Werkzeug 源码阅读-下
Werkzeug是一个全面的WSGI Web应用程序库。它最初是WSGI实用程序各种工具的简单集合,现已成为最高级的WSGI实用程序库之一,是Flask背后的项目。Werkzeug 是一个德语单词,工具的意思。这个单词发音对我来说,有点困难(可能也是它知名度不高的重要因素之一),刚好官方logo是个锤子,我就简称“德国锤子”。文章计划分上下两篇,上篇介绍了 1)serving && wsgi 2)request && response 3)local的实现三个部分,下篇也分3个部分:
- middleware
- routing && urls
- datastructures
middleware
middleware中提供了下面6个示例:
| 名称 | 功能 |
|---|---|
| shared_data | 静态文件 |
| http_proxy | http连接的代理 |
| profiler | 性能检测 |
| proxy_fix | X-Forwarded-For |
| dispatcher | 多app支持 |
| lint | WSGI Protocol Linter |
SharedDataMiddleware
SharedDataMiddleware 可以支持css,image等静态文件及目录, 常用方法如下:
app = SharedDataMiddleware(app, {
'/static': os.path.join(os.path.dirname(__file__), 'static')
})从示例可以猜到,SharedDataMiddleware自动将http路径变成文件读取,基本就是 http.server 的功能。同时SharedDataMiddleware是一个类装饰器,传入app再返回app。类装饰器具主要就是 init 和 call 两个方法。
class SharedDataMiddleware:
def __init__(
self,
app: "WSGIApplication",
exports: t.Union[
t.Dict[str, t.Union[str, t.Tuple[str, str]]],
t.Iterable[t.Tuple[str, t.Union[str, t.Tuple[str, str]]]],
],
disallow: None = None,
cache: bool = True,
cache_timeout: int = 60 * 60 * 12,
fallback_mimetype: str = "application/octet-stream",
) -> None:
self.app = app
self.exports: t.List[t.Tuple[str, _TLoader]] = []
self.cache = cache
self.cache_timeout = cache_timeout
if isinstance(exports, dict):
exports = exports.items()
for key, value in exports:
...
if isinstance(value, str):
if os.path.isfile(value):
loader = self.get_file_loader(value)
else:
loader = self.get_directory_loader(value)
...
self.exports.append((key, loader))
...SharedDataMiddleware构造函数接收app和exports两个参数。其中exports可以是一个字典或者可迭代对象,对export中的文件路径,生成一个文件加载器。注意这里文件没有立即加载,而是有真实调用的时候才会加载。
call方法负责请求的响应:
def __call__(
self, environ: "WSGIEnvironment", start_response: "StartResponse"
) -> t.Iterable[bytes]:
path = get_path_info(environ)
file_loader = None
for search_path, loader in self.exports:
if search_path == path:
real_filename, file_loader = loader(None)
if file_loader is not None:
break
...
guessed_type = mimetypes.guess_type(real_filename) # type: ignore
mime_type = get_content_type(guessed_type[0] or self.fallback_mimetype, "utf-8")
f, mtime, file_size = file_loader()
headers = [("Date", http_date())]
if self.cache:
timeout = self.cache_timeout
etag = self.generate_etag(mtime, file_size, real_filename) # type: ignore
headers += [
("Etag", f'"{etag}"'),
("Cache-Control", f"max-age={timeout}, public"),
]
if not is_resource_modified(environ, etag, last_modified=mtime):
f.close()
start_response("304 Not Modified", headers)
return []
headers.append(("Expires", http_date(time() + timeout)))
else:
headers.append(("Cache-Control", "public"))
headers.extend(
(
("Content-Type", mime_type),
("Content-Length", str(file_size)),
("Last-Modified", http_date(mtime)),
)
)
start_response("200 OK", headers)
return wrap_file(environ, f)- 根据request(wsgi.environ)的路径,去加载文件
- 生成文件的http头,包括Date(服务器时间), Content-Type(MIME类型), Last-Modified(文件最后修改时间)...
