OOM Killer机制学习
当系统内存不足以分配时,Linux内核会使用一种OOM Killer(Out-Of-Memory Killer)机制释放内存,该机制通过一系列比较选择出最适合的进程并将其kill掉,从而达到保障系统稳定运行的目的。那么在内核中,OOM Killer具体是怎么运转的呢?
一、触发过程
在申请内存时,必然会调用alloc_page(),在__alloc_pages中有以下调用关系:
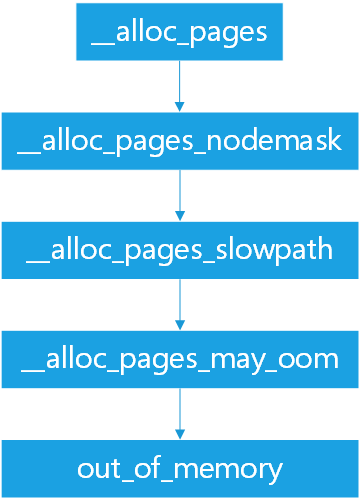
其中,在__alloc_pages_slowpath中,当反复尝试reclaim和compact后仍不成功,就会调用__alloc_pages_may_oom进行内存释放。
/*
* If we failed to make any progress reclaiming, then we are
* running out of options and have to consider going OOM
*/
if (!did_some_progress) {
if (oom_gfp_allowed(gfp_mask)) {
if (oom_killer_disabled)
goto nopage;
/* Coredumps can quickly deplete all memory reserves */
if ((current->flags & PF_DUMPCORE) &&
!(gfp_mask & __GFP_NOFAIL))
goto nopage;
page = __alloc_pages_may_oom(gfp_mask, order,
zonelist, high_zoneidx,
nodemask, preferred_zone,
classzone_idx, migratetype);
......
}如果定义了oom_killer_disabled,就会直接goto到nopage,不会触发OOM机制(此值默认为0).
二、工作过程(基于Linux-3.18)
当内核检测到内存不足,执行到out_of_memory时,OOM Killer会选择一个进程并把他kill掉:
p = select_bad_process(&points, totalpages, mpol_mask, force_kill);
具体的选择过程在select_bad_process中进行:
/*
* Simple selection loop. We chose the process with the highest
* number of 'points'. Returns -1 on scan abort.
*
* (not docbooked, we don't want this one cluttering up the manual)
*/
static struct task_struct *select_bad_process(unsigned int *ppoints,
unsigned long totalpages, const nodemask_t *nodemask,
bool force_kill)
{
struct task_struct *g, *p;
struct task_struct *chosen = NULL;
unsigned long chosen_points = 0;
rcu_read_lock();
for_each_process_thread(g, p) {
unsigned int points;
switch (oom_scan_process_thread(p, totalpages, nodemask,
force_kill)) {
case OOM_SCAN_SELECT:
chosen = p;
chosen_points = ULONG_MAX;
/* fall through */
case OOM_SCAN_CONTINUE:
continue;
case OOM_SCAN_ABORT:
rcu_read_unlock();
return (struct task_struct *)(-1UL);
case OOM_SCAN_OK:
break;
};
points = oom_badness(p, NULL, nodemask, totalpages);
if (!points || points < chosen_points)
continue;
/* Prefer thread group leaders for display purposes */
if (points == chosen_points && thread_group_leader(chosen))
continue;
chosen = p;
chosen_points = points;
}
if (chosen)
get_task_struct(chosen);
rcu_read_unlock();
*ppoints = chosen_points * 1000 / totalpages;
return chosen;
}select_bad_process会选择一个points数值最高的进程并返回。在宏for_each_process_thread循环里,通过switch和oom_scan_process_thread对一些进程做特殊化处理,如一些进程不适合被结束,就跳过本次循环。如果该进程没有特殊状态,oom_scan_process_thread返回OOM_SCAN_OK,继续向下进行判断。这里使用了oom_badness对其points值进行计算。
/**
* oom_badness - heuristic function to determine which candidate task to kill
* @p: task struct of which task we should calculate
* @totalpages: total present RAM allowed for page allocation
*
* The heuristic for determining which task to kill is made to be as simple and
* predictable as possible. The goal is to return the highest value for the
* task consuming the most memory to avoid subsequent oom failures.
