C++常见的三种内存破坏的场景和分析

C++开发经验的同学大多数踩过内存破坏的坑,有这么几种现象:
- 比如某个变量整形,在程序中只可能初始化或者赋值为
1或者2, 但是在使用的时候却发现其为0或者其他的情况。对于其他类型,比如字符串等,可能出现了一种出乎意料的值! - 程序在堆上申请内存或者释放内存的时候,在内存充足的情况下,居然出现了堆错误。
当出现以上场景的时候,你该思考一下,是不是出现了内存破坏的情况了。而本文主要通过展示和分析常见的三种内存破坏导致覆盖相邻变量的场景,让读者在碰到类似的场景,不至于束手无策。而对于堆上的内存破坏,很常见并且棘手的场景,本人将在后续的文章和大家分享。
1 . 内存破坏之强制类型转换
大家都知道不匹配的类型强制转换会带来一些bug,比如int和unsigned int互相转换,又或者int和__int64强行转换。是不是每次当读起这类文章起来如雷贯耳,但是当自己去写代码的时候还是容易犯错?这也就是为什么C++容易写出坑的原因,明知可能有错,还难以避免。这往往是因为真实的项目中复杂程度,往往让人容易忽略这些细节。
不少老的工程代码还是采用VC6编译,为了安全问题或者使用C++新特性需要将VC6升级到更新的Visual Studio。接下来要介绍的一个样例程序,就是隐藏于代码中的一个问题,如果从VC6升级到VS2017的时候会带来问题吗?可以先找找看:
#include <iostream>
#include <time.h>
class DemoClass
{
public:
DemoClass() : m_bInit(true), m_tRecordTime(0)
{
time((time_t *)(&m_tRecordTime));
};
void DoSomething()
{
if (m_bInit)
std::cout << "Do Task!" << std::endl;
}
private:
int m_tRecordTime;
bool m_bInit;
};
int main()
{
DemoClass testObj;
testObj.DoSomething();
return 0;
}Do Task!这个字符串会不会打印出来呢? 可以发现这段程序在VC6中可以打印出来,但是在VS2017中却打印不出来了。那是因为如下原因:
函数原型time_t time( time_t *destTime );,在VC6中time_t默认是32位,而在VS2017中默认是64位。早期程序以为32位中表达最大的时间是2038年,那时候完全够用,但随着计算机本身的发展64位逐渐成为主流time_t在最新的编译器中也默认采用64位,这样时间完全够用以亿年为单位了,那时候计算机发展超出我们想象了。
程序的问题所在m_tRecordTime采用的是int类型,默认为32位,那么其地址作为time_t time( time_t *destTime );函数实参后,在VC6中time_t本身为32位自然也不会出错,但是在VS2017中因为time_t为64位,则time((time_t *)(&m_tRecordTime));后写入了一个64位的值。结合下图,看下这个对象的内存布局,m_bInit的值将会被覆盖,而这里原先的m_bInit的值为1,被覆盖为0,从而导致内存破坏,导致程序执行意想不到的结果。这里只是不输出,那在真实程序中,可能会导致某个逻辑错乱,发生严重的问题。
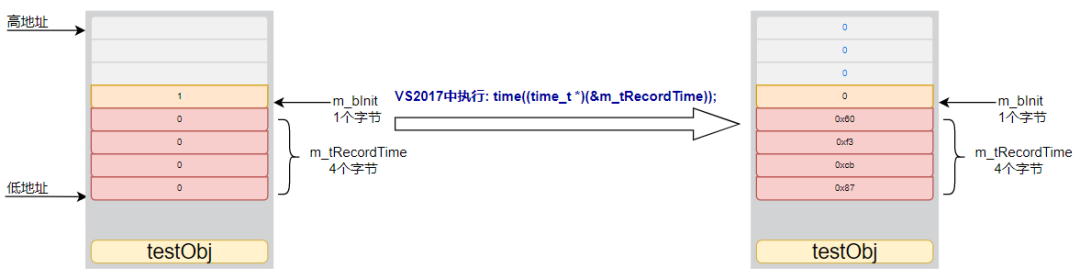
这个问题修改自然比较简单,将m_tRecordTime定义为time_t类型就可以了。
如果有类似的问题发生的时候,比如这个变量的可疑的发生了不该有的变化的时候,你可以查看下这个变量定义的附近是否有内存的操作可能产生溢出,找到问题所在。因为内存上溢的比较多,一般可以查看下定义在当前出现问题的变量的低地址出的变量操作,是否存在可疑的地方。
最后,针对这种场景,我们是不是也可以得到一些收获呢,个人总结如下两点:
- 在定义类型的时候,尽量和原始类型一致,比如这里的
