SHELL 如何实现?
SHELL
诸位应该很熟悉,它获取控制台的输入,然后执行一定的任务,实现人机交互。本文主要通过 来看看如何实现一个简单的 , 实现分为两个主要步骤,一解析输入的命令字符串,二执行命令。
在说 实现之前先来看看 支持的两种机制,重定向和管道
重定向
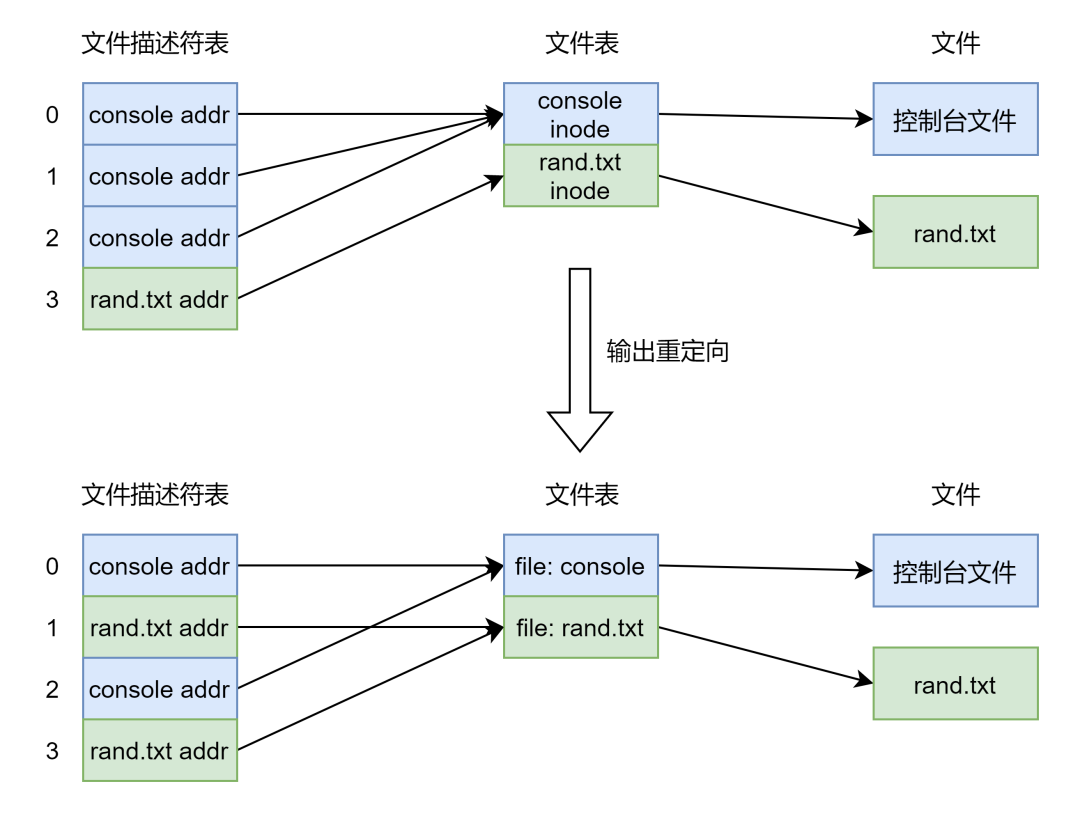
重定向依赖于文件描述符这层抽象和 的实现机制。在[捋一捋控制台的输入输出] 中,我们知道了计算机启动时 进程创建了一个控制台文件,此时文件表中有一个控制台文件结构体,文件描述符 0 指向这个结构体,然后 dup(0) 两次创建了文件描述符 1、2,使得它俩也指向控制台文件结构体。所以使用文件描述符 0、1、2 读写数据就是读写控制台文件,也就是常说的标准输入/输出/错误,这也是一切皆文件思想的运用。
会复制一份进程的文件描述符表,所有进程都可以看作是 进程的子进程,所以每个进程至少都有三个文件描述符,0、1、2,分别表示标准输入,标准输出,标准错误。而我们一般常说的重定向就是改变文件描述符 0、1、2 的指向,比如说 echo hello world > rand.txt 就会使得文件描述符 1 指向 rand.txt 文件结构体,如此再向文件描述符 1 指向的文件写入数据时便不会输出到屏幕,而是将数据写到了 rand.txt 文件。
具体怎样实现的呢?直接来看个简单的代码示意:
char *argv[4] = {"ehco", "hello", "world", "0"};
if(fork() == 0){
close(1); //关闭文件描述符1
open("rand.txt", O_WRONLY|O_CREATE); //打开/创建rand.txt文件,其描述符应该是1
exec("echo", argv); //执行echo程序
}这个命令我们后面会说实现,正常情况下就是将参数标准输出到屏幕,但是重定向就不一样了。我们把文件描述符 1 给关闭了,文件描述符 1 就空闲出来了,每次分配文件描述符时都是从最小的分配,所以打开文件 时分配的文件描述符就是 1,也就是说,现在文件描述符 1 不再指向控制台文件,它指向 这个文件。图示如下:
管道
管道吧使用命令的时候经常用到这个机制,使用 | 来表示,管道左侧命令运行的结果作为右侧命令的输入。这就是管道的功能,如何实现的呢?
管道也是一种特殊文件,本质上是一块内存区域,一端只允许写,一端只允许读,数据的流向只能是写端到读端,感觉就像管道一般,所以将这种文件命名为管道文件。来看其结构定义
#define PIPESIZE 512
struct pipe {
struct spinlock lock; //锁
char data[PIPESIZE]; //存放数据的内存区域
uint nread; // 已读的字节数
uint nwrite; // 已写的字节数
int readopen; // 可读的一端是打开的?
int writeopen; // 可写的一端是打开的?
