常用命令实现
COMMAND
本节来看看在 里面一些常见的命令是如何实现的,它们都是用户程序,封装系统调用而成,大多数都很简单,一眼过去就能懂那种,来看:
echo
命令将紧跟其后的参数当作字符串打印出来
int main(int argc, char *argv[])
{
int i;
for(i = 1; i < argc; i++) //从第一个参数开始循环(0起始)
printf(1, "%s%s", argv[i], i+1 < argc ? " " : "\n"); //将参数作为字符串打印出来,最后一个参数后面打印一个换行符
exit(); //执行完之后退出
}cat
用来查看文件内容
void cat(int fd)
{
int n;
while((n = read(fd, buf, sizeof(buf))) > 0) { //读取fd指向的文件的内容
if (write(1, buf, n) != n) { //输出到屏幕
printf(1, "cat: write error\n");
exit();
}
}
if(n < 0){ //读写的字节数小于0,出错了
printf(1, "cat: read error\n");
exit();
}
}函数接受一个参数文件描述符,然后读取这个文件描述符指向的文件,将其内容输出到屏幕。其主函数:
int main(int argc, char *argv[])
{
int fd, i;
if(argc <= 1){ //如果没有参数
cat(0); //从键盘获取输入
exit(); //执行完后退出
}
for(i = 1; i < argc; i++){ //从第一个参数开始循环(0起始)
if((fd = open(argv[i], 0)) < 0){ //打开文件
printf(1, "cat: cannot open %s\n", argv[i]);
exit();
}
cat(fd); //调用cat读取文件并输出
close(fd); //关闭文件
}
exit(); //执行完后退出
}wc
用来统计输出文件的行数,单词数,字节数
char buf[512];
void wc(int fd, char *name)
{
int i, n;
int l, w, c, inword;
l = w = c = 0;
inword = 0;
while((n = read(fd, buf, sizeof(buf))) > 0){ //从fd指向的文件中读取数据
for(i=0; i<n; i++){ //读取了多少个字符,循环多少次
c++;
if(buf[i] == '\n') //有换行
l++; //行数加1
if(strchr(" \r\t\n\v", buf[i])) //有空白字符
