前端智能化D2C到底怎么样了,带你一睹为快
前言
前端近年来一直在尝试如何提高开发人员的效率,从最初的脚手架工具、组件库、持续集成体系、自动化测试、多端适配到现在的全面的低代码平台、前端智能化、在线 IDE,大家都在为未来的新的且高效率的方式做着努力。
前端行业即将要进入到下一个阶段,因为对于如何搭建组件库、脚手架已经有大量的文章/教程,已经快到了人人可以手撕一个组件库的阶段了,并且随着前端开发人员的技术的普遍提高,枯燥机械式地写代码(样式/布局)已经无法满足开发人员日益增长的追逐技术的心了,因此需要智能化布局来解放这些枯燥的工作。
落后就要挨打,我就打算趁着周末打算探索一下前端智能化。(本人也是新手,纯是感兴趣~,因此不用担心看不懂)

发展历程
其实要说从设计稿转化为 html 的项目,最早可以溯源为 PS(Photoshop) 的导出 html 功能,PS(Photoshop) 可谓是一个老牌的设计产品,从1988年首次发布新版本,到现在仍然在更新。
我们来体验一下这个功能。
首先打开 PS, 导入一张网上随便下载的图片,将 图片 拖进 PS。然后按照以下步骤进行操作。
2.拖出辅助线,拖出分割块
3.选择切片工具(裁剪工具那一个图标按右键)
4.选择顶部的基于参考线切片
5.文件 - 导出 - 储存为 web 所用格式
就能看到导出了以下几个文件。(我这里切的比较粗糙如果是精细地将一张图片进行切片,应该是非常符合web 的所用格式的,毕竟很久以前,设计师就是这么给我们切片的)

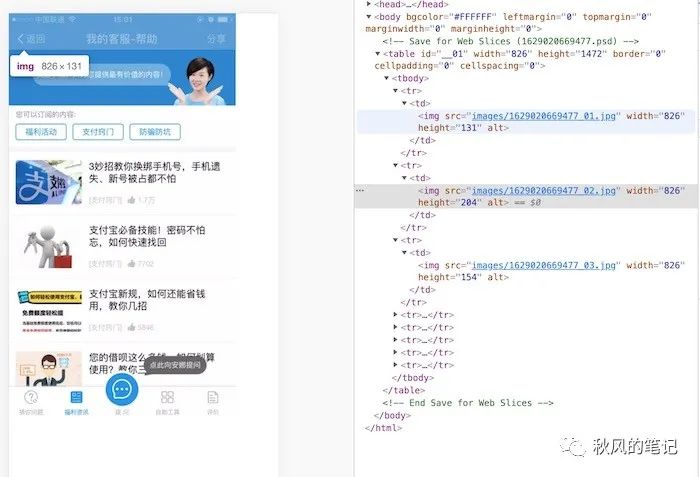
发现它主要以 table 的方式来布局,但是这样的形式,在日益繁多的设备上是无法使用的(可能在当时的PC上还能有不错的应用场景。)
前端当时正处于萌芽阶段,前端智能化的概念还没有被提出,没有 Vue、React,没有工程化,也没有低代码,一切都是刚刚起步,前端智能化也没有被提及。
直到2017年,一篇 pix2code: Generating Code from a Graphical User Interface Screenshot[1] 的论文引起了业界的关注,该论文实现了从一张 UI 截图识别生成了 UI 结构,并且将 UI 结构描述转化成了 HTML 代码。
随后,基于 pix2code 开发的 Screenshot2Code[2] 项目速度进入到 Github 排行榜第一,该工具能够将 UI 截图转成 HTML 代码,该项目作者号称 3 年后人工智能会彻底改变前端开发。
2018 年,微软 AI Lab 开源了草图转代码工具 Sketch2Code[3],一些人认为生成代码效果不理想不适用于生产环境,但也有人认为代码自动生成还处于初级阶段,未来发展值得想象。
工作流:
