负载均衡之备胎转正
问题初现
「滴~~~」,钉钉突然响起了很多客服转发来的用户投诉信息,说是网络连接不上了,经过排查发现是其中一台机器(RS2)挂了

应用层健康检查:HTTP 检测
老梁一眼看出了问题所在:「我们需要开发一个健康检查服务,部署在 LVS 上,这个服务可以定时检查其后的 RS 是否可用,如果不可用则将 RS 摘除,这样就可以保障线上服务正常了」
「妙啊,通过软件及时探测,摘除不可用的机器,避免了人工发现不及时的问题,那么该怎么做这个健康检查呢,需要满足什么条件呢」听说要开发这样的软件,小章顿时来了兴致。
「小章啊,仔细想想看,我们的服务在发布过程中其实也是有健康检查的,要保证一个工程可用,至少保证它是可访问的以及它用到的中间件,DAO 是正常的,所以它的健康代码如下
@Service(protocol = {"rest"})
public class HealthCheckServiceImpl implements HealthCheckService {
@Resource
private TestDAO TestDAO;
@Resource
private RebateClient rebateClient;
@Override
public String getHealthStatus() {
List<TestDO> testDOS =
TestDAO.getResult(123);
Assert.isTrue(testDOS != null, "rebateMemberDOS null");
// 此处省略 redis 检测
// 此处省略其它检测
return "health";
}}如以上代码所示,我们在工程里写了健康检查 HealthCheckService 类,暴露了一个 rest 服务,这样的话在部署的时候在服务部署脚本里首先访问一下此服务的 getHealthStatus 方法,如果返回的值为「health」,则说明此服务的 dubbo 服务,DAO,redis 等正常,说明此服务是没有问题的,如果返回的值不为 health,则说明此服务有问题,不能上线,这就是我们所说的健康检查,通过访问服务暴露的方法,来检测此服务是否可用。
所以我们要开发的检测服务也与此类似,只要定时访问此服务暴露的接口,看下此接口返回的值与我们期待的值是否一致即可,一致说明此服务正常,否则,说明此服务异常,将其剔除,当然了一次连接不通就判断为不可用可能有些问题,我们可以提供一个重试次数,比如 3 次,如果 3 次健康检测都失败,则认定此服务不可用!配置的伪代码如下:
real_server 192.168.1.220 80 {