inword = 0;
else if(!inword){
w++; //单词数加1
inword = 1;
}
}
}
if(n < 0){ //没有读取到字符
printf(1, "wc: read error\n");
exit();
}
printf(1, "%d %d %d %s\n", l, w, c, name); //打印 行数,单词数,字节数,名字
}统计行数就是看换行符的个数,单词数看空白字符,字节数嗯就是字节数(废话学),其主函数:
int main(int argc, char *argv[])
{
int fd, i;
if(argc <= 1){ //如果参数≤1
wc(0, ""); //从键盘获取输入
exit(); //执行完退出
}
for(i = 1; i < argc; i++){ //从第一个参数开始循环(0起始)
if((fd = open(argv[i], 0)) < 0){ //打开参数指向的文件
printf(1, "wc: cannot open %s\n", argv[i]);
exit();
}
wc(fd, argv[i]); //调用wc函数统计这个文件
close(fd); //关闭文件描述符
}
exit(); //执行完后退出
}ls
用来显示文件信息
void ls(char *path) //显示这个路径指示的文件信息
{
char buf[512], *p;
int fd;
struct dirent de;
struct stat st;
if((fd = open(path, 0)) < 0){ //打开文件
printf(2, "ls: cannot open %s\n", path);
return;
}
if(fstat(fd, &st) < 0){ //获取这个文件信息
printf(2, "ls: cannot stat %s\n", path);
close(fd);
return;
}
switch(st.type){ //如果是普通文件,直接输出
case T_FILE:
printf(1, "%s %d %d %d\n", fmtname(path), st.type, st.ino, st.size);
break;
case T_DIR: //如果是目录文件,输出其下的文件信息
if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){ //判断路径是否对头,buf 512字节,正常情况不会超过
printf(1, "ls: path too long\n");
break;
}
strcpy(buf, path); //将参数复制一份到buf
p = buf+strlen(buf); //p现在应指向参数路径的末尾