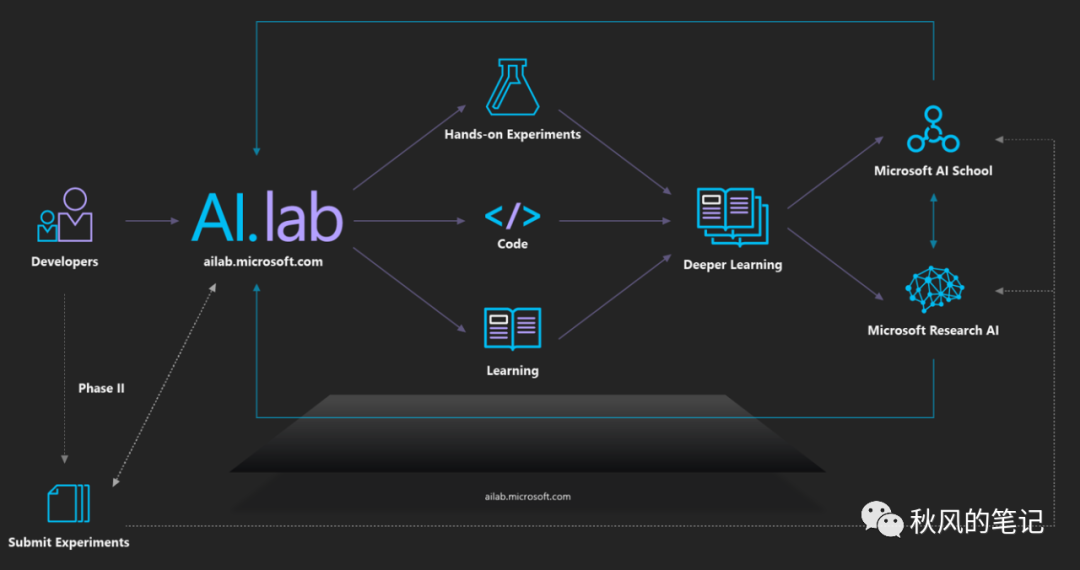
效果实现:

一直到2019年, D2 前端论坛(Designer & Developer Frontend Technology Forum, 简称D2)发布了 imgcook ,前端智能化这个词正式确立了。
随后58集团、CodeFun等 都相继发布了智能化的产品,但是这个行业是年轻的,也是具有挑战的,这些产品的都还在初期,虽然没办法全方面的得到开发者的青睐,但是都已经有一些不错的落地场景了。
项目体验
设计稿:demo.sketch
代码与sketch下载地址:https://github.com/nan980914/ui2code-demo
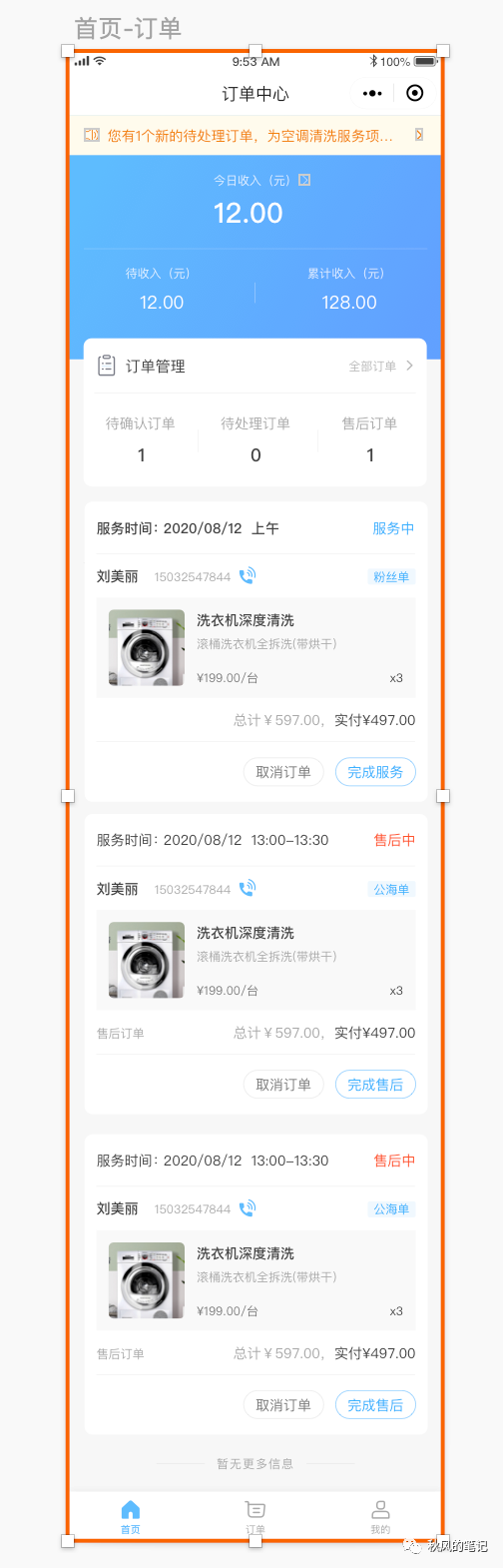
这次将分别体验58的 Picasso、imgcook、CodeFun 3款工具的「sketch设计稿转代码」。
我们将以平常写代码中比较重视的几个部分来对这三款软件进行分析:
- 是否可以还原设计稿
- 布局识别的准确性
- 代码(css)可维护性(代码量,定宽定高,flex)
- List自动识别,分组
- 列表循环识别
其中第一点是最基本的,因为如果一个D2C(Design To Code)工具,抛开一些布局之外,连基本的设计稿都无法1:1 还原的话,对我们开发的工作量来说太巨大了,这就好比某个同事已经写了一个半成品项目了,这个时候他突然有事请假了,需要我们去帮忙结尾,这个时候我们需要去看别人的代码,再去修改。每每这个时候心里都会念叨,还不如自己重新写一个项目。



对于第四点和第五点,算是写代码的复用小能手,对于一个 list 我们一般不会去在 html 写死成多个 块,而是会用循环舒服,减少重复代码,也是为了能够和后端进行适配。
58 Picasso(https://github.com/wuba/Picasso)
操作流程:
Picasso的Github仓库[4]上下载其sketch插件毕加索,在sketch中选中我们的画板后生成Web代码。
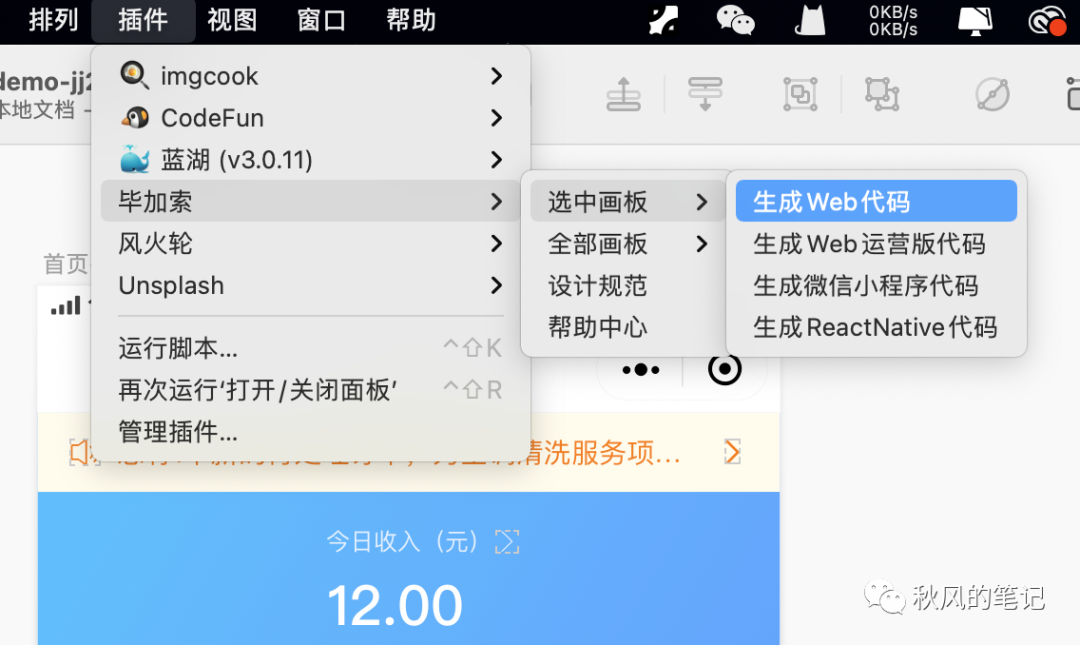
然后就导出了这样一个文件,让我们打开index.html来看看效果。
1.是否还原设计稿:
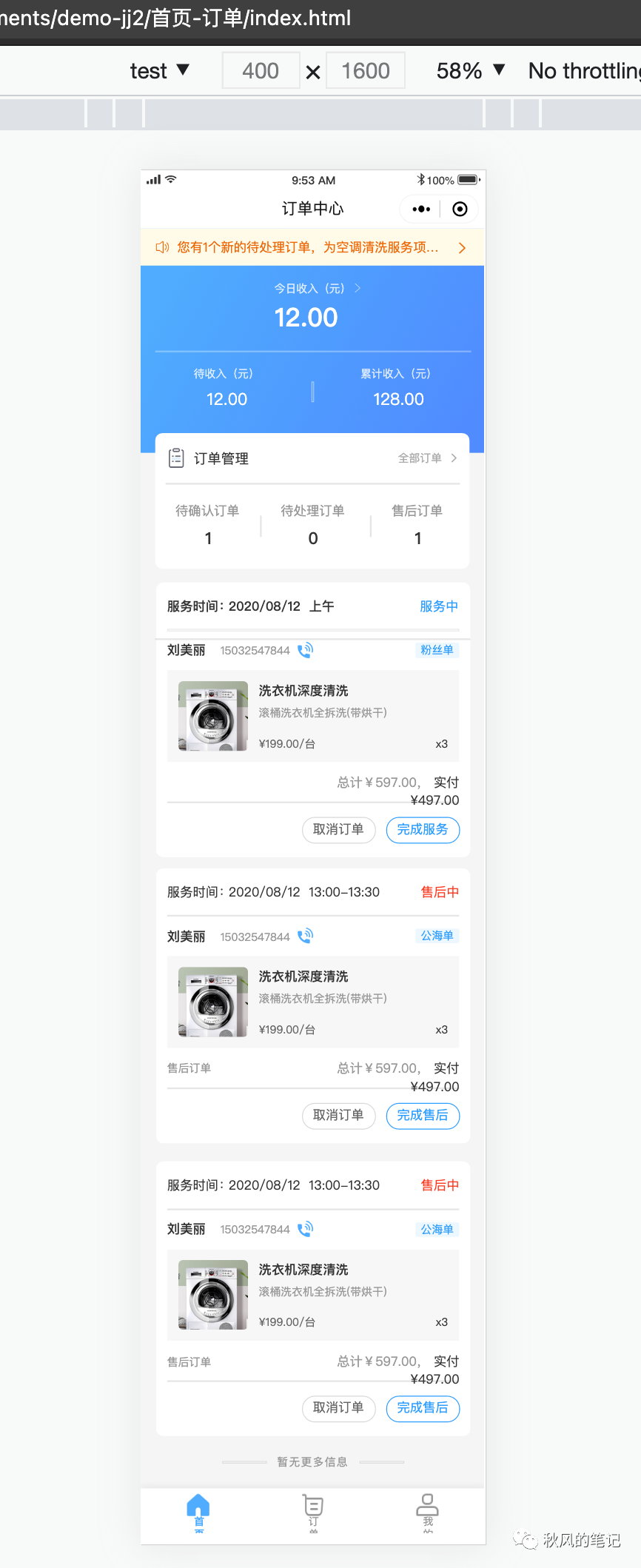
怎么说呢,可以看到58Picasso这个还原效果其实除了订单的实付价格那里不知道怎么被挤下去了,和底部footer的样式错乱以外看起来还可以,那我们来看看代码到底怎么样。
2.布局识别的准确性:
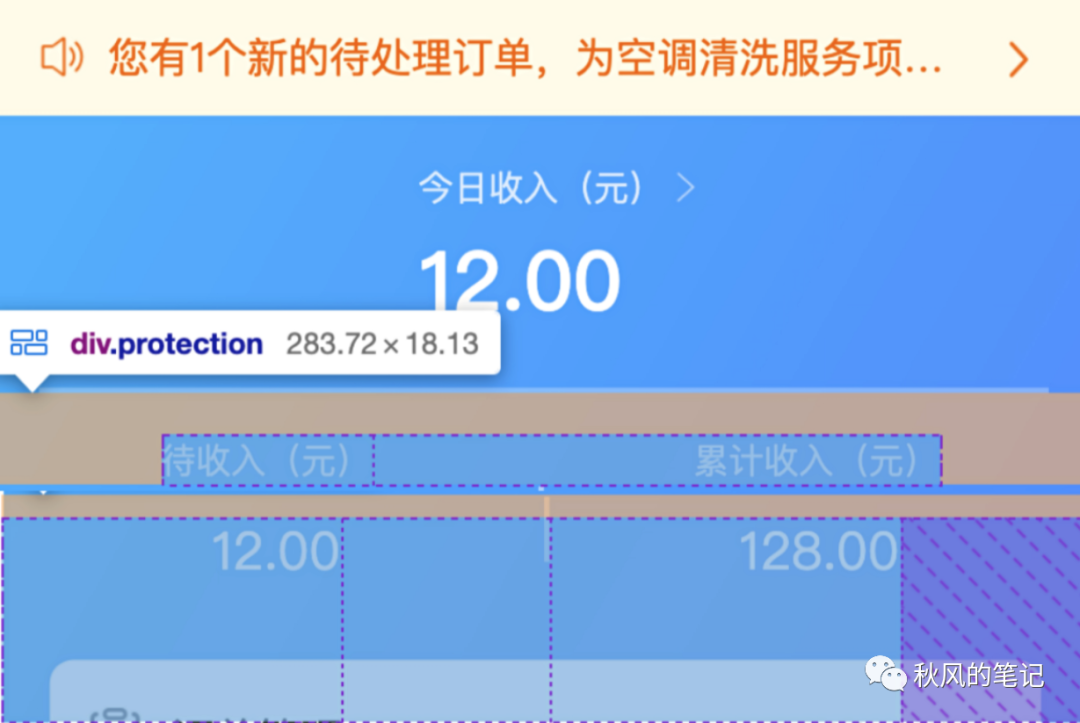
我们期待的是两个左右结构的块,却被识别成了这个样子...
