图解 | Linux进程通信 - 管道实现
处于安全的考虑,不同进程之间的内存空间是相互隔离的,也就是说 进程A 是不能访问 进程B 的内存空间,反之亦然。如果不同进程间能够相互访问和修改对方的内存,那么当前进程的内存就有可能被其他进程非法修改,从而导致安全隐患。
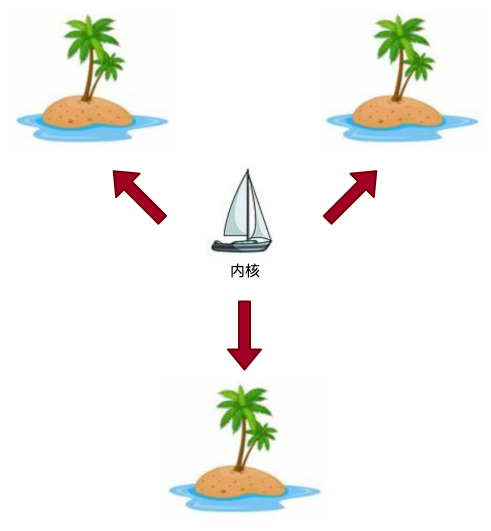
不同的进程就像是大海上孤立的岛屿,它们之间不能直接相互通信,如下图所示:

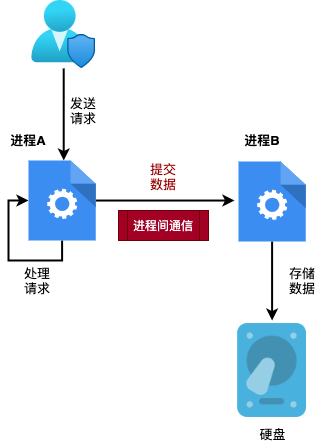
但某些场景下,不同进程间需要相互通信,比如:进程A 负责处理用户的请求,而 进程B 负责保存处理后的数据。那么当 进程A 处理完请求后,就需要把处理后的数据提交给 进程B 进行存储。此时,进程A 就需要与 进程B 进行通信。如下图所示:
由于不同进程间是相互隔离的,所以必须借助内核来作为桥梁来进行相互通信,内核相当于岛屿之间的轮船,如下图所示:
内核提供多种进程间通信的方式,如:共享内存,信号,消息队列 和 管道(pipe) 等。本文主要介绍 管道 的原理与实现。
一、管道的使用
管道 一般用于父子进程之间相互通信,一般的用法如下:
- 父进程使用
pipe系统调用创建一个管道。 - 然后父进程使用
fork系统调用创建一个子进程。 - 由于子进程会继承父进程打开的文件句柄,所以父子进程可以通过新创建的管道进行通信。
其原理如下图所示:
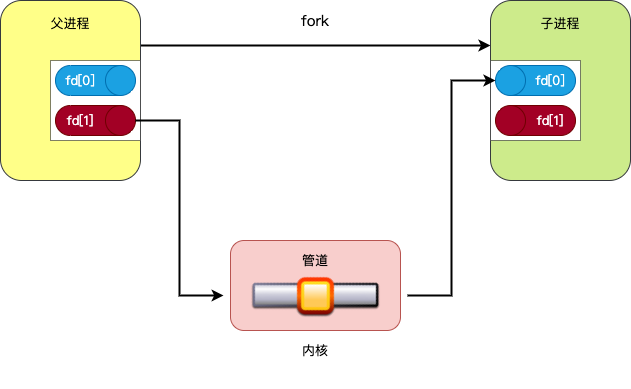
由于管道分为读端和写端,所以需要两个文件描述符来管理管道:fd[0] 为读端,fd[1] 为写端。
下面代码介绍了怎么使用 pipe 系统调用来创建一个管道:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <stdlib.h>
#include <string.h>
int main()
{
int ret = -1;
int fd[2]; // 用于管理管道的文件描述符
pid_t pid;
char buf[512] = {0};
