Python 神器 Celery 源码阅读 (2)
Celery是一款非常简单、灵活、可靠的分布式系统,可用于处理大量消息,并且提供了一整套操作此系统的工具。Celery 也是一款消息队列工具,可用于处理实时数据以及任务调度。
几周前,我们一起阅读celery的源码(点击查看《[第一篇] 》),学习了celery的工具之一,实现Promise功能的「vine库」。这周我们一起看另外一个工具,负责AMQP协议中数据传输的python-amqp库。它采用纯python实现(支持cython扩展),可以通过它理解AMQP协议的细节,打下celery的基础,本文包括如下几个部分:
- py-amqp项目概述
- 帧机制详解
- AMQP协议帧处理
- AMQP使用
- AMQP模型
- 小结
- 小技巧
py-amqp项目概述
py-amqp当前版本 5.0.6 ,主要代码如下表:
| 文件 | 描述 |
|---|---|
| abstract_channel.py | 抽象的channel |
| basic_message.py | message消息实现 |
| channel.py | channel频道实现 |
| connection.py | connection连接实现 |
| exceptions.py | 异常 |
| method_framing.py | 帧解析方法 |
| platform.py | 运行平台适配 |
| protocol.py | 协议对象 |
| sasl.py | ssl认证相关实现 |
| serialization.py | 序列化相关实现 |
| spec.py | 协议规则定义 |
| transport.py | 通讯实现 |
| util.py | 工具类 |
| *.pxd | Cython的实现,可以加速amqp |
项目主要包括2个功能:
- AMQP协议的传输处理,包括字节流,帧和Message的序列化/反序列化
- AMQP协议的Connection,Channel,Message三个基础模型实现
在正式开始之前,我们需要先简单了解一下AMQP协议:
高级消息队列协议即Advanced Message Queuing Protocol(AMQP)是面向消息中间件提供的开放的应用层协议,其设计目标是对于消息的排序、路由(包括点对点和订阅-发布)、保持可靠性、保证安全性[1]。AMQP规范了消息传递方和接收方的行为,以使消息在不同的提供商之间实现互操作性,就像SMTP,HTTP,FTP等协议可以创建交互系统一样。
高级消息队列协议是一种二进制应用层协议,用于应对广泛的面向消息应用程序的支持。协议提供了消息流控制,保证的一个消息对象的传递过程,如至多一次、保证多次、仅有一次等,和基于SASL和TLS的身份验证和消息加密。
文字比较难懂,结合下图,消息如何从生产者传递到消费者的过程,应该就可以理解AMQP:
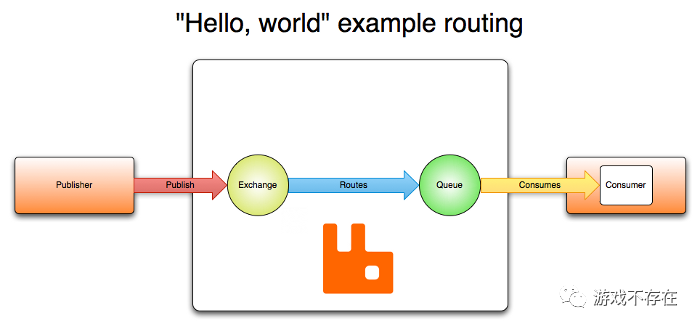
hello-world-example-routing
上图是使用RabbitMQ实现的,RabbitMQ是一个开源的消息中间件,最早实现了AMQP协议,也是celery的默认消息中间件。强烈建议对AMQP协议不熟悉的朋友先阅读一下参考链接中的: 「AMQP 0-9-1 Model Explained」。我摘录了channel和message部分内容如下:
某些应用程序需要多个连接到代理。但是,同时保持许多 TCP 连接打开是不可取的,因为这样做会消耗系统资源并且使配置防火墙更加困难。AMQP 0-9-1 连接与可以被认为是“共享单个 TCP 连接的轻量级连接”的通道复用。