*p++ = '/'; //末尾赋为'/'
while(read(fd, &de, sizeof(de)) == sizeof(de)){ //读取目录项
if(de.inum == 0) //inode编号为0 continue(inode编号从1开始)
continue;
memmove(p, de.name, DIRSIZ); //复制一份文件名字到p,形成新路径,这个路径指向目录下的一个文件
p[DIRSIZ] = 0; //截止处理
if(stat(buf, &st) < 0){ //获取这个文件的状态信息
printf(1, "ls: cannot stat %s\n", buf); //打印错误消息
continue;
}
printf(1, "%s %d %d %d\n", fmtname(buf), st.type, st.ino, st.size); //打印文件信息
}
break;
}
close(fd); //关闭文件
}看着很多,其实也简单,打开路径指示的文件,如果这是个普通文件,直接输出文件状态信息,如果是个目录文件,那么就输出目录下的文件信息。
char* fmtname(char *path)
{
static char buf[DIRSIZ+1];
char *p;
//找到最后一个 / 之后的第一个字符
for(p=path+strlen(path); p >= path && *p != '/'; p--)
;
p++;
if(strlen(p) >= DIRSIZ) //超过了文件名的长度
return p;
memmove(buf, p, strlen(p)); //复制文件名
memset(buf+strlen(p), ' ', DIRSIZ-strlen(p)); //后面空余字节补为' '
return buf;
}这个函数就是将路径转化为最后一个文件名,比如,"/a/b/c",那这个函数就转化为 "c "(后面有空格字符补齐)。最后来看其主函数:
int main(int argc, char *argv[])
{
int i;
if(argc < 2){ //如果参数个数小于2,也就是没有参数,只有一个程序名
ls("."); //那就显示当前目录下的文件信息
exit();
}
for(i=1; i<argc; i++) //对每个参数(文件)调用ls
ls(argv[i]);
exit(); //执行完后退出
}grep
用来搜索文本,并把匹配的行打印出来。 的难点在于正则表达式,这里只实现了 ^ $ . * 四种元字符。关于正则表达式的算法我就不细讲了,可以参考有关正则表达式的算法实现,比如 第 10 题。来看 里的实现
首先是两个匹配函数