char *msg = "hello world";
// 创建一个管理
ret = pipe(fd);
if (-1 == ret) {
printf("failed to create pipe\n");
return -1;
}
pid = fork(); // 创建子进程
if (0 == pid) { // 子进程
close(fd[0]); // 关闭管道的读端
ret = write(fd[1], msg, strlen(msg)); // 向管道写端写入数据
exit(0);
} else { // 父进程
close(fd[1]); // 关闭管道的写端
ret = read(fd[0], buf, sizeof(buf)); // 从管道的读端读取数据
printf("parent read %d bytes data: %s\n", ret, buf);
}
return 0;
}编译代码:
[root@localhost pipe]# gcc -g pipe.c -o pipe
运行代码,输出结果如下:
[root@localhost pipe]# ./pipe
parent read 11 bytes data: hello world二、管道的实现
每个进程的用户空间都是独立的,但内核空间却是共用的。所以,进程间通信必须由内核提供服务。前面介绍了 管道(pipe) 的使用,接下来将会介绍管道在内核中的实现方式。
本文使用 Linux-2.6.23 内核作为分析对象。
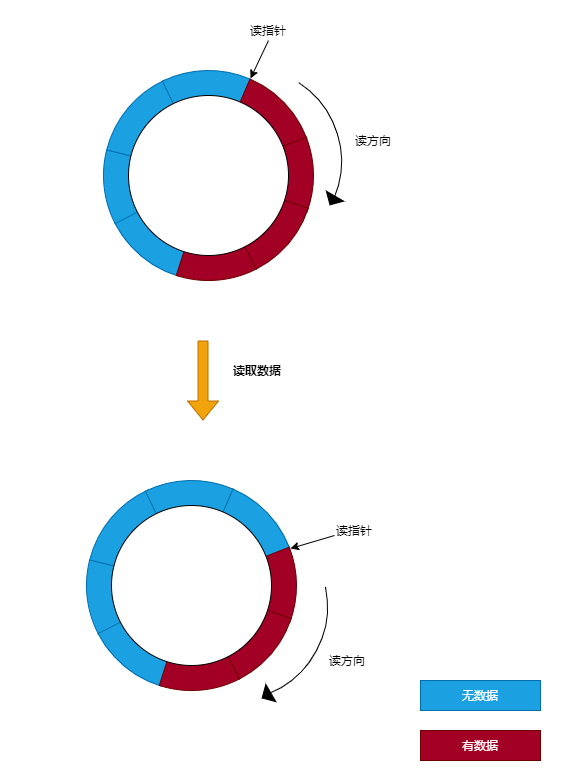
1. 环形缓冲区(Ring Buffer)
在内核中,管道 使用了环形缓冲区来存储数据。环形缓冲区的原理是:把一个缓冲区当成是首尾相连的环,其中通过读指针和写指针来记录读操作和写操作位置。如下图所示:
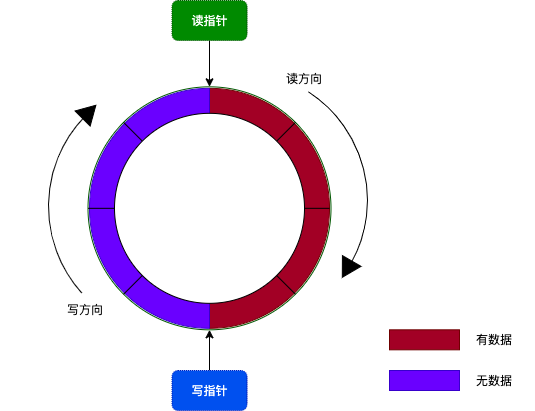
在 Linux 内核中,使用了 16 个内存页作为环形缓冲区,所以这个环形缓冲区的大小为 64KB(16 * 4KB)。