客户端执行的每个协议操作都发生在通道上。特定通道上的通信与另一个通道上的通信完全分开,因此每个协议方法还携带一个通道 ID(也称为通道号),这是一个整数,代理和客户端都使用它来确定该方法适用于哪个通道。通道仅存在于连接的上下文中,而不会单独存在。当连接关闭时,其上的所有通道也关闭。
对于使用多个线程/进程进行处理的应用程序,为每个线程/进程打开一个新通道而不在它们之间共享通道是很常见的。
AMQP 0-9-1 模型中的消息具有属性。有些属性非常常见,以至于 AMQP 0-9-1 规范定义了它们,应用程序开发人员不必考虑确切的属性名称。一些例子是:
- 内容类型 Content type
- 内容编码 Content encoding
- 路由键 Routing key
- 交付模式(持续与否)Delivery mode (persistent or not)
- 消息优先级 Message priority
- 消息发布时间戳 Message publishing timestamp
- 有效期 Expiration period
- 发布者应用程序 ID Publisher application id
AMQP 代理使用某些属性,但大多数属性都可以由接收它们的应用程序解释。一些属性是可选的,称为headers。它们类似于 HTTP 中的 X-Header。消息属性是在发布消息时设置的。
帧机制详解
之前我介绍过Redis客户端和服务端的通讯协议:RESP(Redis Serialization Protocol),链接在这里: 「Redis-py 源码阅读」 。当时介绍的不够详细,这里我尝试通俗的介绍一下在TCP这种二进制流之上的构建各种应用层协议的常用方法。
我们知道TCP是基于字节流的传输层通信协议,你可以把它想像成下图:
+--------------------------------------------+
| |
|...00010001110001101110101111001111010110...|
| |
+--------------------------------------------+这里的数据都是由0和1组成,头和尾的省略号表示还有很多数据,这么多数据从左(服务端)流向右 (客户端)。如果没有额外的说明,我们无法从中获取到有效的信息。类似一篇长文没有标点一样,没法读懂,就是一堆乱码。要解决这个问题,一般有3种办法:
- 定长信息
- 使用特定字符分隔信息
- 使用数据头指定信息长度
定长信息
定长信息,类似下图:
+--------+--------+--------+--------+--------+
| | | | | |
|00100110|10000111|00111011|11010110|00001111|
| | | | | |
+--------+--------+--------+--------+--------+我们约定每个信息都是8位字符长度,这样上面的数据可以得到5段有效信息,分别是:00100110,10000111...。定长信息的缺陷很明显,如果信息大于8位需要截断,如果小于8位则需要补齐。
大家可以想象一下
00100110是如何补齐?方法很简单,位数补齐在前面,所以这里是用0补齐了2位。如果是在尾部进行补齐,就无法知道末尾的0是有效数据还是补齐的数据。
我们可以使用天幕杆帮忙理解,这种工厂生产出来的东西,都有着一样的长度:

使用特定字符分隔信息
也可以使用特定的间隔在数据流中区分信息,比如下图。
+--------------------------------------------+
| |
|01100110101010 101010010101 1000010110101101|
| |
+--------------------------------------------+这里使用空格 `来区分上面的数据,得到3段信息,分别是:01100110101010` ...