- 直接返回文件的包装器
这里有2个小细节:
- 匹配上正确文件后,是直接返回,并未经过app处理
- 默认支持浏览器的本地cache,通过http头的Etag,Cache-Control和Expires控制。
ProxyMiddleware
ProxyMiddleware使用如下:
app = ProxyMiddleware(app, {
"/static/": {
"target": "http://127.0.0.1:5001/",
}
}从使用方式可以推测将/static/的url代理到 http://127.0.0.1:5001服务。http代理的主要实现过程如下:
from http import client
con = client.HTTPConnection(
host, target.port or 80, timeout=self.timeout
)
con.connect()
remote_url = url_quote(remote_path)
querystring = environ["QUERY_STRING"]
if querystring:
remote_url = f"{remote_url}?{querystring}"
con.putrequest(environ["REQUEST_METHOD"], remote_url, skip_host=True)
for k, v in headers:
con.putheader(k, v)
con.endheaders()
stream = get_input_stream(environ)
while True:
data = stream.read(self.chunk_size)
if not data:
break
if chunked:
con.send(b"%x\r\n%s\r\n" % (len(data), data))
else:
con.send(data)
resp = con.getresponse()
start_response(
f"{resp.status} {resp.reason}",
[
(k.title(), v)
for k, v in resp.getheaders()
if not is_hop_by_hop_header(k)
],
)
def read() -> t.Iterator[bytes]:
while True:
try:
data = resp.read(self.chunk_size)
except OSError:
break
if not data:
break
yield data
return read()- 代理创建远程服务的http连接
- 代理向远程服务发送http头
- 读取客户端请求中的body部分,转发到远程服务
- 代理从远程服务获取取response
- 获取远程服务http状态码和响应头信息,返回给客户端请求的response
- 包装远程服务的body读取方法返回给调用者
学会了ProxyMiddleware就知道了如何实现一个简单的http代理服务,科学上网的逻辑也就懂了。
ProfilerMiddleware
ProfilerMiddleware展示了如何对代码进行性能测试。主要是使用 profile.runcall 方法,因为该方法没有返回值,所以使用一个临时的列表response_body和catching_start_response中转一下。
<pre data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: def __call__(
self, environ: "WSGIEnvironment", start_response: "StartResponse"
) -> t.Iterable[bytes]:
response_body: t.List[bytes] = []
def catching_start_response(status, headers, exc_info=None): # type: ignore
start_response(status, headers, exc_info)
return response_body.append
def runapp() -> None:
app_iter = self._app(
environ, t.cast("StartResponse", catching_start_response)
)
response_body.extend(app_iter)
profile = Profile()
start = time.time()
profile.runcall(runapp)
body = b"".join(response_body)
elapsed = time.time() - start
...
return [body]其它几个Middleware就不再详细介绍了,我们再进一步了解一下个Middleware的模型: 洋葱模型
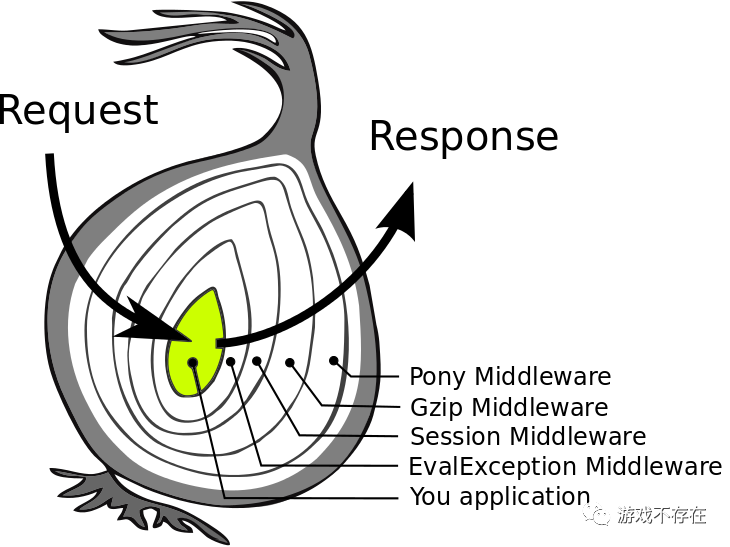
请求像剥洋葱一样,一层层到达应用程序核心,然后再逐层包装返回响应。换成下面的装饰器调用过程,就很好理解了:
# 装饰器方式
@cache
@count_calls
def fibonacci(num):
if num < 2:
return num
return fibonacci(num - 1) + fibonacci(num - 2)
# 实际函数调用方式
cache(count_calls(fibonacci(num)))目标函数被装饰器逐层包裹调用,每个装饰器层都可以对requst和response各进行一次处理。
routing
routring是非常重要的模块,下面是routing的使用示例:
from werkzeug.routing import Map, Rule, NotFound, RequestRedirect
url_map = Map([
Rule('/', endpoint='blog/index'),
Rule('/<int:year>/', endpoint='blog/archive'),
Rule('/<int:year>/<int:month>/', endpoint='blog/archive'),
Rule('/<int:year>/<int:month>/<int:day>/', endpoint='blog/archive'),
Rule('/<int:year>/<int:month>/<int:day>/<slug>', endpoint='blog/show_post'),
Rule('/about', endpoint='blog/about_me'),
Rule('/feeds/', endpoint='blog/feeds'),
Rule('/feeds/<feed_name>.rss', endpoint='blog/show_feed')
])
...