HTTP_GET {
url {
path /healthCheck
status_code 200
}
connect_timeout 3
nb_get_retry 3 // 置超时重试次数
}
}「妙啊,此法甚好!只要访问健康检查服务就可以很方便地查看此服务是否正常了,但是有个问题:如果这个健康检测方法写的检测逻辑很多,而 LVS 定时发检测请求比较频繁的话可能会有一定的性能问题,是否有更轻量级的检测方法呢」小章说道
「考虑得很周到!一般健康检测确实逻辑比较重,所以只在部署的的时候检测一次就够了,在生产上我们可以采用更轻量的检测方式:TCP连接检测」
TCP连接检测
TCP 连接检测原理很简单,我们知道要建立一个 TCP 连接,首先必须由 TCP 客户端发起 connect 请求,三次握手成功后才算建立起一个 TCP 链接,然后才能正常收发数据
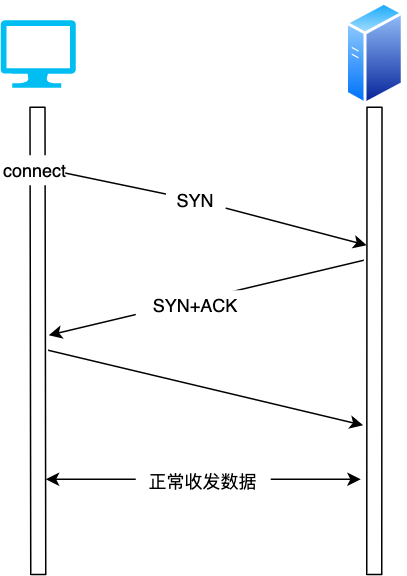
tcp连接检测
TCP_CHECK {
connect_port 80 // 指定端口
connect_timeout 6 // 设置响应超时时间
nb_get_retry 3 // 设置超时重试次数
delay_before_retry 3 // 设置超时重试间隔时间
}小章按着老梁的思路把这两种健康检测思路给实现了,并且给这个服务取了个霸气的名字:keepalived,老梁很满意,不过他又发现了新的问题。。。
单点故障---高可用解决之道
「小章,健康检查做得很好,而且提供了两种检查方式,很全面,不过你这个架构还有个很致命的问题,不知你有没发现,那就是目前只有一台 LVS 在工作,如果这台 LVS 挂了,那我们业务就跌零了, 你还需要让 keepalived 支持 LVS 的高可用」
小章恍然大悟,「那该咋办呢」
「高可用的通用解决方案很简单,冗余+故障自动发现转移,我们可以按照这个思路来设计 LVS 高可用,具体方案如下:
我们可以为 LVS 准备几台备机,如果发现 LVS 挂了,就让备机顶上去,这样不就实现了高可用了吗」不愧是 CTO,一语中的
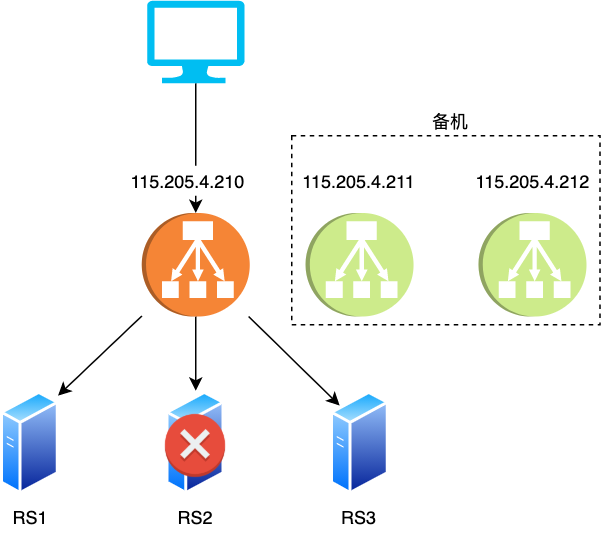
- 如果主机(以下简称 master)宕机,备机(以下简称 backup)顶上,那 IP 地址不是变了吗,此时客户端该怎么连接
- 几台机器首次启动时,谁为 master,谁为 backup
- master 宕机后,backup 是如何感知到的,多台 backup 又是如何竞选出主机的,这个和问题 2 有点类似