注意仅仅为了示意方便,二进制流中没有空格,只有0010 0000
我们可以把间隔理解成竹竿的竹节,2个竹节之间就是一段。自然生长的竹节,肯定是长短不一。

使用分隔符方式的缺陷在于,效率比较低下,需要挨个判断是否分隔符。
使用数据头指定信息长度
数据头就是给每个消息加一个描述消息长度的头,比如下面:
+--------------------------------------------+
| |
|10110110100111010110111110101100011100011100|
| |
+--------------------------------------------+1表示后面有1位数据,0表示后面没有数据,所以上面的数据前面部分翻译出来的信息就是0110 1001,对应ASCII的小写字母i:
1011011010011101011 # 流
0 1 1 0 1 0 0 1 # 去除长度后的信息上面仅仅使用0和1模拟,会显示的有点冗余。如果使用字符,就可以按照字符位数来定义。比如:
+--------------------------------------------+
| |
|30112101051111120010112113000210201211311111
| |
+--------------------------------------------+
30112101051111120010112113000210201211311111
3 2 1 5 2 1 1 2 3 2 2 2 3 1 # 长度
011 10 0 11111 00 0 1 11 000 10 01 11 111 1同样可以用生活中的灯串来理解数据头,每个信息长度的大小,类似大小不等的灯泡,灯泡上标明了数据长度。

所谓帧,在网络中就是表示一个最小单元,所以我们使用上面3种方法都可以从流中区分出各个信息,也就是帧。实际应用中基本都是第3种方法或者混用2和3。比如http协议、RESP协议是分隔+数据头的组合,AMQP协议也可以认为是此类。
AMQP协议帧处理
流的处理
transport负责创建socket,并进行socket上的二进制流的读和写。读的方法如下:
# ch23-celery/py-amqp-5.0.6/amqp/transport.py
def _read(self, n, initial=False, _errnos=(errno.EAGAIN, errno.EINTR)):
"""Read exactly n bytes from the socket."""
# 持续的读取字节
# self.sock = socket.socket(af, socktype, proto)
# self._quick_recv = self.sock.recv
recv = self._quick_recv
# 字节缓存
rbuf = self._read_buffer
try:
while len(rbuf) < n:
try:
# 读取剩余字节
s = recv(n - len(rbuf))
except OSError as exc:
if exc.errno in _errnos:
if initial and self.raise_on_initial_eintr:
raise socket.timeout()
continue
raise
if not s:
raise OSError('Server unexpectedly closed connection')
rbuf += s
except: # noqa
self._read_buffer = rbuf
raise
# 多余的字节缓存住
result, self._read_buffer = rbuf[:n], rbuf[n:]
return result写的方法如下:
# ch23-celery/py-amqp-5.0.6/amqp/transport.py
def write(self, s):
try:
# self._write = self.sock.sendall
self._write(s)
except socket.timeout:
raise
except OSError as exc:
if exc.errno not in _UNAVAIL:
self.connected = False
raise帧的处理
二进制流的读和写一般没有什么特别的,重点在如何从读取的流中解析出帧信息。下面是AMQP中帧的读取,也在transport中,主干如下:
# ch23-celery/py-amqp-5.0.6/amqp/transport.py
def read_frame(self, unpack=unpack):
"""Parse AMQP frame.
Frame has following format::
0 1 3 7 size+7 size+8
+------+---------+---------+ +-------------+ +-----------+
| type | channel | size | | payload | | frame-end |
+------+---------+---------+ +-------------+ +-----------+
octet short long 'size' octets octet
"""
# 本地化方法,加快执行效率
read = self._read
# 缓存buffer
read_frame_buffer = bytes()
...
# 读取帧头7个字节
frame_header = read(7, True)
read_frame_buffer += frame_header
# 解析帧头(大端)(无符号)
frame_type, channel, size = unpack('>BHI', frame_header)
# 读取body
payload = read(size)
read_frame_buffer += payload
# 读取尾部校验码
frame_end = ord(read(1))
...
if frame_end == 206:
# 返回帧数据
return frame_type, channel, payload
...- AMQP的帧格式是帧头+body+帧尾。
- 帧头由1个字节的帧类型+2个自己的channelID+4个字节的body长度组成。
- 帧尾是1个字节,正常情况下是0xce,对应的十进制就是206。
- 使用unpack方法从二进制中获取到信息
Message的处理
通过read_frame方法可以得到一个数据帧,这些帧又在method_framing中被组合成业务可用的Message:
# ch23-celery/py-amqp-5.0.6/amqp/method_framing.py
def frame_handler(connection, callback,
unpack_from=unpack_from, content_methods=_CONTENT_METHODS):
"""Create closure that reads frames."""