int matchhere(char* re, char* text);
int matchstar(int c, char* re, char* text);匹配规则 和文本 , 是处理 * 的情况,参数 是 * 前面那个字符,来看实现函数:
int matchhere(char *re, char *text)
{
if(re[0] == '\0') //规则匹配到结尾了,说明匹配成功返回1
return 1;
if(re[1] == '*') //碰到*,调用matchstar处理
return matchstar(re[0], re+2, text);
if(re[0] == '$' && re[1] == '\0') //规则到结尾了且是$结尾
return *text == '\0'; //如果文本也到结尾了,匹配成功
if(*text!='\0' && (re[0]=='.' || re[0]==*text)) //普通情况,如果规则是.或者单个字符匹配成功
return matchhere(re+1, text+1); //规则和文本都向后移,匹配下一个字符
return 0;
}如果规则匹配到头了,说明匹配成功返回 1
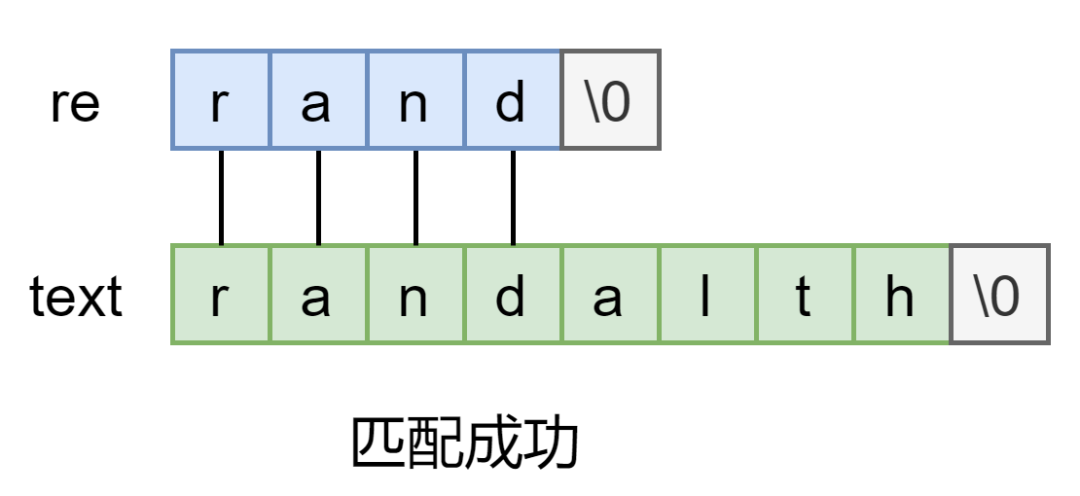
* 是和前面那个字符绑定在一起的,所以直接判断 是否是 *,如果是调用 处理,后面再说
如果规则匹配到末尾了且最后一个规则是 $,则检测文本是否也匹配到末尾了
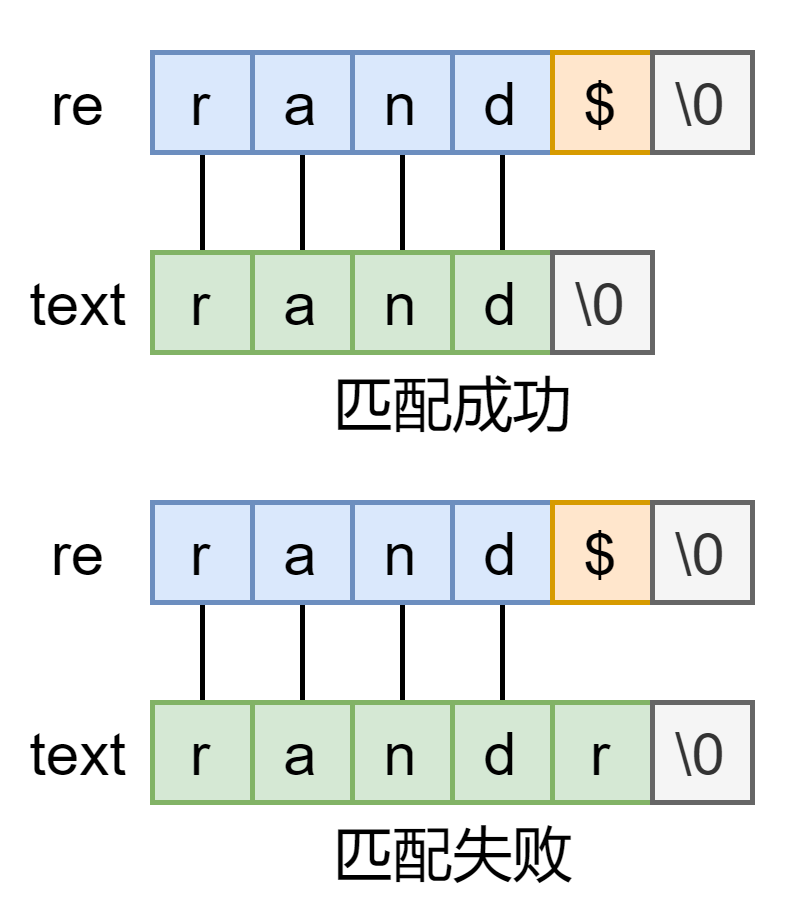
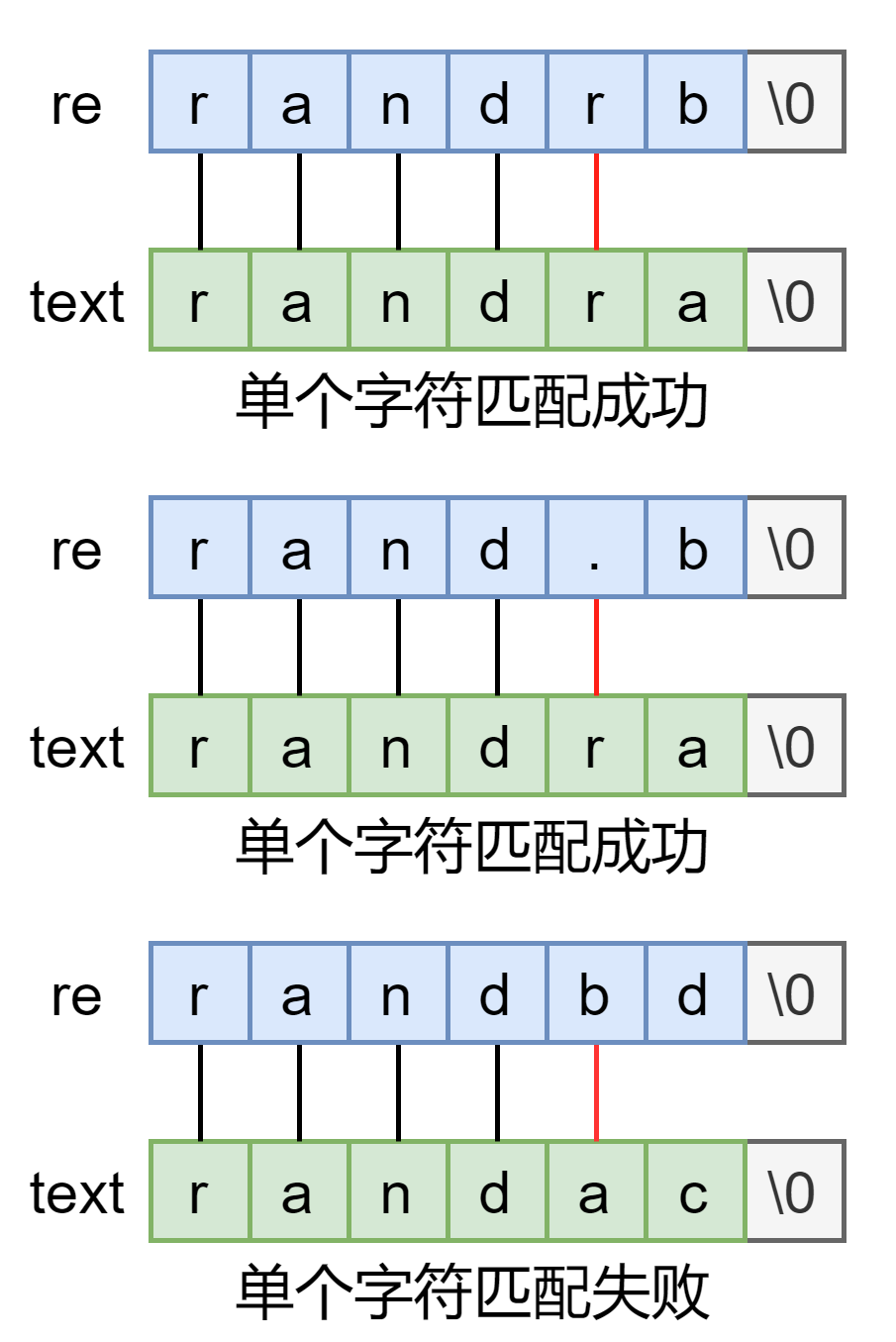
* 组合出现,匹配算法还是很容易的,. 就是当作任意字符来看,$ 就是额外检查文本是否也匹配到末尾了。来看复杂点的 * 处理过程:
int matchstar(int c, char *re, char *text)
{
do{
if(matchhere(re, text)) //第一次执行为*匹配0次,没执行依次*匹配次数加1
return 1;
}while(*text!='\0' && (*text++==c || c=='.')); //*前面字符匹配多次的情况
return 0;
}* 就是指前面的字符可以匹配 0 次或多次,do-while 循环第一次执行就是匹配 0 次的情况,后续再次执行循环体的话就是匹配多次的情况
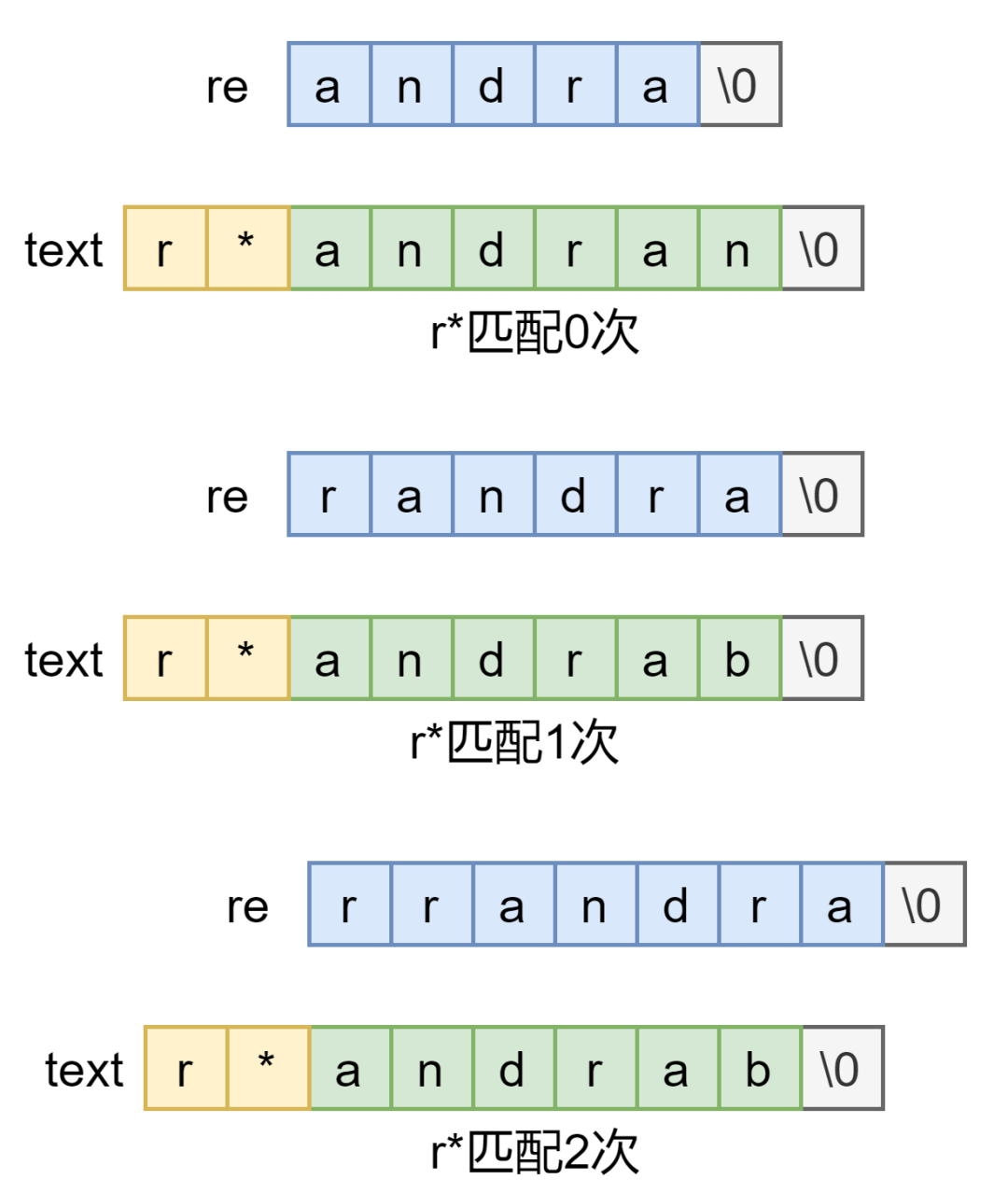
* 元字符,找几个简单例子模拟一下应该也多大问题,到此还有个 ^ 匹配开头没有处理,来看:
int match(char *re, char *text)
{
if(re[0] == '^') //若有^元字符