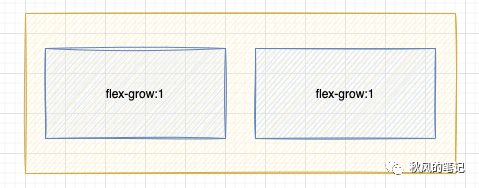
虽然以上采用了 flex 布局,但是并没有等分布局,并且也被定宽了,我们希望的是:
3. 代码可维护性:
index.css生成1289行。

1.累赘的类名
它给每一个div元素都设置了一个英文单词,并且与当前的模块的语义化严重不符。
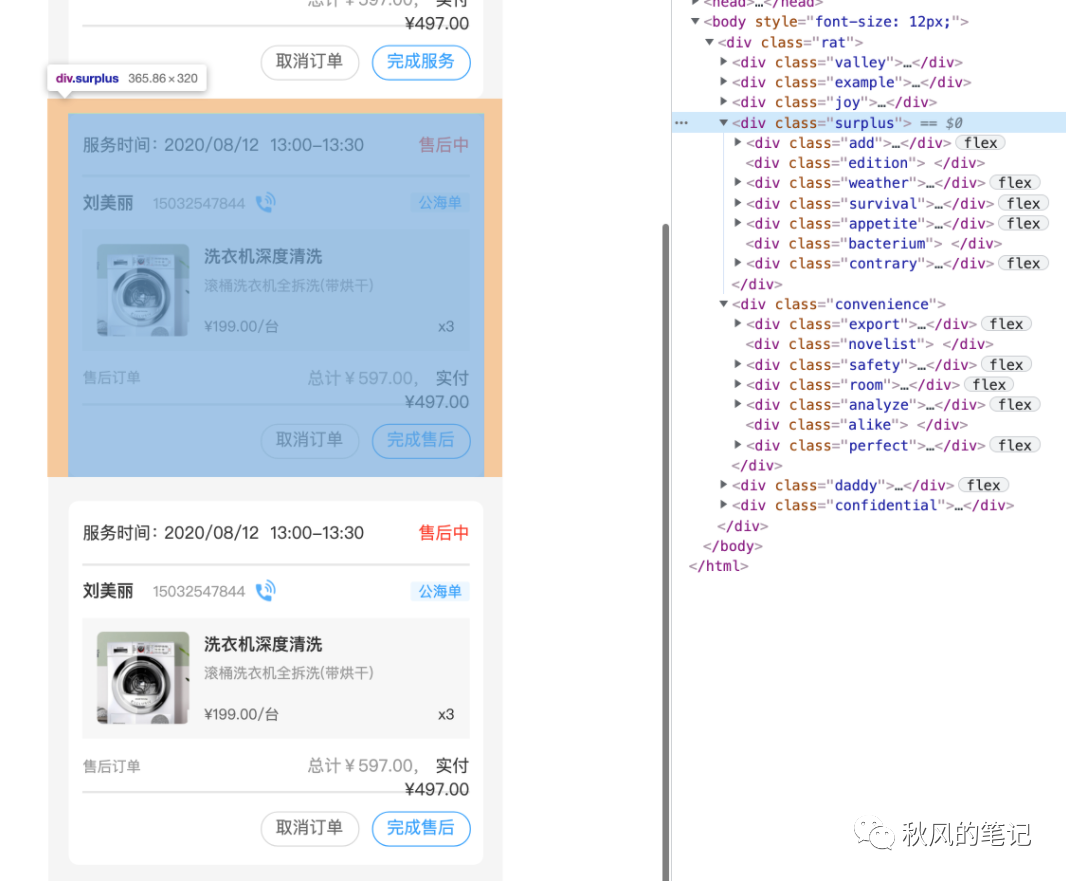
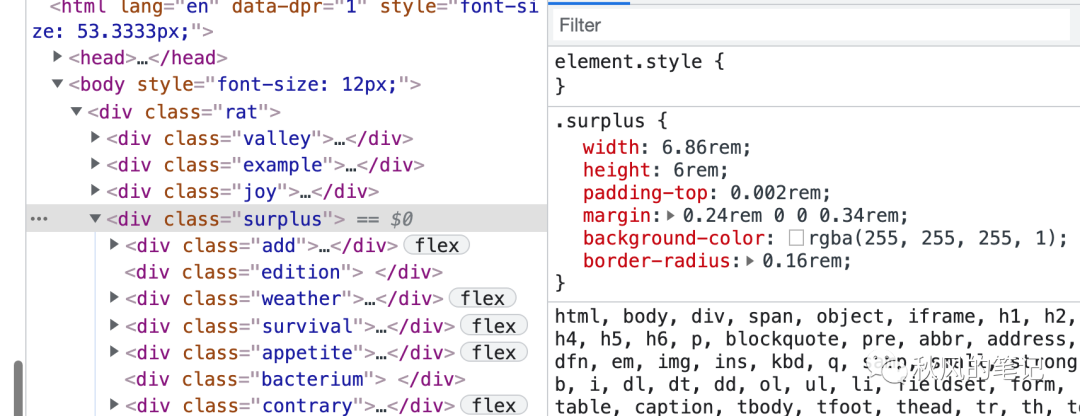
2.定宽定高
由于它给每个div都是定宽定高的,因此也产生了许多不必要的代码。
3.同类型无法合并
由于没有办法归类相同的元素,因此代码也变得更多了。
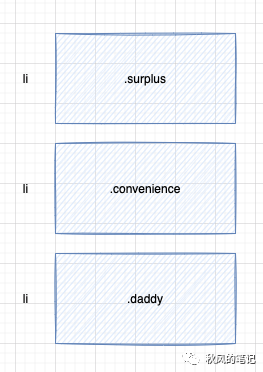
4. List自动识别,分组
分析这个设计稿我们可以看出来,下面三个订单的块其实是非常相似的结构,我们希望生成的代码能把相似的结构识别出来并分在同一个组内而不是平铺。
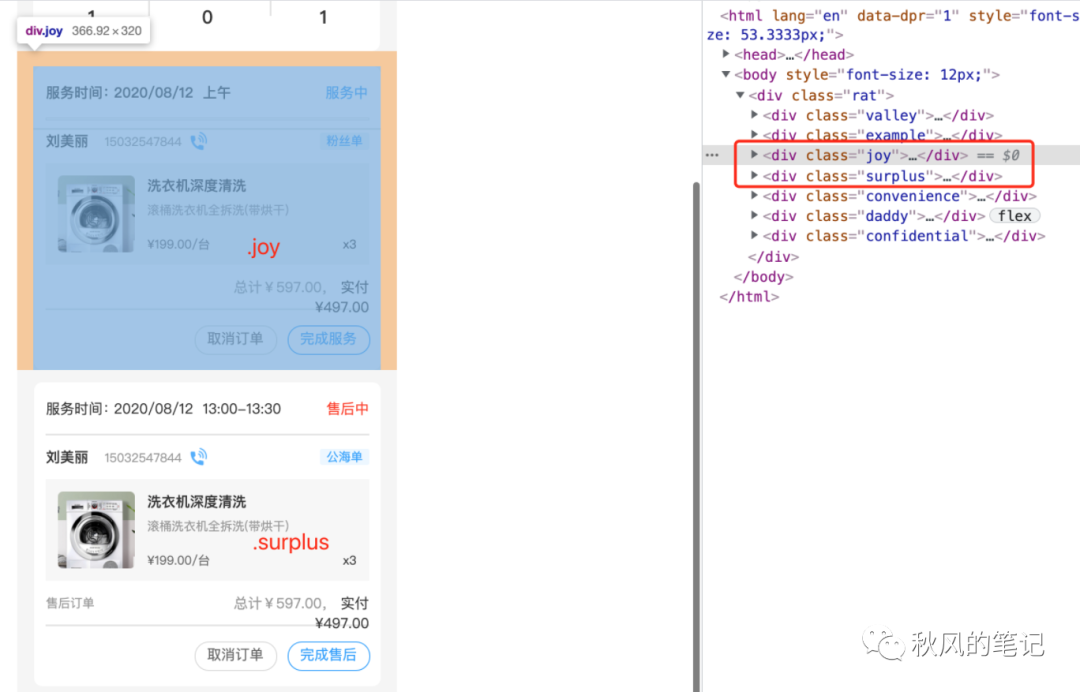