time_t有些程序员可能惯性的认为就是32位,那就定义一个时间戳的时候就定义为int了,而我们要做的应该是和原始类型匹配(也就是函数的输入类型),将其定义为time_t,于此类似的还有size_t等,这样可以避免未来在数据集变化或者做平台迁移的时候造成不必要的麻烦。 - 在有一些复杂的场景的下,也许你不得不做类型转换,而这个时候就格外的需要注意或者了解清楚,转换带来的情况和后果,保持警惕,否则就可能是一个潜在的
bug。这和开车一样,当你开车的时候如果看到前方车辆忽然产生一个不合常理的变道行为,首先要做的不是喷那辆车,而是集中注意力,看看是否更前方有障碍物或者事故放生,做出相应的反应。
2 . 字符串拷贝溢出
这种情况应该是最常见了,我们来看一看样例程序:
#include <iostream>
#define BUFER_SIZE_STR_1 5
#define BUFER_SIZE_STR_2 8
class DemoClass
{
public:
void DoSomething()
{
strcpy(m_str1, "Hi Coder!");
std::cout << m_str1 << std::endl;
std::cout << m_str2 << std::endl;
}
private:
char m_str1[BUFER_SIZE_STR_1] = { 0 };
char m_str2[BUFER_SIZE_STR_2] = { 0 };
};
int main()
{
DemoClass testObj;
testObj.DoSomething();
return 0;
}这种情况下肉眼可以分析的,输出结果为:
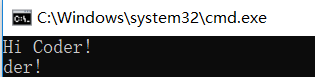
在m_str1的空间为5,但是Hi Coder!包含\0是10个字符,在调用strcpy(m_str1, "Hi Coder!");的时候超过了m_str1的空间,于是覆盖了m_str2的内存,从而导致内存破坏。内存溢出这种尤其字符串溢出,程序崩溃可能是小事儿,如果是一个广为流传的软件,那么就很有可能会被黑客所利用。比如看看这篇文章,就讲解了一种利用内存溢出的场景[<<栈上内存溢出漏洞利用之Return Address>>] 。
这种字符串场景如何分析呢,如果程序崩溃了,可以收集<span style="font-size: 16px;">Dump先看看被覆盖的地方是什么样的字符串,然后联想看看自己的程序哪里有可能对这个字符串的操作,从而找到原因。别小看这种方法,简单粗暴很有用,曾经就用这种方式分析过Linux驱动模块的内存泄露问题。
那如果还找不到问题呢?如果问题还能重现,那还是有调试手法的,下一节将会进行讲解。当然最差最差的还是不要放弃代码审查。尤其在这个内存被破坏的附近的逻辑。
对于这种场景的建议,比较简单就是使用微软安全函数strcpy_s,注意这里虽然列出了返回值errno_t不过对于微软的实现来说,如果是目标内存空间不够的情况下,在Relase版本下会调用TerminateProcess, 并且要注意的是这个时候抓Dump有时候并不是完整的Dump,可以采用这篇文章的方法[<<程序Crash了却无法捕获正确的函数调用栈?>>]。至于微软为什么要这样做,有可能是安全的考虑比崩溃优先级更高,于是在内存溢出不够的时候,直接让程序结束。
errno_t strcpy_s(
char *dest,
rsize_t dest_size,
const char *src
);3 . 随机性的内存被修改
这一个一听都快崩溃了,C++的坑能不能少一点呢。但是确实是会有各种各样的场景让你落入坑内。上一节的程序我稍作修改:
#include <iostream>
#define BUFER_SIZE_STR_1 5
#define BUFER_SIZE_STR_2 8
class DemoClass
{
public:
void DoSomething()
{
strcpy_s(m_str2, BUFER_SIZE_STR_2, "Coder");
strcpy_s(m_str1, BUFER_SIZE_STR_1, "Test");
//Notice this line:
m_str1[BUFER_SIZE_STR_2 - 1] = '\0';
std::cout << m_str1 << std::endl;