当向管道写数据时,从写指针指向的位置开始写入,并且将写指针向前移动。而从管道读取数据时,从读指针开始读入,并且将读指针向前移动。当对没有数据可读的管道进行读操作,将会阻塞当前进程。而对没有空闲空间的管道进行写操作,也会阻塞当前进程。
注意:可以将管道文件描述符设置为非阻塞,这样对管道进行读写操作时,就不会阻塞当前进程。
2. 管道对象
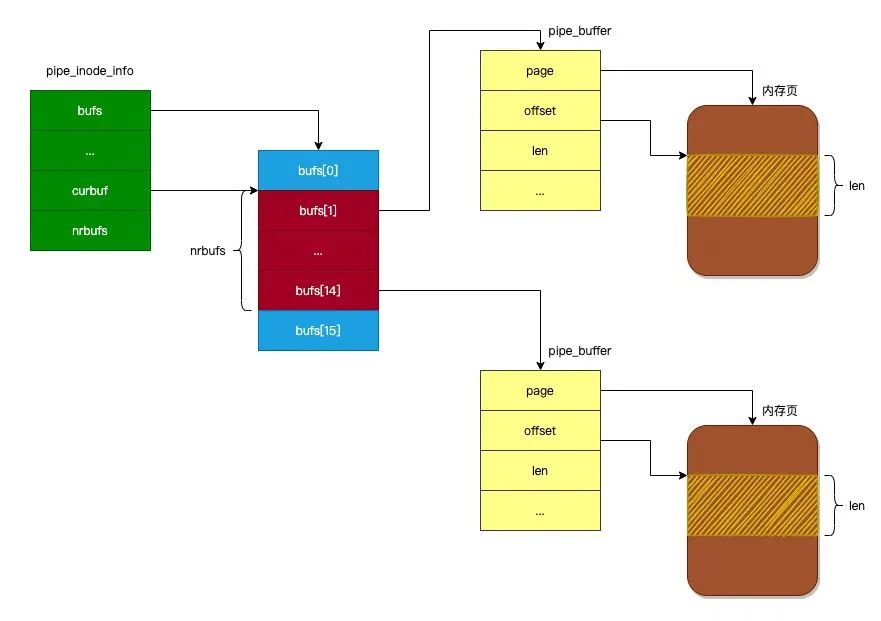
在 Linux 内核中,管道使用 pipe_inode_info 对象来进行管理。我们先来看看 pipe_inode_info 对象的定义,如下所示:
struct pipe_inode_info {
wait_queue_head_t wait;
unsigned int nrbufs,
unsigned int curbuf;
...
unsigned int readers;
unsigned int writers;
unsigned int waiting_writers;
...
struct inode *inode;
struct pipe_buffer bufs[16];
};下面介绍一下 pipe_inode_info 对象各个字段的作用:
wait:等待队列,用于存储正在等待管道可读或者可写的进程。bufs:环形缓冲区,由 16 个pipe_buffer对象组成,每个pipe_buffer对象拥有一个内存页 ,后面会介绍。nrbufs:表示未读数据已经占用了环形缓冲区的多少个内存页。curbuf:表示当前正在读取环形缓冲区的哪个内存页中的数据。readers:表示正在读取管道的进程数。writers:表示正在写入管道的进程数。waiting_writers:表示等待管道可写的进程数。inode:与管道关联的inode对象。
由于环形缓冲区是由 16 个 pipe_buffer 对象组成,所以下面我们来看看 pipe_buffer 对象的定义:
struct pipe_buffer {
struct page *page;
unsigned int offset;
unsigned int len;
...