};各个属性字段应该还是很好理解的,不太理解的话也没关系,在后面管道创建关闭读写的实现函数中会看到这些字段的具体意义
创建
有个系统调用专门来创建一个管道,函数原型如下:
int pipe(int*);参数一般是只有两个元素的整形数组,比如说 int p[2]; 使用时 pipe(p) 就创建了一个管道,执行完 系统调用后,两个整形数就变成文件描述符了,其中文件描述符 表示管道文件的读端,管道描述符 表示管道文件的写端。
数组都没初始化,为啥执行完 系统调用之后, 数组里面的两个元素就变成文件描述符了,而且什么叫做只能从一端写,又只能从一端读?难道是先用写的方式打开文件,关闭之后再用读的方式打开?这是我刚遇到管道时最大的疑惑,让我很是费解。关于这些问题来看看管道是如何创建便会迎刃而解。
管道文件的创建与其他文件的创建有些不同,其他文件创建的时候就是分配 然后安装目录项,打开的时候才分配文件结构体,分配文件描述符。而管道本身就是块内存区,在创建管道的时候就分配文件结构体文件描述符来描述这个管道。
里面对管道文件没有分配 ,我不知道这样做有什么好处,省下了 ?正因为少了 这一层,当时看这一块的源码的时候就感觉不太统一,层次不分明,但 小也无伤大雅,整个脉络还是很容易理清。反观 这一块的处理,它是为管道文件分配了 的,各个层次分明,所以文件读写函数只需要判断 的类型字段去调用不同的读写函数就行了,使得整个代码看起来特别的漂亮,来看一段:
int sys_write(unsigned int fd,char * buf,int count)
{
/***********略***********/
if (inode->i_pipe) //管道文件
return (file->f_mode&2)?write_pipe(inode,buf,count):-EIO;
if (S_ISCHR(inode->i_mode)) //字符设备文件
return rw_char(WRITE,inode->i_zone[0],buf,count,&file->f_pos);
if (S_ISBLK(inode->i_mode)) //块设备文件
return block_write(inode->i_zone[0],&file->f_pos,buf,count);
if (S_ISREG(inode->i_mode)) //普通文件
return file_write(inode,file,buf,count);
/***********略***********/
}这个函数就是 系统调用对应的内核函数,相比 这个 是不是特别的干练漂亮。
接下来还是回到 管道的创建上面,系统调用 用来创建一个管道,它调用了另一个函数 来分配管道文件的文件结构体和内存,先来看看这个函数:
int pipealloc(struct file **f0, struct file **f1){
struct pipe *p;
p = 0;
*f0 = *f1 = 0;
if((*f0 = filealloc()) == 0 || (*f1 = filealloc()) == 0) //分配两个文件结构体
goto bad;
if((p = (struct pipe*)kalloc()) == 0) //给管道分配内存
goto bad;
这一部分为管道分配两个文件结构体,以及为管道分配内存。这里就注意一个管道文件但是分配了两个文件结构体。
p->readopen = 1; //管道读端打开,是可读的
p->writeopen = 1; //管道写端打开,是可写的
p->nwrite = 0; //写了0字节
p->nread = 0; //读了0字节
initlock(&p->lock, "pipe"); //初始化管道的锁这一部分初始化管道结构体,详情见注释
(*f0)->type = FD_PIPE; //文件类型为管道
(*f0)->readable = 1; //该文件可读
(*f0)->writable = 0; //该文件不可写
(*f0)->pipe = p; //该文件的管道指针
(*f1)->type = FD_PIPE; //类型为管道
(*f1)->readable = 0; //该文件不可读
(*f1)->writable = 1; //该文件可写
(*f1)->pipe = p; //该文件的管道指针
return 0; //返回0表正确这一部分初始化管道文件的两个文件结构体,一个可读一个可写,指向同一个管道文件,于是乎模拟出了管道的两端。
bad: //如果出错
if(p)
kfree((char*)p);
if(*f0)
fileclose(*f0);
if(*f1)
fileclose(*f1);
return -1;
}这一部分是中途哪儿出了错,就释放掉已经分配的资源。
上述就是 函数,为管道分配了两文件结构体以及管道需要的内存,下面来看 系统调用的内核函数,看看如何创建一个管道:
int sys_pipe(void)
{
int *fd;
struct file *rf, *wf;
int fd0, fd1;
if(argptr(0, (void*)&fd, 2*sizeof(fd[0])) < 0) //用户栈取参数
return -1;是系统调用 的内核函数,与其他系统调用一样,第一步先去把参数取过来,这里就是那只有两个元素的整型数组。
if(pipealloc(&rf, &wf) < 0) //分配文件结构体和内存
return -1;这里就是调用上述的 函数为管道分配两个文件结构体以及分配相应的内存。
fd0 = -1; //初始化为-1
if((fd0 = fdalloc(rf)) < 0 || (fd1 = fdalloc(wf)) < 0){ //分配文件描述符
if(fd0 >= 0) //如果分配失败
myproc()->ofile[fd0] = 0; //回收文件描述符
fileclose(rf); //回收文件结构体
fileclose(wf); //回收文件结构体
return -1; //返回-1表示错误
}这一部分分配文件描述符,使得 指向读端文件结构体, 指向写端文件结构体。如果分配失败,回收已分配的资源。如果分配失败的话,要么是 分配失败,要么 分配失败(|| 运算符特性,前者为真就不会检查后者),一个文件描述符分配失败表示该文件描述符表项没有使用,不用置 0 来回收,详见[了解文件系统调用吗?如何实现的?] 。所以在文件描述符总体分配失败的情况下,只可能有 分配成功,因此只需要判断 。
fd[0] = fd0; //赋值给参数
fd[1] = fd1;