# 使用闭包读取frame
# 字典默认值为1
expected_types = defaultdict(lambda: 1)
partial_messages = {}
def on_frame(frame):
# 帧类型 channelID 帧内容
frame_type, channel, buf = frame
...
# 帧类型仅 1,2,3,8
if frame_type not in (expected_types[channel], 8):
raise UnexpectedFrame(
'Received frame {} while expecting type: {}'.format(
frame_type, expected_types[channel]),
)
elif frame_type == 1:
# 开始帧
# 读取2个整数
method_sig = unpack_from('>HH', buf, 0)
# 三个类型是消息的开始 content_methods=[spec.Basic.Return spec.Basic.Deliver spec.Basic.GetOk]
if method_sig in content_methods:
# Save what we've got so far and wait for the content-header
# 创建Message并以channel为key暂存
partial_messages[channel] = Message(
frame_method=method_sig, frame_args=buf,
)
expected_types[channel] = 2
return False
...
elif frame_type == 2:
# 头帧
# 从闭包中获取Message
msg = partial_messages[channel]
# 附加header
msg.inbound_header(buf)
if not msg.ready:
# wait for the content-body
# 未就绪,继续等待body
expected_types[channel] = 3
return False
elif frame_type == 3:
# 内容帧
# 继续从闭包中获取Message
msg = partial_messages[channel]
# 附加body
msg.inbound_body(buf)
...
# 重置channel等待下一个包
expected_types[channel] = 1
# 清空通道的消息
partial_messages.pop(channel, None)
# 执行message的callback函数
callback(channel, msg.frame_method, msg.frame_args, msg)- 三个帧构成一个Message(业务消息),分别的帧类型是开始帧1,头帧2,内容帧3
- 开始帧上有frame_method和frame_args对应消息的处理方法
- 头帧上有消息的属性,比如content_type,reply_to等,类似http头
- 内容帧上就是消息的context
写入帧是读取的逆过程,如下:
# ch23-celery/py-amqp-5.0.6/amqp/method_framing.py
def frame_writer(connection, transport,
pack=pack, pack_into=pack_into, range=range, len=len,
bytes=bytes, str_to_bytes=str_to_bytes, text_t=str):
"""Create closure that writes frames."""
# 输出,也就是之前的self.sock.sendall方法
write = transport.write
buffer_store = Buffer(bytearray(connection.frame_max - 8))
def write_frame(type_, channel, method_sig, args, content):
...
buf = buffer_store.buf
view = buffer_store.view
...
# ## FAST: pack into buffer and single write
frame = (b''.join([pack('>HH', *method_sig), args])
if type_ == 1 else b'')
framelen = len(frame)
# 第一帧
pack_into('>BHI%dsB' % framelen, buf, offset,
type_, channel, framelen, frame, 0xce)
offset += 8 + framelen
if body is not None:
frame = b''.join([
pack('>HHQ', method_sig[0], 0, len(body)),
properties,
])
framelen = len(frame)
# 方法帧
pack_into('>BHI%dsB' % framelen, buf, offset,
2, channel, framelen, frame, 0xce)
offset += 8 + framelen
bodylen = len(body)
if bodylen > 0:
framelen = bodylen
# 内容帧
pack_into('>BHI%dsB' % framelen, buf, offset,
3, channel, framelen, body, 0xce)
offset += 8 + framelen
write(view[:offset])
...- 写入的时候是准备好3个帧的二进制数据buf,一次性写入到socket
Message的序列化和反序列化,我们下一个环节,数据模型部分再行介绍。
amqp使用
了解AMQP协议传输相关的细节后,我们还是先从使用方法进入py-amqp。生产者发送消息是这样的:
import amqp
with amqp.Connection('broker.example.com') as c:
ch = c.channel()
ch.basic_publish(amqp.Message('Hello World'), routing_key='test')- 创建连接,并使用上下文包裹,这样可以自动关闭连接