};下面介绍一下 pipe_buffer 对象各个字段的作用:
page:指向pipe_buffer对象占用的内存页。offset:如果进程正在读取当前内存页的数据,那么offset指向正在读取当前内存页的偏移量。len:表示当前内存页拥有未读数据的长度。
下图展示了 pipe_inode_info 对象与 pipe_buffer 对象的关系:
管道的环形缓冲区实现方式与经典的环形缓冲区实现方式有点区别,经典的环形缓冲区一般先申请一块地址连续的内存块,然后通过读指针与写指针来对读操作与写操作进行定位。
但为了减少对内存的使用,内核不会在创建管道时就申请 64K 的内存块,而是在进程向管道写入数据时,按需来申请内存。
那么当进程从管道读取数据时,内核怎么处理呢?下面我们来看看管道读操作的实现方式。
3. 读操作
从 经典的环形缓冲区 中读取数据时,首先通过读指针来定位到读取数据的起始地址,然后判断环形缓冲区中是否有数据可读,如果有就从环形缓冲区中读取数据到用户空间的缓冲区中。如下图所示:
而 管道的环形缓冲区 与 经典的环形缓冲区 实现稍有不同,管道的环形缓冲区 其读指针是由 pipe_inode_info 对象的 curbuf 字段与 pipe_buffer 对象的 offset 字段组合而成:
pipe_inode_info对象的curbuf字段表示读操作要从bufs数组的哪个pipe_buffer中读取数据。pipe_buffer对象的offset字段表示读操作要从内存页的哪个位置开始读取数据。
读取数据的过程如下图所示:
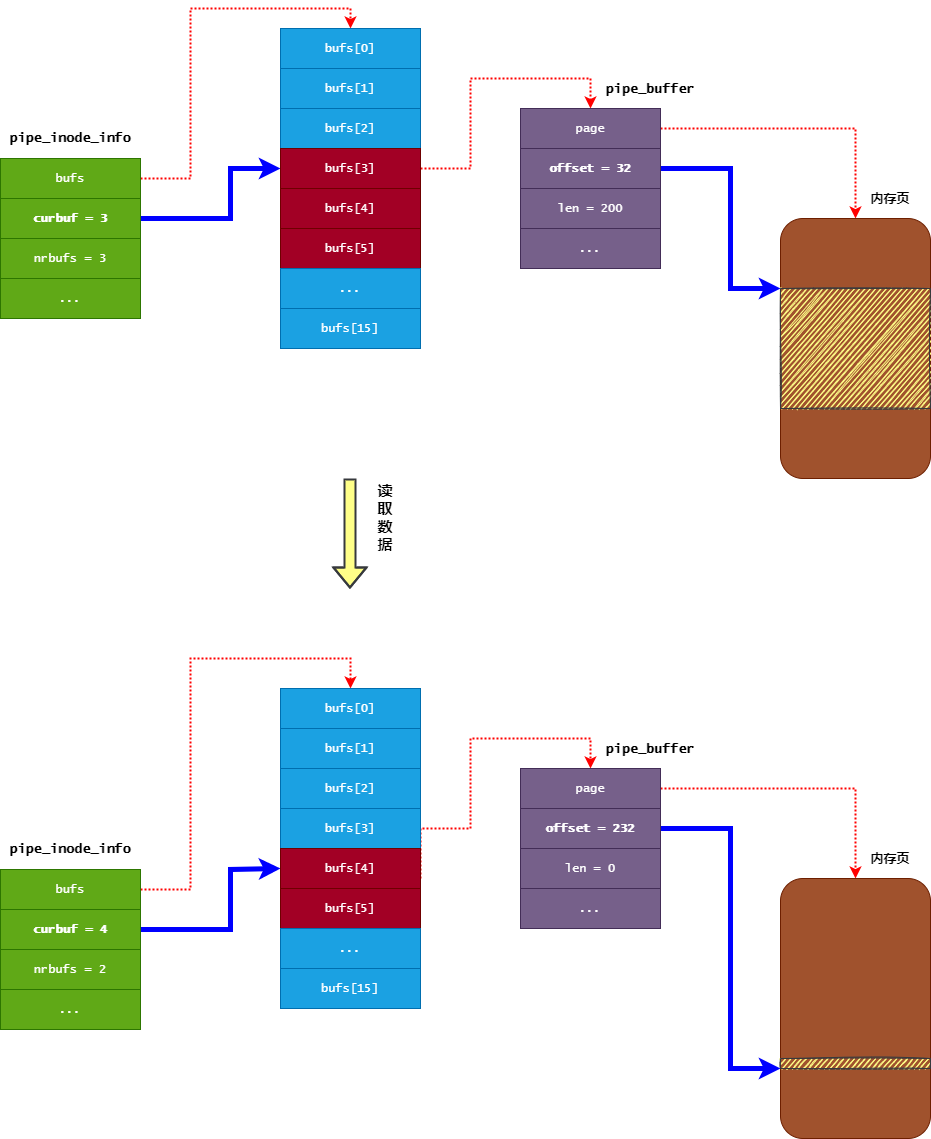
从缓冲区中读取到 n 个字节的数据后,会相应移动读指针 n 个字节的位置(也就是增加 pipe_buffer 对象的 offset 字段),并且减少 n 个字节的可读数据长度(也就是减少 pipe_buffer 对象的 len 字段)。
当 pipe_buffer 对象的 len 字段变为 0 时,表示当前 pipe_buffer 没有可读数据,那么将会对 pipe_inode_info 对象的 curbuf 字段移动一个位置,并且其 nrbufs 字段进行减一操作。
我们来看看管道读操作的代码实现,读操作由 pipe_read 函数完成。为了突出重点,我们只列出关键代码,如下所示:
static ssize_t
pipe_read(struct kiocb *iocb, const struct iovec *_iov, unsigned long nr_segs,
loff_t pos)
{
...