def application(environ, start_response):
urls = url_map.bind_to_environ(environ)
try:
endpoint, args = urls.match()
except HTTPException, e:
return e(environ, start_response)
response = =getattr(self, f"on_{endpoint}")(request, **args)
return response(environ, start_response)- 应用程序的所有路由规则都使用一个Map对象管理,Map对象的主要参数是一个Rule数组。
- Rule包括url的规则和端点endpoint。
- 每个http请求使用Map对象的bind_to_environ得到一组urls(MapAdapter对象)。
- 使用urls的match方法匹配到endpoint和rule的url规则中定义的参数,例如:/int:year/int:month/会得到(year, month)这样2个参数的元组。
- 使用端点endpoint查找对应的handerl函数(Front-Control模式)。
- ...
Rule对象的构造函数和示例一样,主要是rule规则的string定义和监听函数的端点endpoint两个参数:
class Rule(RuleFactory):
def __init__(
self,
string: str,
defaults: t.Optional[t.Mapping[str, t.Any]] = None,
subdomain: t.Optional[str] = None,
methods: t.Optional[t.Iterable[str]] = None,
build_only: bool = False,
endpoint: t.Optional[str] = None,
strict_slashes: t.Optional[bool] = None,
merge_slashes: t.Optional[bool] = None,
redirect_to: t.Optional[t.Union[str, t.Callable[..., str]]] = None,
alias: bool = False,
host: t.Optional[str] = None,
websocket: bool = False,
) -> None:
self.rule = string
...
self.endpoint: str = endpoint # type: ignore
...
self.arguments = set()
...继续看Map对象的构造函数:
class Map:
def __init__(
self,
rules: t.Optional[t.Iterable[RuleFactory]] = None,
default_subdomain: str = "",
charset: str = "utf-8",
strict_slashes: bool = True,
merge_slashes: bool = True,
redirect_defaults: bool = True,
converters: t.Optional[t.Mapping[str, t.Type[BaseConverter]]] = None,
sort_parameters: bool = False,
sort_key: t.Optional[t.Callable[[t.Any], t.Any]] = None,
encoding_errors: str = "replace",
host_matching: bool = False,
) -> None:
self._rules: t.List[Rule] = []
...
self.converters = self.default_converters.copy()
...
for rulefactory in rules or ():
self.add(rulefactory)重头戏在Map对象的add方法:
def add(self, rulefactory: RuleFactory) -> None:
"""Add a new rule or factory to the map and bind it. Requires that the
rule is not bound to another map.
:param rulefactory: a :class:`Rule` or :class:`RuleFactory`
"""
for rule in rulefactory.get_rules(self):
rule.bind(self)
self._rules.append(rule)
self._rules_by_endpoint.setdefault(rule.endpoint, []).append(rule)
self._remap = Truerule.bind主要工作就是对rule进行预先编译,提高查询时候的正则匹配速度, 这一部分比较复杂,我们暂时跳过,知道是将 /<int:year>/<int:month>/<int:day>/ 这样的规则,编译生成对应的正则表达式即可。
请求的rule匹配过程是下面这样,首先从environ中解析出path,method和query_string三个重要的信息,生成一个MapAdapter对象:
def bind_to_environ(
self,
environ: "WSGIEnvironment",
server_name: t.Optional[str] = None,
subdomain: t.Optional[str] = None,
) -> "MapAdapter":
...
path_info = _get_wsgi_string("PATH_INFO")
query_args = _get_wsgi_string("QUERY_STRING")
default_method = environ["REQUEST_METHOD"]
server_name = server_name.lower()
try:
server_name = _encode_idna(server_name) # type: ignore
except UnicodeError:
raise BadHost()
return MapAdapter(
self,
server_name,
script_name,
subdomain,
url_scheme,
path_info,
default_method,
query_args,
)然后调用MapAdapter对象的match方法:
def match(
self,
path_info: t.Optional[str] = None,
method: t.Optional[str] = None,
return_rule: bool = False,
query_args: t.Optional[t.Union[t.Mapping[str, t.Any], str]] = None,
websocket: t.Optional[bool] = None,
) -> t.Tuple[t.Union[str, Rule], t.Mapping[str, t.Any]]:
...