- 从连接中创建channel
- 使用channel发送消息,至少包括消息文本和route
消费者消费消息是这样的:
import amqp
with amqp.Connection('broker.example.com') as c:
ch = c.channel()
def on_message(message):
print('Received message (delivery tag: {}): {}'.format(message.delivery_tag, message.body))
ch.basic_consume(queue='test', callback=on_message, no_ack=True)
while True:
c.drain_events()- 创建连接,也使用上下文包裹
- 一样从连接中创建channel
- 在channel上绑定消息的处理方法
- 消费消息至少指定queue,queue和发送时候的route要一致。也可以设置是否ack。
- 持续对连接进行事件监听
从示例可知发送和接收都需要使用Connection和Channel,消息体都使用Message对象。不同的是发送的时候使用publish方法,接收会复杂一点需要持续监听事件和使用consume方法。
AMQP模型
Connection
Connection主要有AbstractChannel基类和Connection类构成,比较奇怪的是Connection和Channel都继承自AbstractChannel。我个人觉得这种设计并不好,虽然可以通用Channel和Connection的一些操作。
+-----------------+
| AbstractChannel |
+-^-------------^-+
| |
+---+ |
| |
+-----+------+ +--+------+
| Connection | | Channel |
+------------+ +---------+Connection的构造函数:
class Connection(AbstractChannel):
def __init__(self, host='localhost:5672', userid='guest', password='guest',
login_method=None, login_response=None,
authentication=(),
virtual_host='/', locale='en_US', client_properties=None,
ssl=False, connect_timeout=None, channel_max=None,
frame_max=None, heartbeat=0, on_open=None, on_blocked=None,
on_unblocked=None, confirm_publish=False,
on_tune_ok=None, read_timeout=None, write_timeout=None,
socket_settings=None, frame_handler=frame_handler,
frame_writer=frame_writer, **kwargs):
self._connection_id = uuid.uuid4().hex
...
# 帧handler,读取帧
self.frame_handler_cls = frame_handler
# 帧写处理
self.frame_writer_cls = frame_writer
# 所有channel的字典
self.channels = {}
# The connection object itself is treated as channel 0
# 自己也是一个channel,ID是0,这样可以把所有message的操作统一到channel上
super().__init__(self, 0)
...connection最首要的是管理数据传输,由connect函数实现:
def connect(self, callback=None):
# Let the transport.py module setup the actual
# socket connection to the broker.
#
if self.connected:
return callback() if callback else None
try:
# 创建transport实例
self.transport = self.Transport(
self.host, self.connect_timeout, self.ssl,
self.read_timeout, self.write_timeout,
socket_settings=self.socket_settings,
)
self.transport.connect()
# 实例化读和写(因为读和写都是闭包)
self.on_inbound_frame = self.frame_handler_cls(
self, self.on_inbound_method)
self.frame_writer = self.frame_writer_cls(self, self.transport)
...
except (OSError, SSLError):
...connection还要负责一些连接相关的系统功能,比如连接状态的维护:
def _setup_listeners(self):
self._callbacks.update({
spec.Connection.Start: self._on_start,
spec.Connection.OpenOk: self._on_open_ok,
spec.Connection.Secure: self._on_secure,
spec.Connection.Tune: self._on_tune,
spec.Connection.Close: self._on_close,
spec.Connection.Blocked: self._on_blocked,
spec.Connection.Unblocked: self._on_unblocked,
spec.Connection.CloseOk: self._on_close_ok,
})
ef _on_start(self, version_major, version_minor, server_properties,
mechanisms, locales, argsig='FsSs'):
...