return 0; //返回0表正确
}如果操作都都没出问题的话就将分配的文件描述符赋给参数,因为是传指针,所以也就相当于赋值给了用户态下最开始的 int p[2]; 这个数组。
读写
int pipewrite(struct pipe *p, char *addr, int n)
{
int i;
acquire(&p->lock);
for(i = 0; i < n; i++){
while(p->nwrite == p->nread + PIPESIZE){ //管道已经满了需要读
if(p->readopen == 0 || myproc()->killed){ //读端被关闭或者进程被killed
release(&p->lock); //释放锁
return -1; //返回-1表错误
}
wakeup(&p->nread); //唤醒读进程
sleep(&p->nwrite, &p->lock); //写进程睡眠
}
p->data[p->nwrite++ % PIPESIZE] = addr[i]; //写,即数据放入缓存区
}
wakeup(&p->nread); //写了之后唤醒读进程
release(&p->lock); //释放锁
return n; //返回写了多少字节
}
int piperead(struct pipe *p, char *addr, int n)
{
int i;
acquire(&p->lock); //取锁
while(p->nread == p->nwrite && p->writeopen){ //管道空
if(myproc()->killed){ //如果进程被killed
release(&p->lock); //释放锁
return -1; //返回-1表错误
}
sleep(&p->nread, &p->lock); //读进程休眠
}
for(i = 0; i < n; i++){ //循环n次
if(p->nread == p->nwrite) //数据已经读完,管道空了
break;
addr[i] = p->data[p->nread++ % PIPESIZE]; //读操作,搬运数据的一个过程
}
wakeup(&p->nwrite); //读完之后唤醒写进程
release(&p->lock); //释放锁
return i; //返回读取的字节数
}代码有点多,但流程很清楚,注释也很清晰。对于写操作,先是判断缓存区是否满了,如果满了就换新读进程,写进程自己休眠,没满的话就将数据写进缓存区,写完之后唤醒读进程。而对于读操作,先是判断缓存区是否为空,为空的话读进程就休眠。反之读取数据,读完之后唤醒写进程。
关闭
void pipeclose(struct pipe *p, int writable)
{
acquire(&p->lock); //取锁
if(writable){ //如果要关闭的是写端
p->writeopen = 0; //写端置0
wakeup(&p->nread); //唤醒读进程
} else { //否则要关闭的是读端
p->readopen = 0; //读端置0
wakeup(&p->nwrite); //唤醒读端
}
if(p->readopen == 0 && p->writeopen == 0){ //如果读端写端都被关闭了
release(&p->lock); //解锁
kfree((char*)p); //释放管道内存
} else //如果读端写端没有全部关闭
release(&p->lock); //只解锁
}这就是关闭管道的函数,只有读端与写端都关闭的时候管道文件才会被真正的被关闭,即资源占用的内存会被回收。其中关闭读端或写端时要唤醒对端进程,举个例子,读进程等待写进程写,此时写进程意外崩溃退出,在写进程退出关闭文件之前需要把读进程唤醒以免死锁。
上述就是 两种必要重要的机制,单独拿出来说了说,还有其他机制比如说后台运行等等在后面实际的源码中查看。下面讲述实际的 程序, 的 是 的简单实现,而 就是 的前身。
这个程序就是从控制台获取输入的命令字符串,解析这个命令字符串生成语法树,然后执行。其中最困难的地方就在于对命令字符串的解析,从字符串中识别一个个命令,然后他们按照优先级一个个的组合起来生成语法树。虽然困难但咱们也慢慢来看,首先来看对命令的分类。
命令种类
这里所说的命令种类不是真的对命令程序如 , 等等分类,而是说嗯打个比方, 是加法, 是乘法,类似的对于 echo hello world 我们称之为可执行命令,echo hello world > rand.txt 称之为重定向命令。这下应该清楚了吧,来看分了哪几种命令:
基类命令
struct cmd {
int type; //类型
};基类命令,恰如其名,它是其他命令的基类/父类,这就像是使用 语言实现面向对象的一些功能一样,比如说多态。这些概念不懂没关系,看后面在实际代码中的使用也就明白了。
可执行命令
可执行命令是一串命令中的最小可执行单元,结构定义如下
#define EXEC 1
struct execcmd {
int type; //类型(就是EXEC)
char *argv[MAXARGS]; //每个参数开头字符位置
char *eargv[MAXARGS]; //每个参数结尾字符位置
};这类命令可以直接执行,比如 ls 又比如 echo hello world,它第一个元素是 ,就是一个父类元素,然后它还有自己特有的元素,这就是父类与子类,就跟面向对象继承一样的道理。
为什么要用两个元素来确定参数的位置,平时使用的字符串都有一个隐含字符 '\0',它就是字符串的末尾,所以我们只用指定字符串开头就行了,但是在解析命令字符串的时候,一个个 token 都是和在一起的,没有 '\0' 分开所以需要记录 token 的起始末尾的位置。当然,最后会将其提取出来作为一个单独的有 '\0' 的字符串,这到后面再说。
token 这个单词有的计算机书籍翻译为记号,嗯感觉不太得劲儿,就用英文 吧, 什么意思呢?举个例子,"echo hello world > rand.txt",这个命令字符串里面 echo、hello、world、>、rand.txt 都是 token,解析命令的第一步就是将命令字符串分隔成一个个 token。
回到命令种类上来
struct cmd* execcmd(void) //
{
struct execcmd *cmd;
cmd = malloc(sizeof(*cmd)); //分配execmd需要的空间
memset(cmd, 0, sizeof(*cmd)); //置0