连 list 都没有识别好,那就没有第五步了,总结起来这样的代码,仿佛就是同事甩的锅一样,难以维护,有这时间看代码和修复代码,自己已经写好一个完美版本了。
5.总结
所以 Picasso 距离工业化代码还是有一定差距的,不过 Picasso 的代码是开源的,里面的布局方案是通过图层解析出DSL,然后再通过一定的算法生成的代码。
imgcook(https://www.imgcook.com/)
流程:
imgcook的官网[5]上下载其sketch插件,在 sketch 中打开插件的面板选择导出代码导出到我们的项目,然后就可以去官网我们的项目里查看。
1.是否还原设计稿:
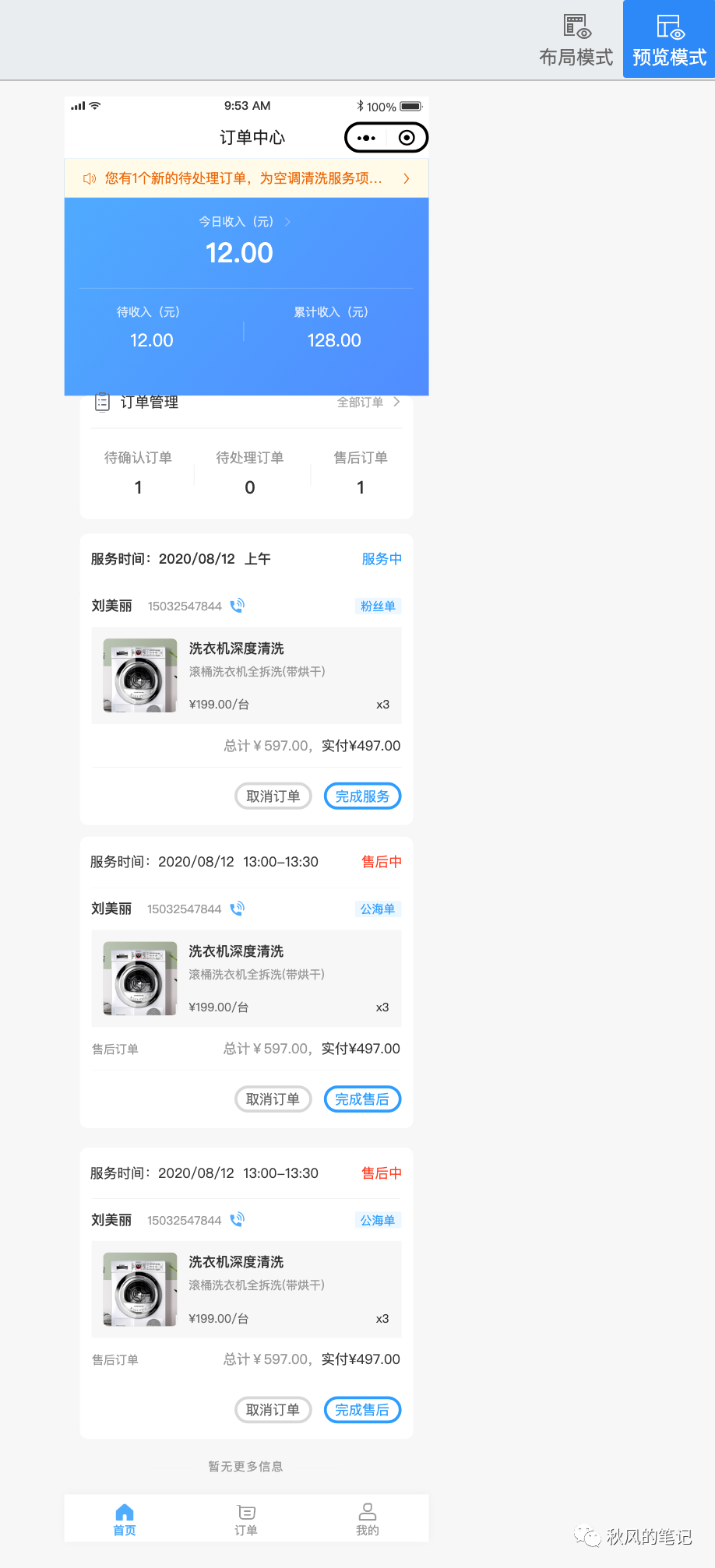
由图可以看到,imgcook 貌似都没有把设计稿还原。

2.布局识别的准确性:
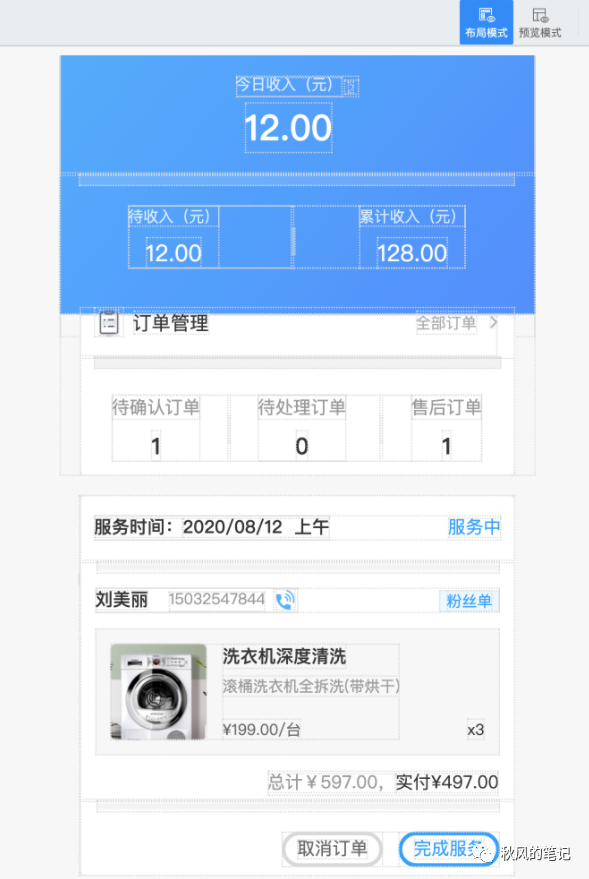
仔细看其布局,其实识别的比上面 58 Picasso 的准确很多,比较符合我们日常写代码的习惯,但是依旧被定了宽度。
