ElasticSearch查询改写
▌查询改写
1. 背景

为什么需要查询改写?主要因为自然语言表达的多样性,首先是Query和Doc之间表达的差异,用户的Query会相对随意,而Doc端相对正规,商家和运营录入的商家介绍等相关字段,会标准化一些。另外一个问题就是一义多词,通常一个含义的表达会有非常多种输入的方式。
右图是线上真实的搜索日志,是“理发”相关的搜索词。可以看到有非常多的变换形式。还有一词多义的问题,比如:结婚照,它可能包含两类的含义,一类是要找婚纱照,另外还有可能是去拍结婚证需要的证件照,如果我们不进行Query查询的改写,直接通过原词文本匹配,很可能会漏召回。
2. 技术演进
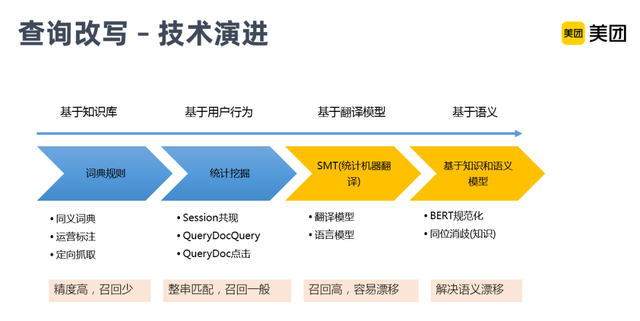
查询改写这块,技术演进主要分4个阶段,最初是基于词典规则,它的优点是精度高,但是召回率非常低。后面加入了基于用户行为统计挖掘的相关扩召回的方式,但由于是基于整串的匹配,召回虽然有一定提升,还是没法满足线上用户很多长尾Query的搜索。
为了解决长尾问题,引入了基于翻译模型的统计翻译改写,主要是通过用户行为日志,训练翻译模型和语言模型,从子串片段级别来解决覆盖问题,极大的提升了改写的召回。但它的问题是会比较容易产生语义的漂移,因为它主要是基于文本对齐和文本替换的统计概率,并未考虑语义信息。所以我们又引入了基于Bert的语义规范化,进行过滤,很大程度的缓解了语义漂移的问题。
3. 为什么选择SMT

接下来重点介绍一下我们线上的翻译改写模型。
为什么要选择这样一个翻译模型呢?首先翻译所需的平行语料,在搜索场景下,比较容易通过搜索日志的Session来构造,甚至还可以用Query-Doc的点击数据来补充,通过这样的平行语料,就能够自动化的获取海量的标注数据,覆盖足够多的语言现象,解决表达多样的问题。
另外翻译模型很重要一个特点,是它能够支持子串级别的替换,并充分考虑上下文。所以说它能够很好的进行召回泛化。
4. SMT改写过程
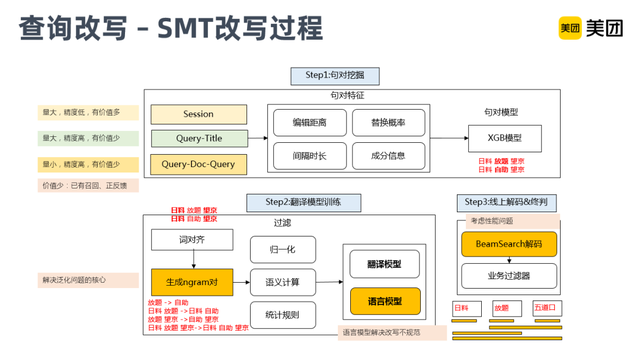
这是SMT改写的一个大致的过程。它主要分为三个部分:
最上面是句对挖掘,通过海量的用户行为,包括Session、Query-Title、Query-Doc-Query数据,对这些数据进行特征抽取,然后再结合句对的判别模型,生成片段级别的对齐语料。
第二部分翻译模型训练,它的输入是上一步生成的对齐语料,然后生成N-gram的片段,再结合语义计算和统计规则,去生产翻译模型和语言模型。它主要是通过N-Gram这种方式进行子串级别的泛化。
第三部分是线上的解码和终判,主要考虑性能问题。因为线上替换时,子串候选解码如果不加限制,会产生组合爆炸的问题。所以结合了BeamSearch以及业务相关的过滤器,例如利用NER和实体链接的信息,对商家实体词限制改写,通过这样的一些业务特征来保证精度。通过路径裁减,返回概率最高的Top-K的结果,进行改写路径的生成。