cmd->type = EXEC; //设置命令类型为exec
return (struct cmd*)cmd; //强制类型转换成普通cmd
}这是可执行命令的构造函数
重定向命令
#define REDIR 2
struct redircmd {
int type; //类型(REDIR)
struct cmd *cmd; //真正要执行的命令
char *file; //重定向文件的路径
char *efile; //上述路径字符串末尾位置
int mode; //以怎样的方式打开这个文件
int fd; //关闭哪个stdio
};这就是重定向命令的包装形式,其元素 才是要执行的命令, 的类型为父类命令,多态那儿我们知道父类指针可以指向子类,意思就是说这里这个 可以表示任何其他子类命令。
是重定向文件字符串首字符地址, 是重定向文件字符串末尾地址,原因同前。
是打开重定向文件的模式, 是要关闭的 文件描述符,将其关闭后,打开重定向文件时分配给重定向文件的描述符就是 。
struct cmd* redircmd(struct cmd *subcmd, char *file, char *efile, int mode, int fd)
{
struct redircmd *cmd;
cmd = malloc(sizeof(*cmd)); //分配redircmd命令需要的空间
memset(cmd, 0, sizeof(*cmd)); //置0
cmd->type = REDIR; //命令类型为重定向REDIR
cmd->cmd = subcmd; //子命令
cmd->file = file; //重定向到哪个文件/重定向文件字符串起始地址
cmd->efile = efile; //重定向文件字符串末尾地址
cmd->mode = mode; //打开文件的格式
cmd->fd = fd; //文件描述符
return (struct cmd*)cmd; //强制类型转换成普通cmd
}这是重定向命令的构造函数
管道命令
struct pipecmd {
int type; //类型
struct cmd *left; //左侧命令
struct cmd *right; //右侧命令
};和 分别表示管道左侧的命令和管道右侧的命令,左侧命令程序的输出当作右侧命令程序的输入。
struct cmd*
pipecmd(struct cmd *left, struct cmd *right)
{
struct pipecmd *cmd;
cmd = malloc(sizeof(*cmd)); //分配pipecmd命令需要的空间
memset(cmd, 0, sizeof(*cmd)); //置0
cmd->type = PIPE; //命令类型为PIPE
cmd->left = left; //管道左侧的命令
cmd->right = right; //管道右侧的命令
return (struct cmd*)cmd; //强制类型转换成普通cmd
}这是管道命令的构造函数
List 命令
struct listcmd {
int type;
struct cmd *left; //左侧命令
struct cmd *right; //右侧命令
};这个命令我不知怎么翻译,怎么翻译都很奇怪,同 处理,就使用英文。什么是 命令呢?同样例子来说明,echo hello; echo world 就是一个 命令,它会先执行 echo hello,等其执行完之后再执行 echo world。实际上在 的 中, 不止 ;还有 &&``|| 等符号,详见 man bash
struct cmd* listcmd(struct cmd *left, struct cmd *right)
{
struct listcmd *cmd;
cmd = malloc(sizeof(*cmd)); //分配listcmd命令需要的空间
memset(cmd, 0, sizeof(*cmd)); //置0
cmd->type = LIST; //命令类型为LIST
cmd->left = left; //LIST左侧的命令
cmd->right = right; //右侧的命令
return (struct cmd*)cmd; //强制类型转换成普通cmd
}这是 命令的构造函数
后台命令
struct backcmd {
int type;
struct cmd *cmd; //子命令
};后台命令,顾名思义, 会在后台执行,这里先不说后台前台这些抽象的概念,在运行命令一节中详述。
struct cmd*
backcmd(struct cmd *subcmd)
{
struct backcmd *cmd;
cmd = malloc(sizeof(*cmd)); //分配listcmd命令需要的空间
memset(cmd, 0, sizeof(*cmd)); //置0
cmd->type = BACK; //命令类型为BACK
cmd->cmd = subcmd; //子命令
return (struct cmd*)cmd; //强制类型转换成普通cmd
}这是后台命令的构造函数。
接下来看看如何进行词法分析将命令字符串的 给分析出来,然后进行语法分析将各个 组合起来形成一个完整的语法树,先来看词法分析
词法分析
char whitespace[] = " \t\r\n\v"; //空白字符
char symbols[] = "<|>&;()"; //特殊符号定义了两个字符串,第一个包括了所有可能的空白字符,第二个包括了一些特殊符号比如重定向管道等等
char* strchr(const char *s, char c)
{
for(; *s; s++)
if(*s == c)
return (char*)s;
return 0;
}这个函数来查看字符串 里面是否存在字符 ,若存在返回第一个 的地址,若不存在返回 0。
用来获取字符串中最前面那个 ,函数原型
int gettoken(char **ps, char *es, char **q, char **eq)
是一个字符串的开头(二级指针), 是字符串末尾, 是一个最近一个 的开头(二级指针), 是最近一个 的末尾(二级指针)。图示如下(没有区分一级和二级指针)
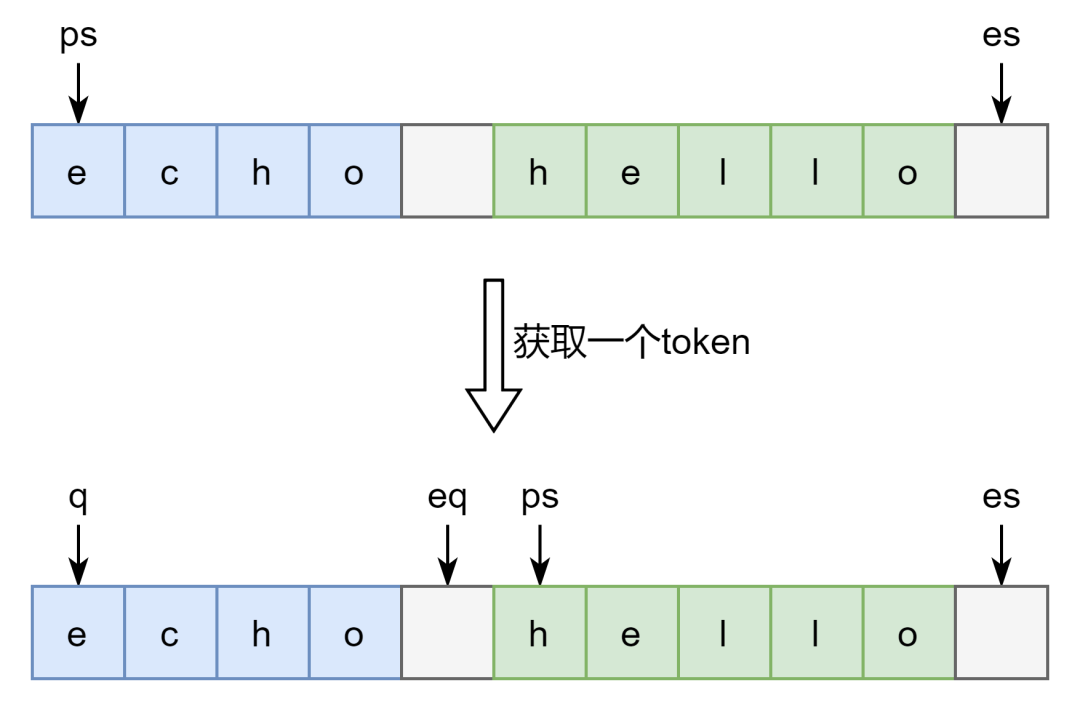
int gettoken(char **ps, char *es, char **q, char **eq)
{
char *s;
int ret;
s = *ps; //获取字符串开头