*/
unsigned long oom_badness(struct task_struct *p, struct mem_cgroup *memcg,
const nodemask_t *nodemask, unsigned long totalpages)
{
long points;
long adj;
if (oom_unkillable_task(p, memcg, nodemask))
return 0;
p = find_lock_task_mm(p);
if (!p)
return 0;
adj = (long)p->signal->oom_score_adj;
if (adj == OOM_SCORE_ADJ_MIN) {
task_unlock(p);
return 0;
}
/*
* The baseline for the badness score is the proportion of RAM that each
* task's rss, pagetable and swap space use.
*/
points = get_mm_rss(p->mm) + atomic_long_read(&p->mm->nr_ptes) +
get_mm_counter(p->mm, MM_SWAPENTS);
task_unlock(p);
/*
* Root processes get 3% bonus, just like the __vm_enough_memory()
* implementation used by LSMs.
*/
if (has_capability_noaudit(p, CAP_SYS_ADMIN))
points -= (points * 3) / 100;
/* Normalize to oom_score_adj units */
adj *= totalpages / 1000;
points += adj;
/*
* Never return 0 for an eligible task regardless of the root bonus and
* oom_score_adj (oom_score_adj can't be OOM_SCORE_ADJ_MIN here).
*/
return points > 0 ? points : 1;
}在oom_badness的上半部分,对进程做了一些判断,排除了不可进行kill的进程以及oom_score_adj为OOM_SCORE_ADJ_MIN(-1000)的进程,进行了return 0。接着是进行比重计算,将rss、nr_ptes、swap空间使用量占RAM比重相加。如果是Root进程则去掉3%的比重points -= (points * 3) / 100;。之后对adj进行归一化并与points相加,在返回值计算时,使用了一个三目运算符,即当points大于0时,返回points,否则返回1。这里注释给出的原因是,对于有资格的进程(即可以被OOM Killer掉的进程),是绝不能返回0的。(这里我的理解是,如果points返回0,这个进程可能在之后的比较中就处于劣势,成为漏网之鱼)
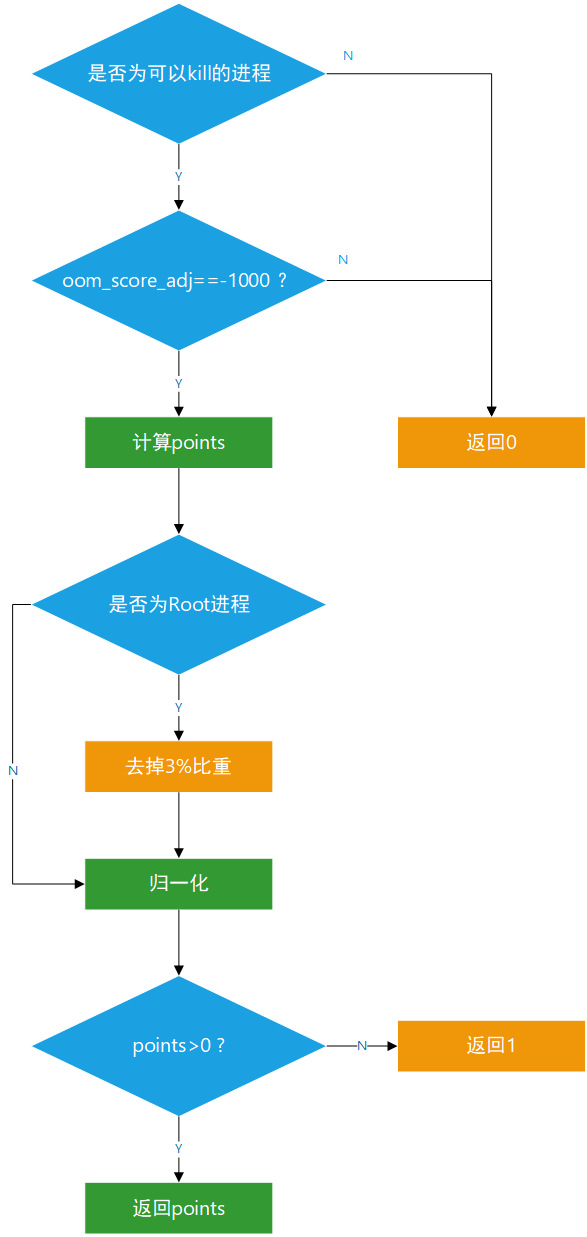
再回到select_bad_process中看,之后跟的一个if比较就是为了进行取最大值的判断,再之后判断该进程是否为thread_group_leader,若是则continue跳过本次循环,否则该进程就是被chosen的进程。
再回到out_of_memory中,得到p值后,需要对其进行判断:
if (!p) {
dump_header(NULL, gfp_mask, order, NULL, mpol_mask);
panic("Out of memory and no killable processes...\n");
}
if (p != (void *)-1UL) {