for rule in self.map._rules:
try:
rv = rule.match(path, method)
except RequestPath as e:
raise RequestRedirect(
self.make_redirect_url(
url_quote(e.path_info, self.map.charset, safe="/:|+"),
query_args,
)
)
except RequestAliasRedirect as e:
raise RequestRedirect(
self.make_alias_redirect_url(
path, rule.endpoint, e.matched_values, method, query_args
)
)
if rv is None:
continue
...
return rule.endpoint, rvmatch过程比较简单,就是对所有的rule进行循环,使用rule的math方法判断是否和path和method匹配:
def match(
self, path: str, method: t.Optional[str] = None
) -> t.Optional[t.MutableMapping[str, t.Any]]:
m = self._regex.search(path)
if m is not None:
groups = m.groupdict()
...
result = {}
for name, value in groups.items():
try:
value = self._converters[name].to_python(value)
except ValidationError:
return None
result[str(name)] = value
return result- 使用正则表达式搜素path是否匹配
- 匹配上的rule将query_string解析出rule参数,这个过程由Converter处理,因为url上都是字符串,需要将字符串转换成具体的类型,比如int。
Converter种类如下表:
| 类型 | 名称 |
|---|---|
| default | UnicodeConverter |
| string | UnicodeConverter |
| any | AnyConverter |
| path | PathConverter |
| int | IntegerConverter |
| float | FloatConverter |
| uuid | UUIDConverter |
简单介绍一下NumberConverter,主要是其to_python方法, 判断是否符合极限值要求,然后强转成int类型数据:
class NumberConverter(BaseConverter):
regex = r"\d+"
num_convert: t.Callable = int
def to_python(self, value: str) -> t.Any:
if self.fixed_digits and len(value) != self.fixed_digits:
raise ValidationError()
value = self.num_convert(value)
if (self.min is not None and value < self.min) or (
self.max is not None and value > self.max
):
raise ValidationError()
return value
...Converter的使用可以配合业务函数理解, 对于 /1001 这样的URL,解析出其中的 short_id=1001 参数:
# /1001
# Rule("/<short_id>", endpoint="follow_short_link"),
def on_follow_short_link(self, request, short_id):
link_target = self.redis.get(f"url-target:{short_id}")
if link_target is None:
raise NotFound()
self.redis.incr(f"click-count:{short_id}")
return redirect(link_target)http的路由处理还有一种使用前缀树实现的方案,比这里使用复杂度为 N 的一次循环算法要更高效,等以后讲解gin框架的时候再介绍。
datastructures
datastructures中的数据结构比较多,我简单整理出下面几个类,其余的类都是以下面的类为基础,组合而来:
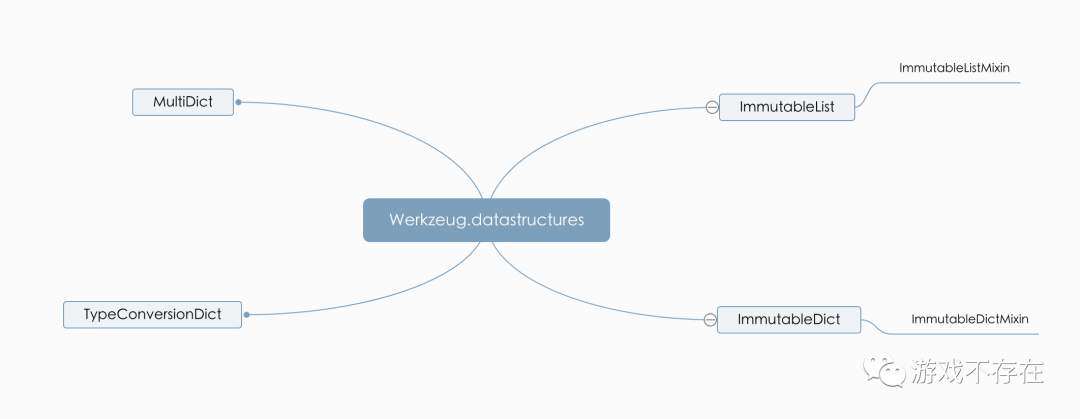
datastructures主要就是处理请求解析后的数据,比如Header,Accept都是不可变的数据,这样保证业务使用的不会被误操作。不可变操作是通过 is_immutabl 函数实现:
def is_immutable(self):
raise TypeError(f"{type(self).__name__!r} objects are immutable")其实也非常简单,就是如果要改变数据,就抛出异常,这样就保证了数据是不可变的。
ImmutableList&ImmutableDict
不可变列表ImmutableList使用Mixin方式,其中ImmutableListMixin主要代码如下:
class ImmutableListMixin:
_hash_cache = None
def __hash__(self):
if self._hash_cache is not None:
return self._hash_cache
rv = self._hash_cache = hash(tuple(self))
return rv
def __delitem__(self, key):
is_immutable(self)
...