# 处理服务端的spec.Connection.Start消息
# 回应spec.Connection.StartOk到服务端
self.send_method(
spec.Connection.StartOk, argsig,
(client_properties, authentication.mechanism,
login_response, self.locale),
)
...
def send_method(self, sig,
format=None, args=None, content=None,
wait=None, callback=None, returns_tuple=False):
p = promise()
conn = self.connection
...
args = dumps(format, args) if format else ''
try:
# 写入数据
conn.frame_writer(1, self.channel_id, sig, args, content)
except StopIteration:
...
# TODO temp: callback should be after write_method ... ;)
if callback:
# 指向回调
p.then(callback)
p()
if wait:
# 等待回应
return self.wait(wait, returns_tuple=returns_tuple)
return p- 客户端收到服务端发来的spec.Connection.Start消息后,回应一个spec.Connection.StartOk消息
通过connection创建Channel:
Channel = Channel
def channel(self, channel_id=None, callback=None):
"""Create new channel.
Fetch a Channel object identified by the numeric channel_id, or
create that object if it doesn't already exist.
"""
...
try:
# channel_id 存在则从字典中获取
return self.channels[channel_id]
except KeyError:
# 不存在则新建一个channel实例
channel = self.Channel(self, channel_id, on_open=callback)
channel.open()
return channelChannel
Channel的构造方法如下:
class Channel(AbstractChannel):
def __init__(self, connection,
channel_id=None, auto_decode=True, on_open=None):
...
# 新建channelID
channel_id = connection._get_free_channel_id()
# 指定自己的channelID
super().__init__(connection, channel_id)
...
# 消息回调
self.callbacks = {}channel也需要初始化关于channel的系统调用,比如spec.Basic.Delive:
def _setup_listeners(self):
self._callbacks.update({
spec.Channel.Close: self._on_close,
spec.Channel.CloseOk: self._on_close_ok,
spec.Channel.Flow: self._on_flow,
spec.Channel.OpenOk: self._on_open_ok,
spec.Basic.Cancel: self._on_basic_cancel,
spec.Basic.CancelOk: self._on_basic_cancel_ok,
spec.Basic.Deliver: self._on_basic_deliver,
spec.Basic.Return: self._on_basic_return,
spec.Basic.Ack: self._on_basic_ack,
spec.Basic.Nack: self._on_basic_nack,
})
def _on_basic_deliver(self, consumer_tag, delivery_tag, redelivered,
exchange, routing_key, msg):
msg.channel = self
# 投递信息
msg.delivery_info = {
'consumer_tag': consumer_tag,
'delivery_tag': delivery_tag,
'redelivered': redelivered,
'exchange': exchange,
'routing_key': routing_key,
}
try:
fun = self.callbacks[consumer_tag]
except KeyError:
...
else:
fun(msg)先看看消息如何投递出去的:
def _basic_publish(self, msg, exchange='', routing_key='',
mandatory=False, immediate=False, timeout=None,
confirm_timeout=None,
argsig='Bssbb'):
...
try:
with self.connection.transport.having_timeout(timeout):
return self.send_method(
spec.Basic.Publish, argsig,
(0, exchange, routing_key, mandatory, immediate), msg
)
except socket.timeout:
...
basic_publish = _basic_publishsend_method在前面介绍spec.Connection.StartOk时候已经有过介绍。
消息的消费,需要先在connection保持监听:
def drain_events(self, timeout=None):
# read until message is ready
# 持续读,直到读取到message的ready状态
while not self.blocking_read(timeout):
pass
def blocking_read(self, timeout=None):
with self.transport.having_timeout(timeout):
# 读取帧
frame = self.transport.read_frame()
# 处理帧
return self.on_inbound_frame(frame)
def on_inbound_method(self, channel_id, method_sig, payload, content):
# on_inbound_frame的callback函数
...