while(s < es && strchr(whitespace, *s)) //跳过空白字符
s++;给定一个字符串提取 ,首先去掉前面可能出现的空白字符。strchr(whitespace, *s) 检查当前字符串是否是空白字符,是的话 s++,否则就停下来,如此来跳过字符串最前面的空白字符。
if(q)
*q = s; //记录跳过空白字符后的第一个有效字符位置如果参数 存在,记录跳过空白字符后的第一个有效字符位置,即将要提取的 的第一个字符位置。
ret = *s; //准备返回用的变量,token第一个字符
switch(*s){ //switch token 第一个字符
case 0:
break;
case '|':
case '(':
case ')':
case ';':
case '&':
case '<':
s++; //如果是这些情况 s++
break; 如果 的第一个字符是这些特殊符号,s++ 然后 break。这些 本身也就只有一个字符,所以 就是返回值。
case '>': //如果是>重定向
s++;
if(*s == '>'){ //如果是>后面还有一个>
ret = '+'; //则是重定向里面的追加情况
s++; //s指针再向后移
}
break;这一部分处理 > 和 >> 重定向,> 输出到文件后会覆盖源文件内容,>> 是追加到文件末尾,不会覆盖。
default:
ret = 'a'; //默认情况
while(s < es && !strchr(whitespace, *s) && !strchr(symbols, *s)) //如果不是空白字符也不是特殊符号跳过
s++;
break;
}这一部分处理默认情况, 可能是一个程序名比如 ls,也可能是一个路径文件名比如
if(eq) //如果eq存在
*eq = s; //记录token的末尾这一部分记录 的末尾,到此如果 和 存在的话,它俩就记录了一个 的起始和末尾位置,其中末尾是最后一个有效字符的后面一个字符的位置。
while(s < es && strchr(whitespace, *s)) //再次跳过空白字符
s++;
*ps = s; //修改外部指针位置
return ret; //返回
}这一部分跳过 后面的空白字符, 现在应该是指向下一个 的第一个字符,但是 只是 这个函数的一个局部变量,我们要将其值传出去,这时二级指针 的作用就来了。
这里关于二级指针的使用是可能有点绕,举个例子:
char *str = "echo hello world";
char es = s + strlen(s);
char *q, *eq;
//int gettoken(char **ps, char *es, char **q, char **eq)
gettoken(&str, es, &q, &eq);函数刚开始执行的时候参数 是一个独立的局部变量,只是它的值等于 ,,同理 只是值等于 ,但是它俩是两个不同的变量。所以在 执行到最后 指向 ,但是此时 还是指向 没有变化。所以有了语句 来改变 的值,因为 ,使得将 的值赋给 。
那么使用一级指针就不行了吗?不行,因为道理还是同上,实参和形参是两个变量。想想平时写的交换函数,要使整型变量 交换,传参传的是 地址,如果 本身就是个指针呢,要交换两者的值怎么办?同样的道理,传两者的地址。
关于二级指针懂了就觉得很简单,不懂的别人说再多还是觉得模模糊糊,还是需要自己琢磨琢磨。我在捋多级指针的时候都是这样告诉自己:指针就是个地址,地址上存放着这个指针指向的变量的值,如果这个变量还是个指针,那就重复上述过程。
int peek(char **ps, char *es, char *toks) //想看看这字符串里有无 toks,顺便跳过前面的空白字符
{
char *s;
s = *ps;
while(s < es && strchr(whitespace, *s)) //跳过空白字符
s++;
*ps = s; //修改外面的指针值
return *s && strchr(toks, *s); //字符串里有无toks字符
}有了上述 的铺垫之后,这个函数应该很简单,就是看看命令字符串里面是否含有 字符,准确来说是看看第一个 的第一个字符是否在给定的 字符串里面出现。这个函数顺便也跳过了开头的空白字符
语法分析
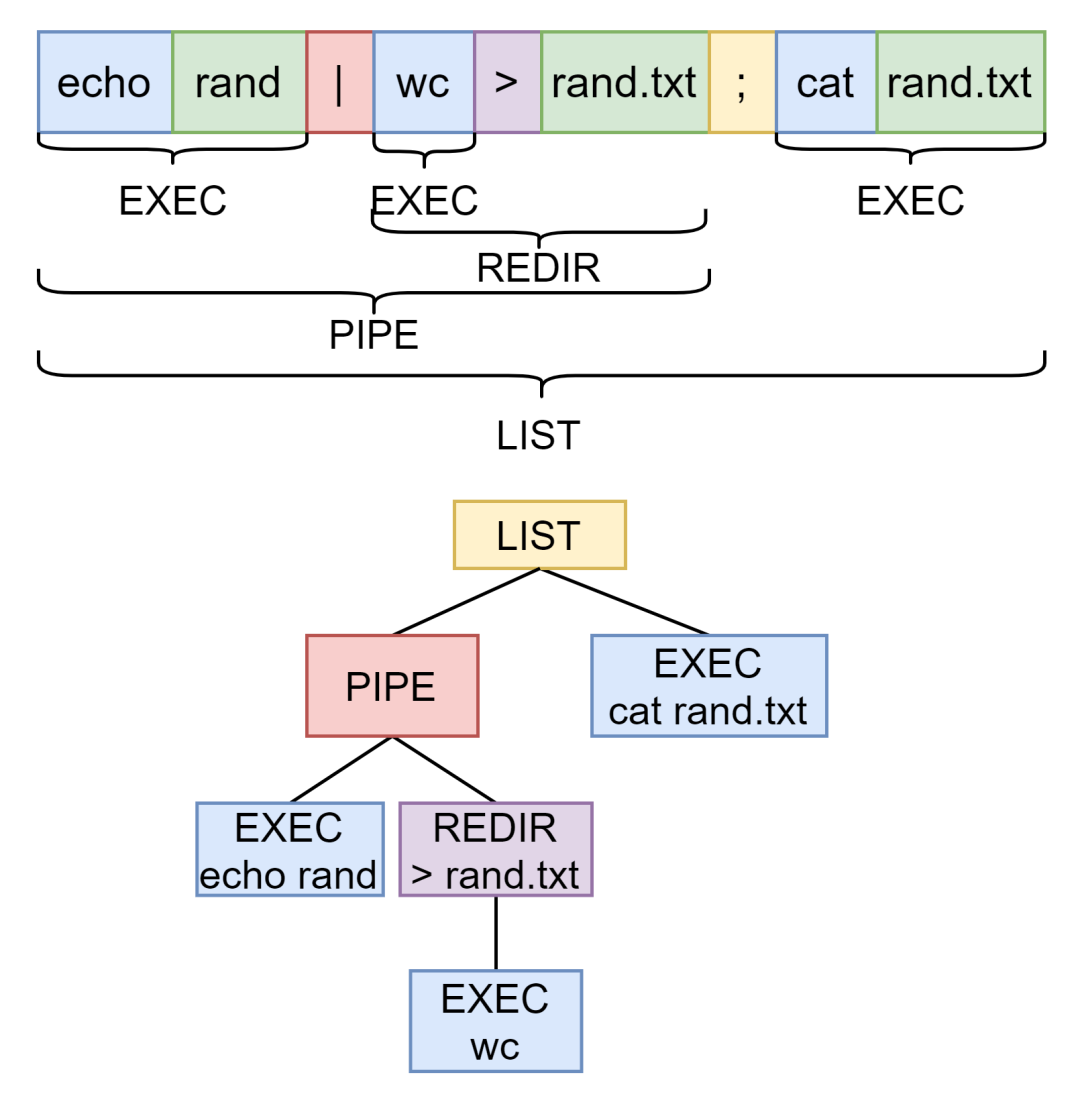
这一节就来具体看看如何将一串命令解析出来,这一部分我改了很多次,最开始使用语言详述代码,结果语言表达能力匮乏,实在讲不清。而且语法分析是一个递归的过程,既不好从上层讲述,也不好下层讲述,因为没有明显的分界线。所以这里除了重点部分我就不解释代码了,就只是用例子和图片说明各个函数的作用,代码的话写了注释,配合图片例子应该没问题。
可以先来看一张图,来了解了解这部分到底要做什么事:
struct cmd* parsecmd(char *s) //将字符串s中的命令解析出来
{
char *es;
struct cmd *cmd;
es = s + strlen(s); //字符串末尾
cmd = parseline(&s, es); //调用parseline解析命令
peek(&s, es, ""); //使得s移向末尾
if(s != es){ //此时s应等于es,否则出错
printf(2, "leftovers: %s\n", s);
panic("syntax");
}
nulterminate(cmd); //将各命令字符串末尾置零,使得字符串分开
return cmd;
}这是最顶层的一个函数,参数就是从控制台获取的命令字符串,它调用 将命令解析出来,然后对命令做截止处理。具体意思往后看
struct cmd* parseline(char **ps, char *es)
{
struct cmd *cmd;
cmd = parsepipe(ps, es); //解析命令
while(peek(ps, es, "&")){ //如果存在后台命令
gettoken(ps, es, 0, 0);
cmd = backcmd(cmd); //包装成一个后台命令
}
if(peek(ps, es, ";")){ //如果是个LIST命令
gettoken(ps, es, 0, 0);
cmd = listcmd(cmd, parseline(ps, es)); //包装成一个LIST命令
}
return cmd;
}用来解析一串”独立“的命令,比如说括号里面的命令,;两侧的命令。
如果命令是 echo rand