def append(self, item):
is_immutable(self)
...
def sort(self, key=None, reverse=False):
is_immutable(self)- ImmutableListMixin的hash方法被覆盖,hash值来自元祖化的对象,元祖是不可变的,这样对象的hash也是确定的。因为不可变,所以只需要计算一次,以后都使用cache。
- 所有的改变数据的操作,包括魔法函数,append,甚至是原地排序等都使用is_immutable抛出异常。
ImmutableList只需要组合ImmutableListMixin和list,不需要额外的实现,非常简单:
class ImmutableList(ImmutableListMixin, list):
...ImmutableDict和ImmutableList类似,只是将list换成dict。
TypeConversionDict
TypeConversionDict主要是对数据类型转换:
class TypeConversionDict(dict):
def get(self, key, default=None, type=None):
try:
rv = self[key]
except KeyError:
return default
if type is not None:
try:
# 类型转换
rv = type(rv)
except ValueError:
rv = default
return rv结合示例,非常容易理解:
>>> d = TypeConversionDict(foo='42', bar='blub')
>>> d.get('foo', type=int)
42
>>> d.get('bar', -1, type=int)
-1MultiDict
MultiDict是一个字典,字典的值使用列表存储。所以一个key可以由多个值,下面是它的构造函数和add方法:
class MultiDict(TypeConversionDict):
def __init__(self, mapping=None):
if isinstance(mapping, MultiDict):
dict.__init__(self, ((k, l[:]) for k, l in mapping.lists()))
elif isinstance(mapping, dict):
tmp = {}
for key, value in mapping.items():
if isinstance(value, (tuple, list)):
if len(value) == 0:
continue
value = list(value)
else:
value = [value]
tmp[key] = value
dict.__init__(self, tmp)
else:
tmp = {}
for key, value in mapping or ():
tmp.setdefault(key, []).append(value)
dict.__init__(self, tmp)
def add(self, key, value):
dict.setdefault(self, key, []).append(value)
结合MultiDict的示例感受一下:
>>> d = MultiDict([('a', 'b'), ('a', 'c')])
>>> d
MultiDict([('a', 'b'), ('a', 'c')])
>>> d['a']
'b'
>>> d.getlist('a')
['b', 'c']
>>> 'a' in d
True也许还是有疑惑,这种字典有什么用呢?我贴一个http请求的Request-Headers:
...
accept-language: en,zh;q=0.9,zh-TW;q=0.8,zh-CN;q=0.7
...这里的_accept-language_就是包括多个参数, 需要使用MultiDict这样的数据结构存储。
datastructures中的其它数据结构,大多是使用上面几个类演变组合而来,就不在赘述。
小结
本章我们知道“德国锤子”的middleware的核心机制来自装饰器,同时简单了解静态文件,http代理和性能分析三个Middleware的实现;了解路由使用单循环遍历的正则匹配来实现,路由参数如何解析;了解了一些使用特定的数据结构,来处理http头中的一些细节。
小技巧
在datastructures中的iter_multi_items函数对数据进行迭代,有使用 yield 关键字 和 yield from 语句:
def iter_multi_items(mapping):
if isinstance(mapping, MultiDict):
yield from mapping.items(multi=True)
elif isinstance(mapping, dict):
for key, value in mapping.items():
if isinstance(value, (tuple, list)):
for v in value:
yield key, v
else:
yield key, value
else:
yield from mapping这里简单介绍一下这两点。yield 关键字可以简单理解成一个函数的暂停。通常一个函数执行后通过return返回,中途不可更改。使用 yield 后就有了暂停和外界交互的能力:
def unlimit_generator():
i = 0
while i is not None:
yield i
i+=1比如上面这个无限生成器,可以在函数返回前输出0和任意正整数,这是使用range无法做到的。
同样是生成数据的迭代器,下面是输出0~20,使用2个迭代器分别输出:
def generator2():
for i in range(10):
yield i
def generator3():
for j in range(10, 20):
yield j仅仅使用 yield关键字的话,要这样编写实现:
def generator():
for i in generator2():
yield i
for j in generator3():
yield j使用 yield from 语句后代码就非常简洁:
def generator():
yield from generator2()
yield from generator3()yield from 在python3的协程中也有体现,这里大家可以先好好体会一下
参考链接
- How to Use Generators and yield in Python https://realpython.com/introduction-to-python-generators/
- Python 3: Using "yield from" in Generators http://simeonvisser.com/posts/python-3-using-yield-from-in-generators-part-1.html