return matchhere(re+1, text); //规则后移,文本不动
do{ // must look at empty string
if(matchhere(re, text)) //调用matchhere匹配
return 1;
}while(*text++ != '\0'); //匹配失败的话文本后移再次匹配
return 0;
}^ 用来匹配开头边界, 函数中直接将规则后移就是了,文本不需要动,因为后面会看到 调用 函数时,传的 本身就是一行数据的开头,所以这里 函数就不用特殊处理了
普通情况就是一个个暴力的匹配:
上述就是匹配算法,下面来看实际的 函数
void grep(char *pattern, int fd)
{
int n, m;
char *p, *q;
m = 0;
while((n = read(fd, buf+m, sizeof(buf)-m-1)) > 0){ //读取文件内容
m += n; //记录已读的字节数
buf[m] = '\0'; //截止处理
p = buf; //buf首地址赋给p
while((q = strchr(p, '\n')) != 0){ //检查刚读取的这段数据是否有换行,有的话
*q = 0; //其位置上的字符置0,因为match函数以0评判是否为结尾
if(match(pattern, p)){ //匹配这一行的文本
*q = '\n'; //匹配成功的话,重新变成换行符
write(1, p, q+1 - p); //并且打印这行
}
p = q+1; //p指向下一行首字符地址
} //重复上述操作
if(p == buf) //如果读取的这段数据一个换行符都没有
m = 0; //m置0重复操作
if(m > 0){ //读取的这段数据中,p之前的已经匹配处理过了,
m -= p - buf; //计算已经处理多少文本
memmove(buf, p, m); //把p之前的文本移出去
}
}
}函数应该要简单的多,有详细注释就不再多说,来看最后的 函数
int main(int argc, char *argv[])
{
int fd, i;
char *pattern;
if(argc <= 1){ //grep pattern [file] 至少两个参数,1个参数出错了
printf(2, "usage: grep pattern [file ...]\n");
exit();
}
pattern = argv[1];
if(argc <= 2){ //grep pattern 没有指定文件,那么就读取控制台文件
grep(pattern, 0);
exit();
}
for(i = 2; i < argc; i++){ //grep patter file1 file2 ...