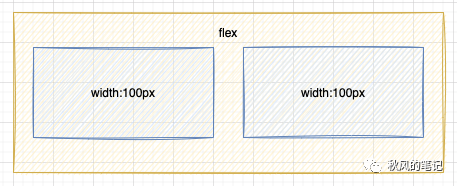
3. 代码可维护性:
CSS 生成1870行...冗余代码非常多。
其实这部分还是和 58 Picasso 一样的问题的。累赘的类名,定宽定高,并且同类型没有合并(暂时没有找到如何合并),还有些是通过 absolute 来布局的。

4. List自动识别,分组
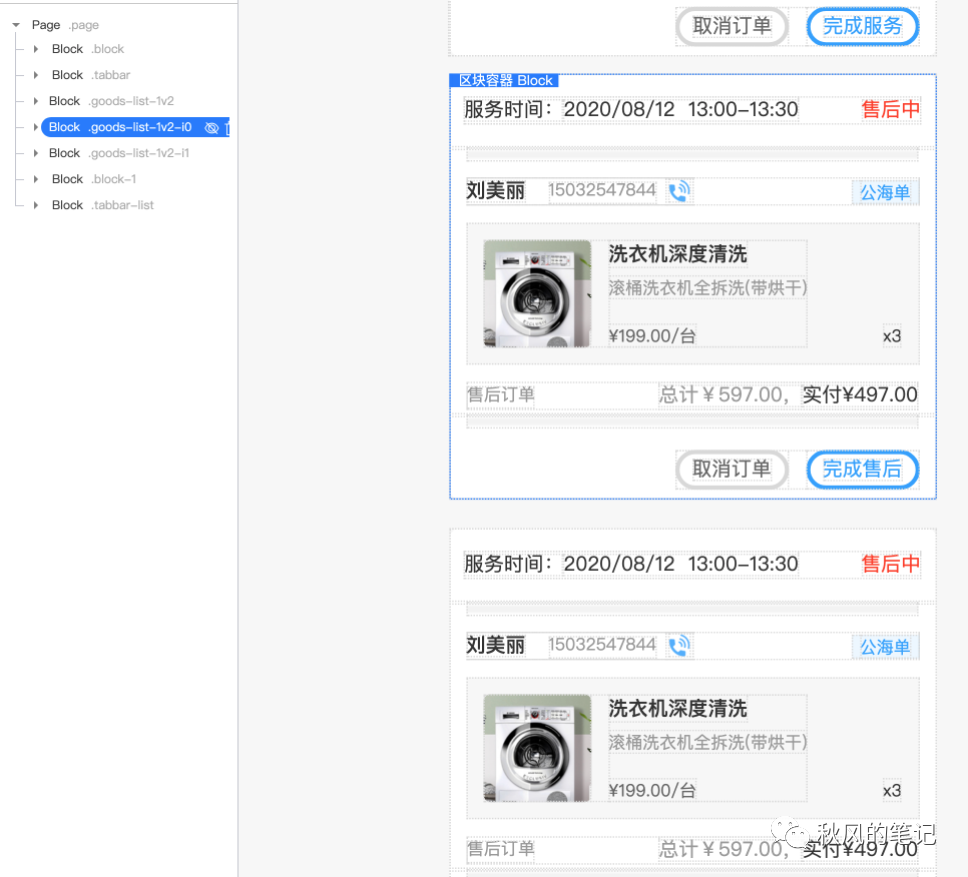
这里也和58 Picasso 有点类似,貌似效果还是不太理想。也是没有很好地将 list 进行识别。
imgcook 也算是一个做了比较久的产品了,可见D2C的难度还是非常大的,对于算法的要求很高。

5.总结
Imgcook 比 58 Picasso 改进了许多,加入了 AI 来训练模型,准确度和可用性都比Picasso 好很多。并且模型训练框架 pipcook[6] 也开源在 github 上面。
CodeFun(https://code.fun/)
流程:
CodeFun的官网[7]上下载其sketch插件,在sketch中打开插件的面板选择上传此设计稿,然后就可以去官网我们的项目里查看。
1.是否还原设计稿:
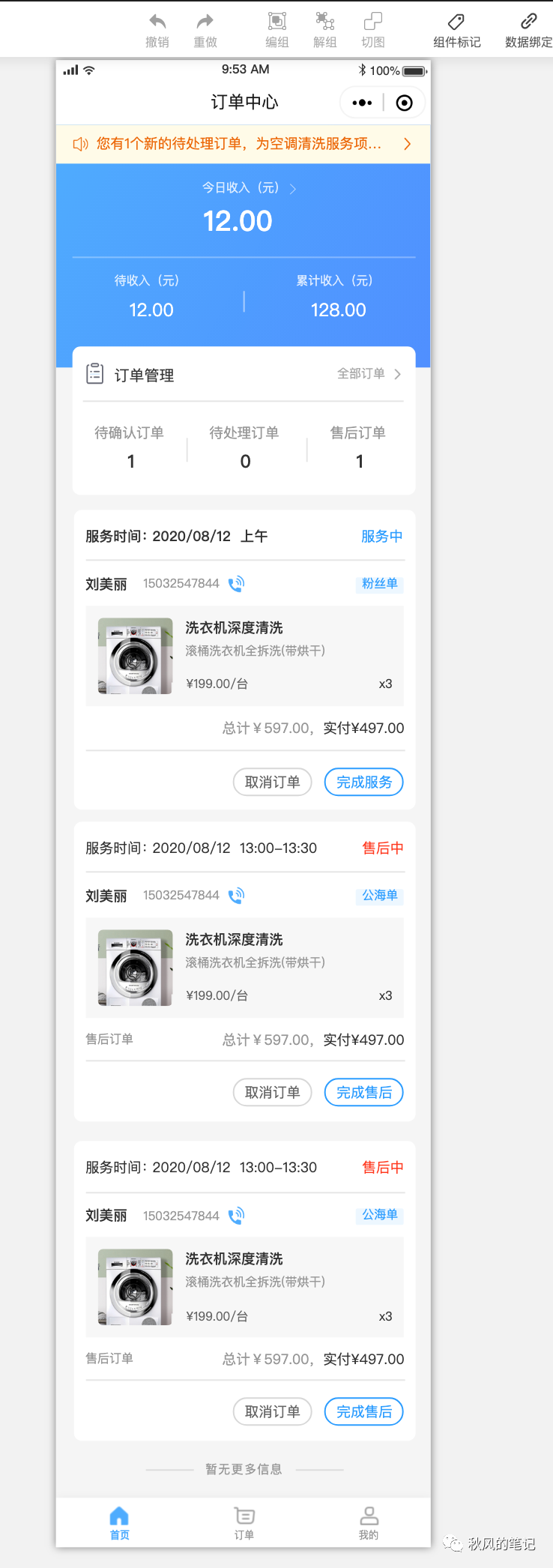
很惊喜,CodeFun 这个还原的比上面两者都要好,和设计稿看起来几乎100%。

2. 布局识别的准确性:
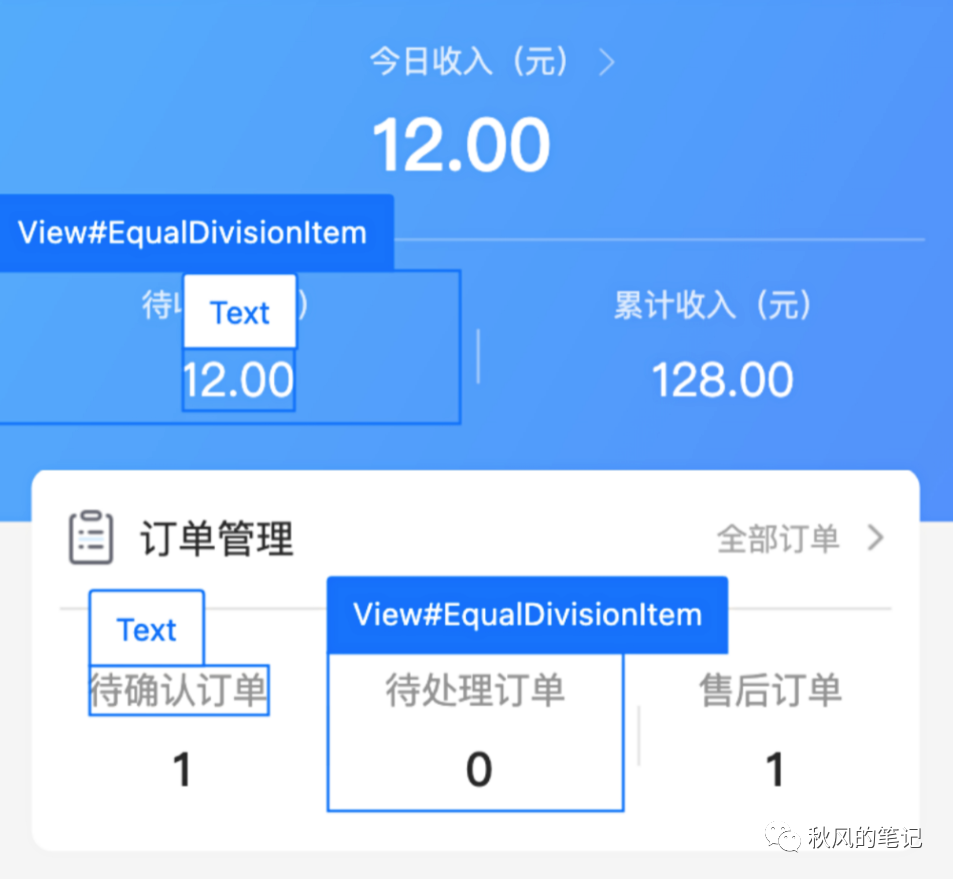
完美的识别出了我们期待的布局,但是这里要提一下的是,CodeFun 不仅识别除了均分的 flex 布局,而且相比 imgcook 没有定宽,而是使用了flex-grow:1
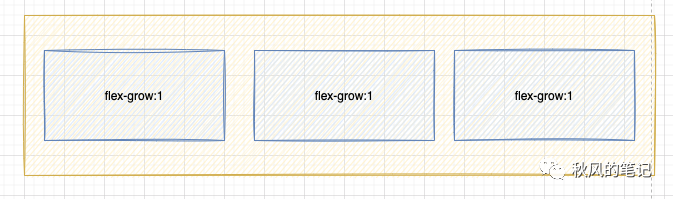
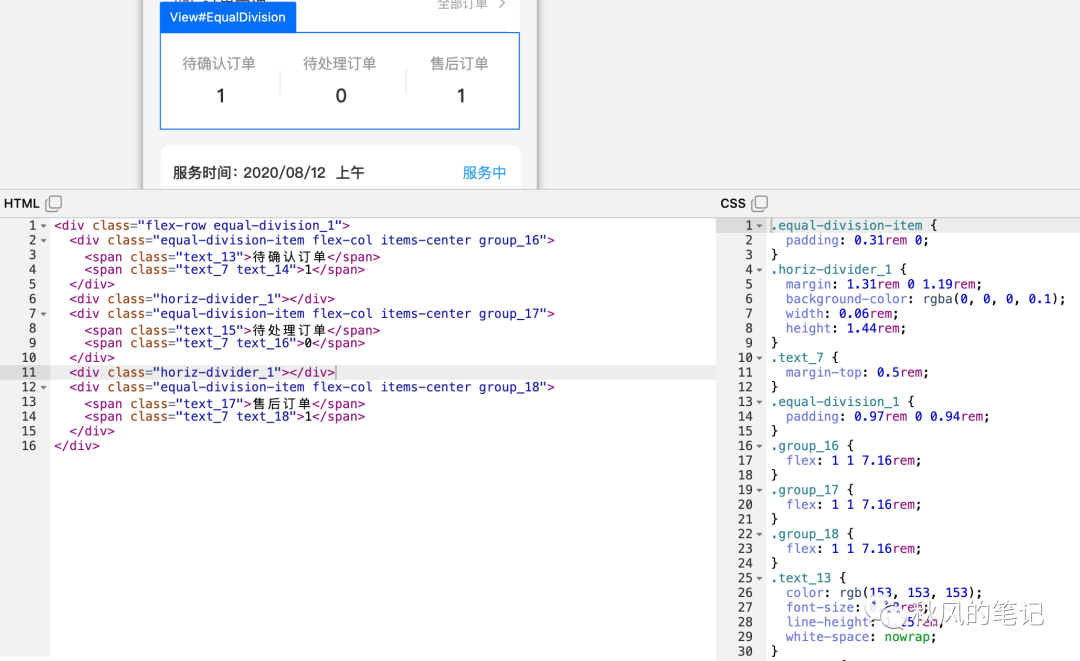
equal-division-item这个class里面,几个box都共享上了,唯独flex-grow:1被单独弄成了group_16 17 18,造成了一些冗余的css代码,这么复杂的识别都做到了,这里是不是个bug呢?