struct pipe_inode_info *pipe;
// 1. 获取管道对象
pipe = inode->i_pipe;
for (;;) {
// 2. 获取管道未读数据占有多少个内存页
int bufs = pipe->nrbufs;
if (bufs) {
// 3. 获取读操作应该从环形缓冲区的哪个内存页处读取数据
int curbuf = pipe->curbuf;
struct pipe_buffer *buf = pipe->bufs + curbuf;
...
/* 4. 通过 pipe_buffer 的 offset 字段获取真正的读指针,
* 并且从管道中读取数据到用户缓冲区.
*/
error = pipe_iov_copy_to_user(iov, addr + buf->offset, chars, atomic);
...
ret += chars;
buf->offset += chars; // 增加 pipe_buffer 对象的 offset 字段的值
buf->len -= chars; // 减少 pipe_buffer 对象的 len 字段的值
/* 5. 如果当前内存页的数据已经被读取完毕 */
if (!buf->len) {
...
curbuf = (curbuf + 1) & (PIPE_BUFFERS - 1);
pipe->curbuf = curbuf; // 移动 pipe_inode_info 对象的 curbuf 指针
pipe->nrbufs = --bufs; // 减少 pipe_inode_info 对象的 nrbufs 字段
do_wakeup = 1;
}
total_len -= chars;
// 6. 如果读取到用户期望的数据长度, 退出循环
if (!total_len)
break;
}
...
}
...
return ret;
}上面代码总结来说分为以下步骤:
- 通过文件
inode对象来获取到管道的pipe_inode_info对象。 - 通过
pipe_inode_info对象的nrbufs字段获取管道未读数据占有多少个内存页。 - 通过
pipe_inode_info对象的curbuf字段获取读操作应该从环形缓冲区的哪个内存页处读取数据。 - 通过
pipe_buffer对象的offset字段获取真正的读指针, 并且从管道中读取数据到用户缓冲区。 - 如果当前内存页的数据已经被读取完毕,那么移动
pipe_inode_info对象的curbuf指针,并且减少其nrbufs字段的值。 - 如果读取到用户期望的数据长度,退出循环。
4. 写操作
分析完管道读操作的实现后,接下来,我们分析一下管道写操作的实现。
经典的环形缓冲区 写入数据时,首先通过写指针进行定位要写入的内存地址,然后判断环形缓冲区的空间是否足够,足够就把数据写入到环形缓冲区中。如下图所示:
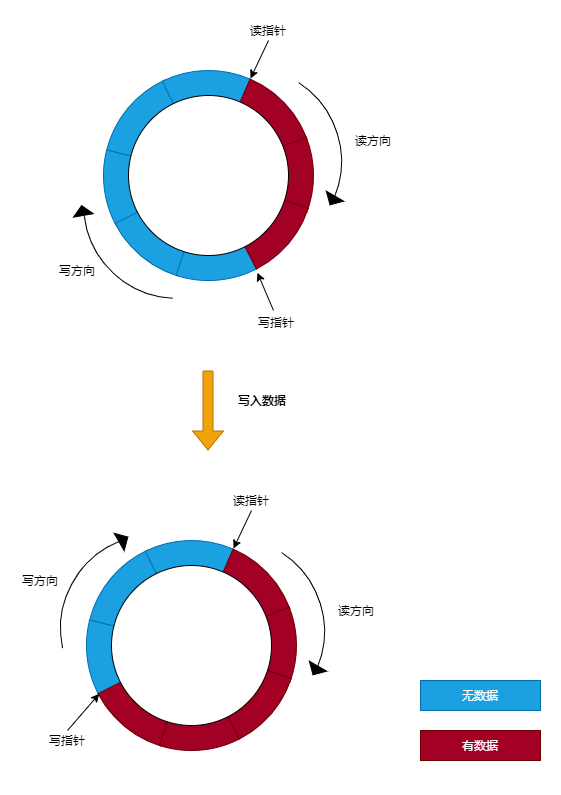
但 管道的环形缓冲区 并没有保存 写指针,而是通过 读指针 计算出来。那么怎么通过读指针计算出写指针呢?