if((fd = open(argv[i], 0)) < 0){ //打开文件
printf(1, "grep: cannot open %s\n", argv[i]);
exit();
}
grep(pattern, fd); //匹配模式串和文本
close(fd); //关闭文件
} //重复上述操作
exit(); //完成之后退出
}命令就到这里,相比其他命令这个的却要难一些,主要是在匹配算法那一块儿,我不讲算法只是简单地说了说,不太清楚的话,可以尝试着举简单例子模拟作为突破口,也可以先去看看一些关于正则表达式的算法题。
kill
kill pid,杀死进程号为 的进程
int main(int argc, char *argv[])
{
int fd, i;
char *pattern;
if(argc <= 1){ //grep pattern [file] 至少两个参数,1个参数出错了
printf(2, "usage: grep pattern [file ...]\n");
exit();
}
pattern = argv[1];
if(argc <= 2){ //grep pattern 没有指定文件,那么就读取控制台文件
grep(pattern, 0);
exit();
}
for(i = 2; i < argc; i++){ //grep patter file1 file2 ...
if((fd = open(argv[i], 0)) < 0){ //打开文件
printf(1, "grep: cannot open %s\n", argv[i]);
exit();
}
grep(pattern, fd); //匹配模式串和文本
close(fd); //关闭文件
} //重复上述操作
exit(); //完成之后退出
}很简单,就是调用 这个系统调用,详见[深入理解进程三之大杂烩]
ln
n src dst, 文件和 文件建立硬链接
int
main(int argc, char *argv[])
{
if(argc != 3){ //ln src dst,至少三个参数
printf(2, "Usage: ln old new\n");
exit();
}
if(link(argv[1], argv[2]) < 0) //调用link系统调用建立硬链接
printf(2, "link %s %s: failed\n", argv[1], argv[2]);
exit(); //执行完后退出
}也特简单,就是调用 这个系统调用,有问题详见[了解文件系统调用吗?如何实现的?]
mkdir
mkdir dirname 用来创建目录, 实际应是一个路径。
int main(int argc, char *argv[])
{
int i;
if(argc < 2){ //mkdir dirname1 至少两个参数
printf(2, "Usage: mkdir files...\n");
exit();
}
for(i = 1; i < argc; i++){ //mkdir name1 name2
if(mkdir(argv[i]) < 0){ //调用mkdir创建目录
printf(2, "mkdir: %s failed to create\n", argv[i]);
break;
}
} //重复上述操作
exit(); //完成后退出
}同样的直接调用 创建目录文件,详见[了解文件系统调用吗?如何实现的?]
rm
rm filepath 用来删除一个文件
int main(int argc, char *argv[])
{
int i;
if(argc < 2){ //rm filepath 至少两个参数
printf(2, "Usage: rm files...\n");
exit();
}
for(i = 1; i < argc; i++){
if(unlink(argv[i]) < 0){ //调用unlink"删除"文件
printf(2, "rm: %s failed to delete\n", argv[i]);
break;
}
}
exit(); //执行完后退出
}直接调用 来"删除"一个文件,但实际上在[了解文件系统调用吗?如何实现的?] 一文中,我们说过,只有一个文件的链接数,引用数都为 0 的时候才会真正地将一个文件删除,当时还在 下做了一个实验,详情见前文。
上述就是 中一些命令的实现,很简单,大多数就是调用现成的系统调用就能完成工作,配上详细的注释应该是一眼就能懂什么意思。稍微困难些的就是 命令,涉及到递归思想的是稍微要困难点,多看几遍问题应该也不大
好了本文就到这里,有什么问题还请批评指正,也欢迎大家来同我讨论交流学习进步。