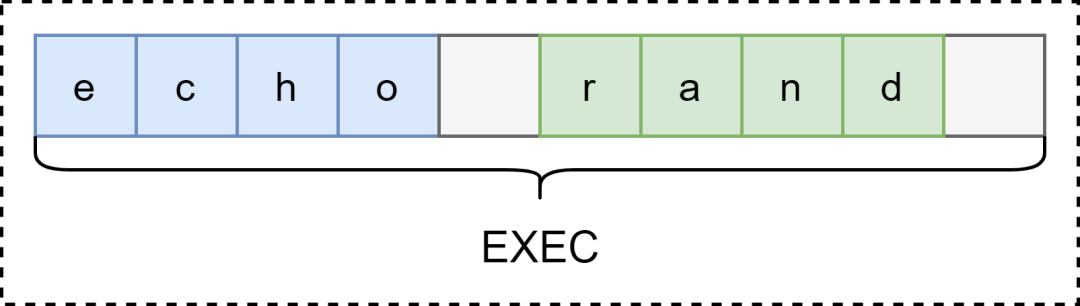
echo rand &
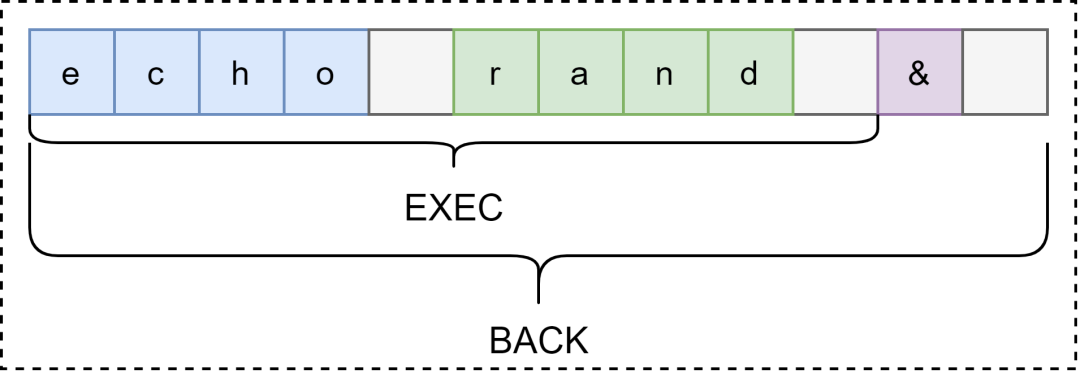
echo hello; echo world

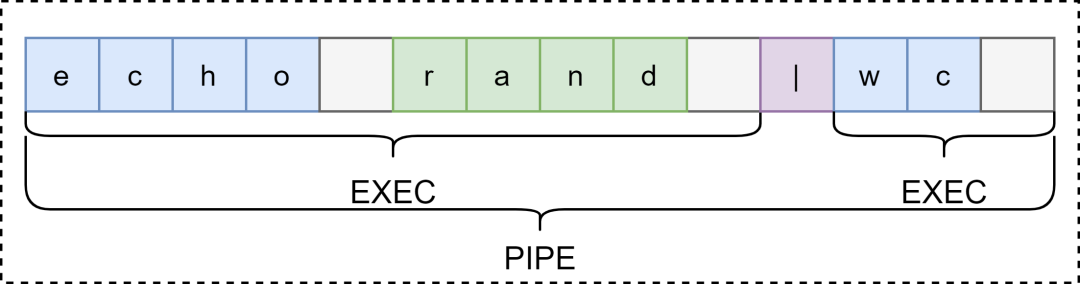
struct cmd* parsepipe(char **ps, char *es)
{
struct cmd *cmd;
cmd = parseexec(ps, es); //解析可执行命令
if(peek(ps, es, "|")){ //如果有管道
gettoken(ps, es, 0, 0);
cmd = pipecmd(cmd, parsepipe(ps, es)); //解析管道右边的命令,然后包装成管道命令
}
return cmd;
}看名字就是解析成管道命令,首先解析左边的命令,然后解析右边的命令,最后包装成一个管道命令。当然是有管道才会包装成管道命令,没有的话就会按照可执行命令来解析。举个例子
echo rand | wc
struct cmd* parseexec(char **ps, char *es)
{
char *q, *eq;
int tok, argc;
struct execcmd *cmd;
struct cmd *ret;
if(peek(ps, es, "(")) //如果字符串第一个有效字符是'('
return parseblock(ps, es); //那么括号里面的当作一个整体的命令这一步是如果有括号,括号里面的当作一个整体,与表达式求值一模一样,有括号就先算括号里面的
ret = execcmd();
cmd = (struct execcmd*)ret;
argc = 0;
ret = parseredirs(ret, ps, es);这一步构造一个空的 命令,然后判断是否有重定向。
while(!peek(ps, es, "|)&;")){ //如果不是这几种特殊符号
if((tok=gettoken(ps, es, &q, &eq)) == 0)
break;
if(tok != 'a') //此时token类型应该是'a'
panic("syntax");
cmd->argv[argc] = q; //记录程序名和参数的起始位置
cmd->eargv[argc] = eq; //记录程序名和参数的结尾位置
argc++;
if(argc >= MAXARGS)
panic("too many args");
ret = parseredirs(ret, ps, es); //检查有无重定向符号
}
cmd->argv[argc] = 0; //参数为0作为结尾
cmd->eargv[argc] = 0;
return ret;
}这部分就是正式构造一个可执行命令,将程序名和参数记录到 中去。其中末尾判断是否有重定向,一般是在参数后面才会出现重定向符号,比如说 echo hello world > rand.txt,参数 之后才会有重定向符号 >,这时候才可能会包装成重定向命令。最后一个参数是 0 作为结尾

struct cmd* parseredirs(struct cmd *cmd, char **ps, char *es)
{
int tok;
char *q, *eq;
while(peek(ps, es, "<>")){ //如果字符串第一个token是重定向字符
tok = gettoken(ps, es, 0, 0); //获取这个token
if(gettoken(ps, es, &q, &eq) != 'a') //获取重定向字符后面那个token
panic("missing file for redirection"); //如果类型不是'a',panic
switch(tok){ //选取重定向类型
case '<': //输入重定向
cmd = redircmd(cmd, q, eq, O_RDONLY, 0); //包装输入重定向命令
break;
case '>': //输出重定向(覆盖)
cmd = redircmd(cmd, q, eq, O_WRONLY|O_CREATE, 1); //包装输出重定向命令
break;
case '+': //输出重定向(追加)
cmd = redircmd(cmd, q, eq, O_WRONLY|O_CREATE, 1); //包装输出重定向命令
break;
}
}
return cmd; //返回命令
}这个函数将重定向命令解析出来,当然是有才解析。输入重定向需要关闭文件描述符 0,输出重定向需要关闭文件描述符 1。这里提一句虽然在 里面区分了输出重定向的覆盖和追加两种情况,但实际 还没有实现相应的功能,这需要我们自行添加这个功能,具体点就是从文件结构体中的偏移量入手。
struct cmd* parseblock(char **ps, char *es)
{
struct cmd *cmd;
if(!peek(ps, es, "(")) //如果有'(''
panic("parseblock");
gettoken(ps, es, 0, 0); //获取token '('
cmd = parseline(ps, es); //解析括号里面的命令
if(!peek(ps, es, ")")) //解析完之后ps应等于es
panic("syntax - missing )");
gettoken(ps, es, 0, 0); //获取token ')'
cmd = parseredirs(cmd, ps, es); //检查括号外是否有重定向,有就包装成重定向命令
return cmd;
}每个括号里面都相当于一个独立的命令字符串,调用 解析里面的命令,与前面所说的操作一模一样。
上述就是命令解析的过程,最后解释最开始的一个问题, 有什么用,以及为什么命令结构体中需要两个指针变量来记录字符串的位置,同样图示来说明:
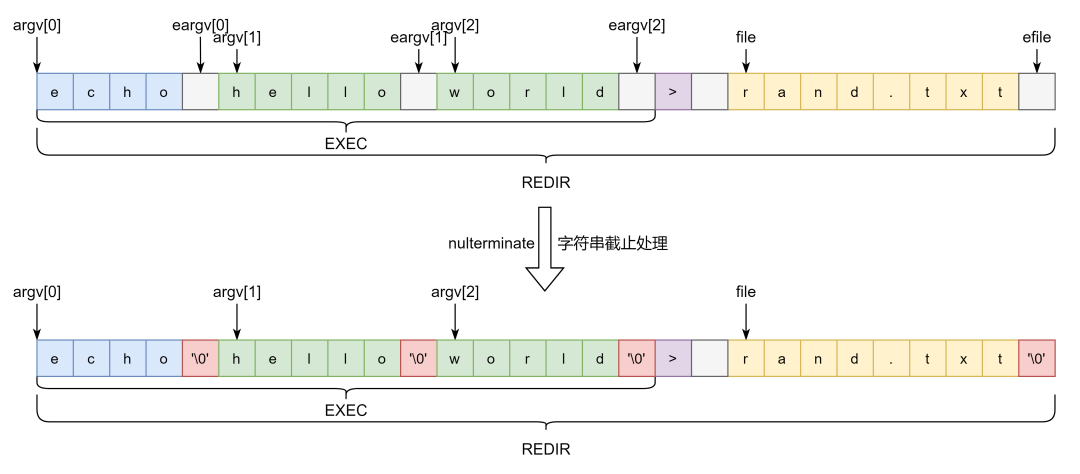
'\0' 作为字符串的结尾,经过 处理之后,就真正的将各个 分离出来,程序名参数分隔成一个个字符串,一些特殊符号隐含在各种命令结构体里面。
整个命令解析的过程就这样,没有讲述代码,不是我懒,而是写了真得感觉跟没写一样,也尝试过画流程图,但这种有很多递归,条件判断的流程图不怎么会画,所以也就算了。理解这部分的代码最好是自己举一些例子,实际模拟一遍。千万不要考虑各种情况直接看码,这样很容易陷进去出不来,当然如果您思维敏捷逻辑清晰当我没说。