「这几个问题提的很好,正是实现高可用的关键,可以看出小伙子还是有经过深入思考的」老梁高兴地说,「这些问题不难化解,我们一一来看看」
问题一:backup 成为 master 后,IP 地址变了怎么办?
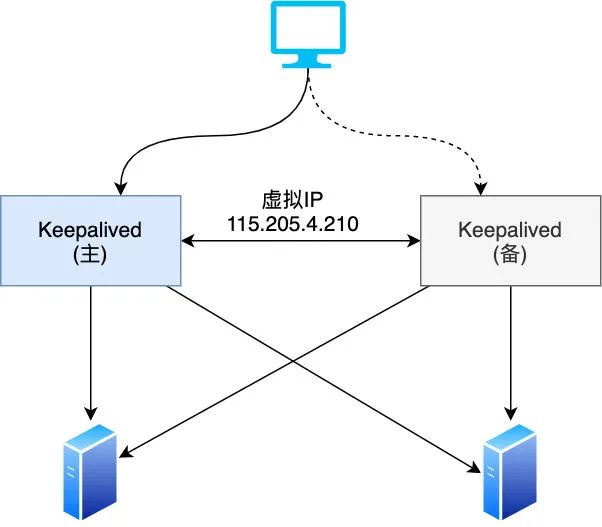
答:IP 地址不能变,对外必须表现为一个 IP,我们通常称为「虚拟(virtual) IP」,通常简称为 VIP
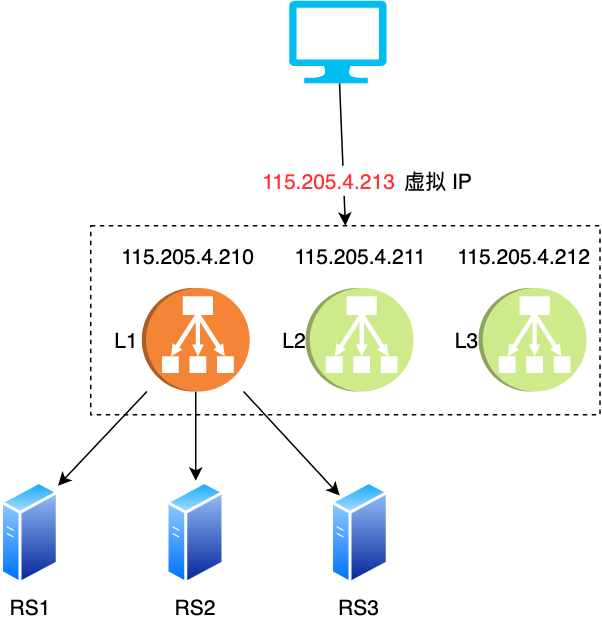
- 一个主机如何才能有两个 IP
- 为什么 VIP 在某台竞选 master 成功的 backup 上生效后要发一个携带有本机的 MAC 地址和 VIP 地址信息的 ARP 报文
先看第一个问题,主机如何才能拥有两个 IP ,毕竟一台机器成为主机后,除了本身机器被分配的 IP(115.205.4.210),VIP 也漂移到它身上了,此时它拥有两个 IP
我们知道计算机要上网,首先要把网线插入网卡,一个网卡其实就对应着一个 IP,所以一台主机配两个网卡就可以绑定两个 IP,一般 LVS 都会配置双网卡,一来每个网卡带宽都是有限的,双网卡相当于提升了一倍的带宽,二来两个网卡也起到了热备的作用,如果一个网卡坏了,另外一个可以顶上。
但有人说了,我就只有一个网卡,也想配置多个 IP,是否可以?
答案是可以的,网卡一般分两种,一种是物理网卡,一种是虚拟网卡
物理网卡:可以插网线的网卡,如果有多个网卡,我们一般将其命名为 eth0,eth1。。。,如果一个网卡对应多个 IP,以 eth0 为例,一般将其命名为 eth0,eth0:0,eth0:1。。。eth0:x,比如一台机器只有一个网卡,但其对应两个 IP 192.168.1.2, 192.168.1.3,那么其绑定的网卡名称分别为 eth0,eth0:0虚拟网卡:虚拟网卡通常被称为 loopback,一般命名为 lo,是一个特殊的网络接口,主要用于本机中各个应用之间的网络交互(哪怕网线拔了,本机各个应用之间通过 lo 也是能通信的),需要注意的是虚拟网卡和物理网卡一样,也可以绑定任意 IP 地址,如果在虚拟网卡配置了任何的 IP 地址,只要有物理网卡,就能到收到并处理目的 IP 为虚拟网卡上 IP 的数据包,lo 默认绑定了 127.0.0.1 这个本地 IP ,如果要绑定其他的 IP,对应的网卡命名一般为 lo:0,lo:1。。。
所以假设一台机器只有一个网卡,一般内网给它默认分配的 IP 绑定在 eth0 上,那么我们就可以把虚拟 IP 绑定在 eth0:0 上,这样的话外界就能正常访问此虚拟 IP 了,如果 master 挂掉了,keepalived 会让此 master 的 eth0:0 端口失效,同时让新 master 的 eth0:0 绑定虚拟 IP,这样就避免了对外暴露两个虚拟 IP。