# 交由对应的channel处理
return self.channels[channel_id].dispatch_method(
method_sig, payload, content,
)channel对message处理就很简单了,直到对应的listener,执行listener
def dispatch_method(self, method_sig, payload, content):
...
content.body = content.body.decode(content.content_encoding)
...
amqp_method = self._METHODS[method_sig]
listeners = [self._callbacks[method_sig]]
one_shot = self._pending.pop(method_sig)
args = []
if amqp_method.args:
args, _ = loads(amqp_method.args, payload, 4)
if amqp_method.content:
args.append(content)
for listener in listeners:
listener(*args)
...Message
Message继承自GenericContent:
+----------------+
| GenericContent |
+-------+--------+
^
|
|
+----+----+
| Message |
+---------+两个类都是比较简单的数据结构:
class Message(GenericContent):
# 消息头
PROPERTIES = [
('content_type', 's'),
('content_encoding', 's'),
('application_headers', 'F'),
('delivery_mode', 'o'),
('priority', 'o'),
('correlation_id', 's'),
('reply_to', 's'),
('expiration', 's'),
('message_id', 's'),
('timestamp', 'L'),
('type', 's'),
('user_id', 's'),
('app_id', 's'),
('cluster_id', 's')
]
def __init__(self, body='', children=None, channel=None, **properties):
super().__init__(**properties)
#: set by basic_consume/basic_get
self.delivery_info = None
self.body = body
self.channel = channel
class GenericContent:
"""Abstract base class for AMQP content.
Subclasses should override the PROPERTIES attribute.
"""
CLASS_ID = None
PROPERTIES = [('dummy', 's')]
def __init__(self, frame_method=None, frame_args=None, **props):
self.frame_method = frame_method
self.frame_args = frame_args
# 消息头
self.properties = props
self._pending_chunks = []
self.body_received = 0
self.body_size = 0
self.ready = False
def __getattr__(self, name):
# Look for additional properties in the 'properties'
# dictionary, and if present - the 'delivery_info' dictionary.
...
if name in self.properties:
# 从properties中获取
return self.properties[name]
...前文介绍的头帧数据,是这样反序列化到Message中的:
def decode_properties_basic(buf, offset):
"""Decode basic properties."""
properties = {}
flags, = unpack_from('>H', buf, offset)
offset += 2
if flags & 0x8000:
slen, = unpack_from('>B', buf, offset)
offset += 1
properties['content_type'] = pstr_t(buf[offset:offset + slen])
offset += slen
...
def _load_properties(self, class_id, buf, offset):
...
props, offset = PROPERTY_CLASSES[class_id](buf, offset)
self.properties = props
return offset
def inbound_header(self, buf, offset=0):
...
self._load_properties(class_id, buf, offset)
... 与反序列化对应的序列化方法主要是_serialize_properties实现,就不在赘述。
小结
本篇文章,我们围绕AMQP协议,理解在TCP的流上构建应用协议的三种方法: 定长、间隔和数据头 ;了解AMQP协议使用frame传输Message的方法: 使用开始帧,头帧和内容帧三个帧承载一个Message;了解AMQP中三个核心的概念: Connection, Channel和Message的实现,以及如何使用这3个概念实现消息发送和消费。
小技巧
channel使用下面的方法生成递增的不重复id:
>>> from array import array
>>> a=array('H', range(65535, 0, -1))
>>> a.pop()
1
>>> a.pop()
2
>>>一点题外话: 之前的文章,都叫源码阅读,主要觉得自己写的还不够。但是从搜索上看,源码解析更符合直觉,个人感觉最近的文章也有点进步,所以厚颜从本期开始都改名叫源码解析吧。
参考链接
- cpython文档 https://cython.org/#about
- amqp0-9-1协议 https://www.rabbitmq.com/resources/specs/amqp0-9-1.pdf
- struct二进制数据 https://docs.python.org/zh-cn/3/library/struct.html?highlight=struct#module-struct
- AMQP协议学习 https://zhuanlan.zhihu.com/p/147675691
- AMQP 0-9-1 Model Explained https://www.rabbitmq.com/tutorials/amqp-concepts.html