3. 代码可维护性
css 代码生成 597 + 81 = 678 行(主代码+公共代码),比Picasso的1289行和imgcook的1870行分别减少了47%和64%。
虽然类名还是有些不语义化,但是已经是去除了写死的宽高,同类型进行了合并抽取出了公共代码。
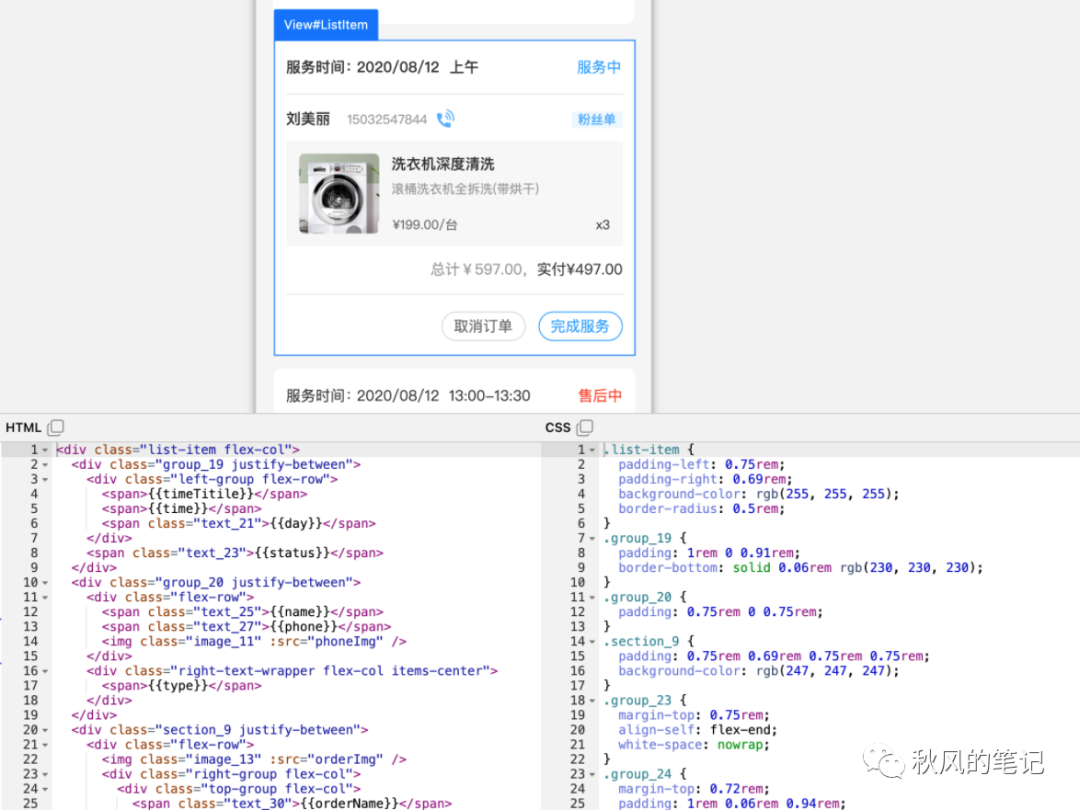
4. List自动识别,分组
CodeFun 能自动识别出下面三个结构相似的订单模块,并进行分组,将三个块外面包了一个wrapper,符合我们开发人员日常写代码的习惯。
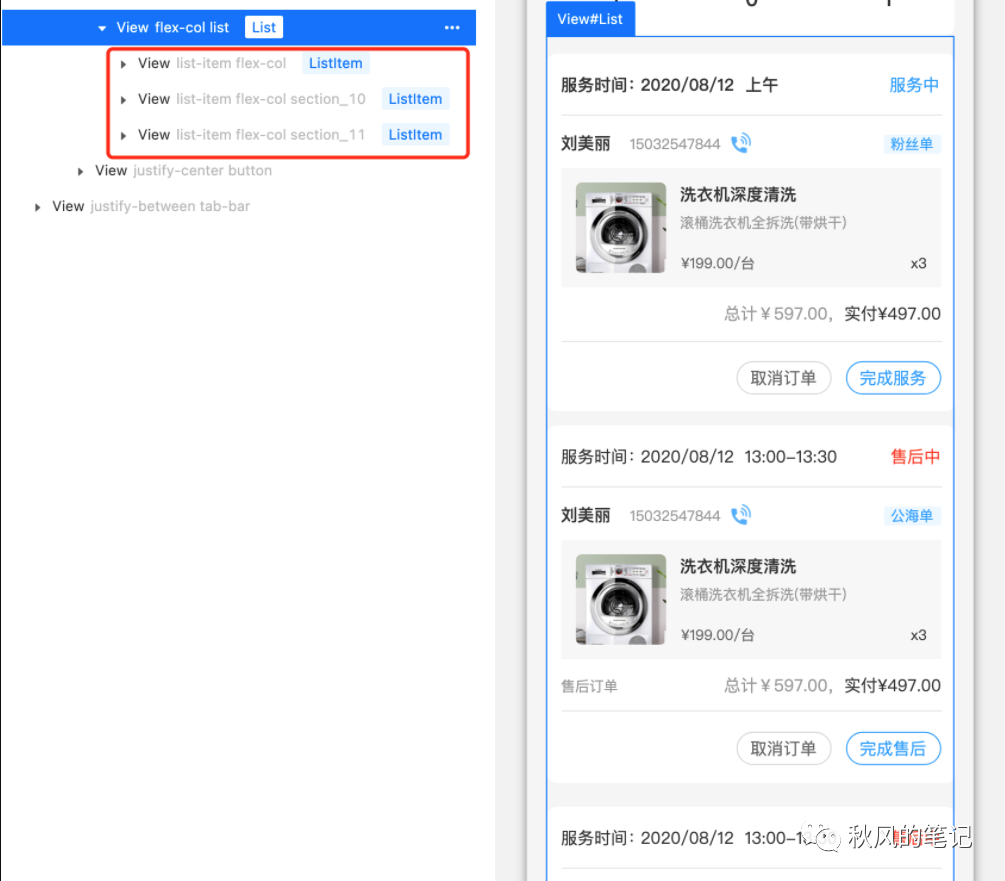
5. 列表循环识别
因为已经识别出了下面三个结构相似的模块,于是vue代码会自动以v-for列表循环的方式展现。
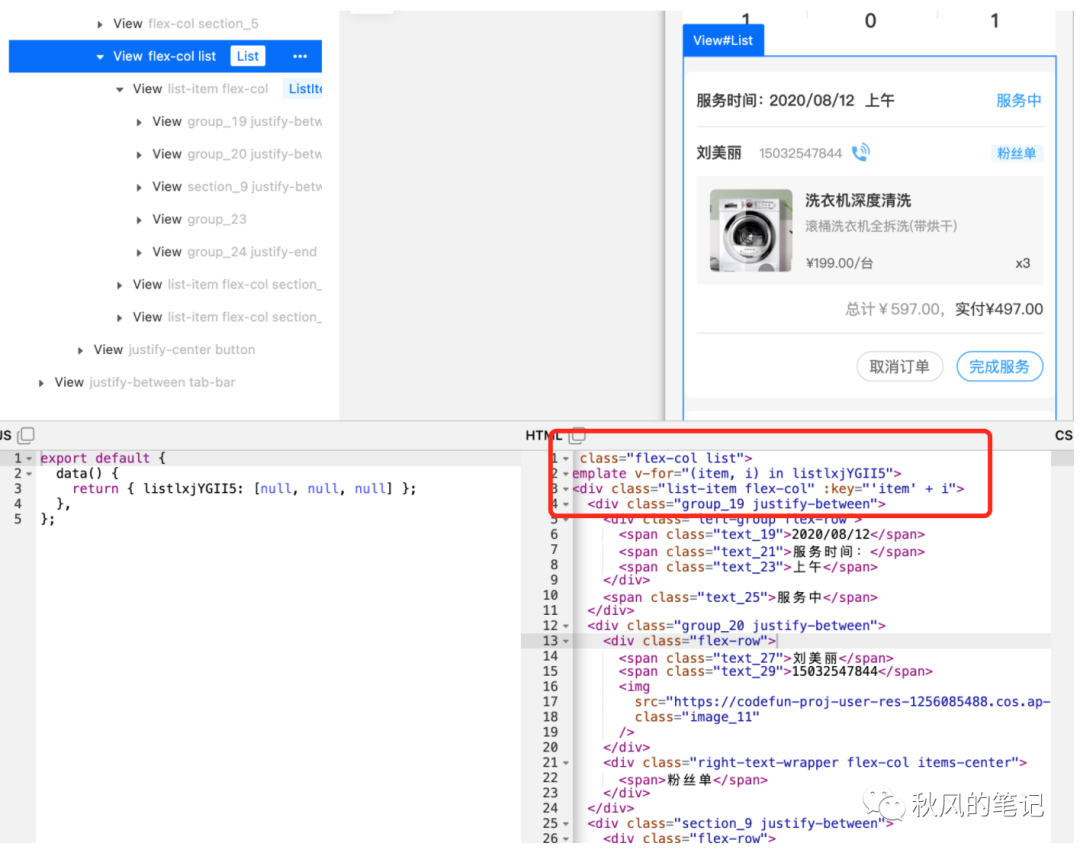
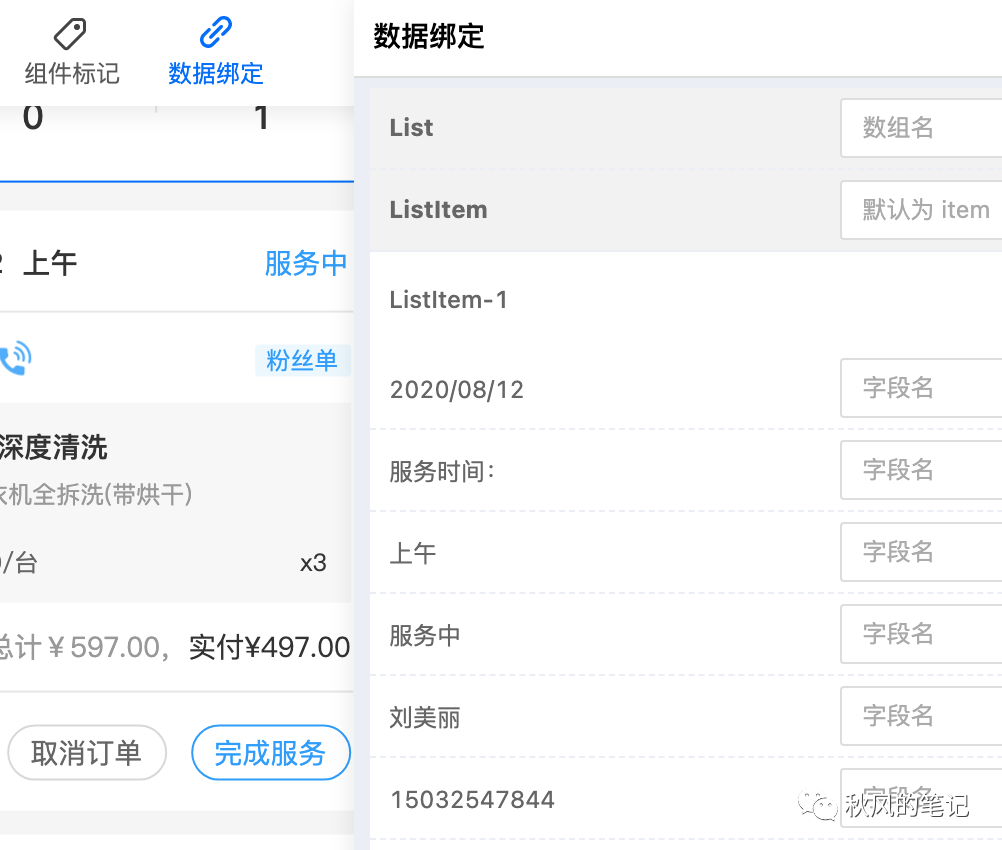
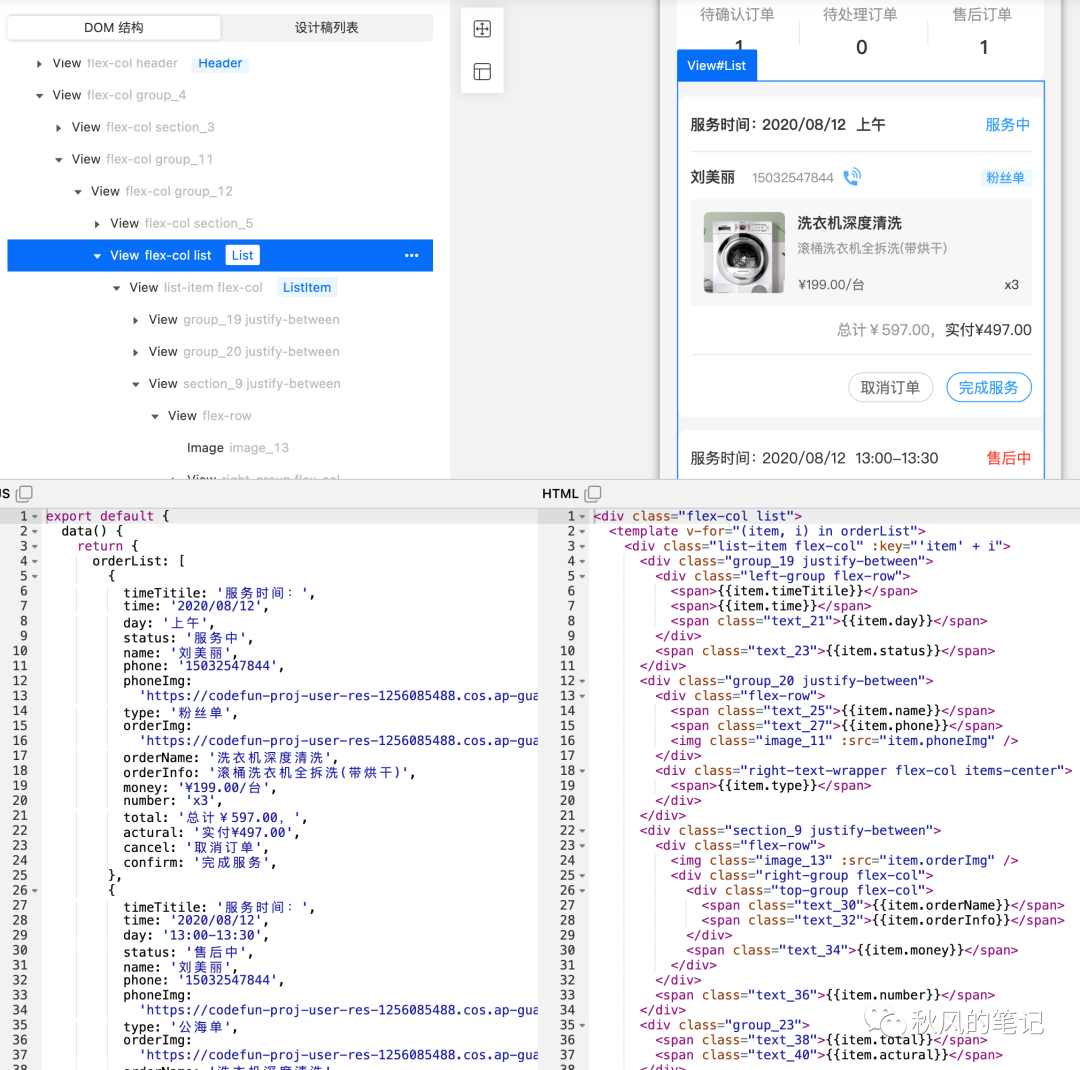
6. 总结
评测 CodeFun 的时候,还是眼前一亮的,虽然说对于类名上,还是需要自己进行修改(不过对于一些维护不需要这么频繁的页面,也可以不进行修改类名),但是对于以上我列出的 5 点都已经完美地进行解析了。CodeFun也是通过AI模型来进行智能化训练,但训练的效果比imgcook更加强大。
结论
| CodeFun | imgcook | 58 Picasso | |
|---|---|---|---|
| 支持语言 | Vue/React/微信小程序/Taro(vue)/uni-app | 支持15余种DSL | Html/微信小程序/Reactive Native |
| 是否还原设计稿 | 是 | 否 | 否 |
| 布局识别的准确性 | 高 | 较高 | 低 |
| 示例sketch导出后css代码量(行) | 678 | 1870 | 1289 |
| 代码可维护性 | 好 | 较好 | 一般 |
| 数据绑定 | 支持 | 支持 | 不支持 |
| 准确度 | 高 | 一般 | 低 |
| 评星 | ⭐️⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️ |