总之经过语法分析之后,就会生成一颗语法树,也就是说将各种命令一层层的包装成一个最外层的命令,但实际运行的时候却又是从最里层的命令执行。同样的来看看开头那个例子
echo rand | wc > rand.txt ; cat rand.txt
执行命令
上面的所有操作都是将给定的命令字符串中的命令解析出来,不管最后多么复杂,最后解析出来的应该都是一个最外层的命令,这个命令下面有子命令,子命令下面又有子命令,如此递归下去,直到叶子命令,然后开始执行这个叶子命令程序。来看代码:
void runcmd(struct cmd *cmd)
{
int p[2];
struct backcmd *bcmd;
struct execcmd *ecmd;
struct listcmd *lcmd;
struct pipecmd *pcmd;
struct redircmd *rcmd;
if(cmd == 0)
exit();这部分没什么说的,就是先定义各种局部变量,如果 表示没有要执行的命令,直接退出。
switch(cmd->type){ //选择命令的类型
default: //只支持EXEC等几种命令,执行到默认情况就是出错了
panic("runcmd");
case EXEC: //如果是EXEC命令
ecmd = (struct execcmd*)cmd; //强制类型转换为execcmd
if(ecmd->argv[0] == 0) //如果参数数组argv一个元素都没有
exit(); //退出
exec(ecmd->argv[0], ecmd->argv); //调用exec函数执行这个命令
printf(2, "exec %s failed\n", ecmd->argv[0]); //正常情况不会返回
break;这部分是运行 类型的命令,这种命令可以直接运行,很简单,正常的情况就是直接调用 函数然后运行。有几点注意:
- 至少都有一个参数那就是程序名,如果连程序名这个参数都没有,运行到这那肯定出错了,所以直接退出
- 调用 函数之后正常情况下不会返回,因为进程的原内存映像已经被删除了,详细情况见进程三之大杂烩。
- 强制类型转换,将基类命令转化为子类命令,体现多态。
- 的第一个参数是可执行程序的路径,所以准确的讲 不是程序名,而是路径名,因为这些可执行程序都在根目录下,当前工作目录又是在根目录,所以说程序名也就当作是路径名了。平时在 下使用命令没有指定命令路径是因为环境变量 已经帮我们做了这个工作。
case REDIR: //如果是重定向命令
rcmd = (struct redircmd*)cmd; //强制类型转换为重定向命令
close(rcmd->fd); //关闭标准输入或者标准输出
if(open(rcmd->file, rcmd->mode) < 0){ //打开文件,描述符为0或1
printf(2, "open %s failed\n", rcmd->file);
exit();
}
runcmd(rcmd->cmd); //递归调用runcmd执行命令
break;这部分处理重定向命令,根据前面讲述的重定向机制,关键点就是关闭标准输入或者标准输出,因为分配文件描述符从最小的分配起走,所以打开要重定向到的文件时,该文件的描述符就是之前关闭的 的描述符。
举个例子 echo hello world > rand.txt,执行这个命令就会关闭标准输出 1,然后文件描述符 1 就空闲出来了,打开 时就会将描述符 1 分配给这个文件,此时文件描述符 1 就指向 。向 1 打印 就会将 写进 ,达到重定向的目的。
重定向命令不能直接运行的,需要运行其子命令,至于子命令能不能直接运行,那要看子命令是不是一个可执行命令。
case LIST: //如果是LIST命令
lcmd = (struct listcmd*)cmd; //强制类型转换为LIST命令
if(fork1() == 0) //fork出一个子进程运行左边的命令
runcmd(lcmd->left);
wait(); //等待左边的程序运行结束
runcmd(lcmd->right); //运行右边的命令
break;这里看出所谓的 命令就是像这种:echo hello; echo world,它会先 出一个子进程运行 echo hello,等他执行完之后再运行echo world。因为父进程调用 等待子进程运行结束,所以有这么一个先后顺序,其他的没什么多说的,来看看不等待的情况
case BACK: //如果是BACK后台命令
bcmd = (struct backcmd*)cmd; //强制类型转换为BACK命令
if(fork1() == 0) //fork出一个子进程运行命令
runcmd(bcmd->cmd); //运行命令
break;
}乍一看似乎与普通的 命令没有什么区别,还另搞一个花样?注意这里后台执行是另外 fork 出了一个子进程来运行,父进程没有等待,父进程会直接返回。关于 & 后台执行 手册中也给出了类似的解释:If a command is terminated by the control operator &, the shell executes the command in the background in a subshell. The shell does not wait for the command to finish, and the return status is 0. 这句英文应该不难看懂,我都能看懂,您肯定也能看懂。
还是不太清楚?咱们来捋捋:首先上述的这些命令程序都是在 出来的子进程中运行的:
if(fork1() == 0) //fork出一个子进程运行命令
runcmd(parsecmd(buf)); //从字符串中解析出命令,然后运行
wait(); //等待子进程退出这是 的 函数一部分,它 出一个子进程运行控制台输入的命令, 调用 来等待命令执行完成。
如果是前台命令,比如说命令 echo hello world,子进程会直接调用 运行。因为父进程 调用了 来等待 运行完毕的,所以父进程 在子进程执行 的这段时间休眠等待。这段时间内我们是能够看到 阻塞在这儿,光标一闪一闪的,这我们就明显地能够感知到这个程序的确是在运行,直接可见所以叫做前台运行。( 执行时间很短似乎是看不到,但我想表达的这个意思应该清楚吧)
如果是命令 echo hello world &,这就是一个后台命令, 出子进程 来运行这个后台命令,子进程 出一个子进程 来运行实际的 程序,子进程 没有等待,直接退出。所以 几乎没有等待子进程 , 进程就继续运行了,等待下一条命令。这种情况 几乎没有被阻塞,我们就感知不到程序是否在运行,不可见所以叫做后台执行。