oom_kill_process(p, gfp_mask, order, points, totalpages, NULL,
nodemask, "Out of memory");
killed = 1;
}当p是0时,即没有找到可以kill掉的进程,内核发出一个panic。当p不是0时,即找到了可以kill掉的进程,则通过oom_kill_process将其kill。
在oom_kill_process中有个“有意思”的事是,在kill之前,会先遍历其子进程,重新通过oom_badness计算出一个最适合被kill掉的子进程,该子进程会有限考虑被kill掉,从而避免kill父进程导致的接管子进程的工作开销。并且最终被kill掉的进程的名字叫victim,这个单词的中文含义是牺牲者,有点是为了整个系统的稳定运转而牺牲的意思。在这之后OOM Killer会kill掉和victim使用相同虚拟内存的进程,并通过发送SIGKILL信号将其终止。

三、到底为什么会发生Out Of Memory?
因为物理内存页的分配发生在使用的瞬间而非分配的瞬间。若某个进程申请了200MB内存,但实际上只使用了100MB,未使用到的100MB根本没有分配物理内存页。当进程需要内存时,进程从内核得到的只是虚拟地址的使用权,而不是实际的物理地址,实际的物理内存只有当进程真的去访问新获取的虚拟地址时,产生缺页异常,从而进入分配实际物理地址的过程,之后系统返回产生异常的地址,重新执行内存访问。虚拟内存需要物理内存作为支撑,当分配了太多虚拟内存,导致物理内存不够时,就发生了Out Of Memory。这种允许超额commit的机制就是overcommit。
overcommit即操作系统在应用申请内存空间时不去检查是否超出当前可用量,随意满足申请要求,应用也不管实际是否有足够多的内存可使用,认为我申请了2G,OS肯定就给我2G使用。最后,随着内存越用越多,OS发现内存不够用了,必须要收回一些内存才行,就触发了上述的OOM Killer机制回收内存。
Linux根据参数 vm.overcommit_memory设置overcommit:
-
0 ——默认值,启发式overcommit,它允许overcommit,但太明显的overcommit会被拒绝,比如malloc一次性申请的内存大小就超过了系统总内存。
-
1 ——Always overcommit. 允许overcommit,对内存申请来者不拒。
-
2 ——不允许overcommit,提交给系统的总地址空间大小不允许超过CommitLimit。(CommitLimit 就是overcommit的阈值,申请的内存总数超过CommitLimit的话就算是overcommit)
-
四、总结
由于物理内存的分配机制,以及overcommit的存在,导致了在物理内存不够时的OOM Killer。OOM Killer机制很有意思,它为了保护整个系统的安全稳定运行,需要找出一个最合适的进程kill掉。这是不得已而为之,内核必须在kill掉进程和系统崩溃之间选择其中一个。内核代码中out_of_memory注释中也体现了这种无奈。> * If we run out of memory, we have the choice between either
* killing a random task (bad), letting the system crash (worse)
* OR try to be smart about which process to kill. Note that we
* don't have to be perfect here, we just have to be good.
在选择合适的进程时,OOM Killer会挑选一个占用内存最大的进程,这也很好理解,毕竟kill掉一个大的可以获得更多的物理内存,并且损失也比较小。如果kill掉多个小的,损失会比较大。Linux内核总是去选择更高效的方法。