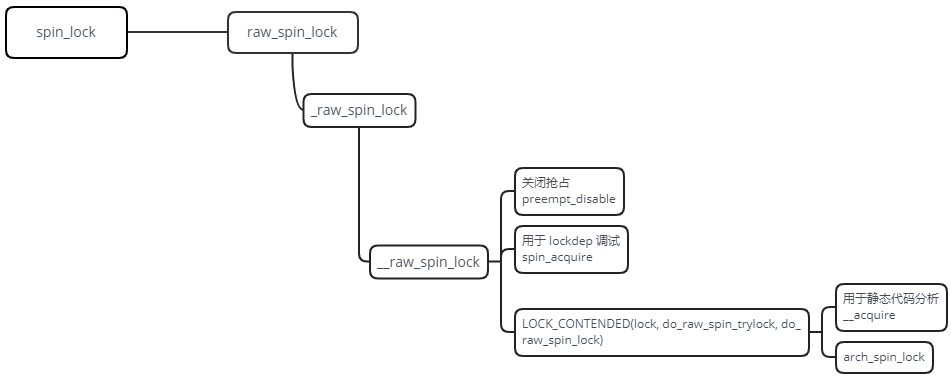
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned int tmp;
arch_spinlock_t lockval, newval;
asm volatile(
/* Atomically increment the next ticket. */
ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" prfm pstl1strm, %3\n"
"1: ldaxr %w0, %3\n"
" add %w1, %w0, %w5\n"
" stxr %w2, %w1, %3\n"
" cbnz %w2, 1b\n",
/* LSE atomics */
" mov %w2, %w5\n"
" ldadda %w2, %w0, %3\n"
__nops(3)
)
/* Did we get the lock? */
" eor %w1, %w0, %w0, ror #16\n"
" cbz %w1, 3f\n"
/*
* No: spin on the owner. Send a local event to avoid missing an
* unlock before the exclusive load.
*/
" sevl\n"
"2: wfe\n"
" ldaxrh %w2, %4\n"
" eor %w1, %w2, %w0, lsr #16\n"
" cbnz %w1, 2b\n"
/* We got the lock. Critical section starts here. */
"3:"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp), "+Q" (*lock)
: "Q" (lock->owner), "I" (1 << TICKET_SHIFT)
: "memory");
}static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
unsigned long tmp;
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" ldrh %w1, %0\n"
" add %w1, %w1, #1\n"
" stlrh %w1, %0",
/* LSE atomics */
" mov %w1, #1\n"
" staddlh %w1, %0\n"
__nops(1))
: "=Q" (lock->owner), "=&r" (tmp)
:
: "memory");
}上边的代码中,核心逻辑在于 asm volatile() 内联汇编中,有很多独占的操作指令,只有基于指令的独占操作,才能保证软件上的互斥。把核心逻辑翻译成 C 语言:
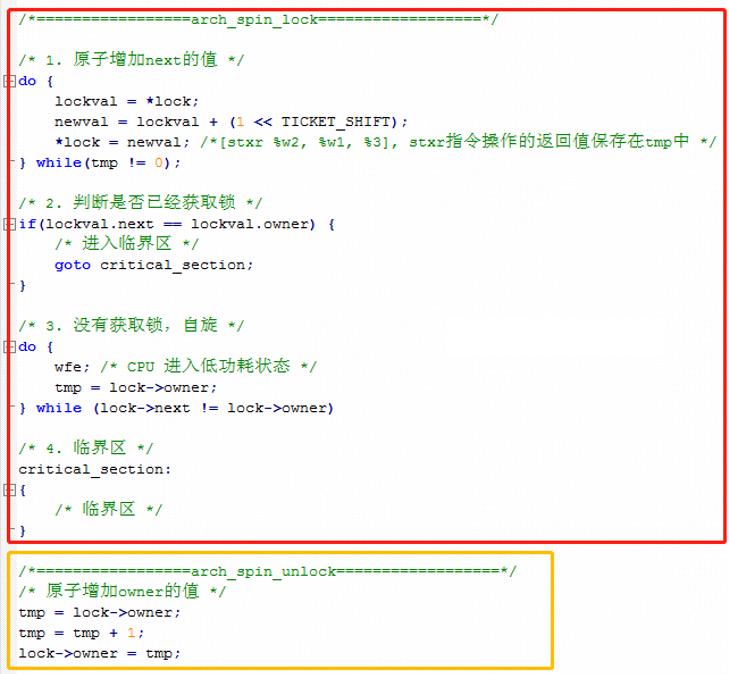
信号量 Semaphore
信号量是在多线程环境下使用的一种措施,它负责协调各个进程,以保证他们能够正确、合理的使用公共资源。它和 spin_lock 最大的不同之处就是:无法获取信号量的进程可以睡眠,因此会导致系统调度。
信号量的定义如下:
struct semaphore {
raw_spinlock_t lock; //利用自旋锁同步
unsigned int count; //用于资源计数
struct list_head wait_list; //等待队列
};信号量在创建时设置一个初始值 count,用于表示当前可用的资源数。一个任务要想访问共享资源,首先必须得到信号量,获取信号量的操作为 count - 1。若当前 count 为负数,表明无法获得信号量,该任务必须挂起在该信号量的等待队列等待;若当前 count 为非负数,表示可获得信号量,因而可立刻访问被该信号量保护的共享资源。
当任务访问完被信号量保护的共享资源后,必须释放信号量,释放信号量是操作 count + 1,如果加一后的 count 为非正数,表明有任务等待,则唤醒所有等待该信号量的任务。
了解了信号量的结构与定义,接下来我们看下常用的信号量接口:
| API | 说明 |
|---|---|
| DEFINE_SEMAPHORE(name) | 声明信号量并初始化为 1 |
| void sema_init(struct semaphore *sem, int val) | 声明信号量并初始化为 val |
| down | 获得信号量,task 不可被中断,除非是致命信号 |
| down_interruptible | 获得信号量,task 可被中断 |
| down_trylock | 能够获得信号量时,count --,否则立刻返回,不加入 waitlist |
| down_killable | 获得信号量,task 可被 kill |
| up | 释放信号量 |
这里我们看下最核心的两个实现 down 和 up。
- down