std::cout << m_str2 << std::endl;
}
private:
char m_str1[BUFER_SIZE_STR_1] = { 0 };
char m_str2[BUFER_SIZE_STR_2] = { 0 };
};
int main()
{
DemoClass testObj;
testObj.DoSomething();
return 0;
}程序本意是m_str2赋值为Coder, m_str1赋值为Test, 在编程中很多字符串拷贝或者操作中有些是在字符串末尾补\0有的可能不补\0, 而在本例中实际上strcpy_s会自动补0,但是有的程序员防止万一,字符串靠背后,在数组的最后一位设置为’\0’。这种有时候就变成了好心办坏事。比如这里的m_str1[BUFER_SIZE_STR_2 - 1] = '\0'; ,大家注意到没,这里应该改写为m_str1[BUFER_SIZE_STR_1 - 1] = '\0'; ,也就是说程序员可能拷贝代码或者不小心写错了BUFER_SIZE_STR_2和BUFER_SIZE_STR_1因为两者宏差不多。只要是人写代码,就有可能会犯这种错误。这个程序的输出变为:
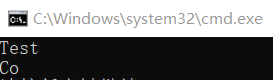
这个程序是比较简单,一目了然,但是在大型程序中呢,这个数组的位置跳跃的访问到了其他变量的位置,你首先得判断这个被跳跃式修改的变量,是不是程序本意造成的,因为混合了这么多的猜想,可能会导致分析变的异常复杂。那么有什么好的方法吗?只要程序能偶尔重现这个问题,那就是有方法的。
通过Windbg调试命令ba可以在指定的内存地址做操作的时候进入断点。假设目前已经知道m_str2的第四个字符,总是被某个地方误写,那么我们可以在这个地址处设置一个ba命令: 当写的这个内存地址的时候进入断点。不过这样还是有个问题,那就是程序中有可能有很多次对这块内存的写操作,有时候是正常的写操作,如果一直进入断点,人工分析将会非常累,不现实。
这个时候有个方法,同时也是一个workaround,就是当你还没找到程序出错的根本原因的时候在被误踩的内存前面加上一个足够大的不使用的空间。比如下面的代码, m_str2总是被误写,于是在m_str2的前面加上一个100个字节的不使用的内存m_strUnused(因为一般程序内存溢出是上溢,当然也可以在m_str2的后面同样加上)。这样我们被踩的内存就很容易落在m_strUnused空间里面了,这个时候我们在其空间里设置写内存操作的断点,就容易捕获到问题所在了。
#include <iostream>
#define BUFER_SIZE_STR_1 5
#define BUFER_SIZE_STR_2 8
#define BUFFER_SIZE_UNUSED 100
class DemoClass
{
public:
void DoSomething()
{
strcpy_s(m_str2, BUFER_SIZE_STR_2, "Coder");
strcpy_s(m_str1, BUFER_SIZE_STR_1, "Test");
//Notice this line:
m_str1[BUFER_SIZE_STR_2 - 1] = '\0';
std::cout << m_str1 << std::endl;
std::cout << m_str2 << std::endl;
}
private:
char m_str1[BUFER_SIZE_STR_1] = { 0 };
char m_strUnused[BUFFER_SIZE_UNUSED] = { 0 };
char m_str2[BUFER_SIZE_STR_2] = { 0 };
};
int main()
{
DemoClass testObj;
testObj.DoSomething();
return 0;
}下面完整的展示一下分析过程:
第一步 用Windbg启动(有的情况下可能是Attach,根据情况而定)到调试进程,设置main的断点
0:000> bp ObjectMemberBufferOverFllow!main