其实很简单,就是:
写指针 = 读指针 + 未读数据长度
下面我们来看看,向管道写入 200 字节数据的过程示意图,如下所示:
如上图所示,向管道写入数据时:
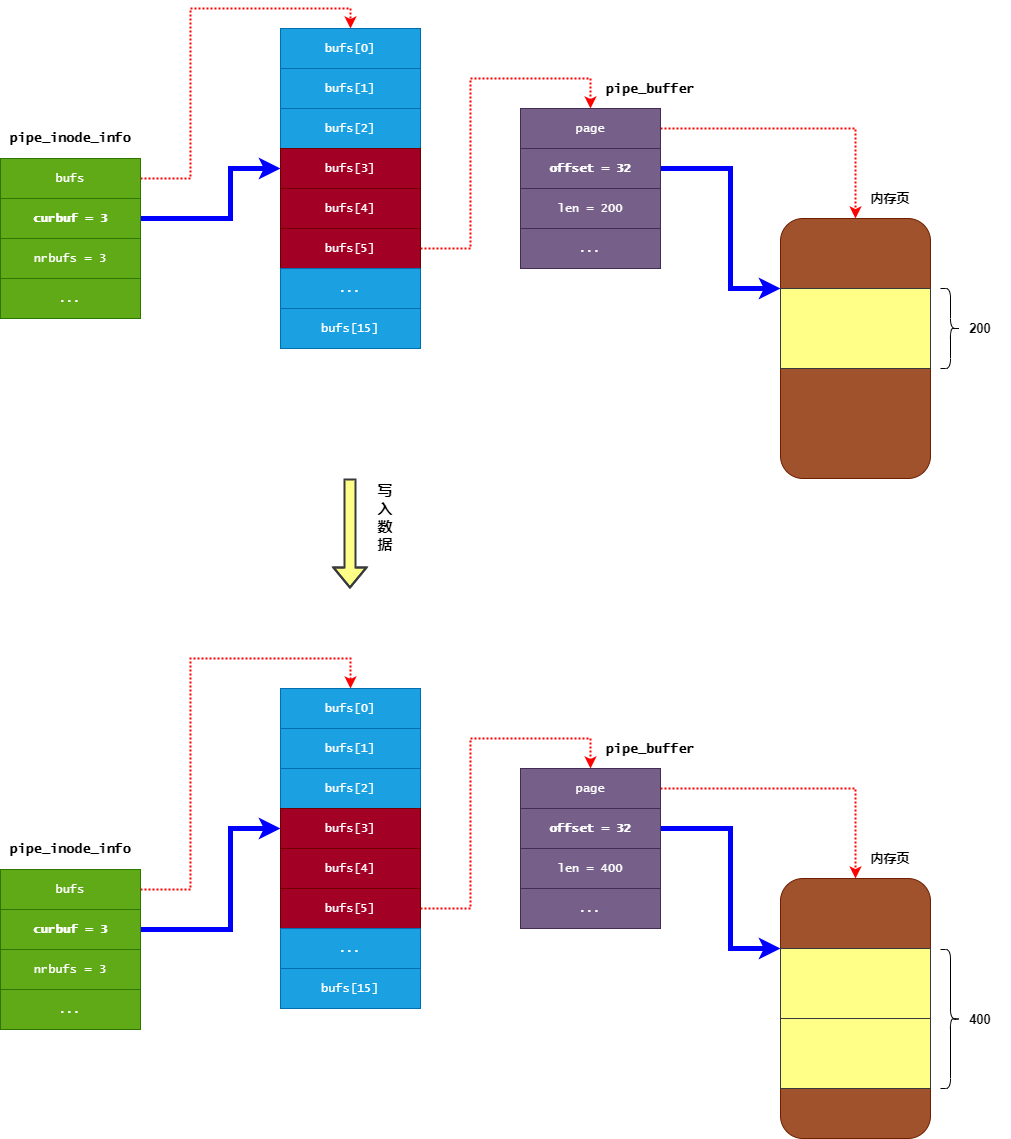
- 首先通过
pipe_inode_info的curbuf字段和nrbufs字段来定位到,应该向哪个pipe_buffer写入数据。 - 然后再通过
pipe_buffer对象的offset字段和len字段来定位到,应该写入到内存页的哪个位置。
下面我们通过源码来分析,写操作是怎么实现的,代码如下(为了特出重点,代码有所删减):
static ssize_t
pipe_write(struct kiocb *iocb, const struct iovec *_iov, unsigned long nr_segs,
loff_t ppos)
{
...