再来看第二位问题,虚拟 IP 在某台机器生效后,为啥要发一个 ARP 请求呢,这个问题其实在之前的文章中提到过,这里为了照顾其他没看过之前文章的读者,再简单提一下,其实上面的架构图我们作了一定程度的简化,更详细的应该如下图所示
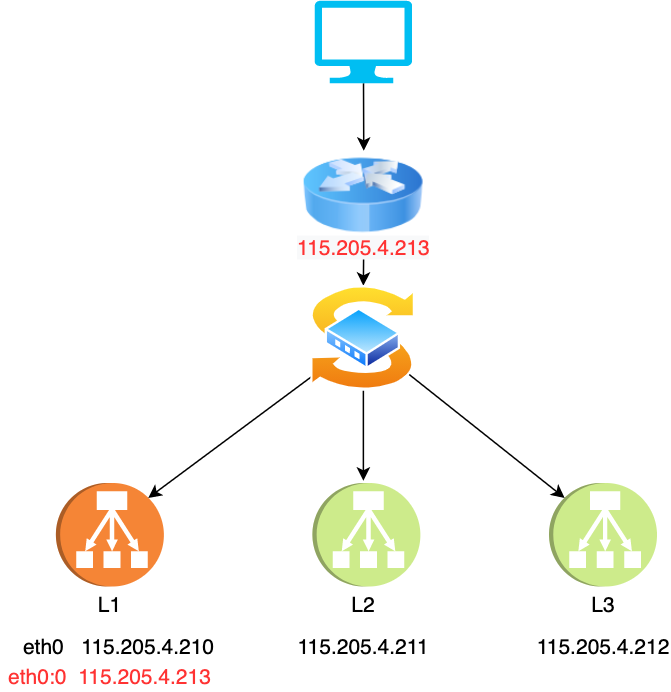
一开始它啥也不知道,所以它在网址发了一个 ARP 广播包,相当于大吼一声:IP 地址为 115.205.4.213 的机器是谁啊,由于这个虚拟 IP 在 L1 上,所以只有 L1 响应了,L1 会把带有自己 mac 地址的响应包发回给路由器,路由器收到后会把 IP 地址与 L1 mac 地址的关系记在本地,然后在包的头部装上 L1 的 mac 地址发给交换机,交换机就能识别到应该发给 L1,下次当客户端再次发数据包到路由器时,路由器会首先在本地缓存(ARP 缓存)中查到 IP 对应的 mac(即 L1 的mac),命中后将包上的 mac 地址替换成 L1 的 mac 转发出去,至此相信你应该明白为啥虚拟 IP 生效后要发 ARP 报文了,就是为了更新由器上的 ARP 缓存,将虚拟 IP 对应的 mac 地址更新为竞选 master 成功的 backup 上的 mac,这样下次路由器就能正确将新 master 的 mac 附在数据包上,就能正确地转发到机器上了,否则,数据包会转发到老的 master 上,引起灾难性的后果!
问题二:几台机器首次启动后,谁为 master,谁为 backup
这个问题其实很简单,谁的能力强,谁就优先成为 master,我们可以给各个机器设置不同的值为 0~255 的权重,权重越大,代表此机器越有可能成为 master(如果权重一样,则比较它们的 IP,IP 大的权重高),这里分几种情况
- 每个机器启动后都处于 Initialize 状态,若某台机器接口(eth0)Up 之后,如果其权重为 255 且此时还没有 master 则其成为 master 并且让虚拟 IP 绑定在 eth0:0 端口上,如果此时已有 master 呢,分两种模式:抢占和非抢占模式,如果处于非抢占模式下,则它转为 backup 状态,否则它会重新竞争成为 master,此时一般能竞争成功,因为它处于最高权重(一般只有一台机器处于最高权限)