代码量计算:导出所有的代码(html+css+js)- 无用的初始化代码(例如reset.css)
代码可维护性:节点变动、位置变动、样式变动、属性变动(https://juejin.cn/post/6911879030559997966#heading-21)
未来与展望
通过这一次的评测,也了解了一些前端智能化的知识以及现有平台的支撑程度。发现前端智能化在未来的道路上还是能帮助我们提高效率的,至少在页面还原度上面,还是非常的完美的,不需要不断地和设计扯皮了,并且也不用当个切图仔了,能够把生产力聚焦于写 JS , 写页面的逻辑(仿佛和后端工程是差不多了,只需要关注逻辑与数据)。
毕竟200年以前你告诉中国人以后不会再有皇帝,他们会告诉你自盘古开天地啥时候没有过皇帝?只要我们敢想没有什么不可能。像现阶段,自动驾驶、人脸识别 无论哪项技术的成熟,都对我们的行业产生巨大的影响。
前端也不例外,前端智能化、Web AR/VR、前端低代码、前端跨端每一项的成熟,都会给我们带来颠覆性的影响。
未来可期!
参考资料
[1]pix2code: Generating Code from a Graphical User Interface Screenshot: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1705.07962
[2]Screenshot2Code: https://link.zhihu.com/?target=https%3A//github.com/emilwallner/Screenshot-to-code
[3]Sketch2Code: https://link.zhihu.com/?target=https%3A//github.com/Microsoft/ailab/tree/master/Sketch2Code
[4]Picasso的Github仓库: https://github.com/wuba/Picasso
[5]imgcook的官网: https://www.imgcook.com/
[6]pipcook: https://github.com/alibaba/pipcook
[7]CodeFun的官网: https://code.fun/