case PIPE:
pcmd = (struct pipecmd*)cmd;
if(pipe(p) < 0)
panic("pipe");
if(fork1() == 0){ //fork出一个子进程运行左边的命令
close(1); //关闭标准输出
dup(p[1]); //标准输出重定向到p[1]
close(p[0]); //关闭p[1]
close(p[1]); //关闭p[2]
runcmd(pcmd->left); //执行左边的命令
}
if(fork1() == 0){ //fork出一个子进程运行右边的命令
close(0); //关闭标准输入
dup(p[0]); //标准输入重定向到p[0]
close(p[0]); //关闭p[0]
close(p[1]); //关闭p[1]
runcmd(pcmd->right); //运行右边的命令
}
close(p[0]); //关闭p[0]
close(p[1]); //关闭p[1]
wait(); //等待子进程退出
wait(); //等待子进程退出
break;看着很复杂,一张图搞定,先做一个定义:A 是要写的子进程,也就是管道左边的命令,B 是要读的子进程,也就是管道右边的命令,来看这张图:
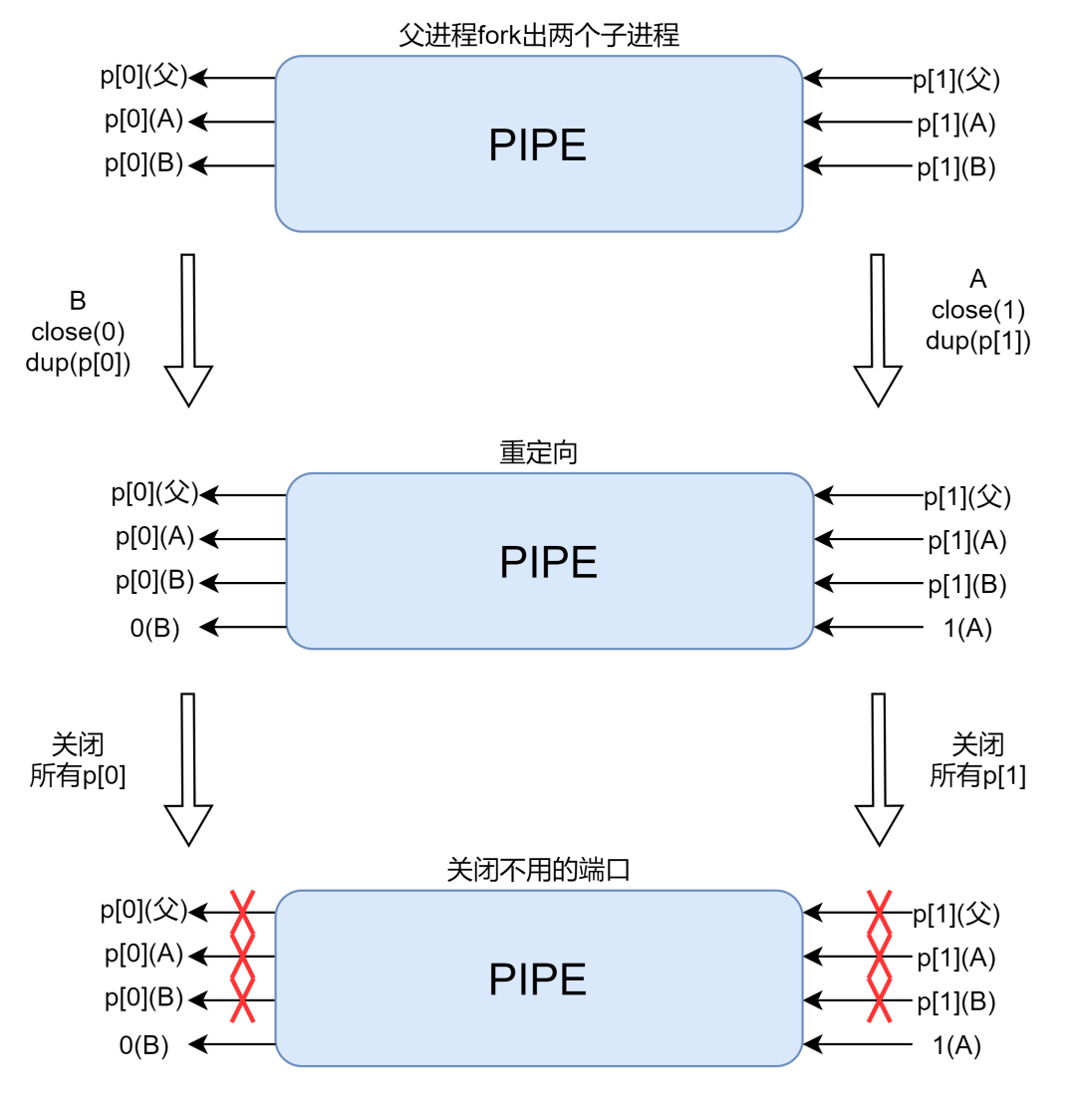
close(1); dup(p[1]),这就把进程 的标准输出重定向到管道的写端。读进程 B close(0); dup(p[0]),这就把进程 的标准输入重定向到管道的读端。另外对于不使用的管道描述符通常会选择关闭,如此,就只有写进程 A 通过描述符 1 来写,只有读进程 B 通过描述符 0 来读。
另外管道是属于内核的一片内存区域, 的机制很简单,回收管道资源就是依靠 系统调用,它会调用 来减少文件结构体的引用数,当文件结构体的引用数减少到 0 的时候就会调用 来关闭管道,当 检测到读端写端都被关闭的时候就会回收管道资源即删除管道。所以 关闭不使用的描述符是很必要的,不然会引起内存泄露。而且它不像堆资源在进程退出的时候会将用户空间的所有资源全部回收,不会造成内存泄漏。总而言之 机制少,使用方面也要符合习惯于规范。关于文件系统和进程资源的回收详见前文,这里不赘述。
最后再来看看 shell 的 main 函数:
int main(void)
{
static char buf[100];
int fd;
// Ensure that three file descriptors are open.
while((fd = open("console", O_RDWR)) >= 0){
if(fd >= 3){ //说明存在0,1,2这三个标准输入输出
close(fd); //关闭一个console文件,没真正关闭只是引用数减1
break;
}
}这部分就是检查控制台的三个标准文件描述符是否都存在,不存在的话那就是出错了
while(getcmd(buf, sizeof(buf)) >= 0){ //从控制台获取一个命令
if(buf[0] == 'c' && buf[1] == 'd' && buf[2] == ' '){ //如果是 cd 命令
// Chdir must be called by the parent, not the child.
buf[strlen(buf)-1] = 0; // chop \n 截断
if(chdir(buf+3) < 0) // 更换当前工作目录
printf(2, "cannot cd %s\n", buf+3);
continue;
}
if(fork1() == 0) //fork出一个子进程运行命令
runcmd(parsecmd(buf)); //从字符串中解析出命令,然后运行
wait(); //等待子进程退出
}
exit(); //shell退出,一般不会退出
}这部分就是获取用户在控制台输入的命令,然后执行,如果第一个命令是切换目录的话就先把目录切换了,本质上就是更改进程结构体 的指向,详见[了解文件系统调用吗?如何实现的?]
其他需要注意的地方就是执行命令是另 出一个子进程去执行命令程序,并且 会等待命令执行完成,当然后台执行除外。
另外这最后解决前文[捋一捋控制台的输入输出] 一文中遗留的一个问题,为什么在控制台键入 Ctrl + D 会导致 shell 退出,从这里我们看出如果 getcmd 函数返回的值小于 0 的话,那么 shell 就会执行 while 循环外面的 exit 退出,所以 Ctrl + D 肯定导致 getcmd 返回值小于 0 了,来看 getcmd 函数:
int getcmd(char *buf, int nbuf)
{
printf(2, "$ ");
memset(buf, 0, nbuf);
gets(buf, nbuf); //read(0, &c, 1);
if(buf[0] == 0) // EOF
return -1;
return 0;
}前文已经说过 会在控制台的缓冲区中放一个 ,这会导致读取的时候返回 0,使得 判断为真, 返回 ,然后使得 退出。这其中有些细节比如说 是 的封装,我就不展开了。
退出之后又会重建,因为在 进程中:
/*******init.c*******/
int main(){
for(;;){
/******略********/
pid = fork();
if(pid == 0){
exec("sh", argv);
printf(1, "init: exec sh failed\n");
exit();
}
while((wpid=wait()) >= 0 && wpid != pid)
printf(1, "zombie!\n");
}
}可以看出, 就算崩溃退出了, 进程又会创建一个新的, 实现交互的程序就只有一个 ,所以 需要一直存在。
总结
本文主要通过 讲述了 这个人机交互程序如何实现,着重把重定向和管道机制拿出来说了说。实现 两个主要步骤,一解析命令,二执行命令。其中解析这部分涉及到的词法语法分析尽力了吧,言语太苍白表达能力太弱,不过图片例子加注释理解起来应该没什么问题,说明地也还算清楚。
关于解析和执行两个部分,都运用到了一个很重要的思想:递归,递归这个东西,我自己认为逻辑不强的千万不要深入,有时是在摸不着头脑的时候可以举一些简单的例子试一试,一般就能够理清内在的逻辑关系。
其他的没什么说的了,本文就这样了吧,有什么问题还请批评指正,也欢迎大家来同我讨论交流学习进步。