struct pipe_inode_info *pipe;
...
pipe = inode->i_pipe;
...
chars = total_len & (PAGE_SIZE - 1); /* size of the last buffer */
// 1. 如果最后写入的 pipe_buffer 还有空闲的空间
if (pipe->nrbufs && chars != 0) {
// 获取写入数据的位置
int lastbuf = (pipe->curbuf + pipe->nrbufs - 1) & (PIPE_BUFFERS-1);
struct pipe_buffer *buf = pipe->bufs + lastbuf;
const struct pipe_buf_operations *ops = buf->ops;
int offset = buf->offset + buf->len;
if (ops->can_merge && offset + chars <= PAGE_SIZE) {
...
error = pipe_iov_copy_from_user(offset + addr, iov, chars, atomic);
...
buf->len += chars;
total_len -= chars;
ret = chars;
// 如果要写入的数据已经全部写入成功, 退出循环
if (!total_len)
goto out;
}
}
// 2. 如果最后写入的 pipe_buffer 空闲空间不足, 那么申请一个新的内存页来存储数据
for (;;) {
int bufs;
...
bufs = pipe->nrbufs;
if (bufs < PIPE_BUFFERS) {
int newbuf = (pipe->curbuf + bufs) & (PIPE_BUFFERS-1);
struct pipe_buffer *buf = pipe->bufs + newbuf;
...
// 申请一个新的内存页
if (!page) {
page = alloc_page(GFP_HIGHUSER);
...
}
...
error = pipe_iov_copy_from_user(src, iov, chars, atomic);
...
ret += chars;
buf->page = page;
buf->ops = &anon_pipe_buf_ops;
buf->offset = 0;
buf->len = chars;
pipe->nrbufs = ++bufs;
pipe->tmp_page = NULL;
// 如果要写入的数据已经全部写入成功, 退出循环
total_len -= chars;
if (!total_len)
break;
}
...
}
out:
...
return ret;
}上面代码有点长,但是逻辑却很简单,主要进行如下操作:
- 如果上次写操作写入的
pipe_buffer还有空闲的空间,那么就将数据写入到此pipe_buffer中,并且增加其len字段的值。 - 如果上次写操作写入的
pipe_buffer没有足够的空闲空间,那么就新申请一个内存页,并且把数据保存到新的内存页中,并且增加pipe_inode_info的nrbufs字段的值。 - 如果写入的数据已经全部写入成功,那么就退出写操作。
三、思考一下
管道读写操作的实现已经分析完毕,现在我们来思考一下以下问题。
1. 为什么父子进程可以通过管道来通信?
这是因为父子进程通过 pipe 系统调用打开的管道,在内核空间中指向同一个管道对象(pipe_inode_info)。所以父子进程共享着同一个管道对象,那么就可以通过这个共享的管道对象进行通信。
2. 为什么内核要使用 16 个内存页进行数据存储?
这是为了减少内存使用。
因为使用 pipe 系统调用打开管道时,并没有立刻申请内存页,而是当有进程向管道写入数据时,才会按需申请内存页。当内存页的数据被读取完后,内核会将此内存页回收,来减少管道对内存的使用。