*** WARNING: Unable to verify checksum for ObjectMemberBufferOverFllow.exe
0:000> g
Breakpoint 0 hit
eax=010964c0 ebx=00e66000 ecx=00000000 edx=00000000 esi=75aae0b0 edi=0109b390
eip=003a1700 esp=00defa00 ebp=00defa44 iopl=0 nv up ei pl nz na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000206
ObjectMemberBufferOverFllow!main:
003a1700 55 push ebp第二步 使用p命令单步执行代码到testObj.DoSomething();
第三步 找到testObj的地址为00def984
0:000> dv /t /v
00def984 class DemoClass testObj = class DemoClass第四步 设置断点到testObj相对偏移的位置,这个位置即&m_str1+BUFER_SIZE_STR_2 - 1 = &m_str1+7。并且继续执行代码:
0:000> ba w1 00def984+7
0:000> g第五步 你会发现程序运行进入断点,这个时候查看对应的函数调用栈即可。这个断点不一定在一个非常精确的位置,但是当你按照函数调用栈去阅读附近的代码,便比较容易找出问题所在了。
0:000> k
# ChildEBP RetAddr
00 00def97c 003a1720 ObjectMemberBufferOverFllow!DemoClass::DoSomething+0x41 [......\strcpybufferoverflow.cpp @ 16]
01 00def9fc 003a1906 ObjectMemberBufferOverFllow!main+0x20 [......\strcpybufferoverflow.cpp @ 30]
02 (Inline) -------- ObjectMemberBufferOverFllow!invoke_main+0x1c [d:\agent\_work\3\s\src\vctools\crt\vcstartup\src\startup\exe_common.inl @ 78]
03 00defa44 75818494 ObjectMemberBufferOverFllow!__scrt_common_main_seh+0xfa [d:\agent\_work\3\s\src\vctools\crt\vcstartup\src\startup\exe_common.inl @ 288]
04 00defa58 770a40e8 KERNEL32!BaseThreadInitThunk+0x24
05 00defaa0 770a40b8 ntdll!__RtlUserThreadStart+0x2f
06 00defab0 00000000 ntdll!_RtlUserThreadStart+0x1b总结
以上对三种内存破坏场景做了分析,在实际应用中将会变的更加复杂。在写代码的时候要注意避开其中的坑,有个叫做墨菲定律,你感觉可能会出问题的地方,那它一定会在某个时刻出现,当你对某个地方有所疑虑的时候一定要多加考虑,否则这个坑可能查找的时间,比写代码的时间要长的许多,更可怕的是可能会带来意想不到的后果。
同样的分析问题要保持足够的耐心,相信真相总会出现,这样的底气也是来自于自己平时不断的学习和实践。
内存破坏问题不区分栈上还是堆上,我们在产品中离不开使用堆开间,而且由多个模块核心功能模块组成,而这些模块通常是公用一个进程默认堆的。所以也有人推荐在这些关键模块中,各自创建一个独立的堆,从而降低一个堆内存的使用对另一个堆中内存的影响。虽然不是完全隔离,但是也是一个聊胜于无的操作了。
对于堆内存破坏的处理,往往会伴随着这种现象:“为什么在我机器上跑的好好的,你的机器上不行”, “为什么机器重启后问题就不再出现了?” 等等。本人将在后续文章中和大家分享如何确认堆破坏以及如何查找堆破坏的罪魁祸首。