down 用于调用者获得信号量,若 count 大于0,说明资源可用,将其减一即可。
void down(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
__down(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
EXPORT_SYMBOL(down);若 count < 0,调用函数 __down(),将 task 加入等待队列,并进入等待队列,并进入调度循环等待,直至其被 __up 唤醒,或者因超时以被移除等待队列。
static inline int __sched __down_common(struct semaphore *sem, long state,
long timeout)
{
struct semaphore_waiter waiter;
list_add_tail(&waiter.list, &sem->wait_list);
waiter.task = current;
waiter.up = false;
for (;;) {
if (signal_pending_state(state, current))
goto interrupted;
if (unlikely(timeout <= 0))
goto timed_out;
__set_current_state(state);
raw_spin_unlock_irq(&sem->lock);
timeout = schedule_timeout(timeout);
raw_spin_lock_irq(&sem->lock);
if (waiter.up)
return 0;
}
timed_out:
list_del(&waiter.list);
return -ETIME;
interrupted:
list_del(&waiter.list);
return -EINTR;
}- up
up 用于调用者释放信号量,若 waitlist 为空,说明无等待任务,count + 1,该信号量可用。
void up(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(list_empty(&sem->wait_list)))
sem->count++;
else
__up(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
EXPORT_SYMBOL(up);若 waitlist 非空,将 task 从等待队列移除,并唤醒该 task,对应 __down 条件。
static noinline void __sched __up(struct semaphore *sem)
{
struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list,
struct semaphore_waiter, list);
list_del(&waiter->list);
waiter->up = true;
wake_up_process(waiter->task);
}互斥锁 mutex
Linux 内核中,还有一种类似信号量的同步机制叫做互斥锁。互斥锁类似于 count 等于 1 的信号量。所以说信号量是在多个进程/线程访问某个公共资源的时候,进行保护的一种机制。而互斥锁是单个进程/线程访问某个公共资源的一种保护,于互斥操作。
互斥锁有一个特殊的地方:只有持锁者才能解锁。如下图所示:
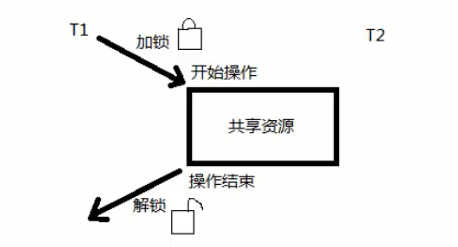
互斥锁的结构体定义:
struct mutex {
atomic_long_t owner; //互斥锁的持有者
spinlock_t wait_lock; //利用自旋锁同步
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
struct list_head wait_list; //等待队列
......
};其常用的接口如下所示:
| API | 说明 |
|---|---|
| DEFINE_MUTEX(name) | 静态声明互斥锁并初始化解锁状态 |
| mutex_init(mutex) | 动态声明互斥锁并初始化解锁状态 |
| void mutex_destroy(struct mutex *lock) | 销毁该互斥锁 |
| bool mutex_is_locked(struct mutex *lock) | 判断互斥锁是否被锁住 |
| mutex_lock | 获得锁,task 不可被中断 |
| mutex_unlock | 解锁 |
| mutex_trylock | 尝试获得锁,不能加锁则立刻返回 |
| mutex_lock_interruptible | 获得锁,task 可以被中断 |
| mutex_lock_killable | 获得锁,task 可以被中断 |
| mutex_lock_io | 获得锁,在该 task 等待琐时,它会被调度器标记为 io 等待状态 |