- 如果某台机器权重不为 255,则经过一段时间后如果此时还没有 master ,那么它会竞争 master,如果此时有了 master,也和情况 1 一样,分抢占和非抢占模式,为啥要经过一段时间才竞争 master 呢,其实主要是为了优先让权重为 255 的机器成为 master
整体流程如下
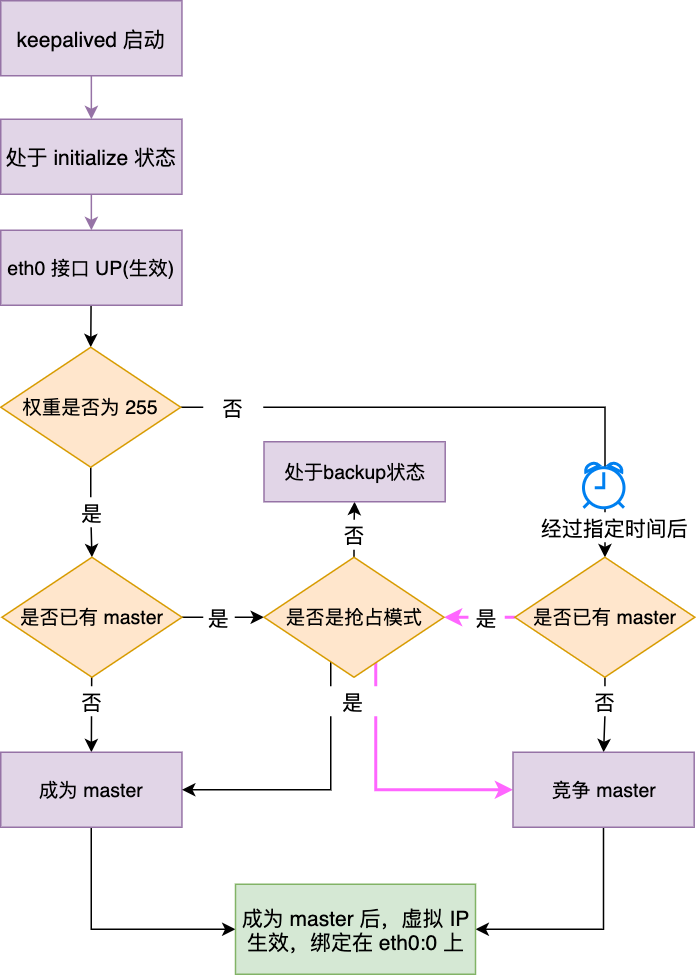
问题三: master 宕机后,backup 是如何感知到的,多台 backup 又是如何竞选出主机的
当机器成为 master 后,它会定时发送广播给其他的 backup,让其他 backup 知道它还存活着,如果在指定时间内(一般我们称此时间为 Master_Down_Interval)backup 没有收到 master 的广播包,那么 backup 互相之间会发广播包通过比较权重竞争 master,某台 backup 竞选 master 成功后同样会让虚拟 IP 绑定在 eth0:0 端口上,并且发送 ARP 包让路由器等更新自己的 ARP 缓存,其他竞选失败的则转为 backup 状态
至此相信大家已经明白了 keepalived 的工作机制,所有上面说的这些工作只要配置一下 keepalived 的配置文件并启动后即可实现。
另外 keepalived 实现的高可用机制不光可以用在 LVS 上,也可以用在 MySQL 等高可用上,所以你内部工程连 MySQL 的地址一般是虚拟 IP。现在我相信你能看懂如下 LVS 的高可用工作图了
总结
相信大家看完本文对 keepalived 的工作原理应该是了然于胸了,它的主要工作模式无非就两块:「健康检查」和「高可用」,健康检查我们只介绍了常见的两种,其实它还支持通过运行脚本来作健康检测,只是不太常用而已,另外 keepalived 的高可用可以说是大放异彩,除了用在 LVS 的高可用,还用在 Nginx ,MySQL 的高可用上,原理其实无非就是利用心跳检测+竞争 master + IP 漂移来实现,完整的 keepalived.conf 配置文件大家有兴趣可以看文末的参考链接,相信经过上面的原理讲解再去看此文件不是问题
另外不知大家是否注意到了,master 虽然可以定时向 backup 发送心跳,但如果此心跳链路坏了 backup 就会误认为 master 已经不可用了,从而去申请成为 master,这样就会造成两个 master 的出现,也就是我们常说的脑裂,怎么解决?可以同时用两条心跳线路,这样一条心跳检测线路坏了,另一条还是好的,依然能传送心跳消息。当然除了心跳链路坏了还有可能会有其他情况也会导致脑裂的发生,我们还是要做好多种预案,必要时人工及时介入,(关于脑裂的更多信息可以看文末的参考链接)